
こんにちは! 山下郁矢です。2018年新卒で入社し、現在はNoSQLデータベースエンジニアとして働いています。
サービスを作るにあたってデータベースは必要不可欠ですよね。ヤフーでは100を超えるサービスで毎日生み出される膨大なデータを、データベースを用いてリアルタイムで蓄積し、運用管理しています。
今回は、その中でも利用規模の大きい、NoSQLデータベースの1つであるApache Cassandraを皆様に知ってもらうべく、ヤフーでどのようにして利用されているのかをお伝えしたいと思います。
NoSQLの立ち位置
Cassandraについてご紹介する前に、NoSQLについて軽く説明します。
NoSQLデータベースは一般的に非RDBMSに該当するデータベースのことを指します。
MySQLやOracleのようなRDBMSとはどう違うのでしょうか? RDBMSと比べて、優位性のあるデータベースなのでしょうか? ...と、よく比較されてしまうことがあるのですが、そもそもRDBMSとは特性が異なります。
CAP定理
CAP定理と呼ばれる「分散システムにおいて、C・A・Pの3つの要素を同時に担保することはできない」というものがあります。NoSQLとRDBMSでは、担保できる要素がそれぞれ異なって設計されているため、NoSQLがRDBMSに打って変わるデータベースというわけではないのです。CAPとは、それぞれの要素名の頭文字を取って名付けられたもので、以下の3要素のことを指します。
- Consistency(整合性):ノード間でデータのズレが起きない(常に最新のデータが取れる)
- Availability(可用性):特定ノードで障害が起きても機能が失われない。単一障害点がない
- Partition-tolerance(分断耐性):通信障害が起きてもシステムとして正しく動作し続ける
一般的にCassandraでは、A・P(可用性・分断耐性)を担保するのに対し、冗長構成をとったRDBMSではC・A(整合性・可用性)を担保するように設計されています。
ここで注意しなければならないのは、要素を単純に担保するということではなく、要件に合わせて要素の度合いを調整してシステムを構築することがCAP定理の本質だということです。Cassandraの場合ですと、完全にC(整合性)を担保することができない、というわけではありません。後ほど説明しますが、Cassandraにはconsistency levelというオプションがあり、これを駆使することで整合性はある程度担保することが可能です。その場合は、A(可用性)が緩められます。
このように、データベースには要件的に目をつぶらなければならない要素が必ず存在するため、NoSQLが優れているかそうでないか、ということではなく、要件に合わせて適切なデータベースを選定していくことが重要になってきます。
Cassandraとは?
CassandraはNoSQLデータベースの一種であり、Key Value Store(KVS)構造をもつ分散型のデータベースです。Facebook社が自社サービスのInbox Search機能を強化するために開発を始めたのがきっかけで、2008年に同社がOSSとして公開し、2009年にはApacheのプロジェクトとなりました。分散システムはAmazonのDynamoDBを、データモデルはGoogleのBigtableをベースに作られています。
