こんにちは、「Hadoop」黒帯(ヤフー内のスキル任命制度)の鯵坂(@ajis_ka)です。
ヤフーでは、およそ2年間の調査・検証期間を経てヤフーで利用している本番環境のHDFS(Hadoop Distributed FileSystem)をHDP(Hortonworks Data Platform)2.6系(Apache Hadoop 2.7.x相当)からApache Hadoop 3.3.0にメジャーバージョンアップし、HDFSの新機能であるRouter-based Federation(RBF)を導入しました。 本記事では、これまでの2年間で何をしてきたのかについて振り返っていきます。
バージョンアップの経緯
ヤフーでは、提供している多種多様なサービスのログを分析してサービスの改善に役立てるため、Hadoopクラスタを複数運用しています。その中でも最も大規模なHadoopクラスタだと、2019年11月時点でデータの利用量は70PB程度、ファイル数、ディレクトリ数、およびブロック数の合計が5億以上にもなっている状況でした。
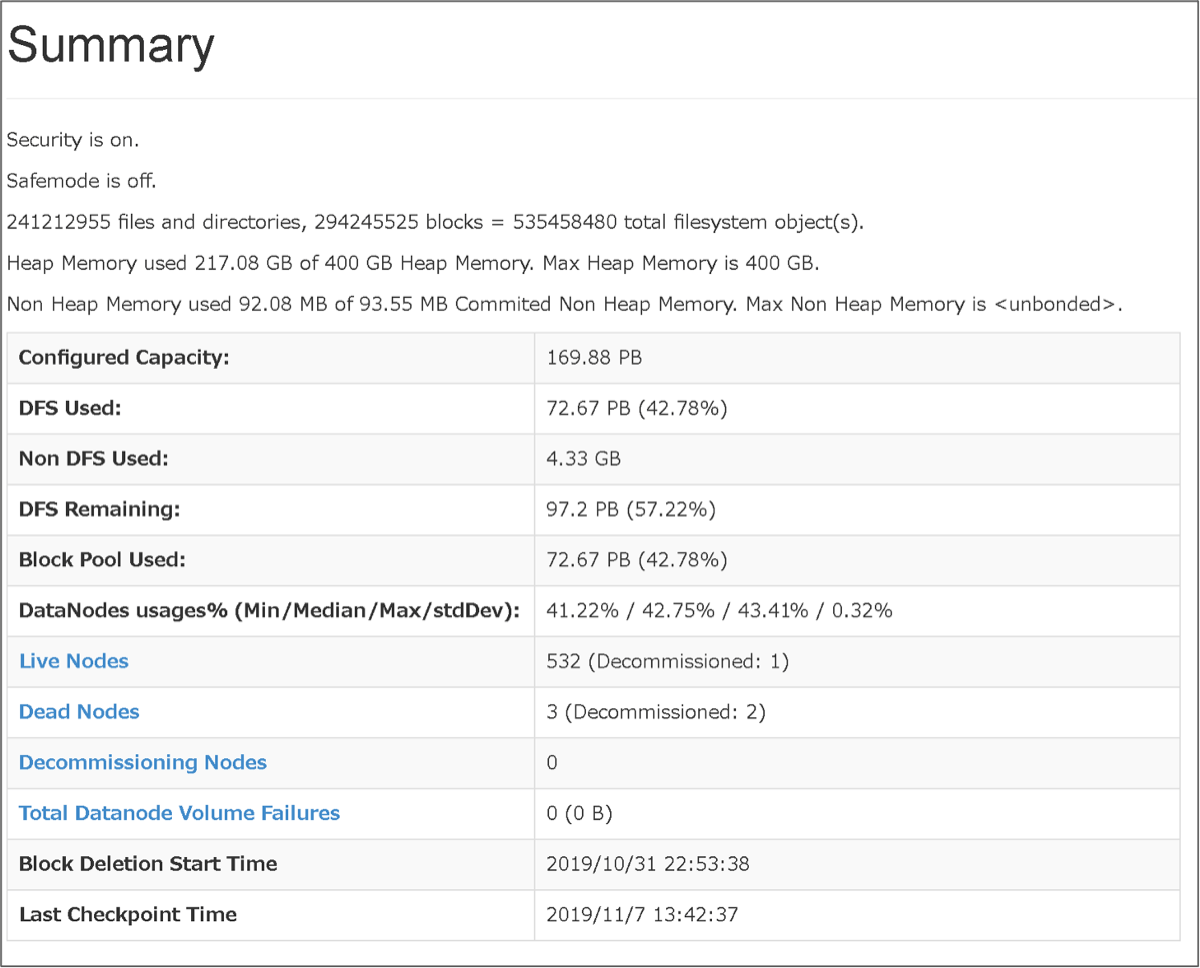 図1. 最大規模のHDFSのサマリ(バージョンアップ前)
図1. 最大規模のHDFSのサマリ(バージョンアップ前)
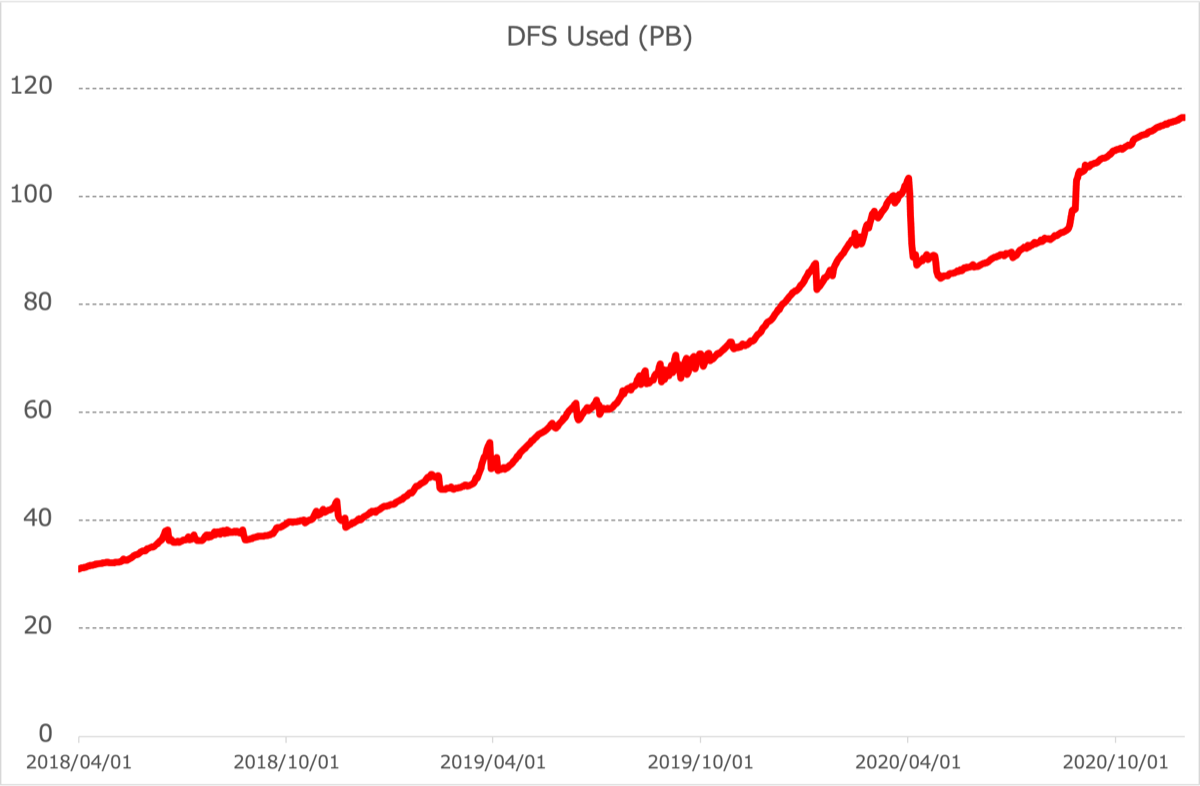 図2. 最大規模のHDFSのデータ利用量推移
図2. 最大規模のHDFSのデータ利用量推移
ここで、HDFSのマスターであるNameNodeへの負荷が2つの意味で厳しくなっていました。
1つ目はGC(Garbage Collection)による負荷です。NameNodeではHDFSのファイル、ディレクトリ、およびブロックのメタ情報を全てJavaのヒープ上に持つため、大規模な環境ではヒープサイズを非常に大きくする必要があり、本環境では400GBに設定しています。 ところが、ヒープサイズを大きくすればするほどGCの負荷も大きくなり、本環境ではG1GCを利用していましたが、mixed GCが発動するたびにNameNodeが数分停止してスタンバイのNameNodeにフェールオーバーするような事態になっていました。フェールオーバーすることでサービスとしては落ちることなく継続できていますが、タイムアウトによりフェールオーバーするまで(本環境では1分間)はリクエストに全く応答できていないことになり、これはもちろん避けるべき事態です。
2つ目はクライアントからのリクエスト増加による負荷です。Hadoopの利用ユーザーやジョブ数が増え続けたことによりNameNodeへのリクエストが増加し、NameNodeのキューがたびたびあふれている状況です。
これらの負荷状況を端的に表したスライドがこちらです。
