こんにちは。ヤフー株式会社のシステム統括本部に所属している奥村です。現在、私はシステム統括本部内でプライベートクラウドを担当しています。私たちのチームはヤフー内のIaaS(Infrastructure as a Service)基盤の開発及び運用を担当しています。
IaaSとはサーバーやストレージ、ネットワークといったインフラリソースを仮想的に定義し、ユーザーへ提供するサービスです。
ヤフーのIaaS基盤は社内のユーザーやサービスに対して幅広く提供しており、ヤフーがエンドユーザーに対して公開している多くのサービス(Yahoo!ニュースや、ヤフオク!など)もこのIaaS基盤を利用しています。
本項では、「構築編」と「運用編」という前後編でこのヤフーのIaaS基盤についてご紹介します。
本記事では「構築編」としてIaaS基盤の設計ポリシーや、大量なサーバーからなるIaaS基盤をどのようにして効率的に構築しているかをご紹介します。
ヤフーのIaaS基盤について
まずはヤフーのIaaS基盤全体の概要について簡単にご紹介します。
ヤフーのIaaS基盤はその規模の大きさが特徴として挙げられます。
VM(仮想サーバー)数は17万台を超え、それらのVMは2万台を超えるサーバー(親機)上で起動されています。
それらのサーバーのラッキングには1000台以上のラックが使用されています。
IaaS基盤の管理にはOpenStackが使用されており、ヤフー全体では200を超えるOpenStackクラスタが存在します。
ハイパーバイザーとしては主にKVM(Kernel-based Virtual Machine)が使用されていますが、ごく一部の限られた環境ではVMware vSphereも採用されています。
これら全てがオンプレで、主に自社のデータセンターで運用されています。
OpenStackとその提供形態
OpenStackはIaaSリソースを作成・管理するためのOSSです。
OpenStackによって、ユーザーはWebコンソールやCLI、APIなどさまざまなI/Fを介してリソースを操作できます。
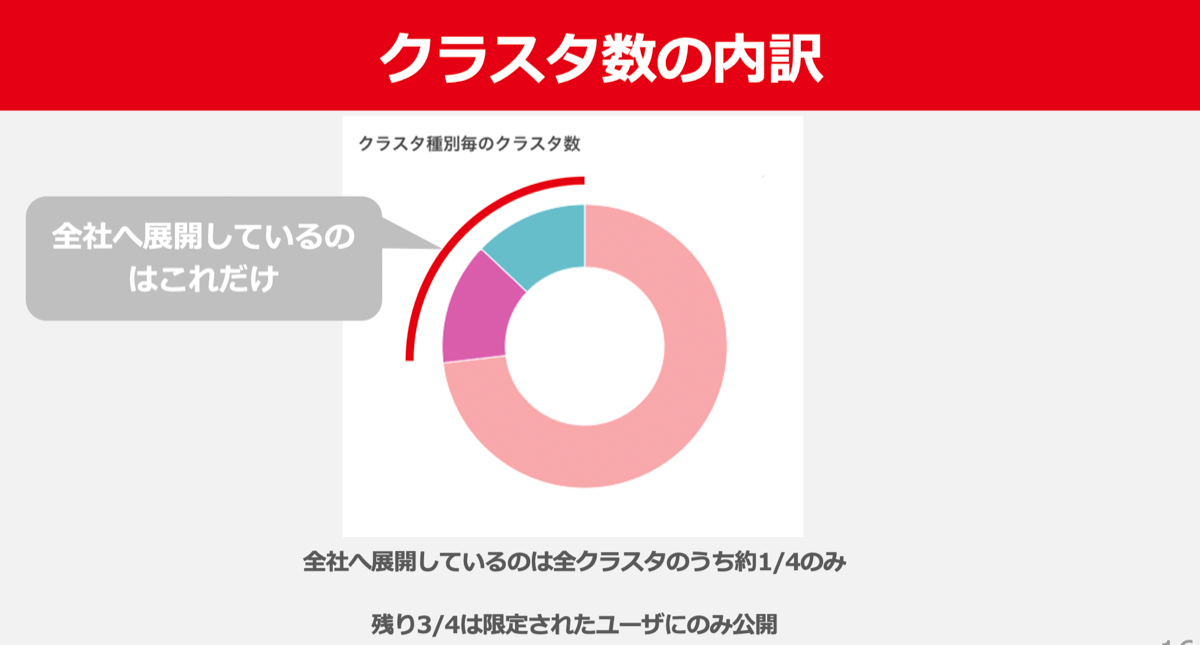
前述の通り、ヤフーのIaaS基盤にはこのOpenStackのクラスタが200以上存在します。
これだけ多くのOpenStackクラスタが存在するのは、全社向けに公開されているクラスタ以外にも特定の環境や特定のユーザー向けに提供しているクラスタが多数存在しているからです。
プロダクション用環境と開発環境ではクラスタを分けていたり、一部の大規模なサービス専用のクラスタが存在していたり、CaaS※1やPaaS※2といったプラットフォームのIaaS基盤としても専用のクラスタを提供しています。
こういった理由が積み重なった結果、現在のように200以上のクラスタが作られることになりました。
いわば、より”プライベートな”プライベートクラウド環境が多数存在することが、ここまでOpenStackクラスタの数が膨れ上がった大きな理由です。