今やCassandraはApacheのトップレベルプロジェクトとなっており、マルチビッグデータを支えるシステムとして、AppleやNetflix, Instagramなど、さまざまな企業が積極的に採用しています。
サーバー単体から構築することが可能ですが、メリットを生かすためには複数台での構成が基本です。
データモデル
データモデルは至ってシンプルです。データはkeyとvalueの組み合わせで構成されています。ただ、Cassandraに関しては単なる組み合わせではなく、valueに複数のカラムを持つWide-column Storeを採用しています。
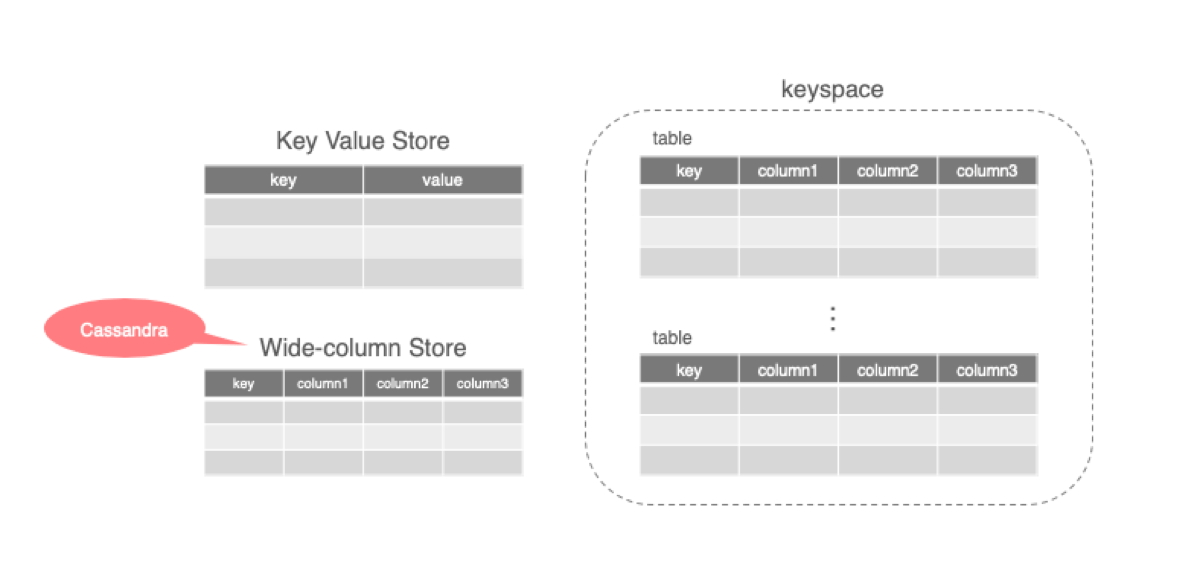
データはRDBMS同様、tableと呼ばれる単位で管理されます(以前はcolumn familyとも呼ばれていましたが、今はtableに名称が変わっています)。tableの集合体をkeyspaceと呼び、これはRDBMSで言うところのdatabase部分に該当します。
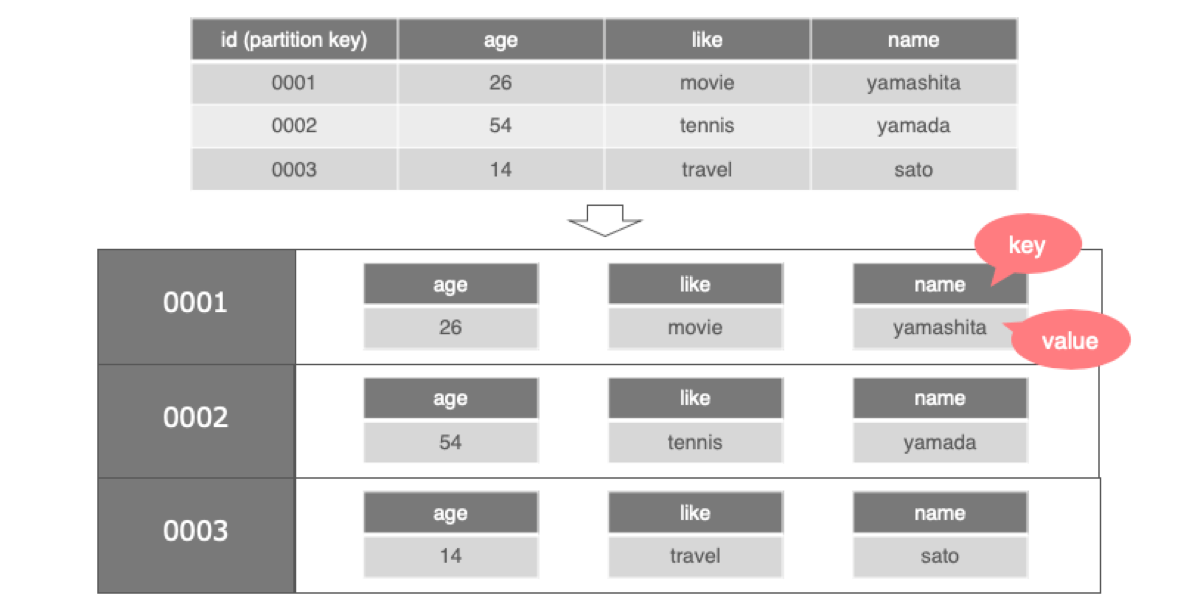
注意しなければならない点として、Cassandraは上記の図のように、RDBMSのようなテーブル構造としてデータを持っているわけではありません。1レコードを表の通り1行と認識するのではなく、1レコードをpartitionという括りにし、その中に複数のカラムがkey-valueで管理されています。partitionを区別するkeyのことをpartition keyと呼び、これをプライマリーキー(※)としてレコードを一意に識別します。従って、tableを作成する際には、partition keyの指定は必須です。
※Cassandraのプライマリーキーは、partition keyの他にもオプションとしてclustering columnというものがありますが、今回は割愛します。
データモデルとしては、下記のイメージです。
データ配置の仕組みについて
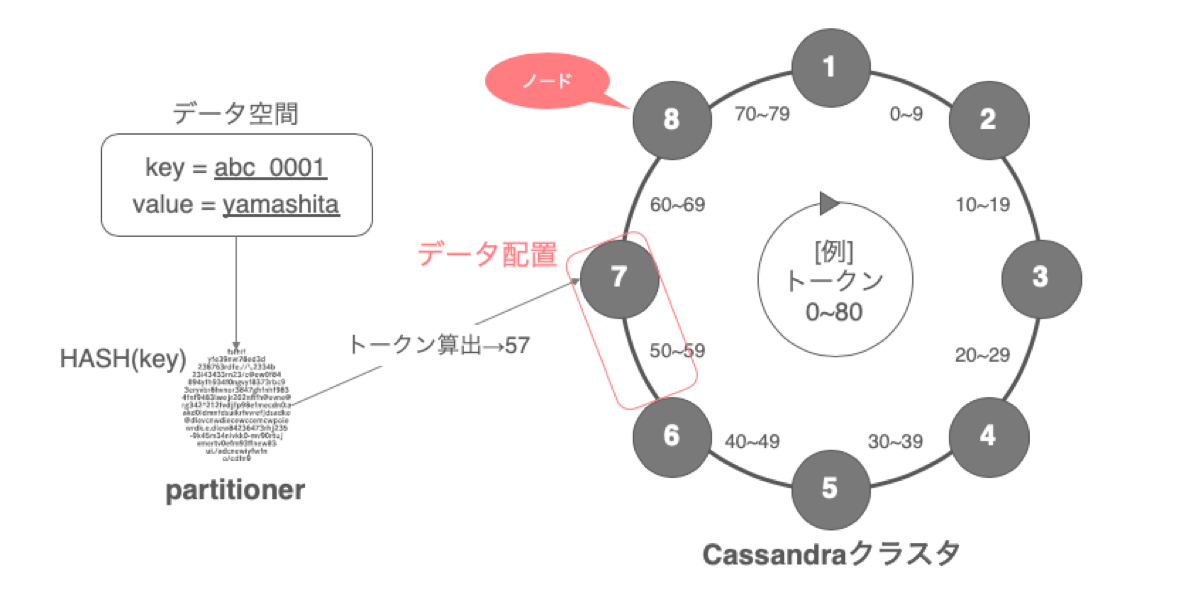
Cassandraでは、クラスタ内に構成されている複数ノードを時計回りに配置してリングとして見立て、リング1周をハッシュトークン値で構成します。各ノードは担当するトークン範囲が決まっており、プライマリーキーの値をpartitionerと呼ばれる機構でハッシュ関数にかけてトークン値を算出し、その値によってどのノードにデータが配置されるかが決定されます。ノードは、時計周りから見て自身とその手前のトークン範囲を担当します。
partitionerはいくつか種類がありますが、ハッシュ値の範囲やハッシュ関数はそれぞれ異なります。現在ではMurmur3Partitionerが主流となっています。高速なアルゴリズムで、クラスタ全体で均等にデータを分散させることができます。
