
こんにちは、ヤフーのKubernetes as a Service(以下KaaS)を担当している勝田です。 今回、KaaSをProduction環境で2年活用してきた中でどのような変化がおき、ヤフーの開発環境がどう変化してきたかをご紹介いたします。
※ 本記事はYahoo JAPAN Tech Conference 2019 in Shibuya(以下YJTC2019 in Shibuya)のセッション「Kubernetes as a ServiceをProduction環境で2年活用し、直面してきた課題と解決策」をベースに、よりヤフーのKubernetes事情にスポットを当ててお話させていただきます。YJTCのスライドも下記リンクから見られますので、こちらもご参照ください。
始めに
皆さんYJTC2019 in Shibuyaの基調講演はご覧になられましたでしょうか。
ヤフーのモダナイゼーションについて語られており、本記事のKaaSとはまさにこの動きから生まれたシステムです。 また、Speedを向上させるため技術選択において自分たちで作る「Make」とOSSなど活用する「Use」を使い分けるという話も出ています。 今回お話させていただくKaaSについてもこの「Make」と「Use」を意識して、よりヤフーが価値提供Speedを向上させられる開発環境を素早く実現させています。
さて、ヤフーではKubernetes(以下K8s)を多くのプロダクトで活用しています。 2019年11月時点での利用規模は次の通りです。
- 利用プロダクト数: 約140
- K8sクラスタ数: 530以上
- コンテナ数: 70,000コンテナ以上
そして本2020年ではさらにこの倍以上の規模になる見込みです。 この大量のK8sクラスタを私たちKaaSチームが1チームで運用管理しています。 もちろんProduction環境稼働当初からこの規模というわけではありません。下図が2年間のクラスタ数の推移です。
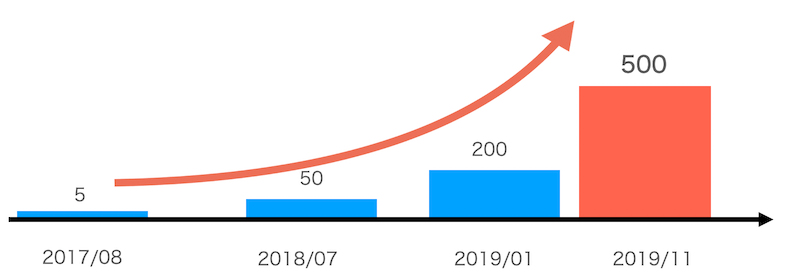
Production環境の増加に伴い、KaaSチームも変化しています。稼働当初のKaaSメンバーは数人でした。 その後、利用プロダクトの増加に伴い、現在では20人程度のチームになっています。 このような大規模なK8s運用を実現するための組織づくりについては別途記事が作成されていますので、そちらもご参照ください。
本記事では主にシステム側についてお話させていただきます。
ヤフーのKaaS
ヤフーでは上記のような大量のK8sクラスタを管理するためにKaaSを使用しています。 下記にKaaSで自動化・簡略化している機能の一部を記載します。
- K8sクラスタの払い出し作業
- Node障害時の復旧
- ダウンタイムゼロでのクラスタUpdate
KaaSの仕組みや、自動復旧の流れに関してはKubeCon China2019で発表させていただきました。 これらの仕組みについて詳しく確認したい方は公式サイトに資料と動画がありますので、そちらを参照ください。
KaaSも2年間で、より多くの利用者に安定して提供でき、より多くの利用ケースに応えられるシステムとなるようさまざまな改修が行われてきました。 以下でそれら改修の一部をご紹介します。
MakeによるKaaS改修
クラスタの段階的一斉Updateによる古いバージョンのクラスタ根絶
