こんにちは、社内IaaS(Infrastructure as a Service)の構築・運用などを行っている奥野です。私たちのチームはヤフー内のIaaS基盤の開発及び運用を担当しています。
IaaSとはサーバーやストレージ、ネットワークといったインフラリソースを仮想的に定義し、ユーザーへ提供するサービスです。ヤフーのIaaS基盤は社内のユーザーやサービスに対して幅広く提供しており、ヤフーがエンドユーザーに対して公開している多くのサービス(Yahoo!ニュースや、ヤフオク!など)もこのIaaS基盤を利用しています。
本項では、「構築編」と「運用編」という前後編でこのヤフーのIaaS基盤についてご紹介します。
本記事では「運用編」として大規模なIaaS基盤を少人数で運用するために工夫していることや、より良いIaaSを提供するために行っていることを大きく「監視・アラート対応」と「仮想化推進」の二つにわけてご紹介します。
監視・アラート対応編
構築編で説明しましたが、プライベートクラウド基盤で利用しているOpenStackクラスタ数は200以上あります。そこで利用されている親機(ハイパーバイザーが動作している物理サーバー)に至っては2万台を超えている状態です。監視・アラート対応編では、これらの基盤を少人数で効率良く運用するために行っていることを紹介したいと思います。
まず簡単に私が所属するクラウドチームのチーム体制について説明します。チームのタスクとしては検証・開発・構築・運用といったプライベートクラウド基盤に関わるタスクであれば全て行っています。チーム人数はざっくり20人強です。運用はたしかに重要なのですが、チームとしては運用に要する工数をなるべく減らし、その分システムの改善・新規機能の提供に力を入れたいと考えています。また誤解のないように説明しますと、20人強でネットワーク・ストレージ・データセンタなどのインフラ全てを見ているわけではなく、ネットワークはネットワーク専門のチームがおり、ストレージにはストレージ専門のチームが存在し、各分野にて分業しています。その中で私たちは必要な機材を組み合わせてクラウド基盤を構築し運用しています。クラウドチームでは主にOpenStackと親機の運用を担当しています。
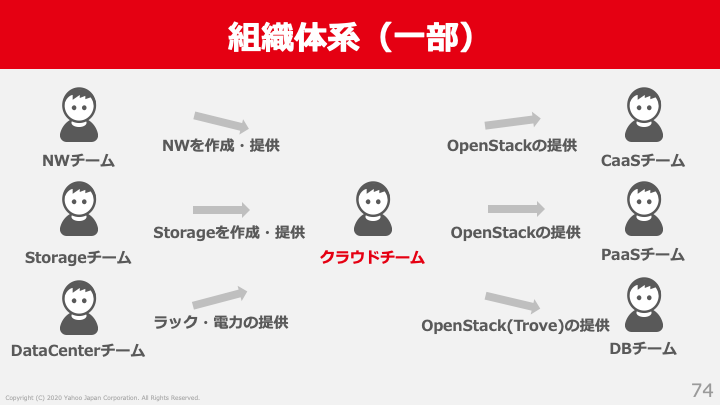
少人数で効率良く運用するために以下のことを行っています。
- アラートを出さない。アラートを出す必要のないような障害に強いシステムを構築します。
- アラートの対応を減らす。アラート発生時のフローなどを改善することにより、アラートに要する工数を減らします。
- アラートを常に見直す。監視の内容は必要十分にし、必要のないアラートは出さないように常に監視内容を見直します。
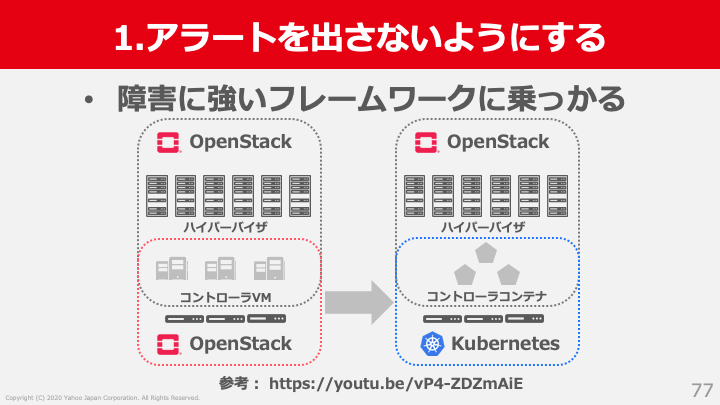
アラートを出ないような障害に強いシステムを作る
機材は必ず壊れてしまいます。多少サーバーやスイッチなどが故障しても自動で復旧し、緊急のアラートとして対応しなくてよいシステムが理想です。そんな障害に強いシステムを作るために、私たちは障害に強いフレームワークに乗ることにしました。障害に強いフレームワークとしてKubernetesを採用し、OpenStack on Kubernetes構成にすることでコントローラーのアラートは大きく削減できました。OpenStackコントローラーをKubernetes上にデプロイする話は、過去の記事がありますので詳細は割愛します。興味のある方はこちらをご参照ください。OpenStackのコントローラをKubernetes上にデプロイする