データ利用量およびリクエスト数は今後も増えていく傾向があることから、NameNodeへの負荷に対して何らかの抜本的対策を講じる必要がありました。そこでさまざまな調査および検証を実施した結果、HDFSを最新バージョンに上げて、新機能であるRBFを導入することに決めました。 RBFではHDFSクラスタを複数に分割してNameNodeへの負荷を分散しますが、Routerによってユーザーからのリクエストは適切なHDFSクラスタにリダイレクトされるため、ユーザーからは1つのHDFSクラスタとして扱うことができます。この調査の一環としてシリコンバレーで開催されたApache Hadoop Contributors Meetupに参加しました。RBFについてもっと詳しく知りたい方は以下の記事をご確認ください。
Apache Hadoop Contributors Meetup出張報告(後編)
本番導入までの長い道のり
HDFSバージョンアップおよびRBFを導入すると決めてから実際に本番環境に導入するまでに、多くの開発および検証を積み重ねてきました。これらの取り組みについて紹介します。
デプロイ・運用ツールの移行(Ambari -> Ansible)
これまで、HDFSはApache Ambariというツールを利用して運用していました。ところが、Apache Ambariはコミュニティー版のApache Hadoopに対応していないため、HDFSのデプロイや運用ツールをAnsible playbook(以降は単にplaybookと記載する)に全て置き換えました。Hadoopの設定配布や各コンポーネントの起動・停止・正常性確認のためのplaybookを実装し、Ansible AWXからGUIで実行できるようにしています。 また、社内のセキュリティ基準を満たすためにAWXのソースコード自体を少し改変し、監査ログを出す、任意コマンドを実行できないようにする(事前に定義されたplaybookしか実行できないようにする)などの変更を施しています。過去の発表資料では時間の都合で触れていませんでしたが、純粋にもっとも工数がかかっているのはこのAmbari脱却のためのツール移行でした。 また、Hadoopにおいて非常に複雑なことで知られるKerberos関連の設定についても、playbookを実行するだけでprincipalの発行やkeytabの配置などの操作が自動で完了するようにしています。
Hadoopのコンポーネントについては自前でソースコードからビルドし、Nebulaというツールで独自にパッケージングしています。Hadoop関連のプロダクトをパッケージングするツールとしてApache Bigtopがよく知られていますが、当時はHadoop 3系に追従していなかったため今回は利用していません。 また、HDFSのアップグレードで実行するコマンド群もplaybook化して、ワンコマンドでHDFSのアップグレードが完了するようにしました。
クライアント/サーバー間の互換性の検証