そのため、ヤフーのプライベートクラウドチームは本質的にはいわばOaaS(OpenStack as a Service)のようなかたちでIaaSを提供しているとも言えます。
※1 Container as a Service
※2 Platform as a Service
IaaS基盤の主要ユーザー
ヤフーには大小さまざまなサービスが存在しますが、どのようなサービスがIaaS基盤を多く利用しているのかをリソース量ベースでランキングしてみました。
- 全文検索サービス
- 広告
- PV計測
- Yahoo!ショッピング
- ヤフオク!
- ストリーム処理プラットフォーム
- GYAO
- 通知
- Yahoo!ニュース
- Yahoo!トラベル
太字で表示されているサービスはエンドユーザーへは直接提供していない、社内でプラットフォームとして開発者へ提供されているサービスを指しています。
こうして見ると分かる通り、エンドユーザーへ提供しているコンシューマサービスだけでなく、そのバックエンドとなるプラットフォームにも大量のリソースが使われているという事実が見えてきます。
特に近年はサービス間の高度なデータ連携や、より優れたユーザー体験実現のための詳細なサービス計測がシステムのバックエンドで行われているため、バックエンドシステムで必要なコンピュートリソースは急速に増加傾向にあります。
構築編
ここから先は本題であるIaaS基盤の舞台裏の構築編として、実際のIaaS基盤構築時の流れを基にわれわれのIaaS基盤の設計上のポリシーや効率的に構築を行うために工夫している箇所をご紹介します。
クラスタ構築の流れ
1つのIaaSクラスタを構築する際には、以下のフェーズを経てリリースされます。
- 設計、サーバーの選定
- 見積もり、購入
- 設置
- セットアップ
- デプロイ
- テスト
サーバー数百台からなる大規模なIaaSシステムであっても、システム構築の段取りは通常の一般的なシステムとそう大きな違いはありません。
まずは1つ目のフェーズである「設計、サーバーの選定」において、どのような観点でサーバー(親機)を選んでいるかをご紹介します。
サーバー(親機)の選び方
ここで言うサーバーとは、ユーザーへ提供するVMの親機を指しており、KVMやvSphereといったハイパーバイザーが動作するサーバーです。
一般に、クラウドの親機として利用するサーバーでは以下のような性能が重要視されます。
- 価格
- 高集約
- 低電力
- 高信頼性
- メンテナンス性
- 調達性
- サポート力
これらの性能はわれわれのIaaS基盤でも当然重要視されます。特に1ラックあたりの電力量がシビアな環境が多いため、電力あたりの性能は非常に重要です。
また、一度の発注で最大で数千台のサーバーを購入することもあるため、目標とする納期に納入可能かどうかに影響する調達性という部分も重要です。