各ノードは、initial_tokenという設定項目で、配置場所を決めるためにトークンの割り当てを行う必要があります。initial_tokenは固定値なので、この設定を変更しない限り配置場所は変わりません。例えばクラスタのサービスイン/アウトを行ってトポロジーが変わり、クラスタのノード配置をリバランスしたい場合は全ノードに対してinitial_tokenの再設定が必要です。
より良くデータを均一化し、トポロジーが変わった際の負荷を分散させるために、Cassandraでは後に仮想ノード(vnode)というアーキテクチャが登場します。これは、ノードを配置するためのトークンを自動的に計算して割り当て、さらにはトークン範囲を細分化して1つのノードを仮想的に分散配置するアルゴリズムです。num_tokensという設定項目で、ノードあたりのvnodeをいくつ生成するかを設定します(1に設定すると、vnodeは無効になります)。
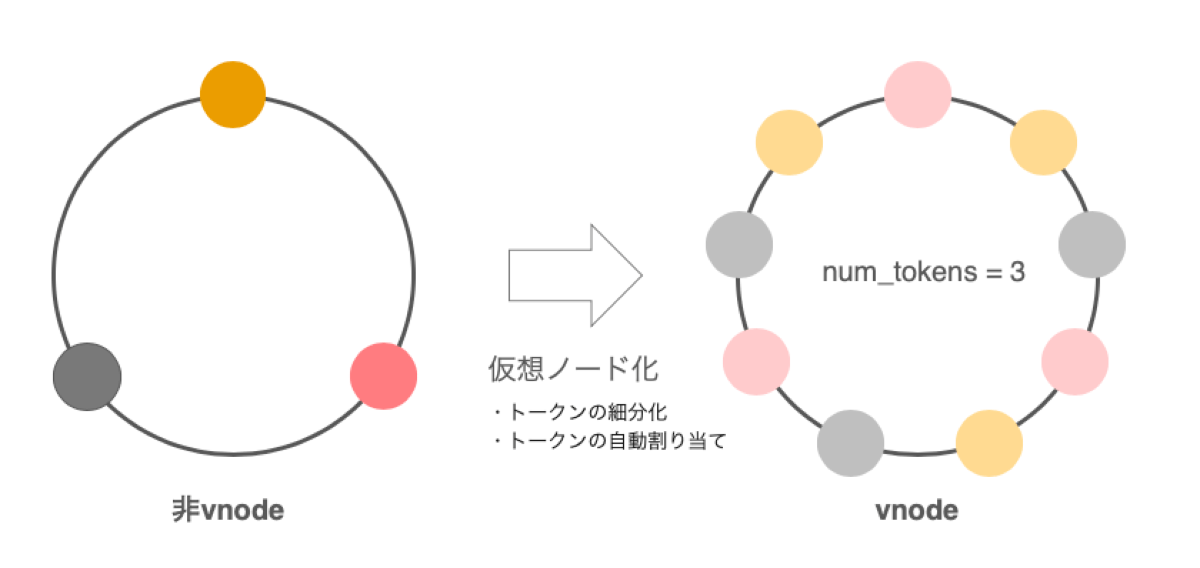
トークン範囲を細分化することで、データはより均一に分散されるようになります。また、あるノードが障害などの理由でクラスタからサービスアウトを行う場合、Cassandraでは基本的にリング上で隣接するノードにデータをストリームします。非vnodeの場合は1つのノードがデータを受け持つこととなり、負荷が高まってしまいます。vnodeだと、トークン範囲が細分化されており、なおかつ分散して配置されているため、サービスアウトの際にはノード全体へ均等にデータが分配され、負荷が分散します。これはサービスインの際も同様で、サービスインノードがノード全体から均等にデータを受け取れるように割り当てを行います。
現在はデフォルト設定でnum_tokensが256となっており、vnodeは推奨設定となっています。
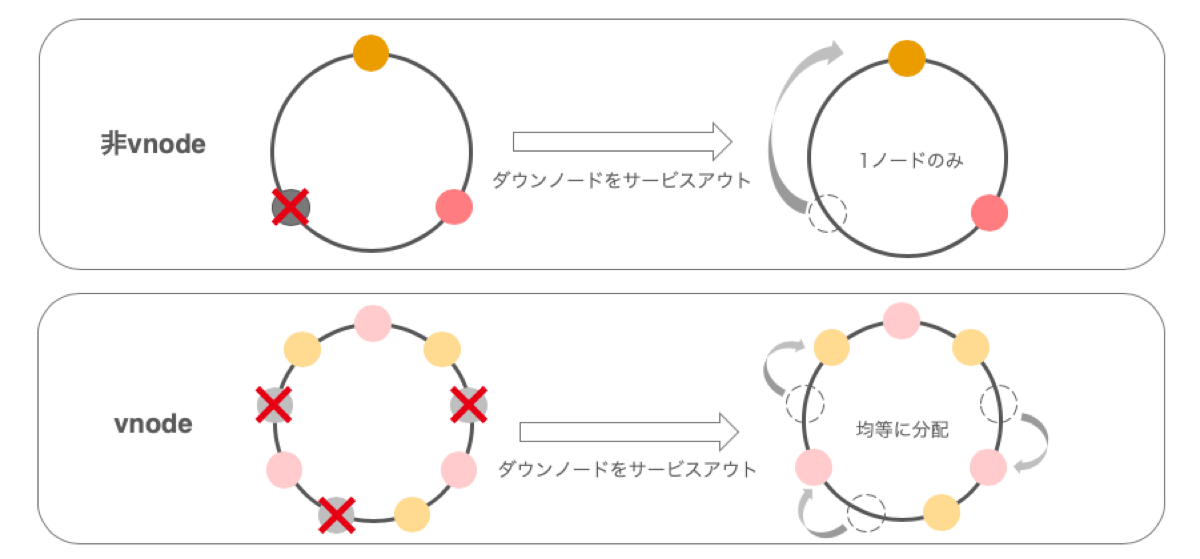
分散構造
Cassandraでは、replication factorという設定を変更することで、データのレプリカを各ノードにどれだけ分散させるかを任意に決めることができます。ここを増やせば可用性は上がりますが、レプリカ数を2にするだけでも容量は倍になりますので、サーバーリソースに合わせて適切な設定が必要です。
こちらの仕組みについては、後ほど改めて詳しくご説明します。
高速な書き込み
Cassandraは高速なデータの書き込みを重視しています。そのために、Log-structured merge-tree(LSM tree)というアルゴリズムを採用しており、これを実現しています。
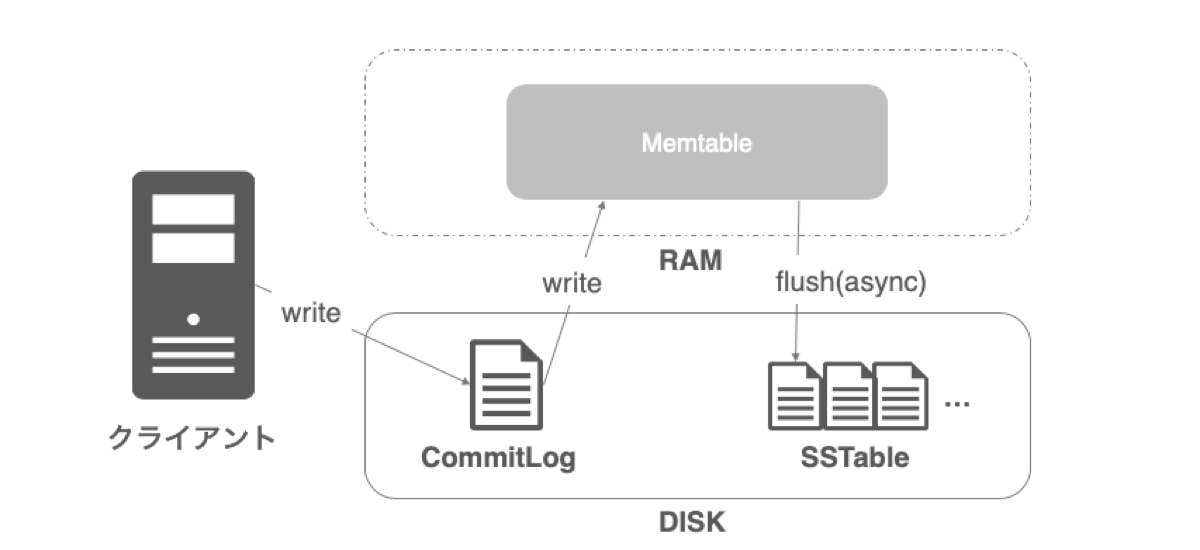 書き込みを行う際、最初にCommitLogというリカバリー用のファイルに書き込み操作を記録します。障害やメンテナンスなどでノードがダウンした際、立ち上げ復旧のタイミングでこのファイルが使用され、リカバリーが実行されます。次に、CommitLogからMemtableというRAM領域に書き込みを行います。書き込みは逐次的に行われ、書き込みプロセスとしてはここで完了するため、高速な書き込みを実現できます。
書き込みを行う際、最初にCommitLogというリカバリー用のファイルに書き込み操作を記録します。障害やメンテナンスなどでノードがダウンした際、立ち上げ復旧のタイミングでこのファイルが使用され、リカバリーが実行されます。次に、CommitLogからMemtableというRAM領域に書き込みを行います。書き込みは逐次的に行われ、書き込みプロセスとしてはここで完了するため、高速な書き込みを実現できます。