対応フローを見直すことによりアラート対応を減らす
OpenStackコントローラーはコンテナ化し、Kubernetesによって守ることができました。ただ親機やコンテナ化できない周辺システムなどはそういうわけにもいきません。アラート対応のなかにはクラウドチームが直接対応しなければならないケースと、確認や依頼を出すだけのようなアラートが存在します。前者は対応すべきアラートで問題はないのですが、後者は対応フローの改善で減らすことが可能です。以前のクラウドチームでは親機が落ちた場合に直接アラート連絡が来るフローが存在していました。具体的なフローは以下の通りです。
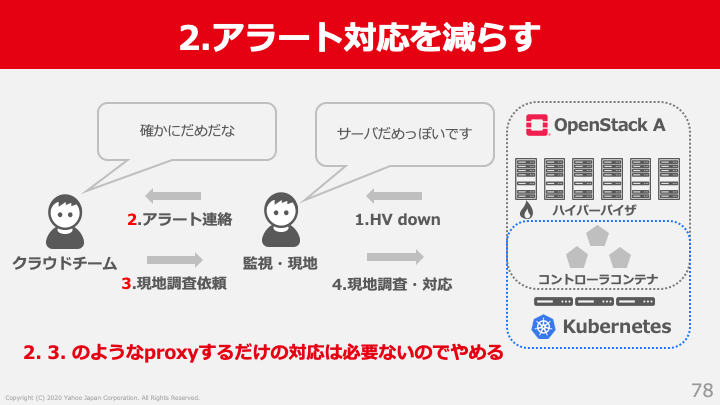
- 親機Downが発生
- 現地・監視からクラウドチームに連絡がくる
- サーバーの状態を確認し、必要に応じて現地にサーバー物理故障の調査依頼を出す
- 現地サーバー物理故障調査・対応
- 親機復旧確認後、親機をサービスインさせる
親機のDownの理由はハードウェアの問題に起因していることが多いです。そのような場合にクラウドチームはアラートを確認し、ただ依頼を出し、アラートをプロキシするような対応でした。このフローを改善し親機が落ちた場合にクラウドチームに連絡を来るようにするのをやめて、現地だけで復旧できるフローに改善しました。もちろん、ソフトウェアが原因の場合には私たちが直接調査して解決まで行います。
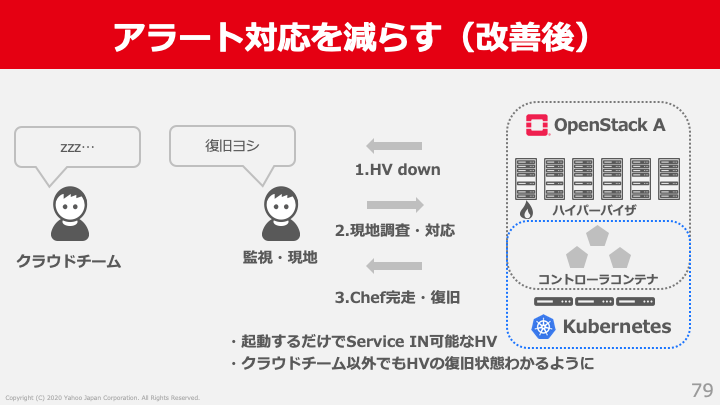
- 親機Downが発生
- 現地・監視が検知し、そのままサーバー物理故障調査
- サーバー物理故障調査完了後、親機が正常であればそのままサービスイン
この事例ではフローの改善だけではなく一部システムの改善も入っていますが、このように確認するだけや依頼するだけのようなアラートは、フローやシステムを一緒に改善することによって減らしてきました。
不要なアラートを出さないように監視内容を常に見直す
監視内容の追加というのは常に行われるものです。新規システムの導入時にはそのシステムの監視で必要と想定されるもの全てが追加されます。既存システムで問題が発生し、監視が足りないとなったときにも追加されていきます。その結果、監視には多くの過剰な監視が発生します。
前提として過剰な監視は、監視が漏れるよりは良いと考えています。これはもちろん問題が発生しても気づけないケースが最もシステムへの影響が大きいためです。しかし、単純に監視を追加し続けると、不要な監視や重複した監視が発生し、それにより不要なアラートがあがることがあります。不要なアラートというのはそれだけで手間を発生させます。そのため、監視内容は常に必要十分条件であるか見直す必要があります。
私たちは四半期や半期のペースで監視が必要十分に行われているかの見直しを行なっています。その見直しの結果、毎回30件ほどの監視内容が廃止になっています。システムに日々多くの変更が行われると同時に、必要とされる監視もまた日々変わってきています。システムの変更に対してその監視も柔軟に追従することが大切です。
仮想化推進編