ここで挙げたような性能も当然重要ですが、長い目で見ると別の視点も現れてきます。
それは、なるべくサーバーの種類を増やさないというものです。
ヤフーのデータセンターでは数万台以上のサーバーを管理しているため、サーバー故障時の保守交換は基本的に現地のNOC(Network Operation Center)が行っており、交換用の保守パーツもデータセンターにて管理されています。
そのため、発注ごとにスペックを変えむやみにサーバーの種類を増やしてしまうと管理すべきパーツの種類も増え、NOCの運用負荷が増大します。
これらの運用コストは場合によってはイニシャルコスト以上の負担となってしまうため、慎重に見極める必要があります。
ヤフーのIaaS基盤に存在する2万台のサーバーも、その種類が10種類しかなければ運用もスケールさせやすいですが、もしその種類が100種類にもなればサーバー運用はほぼ不可能になってしまいます。
サーバーの種類が増えてしまうとIaaS基盤のリソース管理も複雑化します。
サーバーごとにスペックがバラバラの状態ではユーザーも自身が起動するVMがどんな性能のサーバーが起動するのか分からなくなってしまう※1ため、いわゆる”インスタンスガチャ”の引き金となってしまいます。
これらの問題を回避するため、ヤフーのIaaS基盤ではサーバーのスペックはCPU世代※2ごとに固定し、それ以外のスペックではサーバーを購入しない決まりになっています。CPUアーキテクチャの見直しは年1回行われますので、サーバーのスペック変更も結果的に年1回行われることになります。
※1 仮想化環境では同一のflavorを使用してVMを起動しても実際のVMの性能は親機側の性能に大きく左右されます
※2 CPU世代とは、Intel XeonであればCascade lakeやIce lake、AMD EPYCであればRomeやMilanといったCPUアーキテクチャごとの世代を指します
リソースの割り当てポリシー
それでは、前項で選定したサーバー(親機)に対してどのようなポリシーでVMのリソースを実際に割り当てているのかをご紹介します。
まずは、IaaS基盤におけるリソース割り当てポリシーの例を以下に示します。
- あるCPUコアを物理的に単一のVMに占有させるのか、複数のVMに共用させるのか
- VMのルートディスクは集約ストレージ上に置くのか、サーバーのローカルディスクに置くのか
これらのポリシーは言うまでもなくVMの性能とクラスタ全体のキャパシティー、コスト効率に直結する非常に重要な設計部分です。
CPUリソース
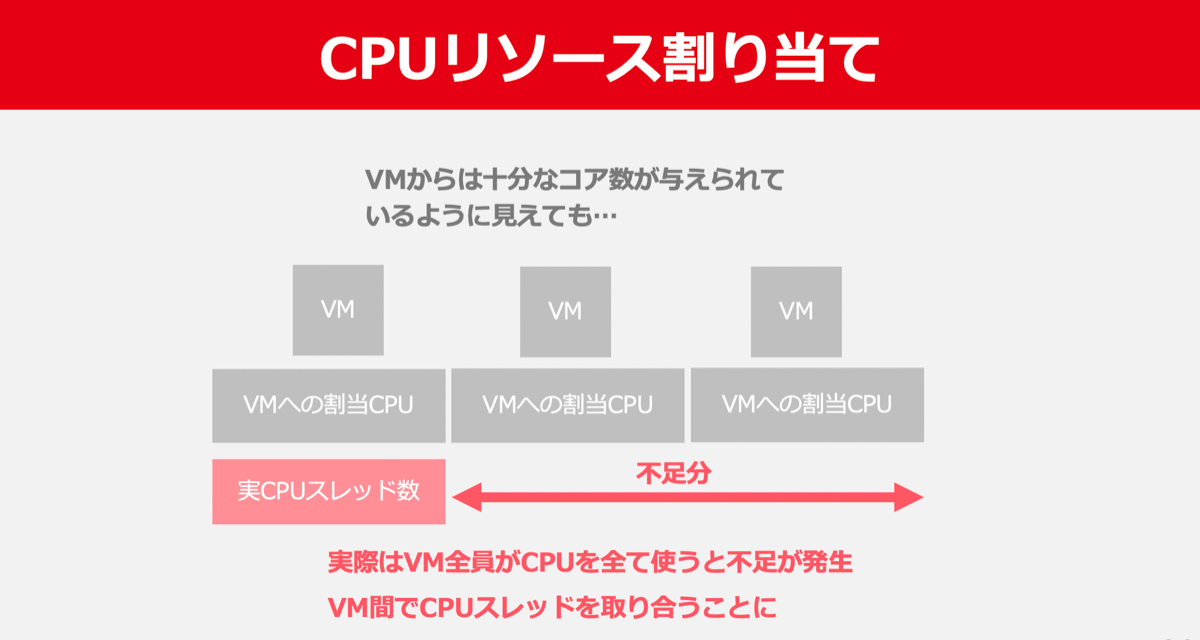
CPUに関しては結論から言うと実CPUスレッド数の3倍までVMのCPUを割り当てています。
仮にサーバー(親機)に搭載されたCPUスレッド数が100ならば、そのサーバーで動作するVMのトータルvCPU数は300まで許可されます。