ここからは非同期処理ですが、Memtableが一定の値を超えると、今度はSSTableというファイルにフラッシュされ、データが永続化されます。ファイルは更新されることはなく、Memtableからのフラッシュを繰り返すたびに新たな世代のSSTableが作られていきます(compactionという、SSTableファイルの統合プロセスによる例外はあります)。
CommitLogは永続的なファイルではないため、リカバリー後に強制破棄されるか、設定したファイルサイズに到達したタイミングでローテートされます。また、MemtableからSSTableへフラッシュしたタイミングでも破棄されます。
以上の仕組みから、高速な書き込みを実現するLSM treeですが、その反面読み込みについては少し苦手です。データの読み込みを行う場合、Memtableから探索を行います。そこにデータがない場合は、SSTableを参照して探索していきます。読み取りたいデータを見つけるまでに時間がかかってしまうため、書き込みよりも少々性能が劣ってしまいます。キャッシュ機構やBloom Filterという仕組みを活用して読み取りの高速化を実現していますが、今回は割愛します。
Cassandraのメリット
書き込みが速い
上記のLSM treeの説明の通り、Cassandraは書き込みが高速で、これにより高パフォーマンスでの処理が期待できます。
マスターレス
Cassandraはマスターレスなので単一障害点がなく、どこかのノードがダウンしてしまっても問題なく処理を続けることが可能です。
全ノードが同じように動作するので、多数のリクエストを同時に受け付けることが可能です。さらにはスケールアップ/アウトを行ってより多くのリクエストを捌けるようにパフォーマンスを上げることができるので、マスターレスであることは高パフォーマンスを目指す上での利点になっているわけです。
スケールアップ/アウトが簡単
Cassandraではノードのサービスイン/アウトを容易に行うことができます。そのため、サーバーリプレイスやノードの増設などが行いやすく、簡単に性能を上げることができます。基本的にサービスイン/アウトをする際にはダウンタイムがないため、任意のタイミングで実施が可能です。
RDBライクに操作が可能
データモデル的に、これまでRDBMSを扱ってきた人にとっては扱いに苦労する印象がありますが、Cassandraのクエリ言語であるCassandra Query Language(CQL)は、SQLライクにデータベースを操作することが可能です。シンタックスもSQLに非常に似ており、DML(データ操作言語)を使って操作ができます(ただし、リレーショナル機能はないので、SELECTの際にJOIN句は使えません)。cqlshという、CQLを対話形式で実行できる公式のコマンドラインクライアントがありますが、こちらを利用してSELECT表示した際もRDBMSのようにテーブル表記でデータを表示してくれるので、使用していて抵抗はほとんどないと思います。