ここからは少し監視・アラート編とは相反する内容についてお話しします。運用の省力化を考えるとIaaS基盤で使用する親機には同じ構成・設定のサーバばかりを使用した方が理想的です。違う構成が存在するとその分だけ設定管理、監視内容、運用方法などが異なり、運用コストが上がることになります。しかし、現実にはさまざまな構成が必要です。その理由としてはさまざまなワークロードを可能な限りVM化(仮想サーバー化)を進める必要があるからです。
クラウドチームの大きなミッションの一つに既存の物理サーバを仮想化し、社内の物理サーバを減らすというものがあります。仮想化はユーザーとクラウドチーム双方にとって以下のようなメリットがあるためです。
- VM化してサーバーの可搬性・抽象性を高くする(マイグレーションやスケールアップ・アウトなどを容易にする)
- ユーザーはハードウェア管理から解放される
- サーバーコスト・データセンタ運用的に優位
このメリットのうち、上の2つはパブリッククラウドでもよく言われているものです。3つ目のサーバーコスト・データセンタ的に優位というのは、IaaS基盤の親機の中に複数のVMを高い集約率で収容し、その親機をラック内に効率よく収容することでコスト面やデータセンタ運用の面で生まれる大きなメリットを指します。例えば、2016年製の物理サーバが3ラック分存在し、これを2019年製の親機上でVM化すると1ラックに収容することが可能という事例も存在します。ラックや電源といったデータセンター設備は有限ですのでこれらをより効率的に使うために仮想化による集約を推進しています。社内にはIaaS基盤の親機以外の物理サーバもまだまだ大量に存在するため、ゆくゆくはこれら全てを仮想化しユーザーとクラウドチーム双方にとってメリットのある未来を目指していきたいと考えています。
しかし、現在も物理サーバーを使っているユーザーやサービスにはそれなりの理由があるというケースがほとんどです。例えば、非常にCPU性能が重視されるサーバーや、ネットワークレイテンシが重要なサーバー、大量の物理ディスクを搭載したサーバ、特殊な構成を利用したサーバーなど、多岐にわたるパターンが存在しています。こういったサーバー郡もなんとかVM化し、コストメリットを出すことが我々クラウドチームには求められています。ただ単純に既存の物理サーバーを親機化して、その中に1VMだけ作るような構成にしては意味がありません。IaaS基盤の汎用的な親機サーバーを利用し、ユーザーとともにパフォーマンスチューニングや特別な設定を行い、ユーザーの求める性能要件を満たせるように環境を構築します。その結果、特定のユーザーやサービス専用の環境や構成が増えることにもなります。
仮想化推進事例
どのようにして専用環境が増えていくのかを、事例を元に説明していきたいと思います。まずはVM化したいときにユーザーの要望をヒアリングします。今回の事例では、ユーザーの要件の以下の通りでした。
- ネットワークレイテンシは重要
- 1VMで25Gbps or 100Gbpsのネットワーク帯域を出したい
- 親機側で通信制御をかけてほしい
- CPUも高負荷になるくらいに使う予定
- 1親機に数VMでOK
今回の場合はHadoop系のシステムの一部で利用するため、ネットワーク周りの要件が非常に重要な環境でした。通常の構成ではもちろん要件を満たすことができませんでした。そこで、検証中技術などを利用することで性能要件を満たせるようにしました。要件を満たすために利用した技術・構成は以下の通りになりました。
- ネットワークレイテンシは重要→OVS-TC(Open vSwitch Traffic Controll) hardware offload, SR-IOV(Single Root I/O Virtualization), NIC(Network Interface Card) passthrough