この3倍という数字はこれまでのIaaS基盤での運用における経験から「この程度であれば大丈夫」という倍率を経験則で導き出しています。ただし、近年はCPUの高集約化が進んだため3.5倍や4倍という倍率も使われ始めています。
あくまでもヤフーのIaaS基盤の負荷、ひいてはヤフー全体のワークロードを前提としているため、どのようなIaaS基盤であってもこの数字がリスクなく適用できる訳ではないことには注意が必要です。
しかし、こういった環境で起動したVMは非常に高い負荷がかかった場合に2つの大きな問題が発生します。
1つ目の問題は、他VMとCPUを共用していることからflavorに設定されたvCPU数相当の性能を100%発揮できないという点です。
2つ目の問題は、この負荷の高いVM自身がノイジーネイバーとなり他のVMに深刻な影響を与えることです。
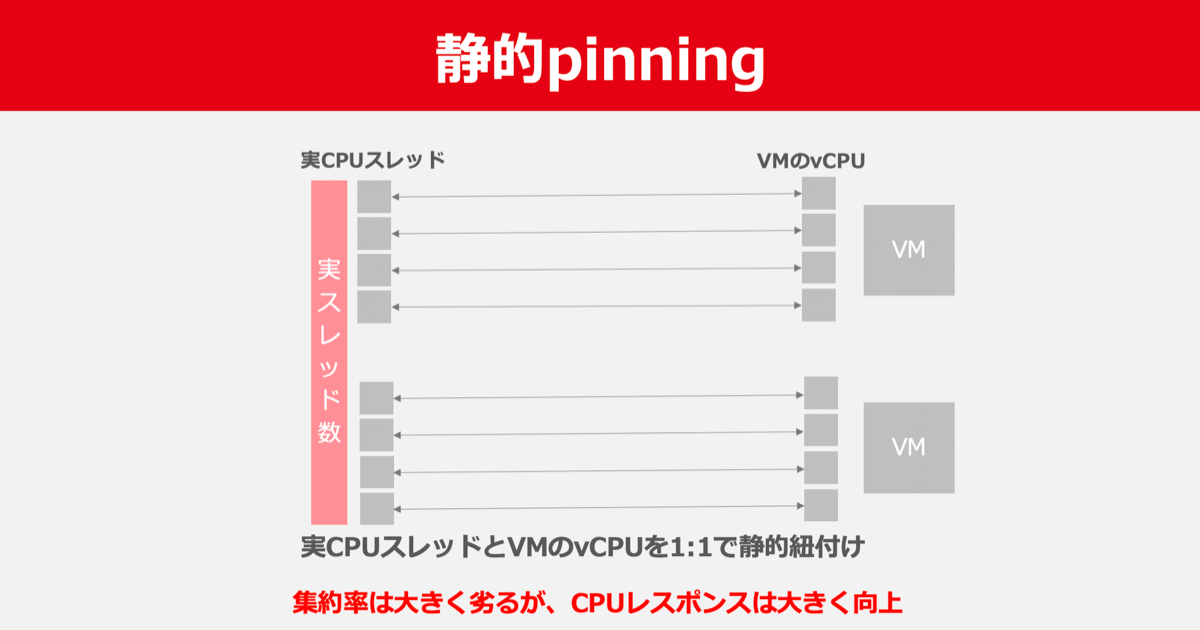
そのため、そういったワークロードを持つユーザーのために静的にサーバーのCPUとVMのCPUをpinningした環境も用意しています。
こういった環境は主に広告配信システムなど、非常にシビアなレイテンシが求められるサービスに使用されています。
こうすることで集約率は大きく劣りますが、CPUレスポンスは大きく向上させられ、通常のVM環境では食えないようなワークロードも収容できるようになります。
diskリソース
続いてはdiskリソースのポリシーです。
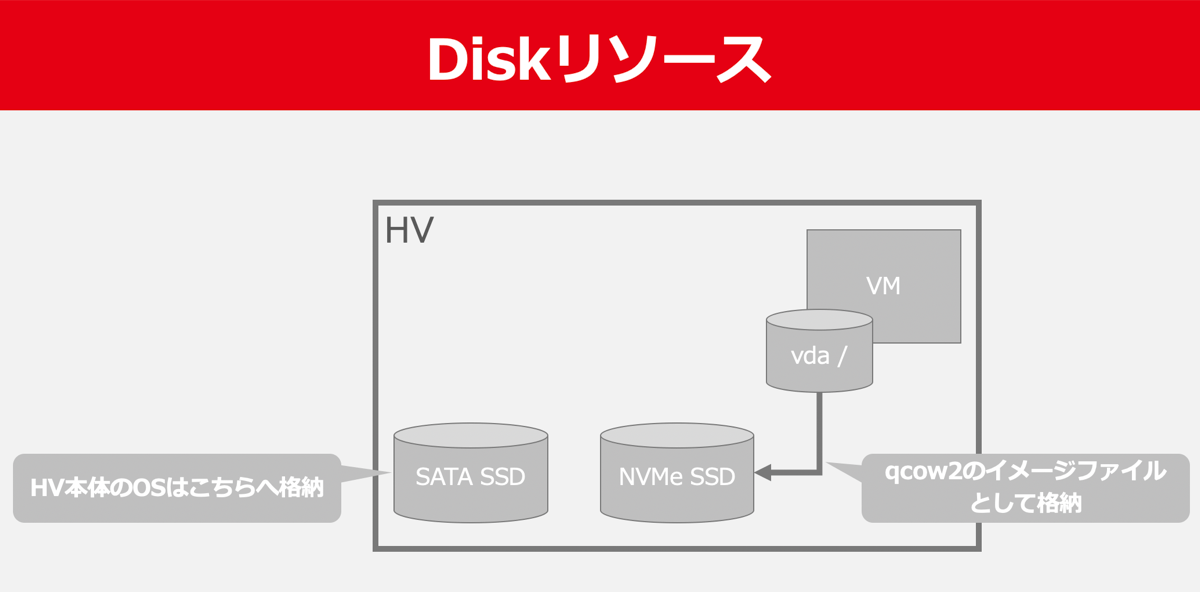
ヤフーのIaaS基盤ではVMのルートディスクのデータは基本的にはサーバー(親機)のローカルディスクへ保存しています。
VMのデータを格納しているローカルディスクは非RAID構成ですので、ローカルディスクがデータロストすれば当然VMのデータもロストするという設計です。
サーバーには低速なSATA SSDと高速なNVMe SSDの2つのローカルディスクが搭載されており、サーバー本体のOSはSATA SSDへ、VMのデータはNVMe SSDへ格納しています。
VMのルートディスクは実際にはqcow2のイメージファイルとしてサーバーのNVMe SSDに格納されています。
前述の通り、VMのデータを格納するディスクはRAID構成にはなっておらず、原則NVMe SSDの1本構成になっています。
ですので、必然的にVMのデータロストはディスクの故障と同確率で発生することになります。
これは高いコストを払ってディスクを冗長化するよりは、利用者がVMのデータロストが発生しても問題ないシステムアーキテクチャを採用する方が建設的であるという考えのもと、こういった構成になっています。
ですので、ヤフーのIaaS基盤を利用するユーザーはVMのデータロストを前提とした分散アーキテクチャの採用が不可欠になっています。