今回のアップグレードでHDFSのメジャーバージョンを上げますが、クライアントの多くは古いバージョンのHDFSクライアントをそのまま利用します。 そのため、古いバージョンのHDFSクライアントからHDFS 3系にアクセスできるかどうか確認する必要がありました。Hadoopではクライアント/サーバー間の通信はProtocol Buffersを利用しているため、Protocol Buffersにおけるメッセージの定義ファイル(.protoファイル)を確認して互換性について問題ないことを確認しました。詳細については昨年のAdvent Calendar記事をご確認ください。
Hadoopのバージョン混用は可能? HDP 2.6.4 とコミュニティ版 Hadoop 3.2.1 におけるHDFSの互換性調査結果
クラスタ分割方針の検討
今回のアップグレードでは1つのHDFSクラスタを2つに分割することにしたのですが、既存クラスタのHDFSディレクトリを2つのクラスタに対してどのように割り当てるべきか検討する必要がありました。ここで、NameNodeが保持するメタデータの量とNameNodeに対するリクエスト数がなるべく均等に分かれるように、NameNodeのメタ情報であるfsimageやNameNodeの監査ログを分析しました。リクエストには更新系と参照系がありますが、更新系のリクエストのほうが負荷が重いため、更新系と参照系でそれぞれリクエスト数がなるべく均等になるようにディレクトリを割り当てました。 また、クラスタを物理的に2つに分けてしまうため、それぞれのHDFSクラスタをまたぐrenameはできなくなります。そのため、クラスタまたぎのrenameがないかどうか監査ログから確認しました。
新しく構築したクラスタにデータをコピーしておくことも必要です。過去分のデータはアップグレード前にDistCpでコピーできますが、当日分のデータなど、どうしてもアップグレードのメンテナンスのタイミングでコピーしなければいけないデータがあります。このデータ量をなるべく減らし、現実的な時間内にコピーできるよう調整しました。
 図3. HDFSアップグレード前後の概略図
図3. HDFSアップグレード前後の概略図
Java 11へのバージョンアップ
今回のHDFSアップグレードでJavaのバージョンアップにも挑戦しました。バージョンアップ前はJava 8を利用していたのですが、現時点での最新LTS(long-term support)バージョンであるJava 11ではGCの性能改善のための機能が多数入っているため(参考: FYI: Changes to Garbage Collection in JDK11)、Java 11にバージョンアップすることでNameNodeの負荷が軽減できると考えました。 また、ヤフーではHadoopのJava 11対応に2年前から取り組んでいて、OSSのHadoopコミュニティーに50件以上ものパッチを投稿し、現在の最新リリースであるHadoop 3.3.0ではついにJava 11のランタイムでの動作が可能になりました。昨年開催されたJJUG CCC 2019 Fallでこの取り組みについて発表したのですが、最新のJavaバージョン(ブログ公開時点ではJava 15)や、来年秋にリリースされる予定のJava 17 LTSにも対応していくためにまだまだやるべきことが残っています。