- 1VMで25Gbps or 100Gbpsのネットワーク帯域を出したい→SR-IOV, NIC passthrough
- 親機側で通信制御をかけてほしい→OVS-TCの機能利用して通信を制御
- CPUも高負荷になるくらいに使う予定→CPU pinning
その結果、対象システムでは従来環境より1.5倍の性能を出すことができたと嬉しい連絡をもらえました。ただSR-IOVし、NICをpassthroughしたことによりVMの構成が親機と密結合になり、VMをマイグレーションなどが困難になるというデメリットもあります。通常の汎用環境では受け入れられないデメリットですが、この環境のユーザーはこのようなデメリットがあっても問題ないとのことで導入可能でした。そうしてこのような専用環境が生まれます。
増える専用環境とその対応
このようにして増えた専用環境は数十に及びます。しかし、全てはユーザーのために必要な環境を提供することが大切です。増えれば増えるだけ、管理工数が増えるのは事実なのですがこういった厳しい要求や専用環境は新しい技術の挑戦の場所でもあります。先ほど挙げたように、検証中のOVS-TCなどの新しい技術を、ユーザーとともにパフォーマンス・機能要件・信頼性などを実際のワークロードを元に確認しながら入れることができます。こういった新しい技術は常に積極的に試しながら、状況によって使い分けていっています。もちろん、この増えた専用環境・特別設定を管理するためにInfrastructure as codeは必須です。
運用コストも重要ですが、オンプレの良いところは伸ばしていきたいと考えています。具体的には、先ほど挙げたようなサービス個別要件に特化した専用環境の提供やユーザーの性能要件を満たせるように、パフォーマンス最適化をユーザーとともに行っていくことなどです。また新しい技術を積極的に試しながらVMの受け入れ可能な幅を常に広げる努力を行っています。
まとめ
少ない人数で大規模環境を運用するためには、アラートや監視の部分で運用コストを減らす工夫をしています。アラートを出さないようなシステム作り、アラート対応フローの見直し、監視の見直しの事例について紹介しました。 また、どんなVMでも受けられるように技術の検証・導入を進めていることについてお話しました。
このように、ヤフーのIaaS基盤は大量のキャパシティが必要とされると同時に、高い基準の性能と可用性が求められるIaaS基盤です。
このような大規模の環境を安定して運用し、よりユーザーに高い品質のリソースを提供するため、プライベートクラウドチームは常に改善と挑戦を続けています。
本項は2020年07月29-30日に開催されたCloud Operator Days Tokyo 2020でのヤフー株式会社の講演を記事化したものです。
YouTubeにて本講演のアーカイブも配信されておりますので、ご興味のある方はそちらもご参照ください。
Cloud Operator Days: https://cloudopsdays.com/
本講演のアーカイブ配信URL: https://www.youtube.com/watch?v=tx_pG8cqbSw
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 奥野 修平
- インフラエンジニア