こういったデータロストのリスクを抱えてまでローカルディスクを使う理由は、アプライアンスの集約ストレージと比較して次の大きな3つのメリットがローカルディスクにはあるためです。
- I/Oが非常に高速
- 安価
- 分散アーキテクチャとの相性が良い
まず、I/Oが非常に高速であるという点です。
PCIe3.0のエンタープライズ向けのNVMe SSDではシーケンシャルリードで5GB〜6GB/sec、10万IOPSの性能を実現できています。
このような高速なディスクを使用することで1台のサーバーに多数のVMを収容しても1VMあたりの性能劣化を抑えられるため、CPUリソースの項目で話したような集約効率を高める設定をより活かすことができます。
仮にアプライアンスの集約ストレージ上にVMのデータを格納した場合、各々のVMに対してローカルディスク環境と同等のIO性能を割り当てることは非常に困難です。
2点目に安価であるという点が挙げられます。
近年、大容量のNVMe SSDは低価格化が進み、非常に価格がこなれてきています。
1つのIaaSクラスタのためにアプライアンスの集約ストレージを購入するよりサーバー全台にNVMe SSDを搭載した方がはるかに安価です。
最後の分散アーキテクチャとの相性が良いという点については、どちらかと言えばローカルディスク環境の利点というよりも集約ストレージの大きな問題と言えます。
クラウドネイティブな環境を前提としたソフトウェア、プロダクトは一般に並列化による分散アーキテクチャを採用しています。
そのような分散アーキテクチャが採用されたソフトウェアが集約ストレージ上のプラットフォームへデプロイされた場合、並列化された各コンポーネントのI/Oが集約ストレージに集約することになります。
これにより分散アーキテクチャの大きなメリットであるスケール性が損なわれるばかりか、障害性の観点でもシングルポイントの障害点を作ることになります。
こういった理由から、ヤフーのIaaS基盤におけるVMのルートディスクの格納にはローカルストレージが採用されています。
しかし、VMのルートディスクを集約ストレージに格納することは、ユーザーの利便性においては非常に大きなメリットが存在します(安全なライブマイグレーション、親機故障時の迅速な復旧など)。
ですが、ヤフー環境ではその利便性のために要するコストや、ローカルストレージで手軽に得られるパフォーマンスやスケール性、VMがデータロストしてもユーザー側で即座に新規のVMでデプロイを行える方が建設的であるという考え方を重視し、現在の設計となっています。

とはいえ集約ストレージがヤフーのIaaS基盤に一切存在しないわけではありません。
データが冗長化されておらずデータロストも許容できないデータを取り扱うユーザー向けに、OpenStack CinderのI/Fを介して集約ストレージ上のブロックボリュームを提供しています。
ユーザーに多様な選択肢を与えることも優れたIaaS基盤の条件の一つです。