2021年1月22日に開催されるYahoo! JAPAN Tech Conference 2021でこの取り組みの最新状況について発表するので、興味があればぜひご視聴ください。
ユーザー向け開発環境への導入
今回アップグレードしたHadoopクラスタは、エンドユーザー向けの開発環境、サーバーやネットワークの構成を本番とそろえたステージング環境、本番環境の3つセットで構成されています。互換性の調査やJava 11、RBFの動作検証がひととおり完了したところでまずは開発環境をアップグレードしました。この時点ではHadoop 3.3.0はリリースされておらず、trunkのソースコードをビルドして利用しました。
Hadoop 3.3.0リリースへの貢献
当初の予定では今年の5月に本番環境をアップグレードするつもりでしたが、5月の時点でまだHadoop 3.3.0がリリースされていませんでした。3.3.0を使わずにtrunkをビルドして使うという方法もありましたが、trunkを利用すると次にバージョンを上げるときに互換性に対する保証が得られないため、リリースを待つことにしました。 しかし、ただ待っているだけではリリースがさらに延期される可能性があるため、率先してrelease blockerのバグを修正・レビューしていく、リリースマネジャーの作業を手伝うなど、なるべく早くリリースができるようにコミュニティーに対して働きかけました。Release blockerのバグは多くの場合かなり複雑で、今回のバグ(HDFS-13596およびHDFS-15421)でも調査に多くの時間を割くことになりましたが、周りの開発者の助けにより無事解決することができました。
ステージング環境および本番環境への導入
Hadoop 3.3.0が無事リリースされて、ステージング環境と本番環境に導入しました。 開発環境とステージング環境で何度も検証したにもかかわらず、本番環境特有の環境差分によりアップグレード用のplaybookが想定通りに動作しない問題に出くわしました。ここでplaybookが正常に動作しなかった原因を突き止め、問題を修正してplaybookを途中から実行することになるのですが、アップグレード用のplaybookではある程度の意味のあるtaskの固まり単位でtagを付けていたため、tagをいくつか指定するだけで途中からスムーズにアップグレードの処理を継続することができました。アップグレードかどうかにもかかわらず、大きめのplaybookを扱う際にはtagを付けておくのがおすすめです。結果として、開発環境とステージング環境では何度かアップグレードに失敗してロールバックしたのですが、本番環境ではなんとかロールバックすることなくアップグレードを終えることができました。