Cassandraのデメリット
複雑な検索や集計などは不得意
プライマリーキーを元に配置先が決まっているため、基本的にはプライマリーキーを検索キーとしてアクセスする使い方が望ましいです。プライマリーキー以外の要素で検索したり、結果を統計的に集計するなどの複雑な処理は得意ではありません。もちろん不得意なだけで、機能的にはRDBMS同様の処理を行うことはできますが、パフォーマンスが大きく下がってしまうため、Cassandraにとってはアンチパターンです。
整合性を担保しづらい
CAP定理にあるように、Cassandraでは整合性については目をつぶらなければならない要素です。ただし、ここは後述する
consistency levelを調整することで、ある程度担保できます。
ヤフーでのCassandra利用
今やCassandraは、ヤフーにおいて必要不可欠な存在となりました。今となっては約400クラスタを運用しており、総ノード数は約9000にもなります。そんなCassandraですが、ヤフー社内で一体どのようにして利用しているのかをご紹介したいと思います。
整合性に関するデメリットを最小限に抑えるために
Cassandraのような分散データベースでは、サーバーやネットワークの状態、メンテナンス、障害などが発生した場合に部分的に書き込みが行き渡らないことがあります。その結果、レプリカノード間でデータのズレが生じることは少なくありません。このズレとどう向き合っていく必要があるか、社内の例を元に説明していきます。
クライアントから最初に接続しにいくノードのことをコーディネーターノードと呼びます。コーディネーターノードを介してリクエストを送る際、あるデータがレプリカされた(もしくはされる予定の)ノードに対し、いくつ読み書きが成功すればクライアントに正常な結果を返すかを決めるための設定をconsistency levelといいます。代表的なものとして、3つ紹介します。
- ONE : 最初にリターンしてきたノードのデータを返却する
- QUORUM : 最初にリターンしてきた
replication factor/2+1数(過半数)のデータの中で、タイムスタンプの新しいものを返却 - ALL : 全てのノードからリターンするのを待ち、タイムスタンプの新しいものを返却
ONEでは、とにかくどこかのノードからリターンがあればクライアントにデータ返却しますが、QUORUMやALLはリターンするノード数が満たされない場合はエラーを吐きます。
以下の図で、replication factorを3とし、データのズレが起きている状態でSELECTをした際のリクエスト結果について3パターンで考えてみます。
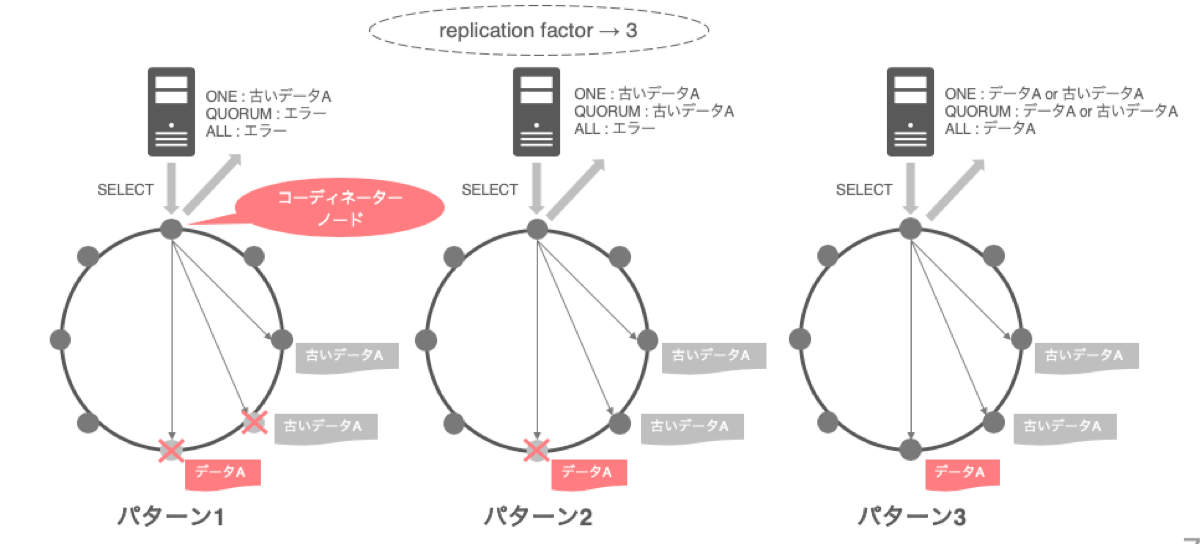
まずパターン1ですが、QUORUMとALLの場合だとレプリカノードが2個ダウンしているため、エラーとなります。ONEはデータを返却しますが、リターンされたノードは古い状態のデータを保持していたため、結果として古いデータが返却されます。
次にパターン2では、QUORUMもデータを返却しますが、これもリターンしてきた2ノードが古い状態のデータだったため、古いデータが返却されてしまいます。もし、この2ノードのいずれかが最新のデータを持っていた場合は、データ内部で保有されているタイムスタンプを比較して新しい方を返却するため、古いデータが返却されることはありませんでした。ALLは引き続きエラーを吐きます。