また、SDS(Software Define Storage)などのパフォーマンスがアプライアンスの集約ストレージと比較してスケールしやすいストレージについては、今後ローカルストレージの現実的な代替案となる可能性もあるため検証や試験導入を進めています。
サーバーのセットアップ
続いて、購入したサーバー(親機)をどのようにセットアップしているかについてお話しします。
前述の通り、ヤフーのIaaS基盤は時には数千台のサーバーを同時に購入しセットアップを行います。
これらのサーバーをいかに素早くIaaS基盤の親機としてVMを起動可能な状態にできるかは非常に重要です。
OpenStack環境を特定のサービス向けに新たに用意する場合、可能な限り早く環境を使えるようにしてほしいと依頼されることも多く、発注から環境の提供までのリードタイムの短縮はユーザーメリットに直結するためです。
ヤフーではOSのインストールにはPXE bootを利用しており、PXE bootとサーバー管理システムを連携させることで任意のサーバーに対して目的のコンフィグレーション(サーバーのIPアドレスやホスト名など)を流し込んでいます。
この方式ではPXE boot時にOSインストール対象のサーバーとサーバー管理システム上の登録情報を紐付けるキーが必要となりますが、これにはMAC Addressが使用されています。
あらかじめサーバー管理システムにはサーバーごとのMAC addressが登録されており、PXE boot時にはこのMAC addressを元にサーバーに流し込むコンフィギュレーションが決定されます。
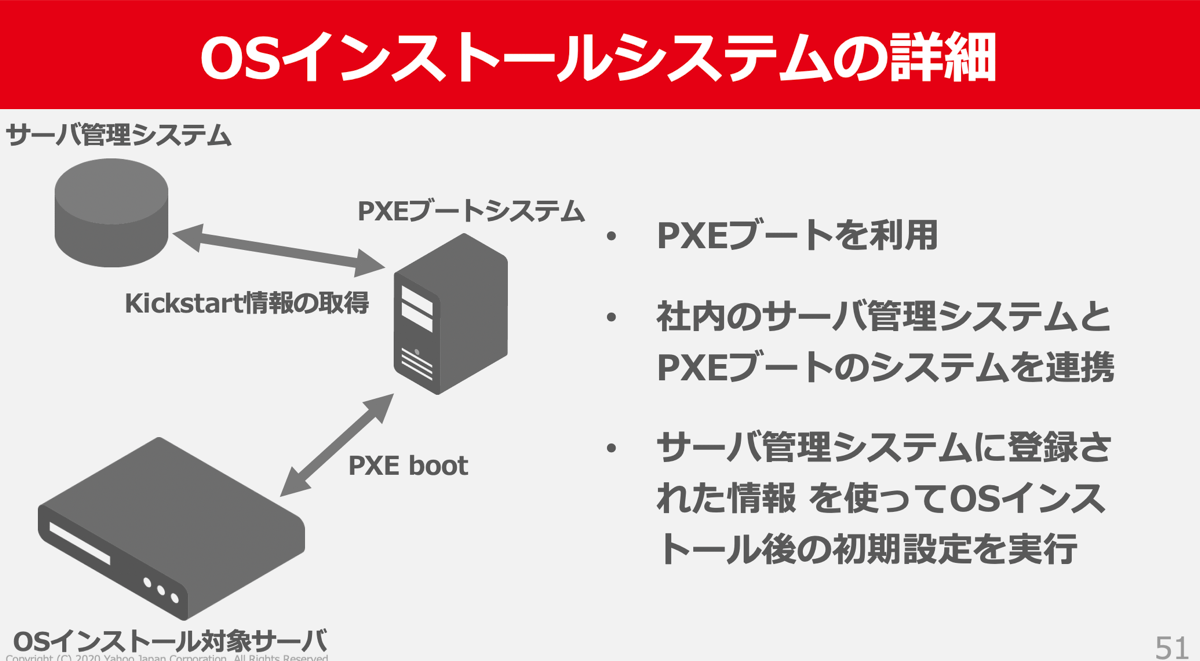
この方式では、いかにサーバー管理システムに対してMAC addressを効率よく登録するかが肝になります。
サーバーのシリアルとそれに対応するMAC addressは事前にベンダーから入手可能ですが、任意のシリアルを持つサーバーがどこにラッキングされるかについては管理できない(仮に管理できたとして、ラッキングに要する工数が膨れ上がる)ため、サーバー管理システムに対して事前にMAC addressを登録することは困難です。
この課題に対応するため、ヤフーではサーバー本体に出荷時から貼付されている二次元バーコードを利用しています。
この二次元バーコードにはサーバーのシリアル情報が含まれているため、バーコードリーダーを用いて読みだしたシリアルを元にMAC addressをサーバー管理システムに対して半自動で登録することが可能です。
こうすることでサーバーをラッキング後にシリアルを読み取り、サーバー管理システム上の任意のサーバーとそれに対応するMAC addressの登録を効率化しています。
こういった効率化を行うことで、ヤフーでは数千台のサーバーのOSインストールをおよそ数日〜一週間程度で完了させています。
OpenStackのデプロイ
サーバー(親機)が利用可能になったらいよいよOpenStackをデプロイすることになります。