本番導入時に発生したトラブル
このように長い準備期間を経てHDFSのメジャーバージョンアップを実施したのですが、本番導入後に複数のトラブルが発生してしまいました。本記事では、それらのトラブルの中から2つ抜粋して紹介します。
直近分のデータ転送が終わらない
“クラスタ分割方針の検討”で書いたとおり、メンテナンスでコピーするデータ量をなるべく抑えて現実的な時間で終わる見込みにしていましたが、実際には想定していた時間を何時間もオーバーすることになり、メンテナンス時間も大幅に延長することになりました。
DistCpというHadoop MapReduceジョブを利用することで並列にデータコピーしたのですが、DistCpでは「どのファイルおよびディレクトリをコピーするか決める処理」が最初に実行されます。この処理は並列化されていないため、データ量がそれほど多くない場合でもファイル数やディレクトリ数が非常に多い場合はこの処理だけで数十分もの時間がかかってしまいます。DistCpで多数のファイルおよびディレクトリをコピーするときには処理対象となるディレクトリを細かく分けてDistCpジョブ自体を並列に実行するとよい、というのがここで得られた知見です。 それ以外にもDistCpには罠となりうるオプションが多く、オプションやパスを間違えてしまうと消えてはいけないデータが上書きされる、あるいは削除されるなど取り返しがつかなくなります。開発環境などで実際にコマンドを実行して挙動を正確に確認しておくことが必須です。
DataNodeのNW負荷によりジョブが失敗する
メンテナンス直後から、ジョブが失敗するようになったという報告が複数あがるようになりました。調査の結果、Cluster 2のDataNodeのネットワーク帯域(25Gbps)が使い切られた状態であることがわかり、これがジョブ失敗の原因でした。
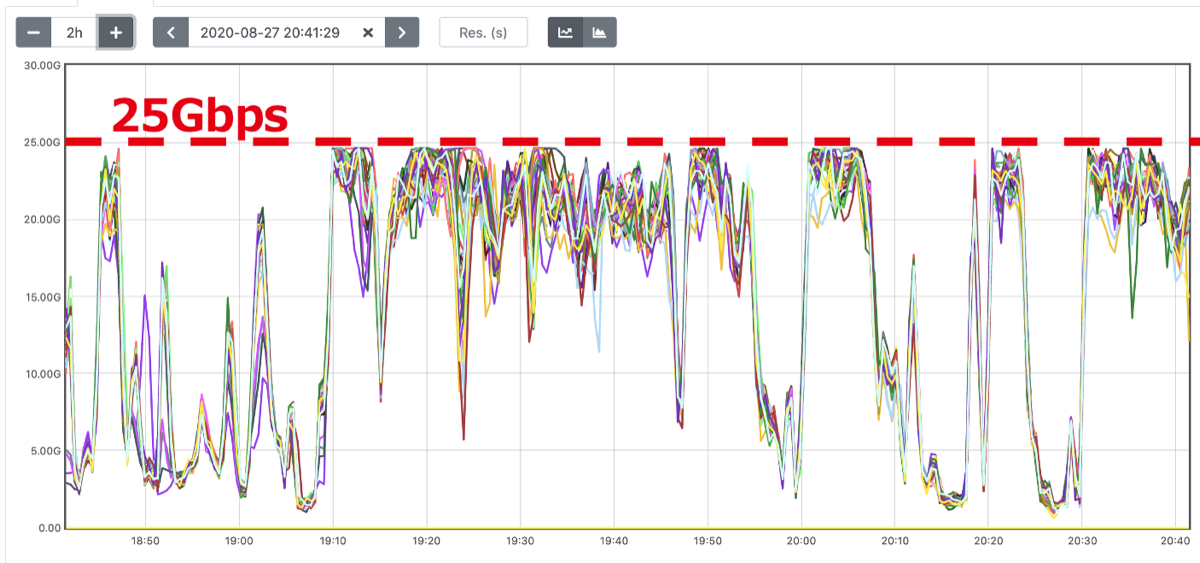 図4. アップグレード直後のDataNodeのoutトラフィック
図4. アップグレード直後のDataNodeのoutトラフィック
“クラスタ分割方針の検討”において各クラスタのNameNodeへの負荷については考慮されていましたが、DataNodeへの負荷については特別な考慮がなされておらず、単純にディレクトリの容量だけでDataNodeの台数を決めていたのがこのトラブルの原因でした。この件については、本番稼働させずに余剰に確保していたDataNodeをCluster 2に追加することで応急処置としました。DataNodeの台数が増えて負荷が分散されたことでネットワーク帯域を使い切るようなことにはならずジョブの失敗もなくなりましたが、引き続きCluster 2のDataNodeに負荷が偏る状況が続いています。この状況をうまく改善していくのが今後の課題です。
バージョンアップで得られた成果
今回のバージョンアップの成果として以下の3点があげられます。
1. あと5年戦えるデータ基盤になった