パターン3では、レプリカノードが全て生きているので、ようやくALLでデータが返却されるようになります。データについても全てのノードでデータが比較されるため、最新のデータを取得できます。しかし、ONEとQUORUMについては、引き続き古いデータが返却される可能性があります。これはクライアントに返却する際、最初にリターンしてきたノードのデータを考慮するため、ONEはともかくとしてQUORUMの際にも、古いデータを持つ2ノードが最初にリターンしてきた場合は古いデータを返却してしまうことになります。
このように、consistency levelの設定次第ではALLのように整合性をガッチリ満たせるようにアクセスすることは可能ですが、全てのノードからの応答を待ったり、1つでもノードがダウンしているとエラーが吐かれてしまうなど、パフォーマンスや可用性に影響が出てしまうため、Cassandraのアンチパターンとなってしまいます。
ヤフー社内ではconsistency levelの設定はサービス開発チームごとに任意に決めてもらっていますが、例外としてALL設定だけは利用しないように促しています。
このデータのズレを修復するための機能として、Cassandraにはrepairという機能が備わっています。repairは、レプリカが配置されているノード間でデータを比較し、ズレが生じている場合は最新のデータに再同期する機能です。ヤフー社内では、repairを週に2回ほど定期的に実行するためのバッチスクリプトを動かしており、整合性の面でのデメリットを最小限に抑えるための対策を行っています。repairを実施している間はパフォーマンスが落ちてしまうため、なるべく早く終わらせたいところです。repairはデフォルトで実行すると、それなりに時間がかかってしまうため、スクリプト内ではrepairの時間短縮のための工夫も行っています。こちらについては以前別のエンジニアが発表した資料で詳細に説明がありますのでご参照ください。
障害に耐えうる分散構造
Cassandraでは先に説明したような、クラスタ全体で1つのリングとして形成するだけでなく、ノードごとにdatacenterとrackを論理的に設定し、rack単位でデータを配置できます。これによりreplication factor設定を駆使して、より一層障害に耐えうるような屈強な構成になります。
replication factorは、設定した論理datacenterごとにいくつレプリカを作成するか詳細に設定できます。例えば、2つの論理datacenterに3つずつレプリカを作成する、と設定した場合、クラスタ全体で合計6つのレプリカを作成します。また、論理datacenter内の各論理rackに関しては、なるべく同じ論理rack内に複数のレプリカが配置されないようにうまく分散してデータを配置してくれます。