OpenStackのデプロイはおおよそ2つのステップからなります。
- Openstackコントローラのデプロイ
- サーバー(親機)のデプロイ
このうち、Openstackコントローラのデプロイについてはヤフー環境ではほぼ全自動化がされており、約数十分もあれば構築が完了するようになっています。
OpenStackコントローラーはコンテナイメージ化されておりKubernetesで自動配置がされます。
Kubernetesの各リソースはchartでtemplate化されており、クラスタ構築者はクラスタの変数(クラスタ名や各リソースプロバイダの設定など)を定義するだけでデプロイが完了するようになっています。
このように、クラスタ構築の第1ステップであるOpenStackコントローラのデプロイは非常にスムーズに完了しますが、問題はサーバー(親機)のデプロイです。
1クラスタに含まれるサーバーの数は最大で500以上にも上るため、筐体不良は必ず数台は引くことになりますが、それ自体はセンドバックすれば済むことであり大した問題ではありません。
問題が深刻化してしまうのは、納入されたサーバーの設定が発注時の指定と異なっていたり、納入ロット全体のファームウェアに問題があったり、発注と異なる構成で機器が納品されてしまった場合です。
実際にヤフー環境で発生したトラブルをいくつか紹介します。
- 納品された500台のサーバーのBIOS設定に誤りがあった
- IPMI経由で全てのサーバーのBIOS設定を手修正
- 納品されたサーバーにディスクが搭載されていない
- その他納品時の構成誤り系は多数
- OSインストールしたカーネル版数でNICのカーネルドライバが動作しない
- 全てのサーバーをOS再インストール
- ファームウェアや制御チップの問題でReboot後にサーバーが起動しない
- ファームウェアのアップデート、場合によってはチップを焼き直して交換
このように、構築のリードタイムの多くを占めるのはハードウェアの問題への対応がほとんどです。
だからと言って構築の効率化のための数々の施策が不要であるというわけではありません。
むしろ、こういったトラブルが発生してもスケジュールどおりにユーザーへIaaS基盤を提供するためにも、効率化の施策はより重要となります。
テスト
この様に構築されたOpenStackクラスタは最後にテストを経てユーザーへリリースされます。
一般的なシステム開発におけるテストの重要性は既に説明の必要もありませんが、IaaS基盤であってもそれは同じことです。
むしろIaaS基盤は一度リリースした後からではデータプレーンに関する修正はユーザー影響が大きくなり難しいため、より確実なテストが求められます。
そのため、テストの内容は全てコード化され、テストの実行も自動で行われる仕組みをヤフーでは整えています。
サーバー(親機)の全台をテストする必要があるため、テストコードの配布と実行はfabricによって行われています。