“バージョンアップの経緯”で述べたとおりHDFSにたまるデータ量は増え続けていくため、ほぼ無制限にスケールアウト可能なことが重要になっています。今回のアップグレードにおいてRBFを導入したことで、ボトルネックとなっていたNameNode自体も台数を増やしてスケールアウトさせられるようになりました。10年先ともなるとちょっとよくわかりませんが、あと5年はこのアーキテクチャでも耐えられるのではないかなと考えています。
また、HDFSのメジャーバージョンアップによりErasure Codingというデータの冗長性を担保しつつも実データ量を節約する仕組みを本格導入できるようになる見込みが立てられました。ヤフーでは2017年にErasure Codingの記事を執筆しておりそこですでに本番運用していると書いたのですが、その後クリティカルなバグを踏んでしまったため本番運用を停止していました。今回のバージョンアップでHDFSが最新バージョンに上がったことで、Erasure Codingについても多くのバグが修正されているため再び本番環境に導入しようと考えています。
HDFS Erasure Codingの紹介とYahoo! JAPANにおける運用事例
2. GCによる停止時間が大幅に短縮した
アップグレード前はNameNodeでmixed GCが発生するたびにフェールオーバーしていたのですが、現在はmixed GCは数秒で完了していてフェールオーバーはなくなりました。これはJava 11にアップグレードしたことによる効果だと考えられます。私が2018年に中途で入社したときにはすでにこの問題が発生していてアップグレード前までずっと残っていたので、この問題が解決して本当に良かったと思っています。
3. OSSコミュニティーの力をさらに活用できる環境になった
HadoopをOSSコミュニティー版の最新バージョンに上げたことで、コミュニティーに投稿されているパッチを適用しやすくなりました。 また、何らかのバグを踏んでしまいコミュニティーに報告するときも、最新版のリリースで発生しているバグであれば、開発者からほぼ確実に何らかのアクションをもらうことができます。わざわざ自分でパッチを書かなくてもバグを修正してもらえる可能性は高いでしょう。もし仮にEoL(End of Life)のバージョンを利用していたとすると、バグ報告をしても開発者からは見向きもされないことが多いです。
補足. リクエスト数増加に伴うNameNodeのキューあふれについて
NameNodeのキューあふれについては、実はバージョンアップ前にHadoopクラスタが配置されているデータセンターを移行してハードウェアを刷新したタイミングで、突発的な負荷によるもの以外は解消しました。 そのうえで、今回のバージョンアップおよびRBF導入によって複数のHDFSクラスタにリクエストを分散させているため、さらに多くのリクエストがユーザーから発行されても耐えられるようになっています。 