物理的な配置と論理設定を合わせることで、実際のデータセンターが何かしらの障害でダウンしてデータをロストしてしまっても、もう一方のデータセンターで同じデータを保持しています。そのため、データのロストは起きずにシステムも引き続き動作し続けることが可能です。また、物理ラック単位でダウンした際も、他のラックでカバーできるためシステムは問題なく動き続けます。
物理配置と論理設定をしっかり考慮しないと、システムとしては危険な状態です。物理ラックがダウンしてしまった際、その中に格納されていたノードが全て、あるデータのレプリカ先として集約されてしまっていた! ということになればデータロストとなってしまいます。
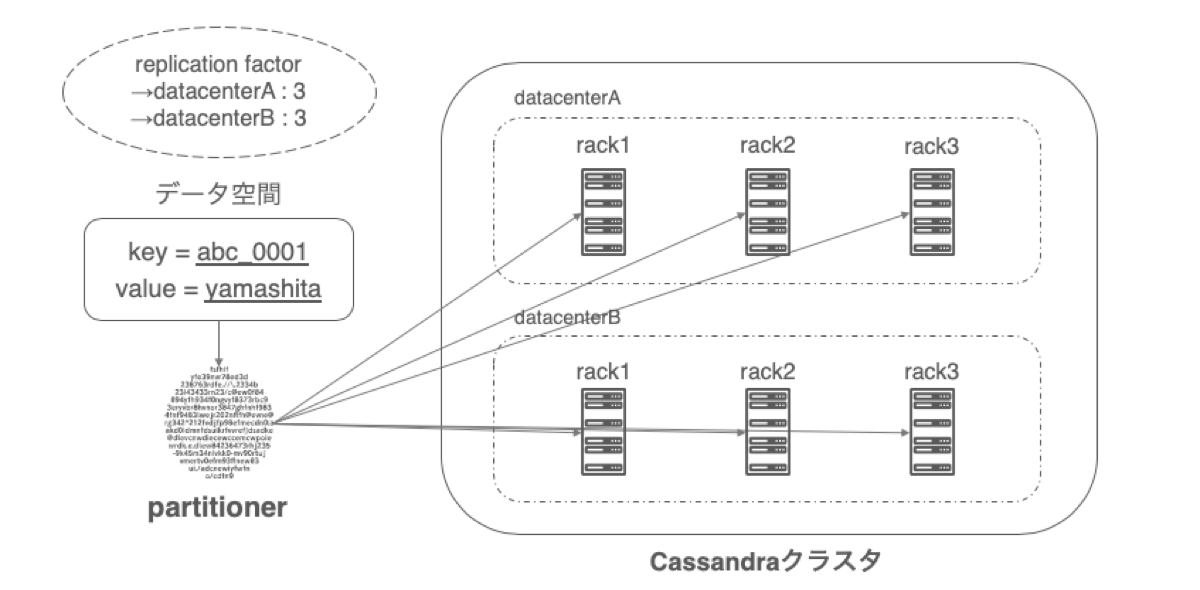
上記の図は実際にヤフー社内で採用しているCassandraのシステム構造となっています。Cassandraの仕様上、論理datacenterや論理rack, replication factorの設定には制約がなく、任意の数で設定ができます。ヤフー社内では、以下の設定でCassandraを運用しています。
論理datacenter数:1つ or 2つ
利用するサービスがBCP構成を必要とするか否かという要件に合わせます。
replication factor : datacenterごとに3
基本的に3で固定しています。Cassandraでは障害検知時に自動的にフェイルオーバーされるので、過度な冗長は不要です。
整合性とサーバーメンテナンス、障害の観点から、社内では
consistency levelをReadでLOCAL_QUORUM、WriteでEACH_QUORUMかLOCAL_QUORUMで運用することを前提として構成しています(※)。QUORUM(過半数)となるためには、レプリカ数は3以上が望ましいです。後述する論理rack設定で適切な構成にすることで、十分な可用性を担保できるため、3としました。ヤフー社内では、この構成で今までにデータロストのような大障害が発生したことは一度もありません。※LOCAL_QUORUMは、コーディネーターノードと同じ論理datacenter内のレプリカを対象にリクエストを送ります。EACH_QUORUMは、各論理datacenterのレプリカを対象にリクエストを送ります。EACH_QUORUMではReadはサポートされていません。
論理rack数:3
replication factor数を合わせることで上記の図のようにデータを分散させる際に、均等にrackごとに配置されるようになります。キャパシティー管理や障害時の対応などの運用面で都合が良いため、ここは合わせるようにしています。
クラスタ内の各ノードはそれぞれrack1, rack2, rack3と割り振られることになります。前述にもありますが、例えばある物理ラック内にrack1, rack2, rack3と割り振られたノードが存在しているとします。データのレプリカはそれぞれの論理rackに均等に分散されますので、特定データのレプリカノードが全てその物理ラックに格納されてしまっている可能性があります。この場合、物理ラックが障害などでダウンしてしまった際、特定のデータを取得することができなくなり、最悪のケースだとデータロストが発生してしまいます。なので、1つの物理ラック内のノードは全て同じ論理rackに設定する必要があります。適切に設計することで、可用性がぐぐっと上がります。