サーバーだけでなくOpenStackのAPI単位の機能テストもfabricを用いて行っており、コードは可能な限り共通化されています。
実行しているテストの項目は100以上に上ります。以下にいくつか例をあげます。
- kernel boot opsが設定通りか
- サーバー(親機)のhugepageのサイズや枚数が適切か
- 必要なポートが開放されているか
- NICは正しく冗長化されているか
- ディスクのマウント設定は適切か
- アプリケーションアカウントの設定は適切か
- ネットワークIFのoffload設定は適切か
ここまで多くのテスト項目が積み上がったことには理由があります。
それは、これまでの「失敗の歴史」がテスト項目として反映されているためです。
冒頭のヤフーのIaaS基盤の概要でお話しした通り、ヤフーには200以上のOpenStackクラスタが存在します。
これだけの数を構築していると当然多くの失敗が積み重なります。確かに最初から失敗しないことも大切ですが、それよりも遥かに大切なのは同じ失敗を繰り返さないことです。
失敗はチーム全体で共有する財産ですので、正しく活かすことが重要です。
「目視で確認する」や「ダブルチェックする」といった、無意味でなおかつ担当者の負担だけが増えるような再発防止策は行わず、全てのテストがコード化され、同じ失敗を繰り返せない仕組みになっていることが重要です。
このように全てのテストがコード化され、人の手がテストに介入する余地がないことが理想ではありますが、現実ではコード化されていないテストも一部存在します。
特に連携するコンポーネントやリソースプロパイダが数多く存在するIaaS基盤では完全なコード化が困難なテスト項目も存在します。
そのため、自動化させるべきテストと人が実施すべきテストの住み分けの判断が重要です。
まとめ
ここまで「構築編」としてヤフーのIaaS基盤の設計上のポリシーや構築時の工夫点をかいつまんでご紹介しました。
次回は「運用編」として、大規模IaaS基盤の運用観点でのTipsをご紹介します。
本項は2020年07月29-30日に開催されたCloud Operator Days Tokyo 2020でのヤフー株式会社の講演を記事化したものです。
YouTubeにて本講演のアーカイブも配信されておりますので、ご興味のある方はそちらもご参照ください。
Cloud Operator Days: https://cloudopsdays.com/
本講演のアーカイブ配信URL: https://www.youtube.com/watch?v=tx_pG8cqbSw
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 奥村 司
- インフラエンジニア
- ヤフーのIaaS基盤の開発および運用を行うチームで、インフラエンジニアとして日々増え続けるサーバーに立ち向かっています