ちなみに、このデータセンター移行は旧データセンターのサーバーを新データセンターのサーバーに徐々に交換していくという方法でクラスタ停止を伴わずに実施しており、この移行もHDFSのバージョンアップと同様かそれ以上に困難な取り組みでした。また、突発的な負荷についてはあるユーザーが大量にHDFSにリクエストを投入するジョブを(故意ではなく)うっかり実行したことによるものがほとんどです。この突発的な負荷については、Fair Call Queueという、大量にリクエストを投入するユーザーの処理優先度を下げる仕組みを導入して解決していこうと考えています。
今後の展望
今後HDFSクラスタをさらに増やしていくことになると、HDFSクラスタをまたいでデータを再配置する必要性がさらに高まっていきます。現在HadoopコミュニティーではRBFにおいてデータの再配置を自動で実施するツール(HDFS-15294)が実装されています。このツールは以下の3ステップの処理を実行します。
- DistCpとHDFSスナップショットを利用して、移動元と移動先のdiffがなくなるまで同期し続ける
- DFSRouterのマウントテーブルを更新する
- (必要であれば)移動元のデータを削除する
また、さらに高速にデータを再配置し、一定の条件下ではHDFSクラスタをまたぐrenameすら可能になる実装がXiaomiにより提案されており(HDFS-15087)、こちらについても非常に興味を持っています。この実装には1つ注意点があって、DataNodeは図4の右側のように複数のHDFSクラスタで共有している必要があります。
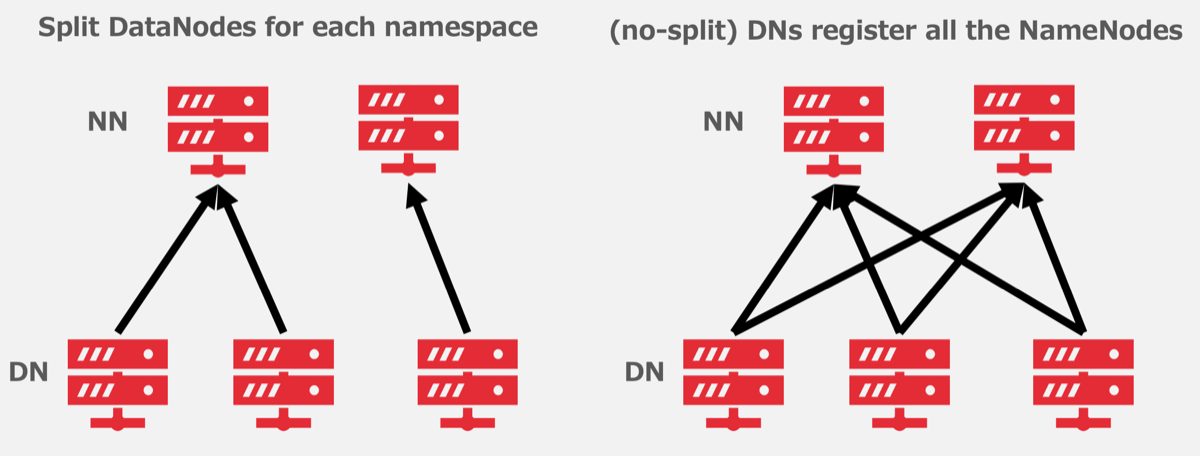 図5. FederationにおけるDataNodeの設定
図5. FederationにおけるDataNodeの設定
しかしながらDataNodeを共有させるとこれまでの運用が大きく変わってしまうことになるため、現時点では図5の左側のようにクラスタごとにDataNodeを分けて利用しています。 とはいえ、複数NameNodeからDataNodeを共有するのであれば”本番環境で発生したトラブル”で紹介したようなクラスタ間でのDataNodeの負荷の偏りが解消されるという大きなメリットがあるため、今後挑戦してみたいと考えています。
おわりに
本記事とほぼ同様の内容についてLINE Developer Meetup #68とApacheCon @Home 2020で発表しました。資料と動画が公開されているため、興味があるかたはこちらもぜひご確認ください。
チームの同僚および社内Hadoopユーザーの多大な協力があって、この困難なHDFSのメジャーアップグレードを無事完了させることができました。本当にありがとうございました。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 鯵坂 明
- Hadoop黒帯
- Apache Hadoopを開発しています。
-