ヤフー社内でのプラットフォーム提供
Cassandraは、ヤフー社内のプラットフォームサービスとして2012年頃から提供を始め、さまざまなサービス開発チームに対してCassandraを提供・運用を行っています。利用相談から始まり、パフォーマンス要件に合わせた台数見積もりや、テーブル設計に関するコンサルティング、提供後のメンテナンス管理や問い合わせ対応など、開発者が安心して利用し、サービス開発を進められるように、日々努力しています。
利用形態はさまざまで、メインストレージとしての利用はもちろん、機械学習のレコメンドデータの格納やオブジェクトストレージのメタ情報格納、キャッシュ機構としての利用などがあります。われわれ同様サービス開発チームに向けて提供を行っているプラットフォームでもCassandraを利用してもらっているケースは多々あるため、ほぼ全てのサービスで使われているといっても過言ではありません。
2018年からは、社内向けDBaaSの提供を開始しています。クラスタ名とkeyspace名を入力するだけで、ワンクリックでCassandraクラスタが作成できるので、リードタイムの短縮に大きく貢献しています。
OSSコミュニティーへの貢献
Cassandraの構築・運用だけでなく、OSSへの貢献も行っています。2016年頃から現在までに約20件のチケットに関与しており、バグ修正や機能改善に貢献してきました。大規模運用をしていないと見えてこない課題もあるため、まだまだ改善できるところはありそうです。
私も以前コントリビュートし、修正パッチが採用されて最近ようやくリリースされました。
OSSへのコントリビュートに関しては、さまざまな不安があったため若干抵抗があったのですが、いざ参加してみて、英語の壁や技術力などは気にせずに積極的に行っていくのが大事だと感じました。
おわりに
今回は、Cassandraについてご紹介しました。
社内での提供数は年々増加していき、今後も増えていく予定です。ただ、ノード数が増えれば増えるほど新しい運用課題はどんどん生まれてきます。そういった課題を日々解決していき、ユーザーがサービスを安心して利用していけるようなプラットフォームとして提供していきたいと思っております!
参考
12年後のCAP定理: "法則"はどのように変わったか - InfoQ
https://www.infoq.com/jp/articles/cap-twelve-years-later-how-the-rules-have-changed/
Cassandra - A structured storage system on a P2P Network - Facebook
Partitioners - Datastax Documentation Apache Cassandra 3.x Understanding the architecture
https://docs.datastax.com/en/cassandra-oss/3.x/cassandra/architecture/archPartitionerAbout.html
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