ヤフーではK8sを利用しているサービスの多様性からクラスタのバージョンは全て統一するのでなく、利用者が自由なタイミングでUpdate可能にしています。 しかし、やはり可能であれば自動でUpdateされて欲しいもの。KaaSでは1コマンドでダウンタイムゼロのUpdateが可能ですが、それでもUpdateが先延ばしになってしまうことが多々ありました。 利用者目線だけでなく、KaaSチーム目線でも古いバージョンのクラスタが残ってしまうことはサポートの面で不都合がありました。
そこで、段階的な一斉Updateを実現しました。 KaaSの利用者は全プロダクトがDevelop環境, Production環境といった複数の環境にクラスタを持っています。 まず、Develop環境の古いバージョンのクラスタを一斉にUpdateし、そこで動作が問題ないことを確認します。 KaaSチームが提供しているaddonなどは自動で適切なバージョンに更新され、もしアプリケーションの動作に問題があった場合はアラートが発生するようになっています。 このようにして新しいバージョンでも問題がないことが確認されてから、Production環境のクラスタを一斉にUpdateします。
こうして、開発者が意識せずとも新しいバージョンでの動作確認がしっかり行われ、かつクラスタが順次新しくなっていく仕組みを実現しました。
Machineリソースの効率的な活用
VM時代と比較すると図のように層が増え、各層で余裕を持たせていると実際に動かすアプリケーションの規模が変わらなくても、必要な物理マシンの量が多くなってしまいます。
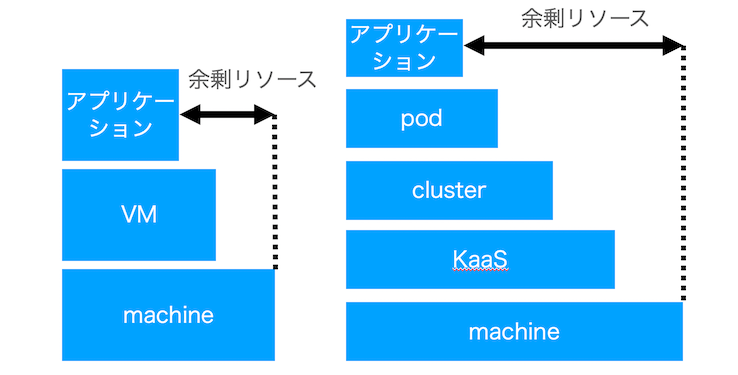
そこで、各層で実際に必要なリソース量を可視化し、本当に必要なリソースがどの程度なのかすぐに確認できるようにしました。 これにより明らかに過剰なリソースが割り当てられていることがグラフィカルに確認できるようになり、各層での余剰分を実際に必要な分にすることで、過剰なリソース要求を抑えられるようにしました。
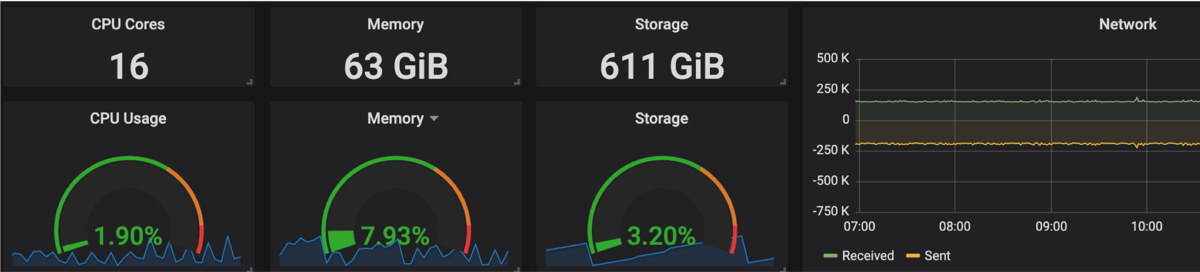
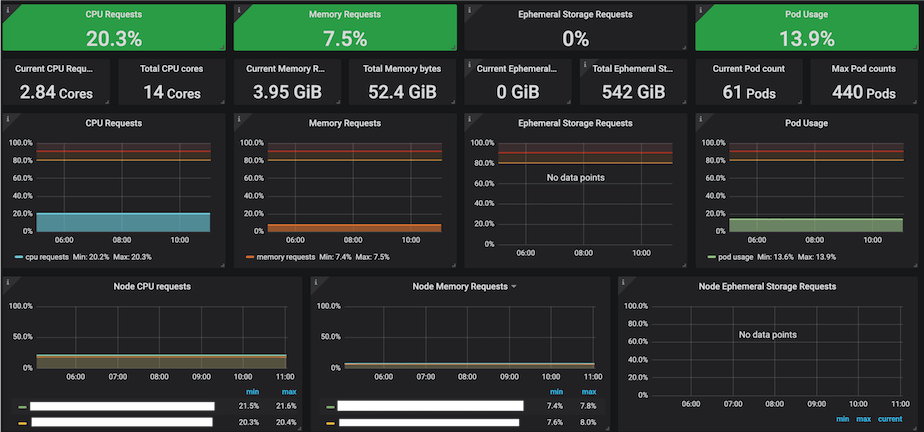
必要なログを必要なタイミングで参照できる最小限のログ集約システム
コンテナは頻繁に作成と削除が繰り返され、すでに削除されているコンテナのログは通常参照できません。 ヤフーのK8sではデフォルトの機能としてログの集約をしており、利用者は何も意識せずともログ集約システムで全ログを確認できます。
しかしクラスタ数が数百となった今、それらのログを全て集約しようとするとかなり困難です。 特にクラスタで稼働しているアプリケーションに異常が発生した際、エラーログが大量に吐き出されログ集約システムの遅延や不安定化につながりました。 そのような異常時のログは爆発的な量となり、対応できるように集約システムをスケールしても普段は過剰なシステム規模となってしまいます。
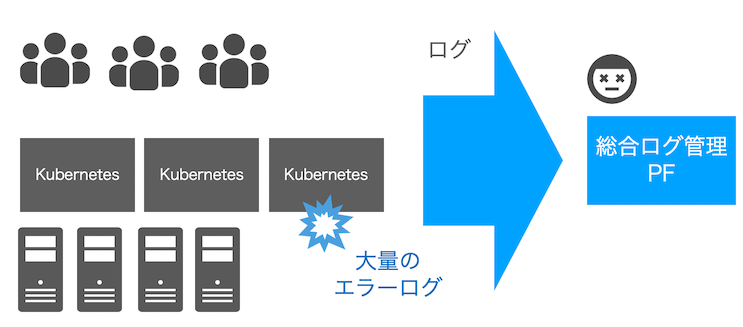
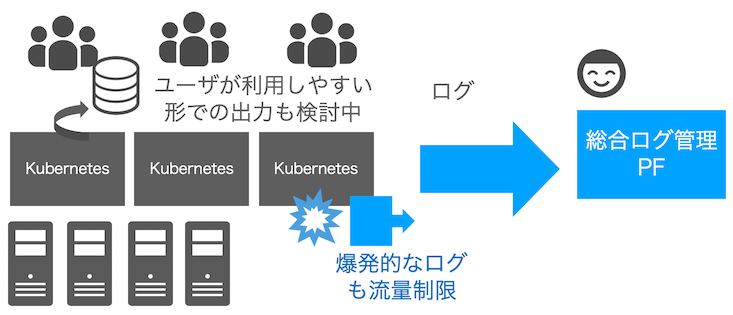
そのような、爆発的なエラーログは流量制限を行い、各クラスタからのログ量が跳ね上がらないログ転送を実装しました。 また、単にログを集約する以外に、利用者が利用しやすい形でクラスタから直接出力できるよう改修を検討しています。 これにより、共通システムへの負荷を増やさず、利用者は自分たちの運用体制にログ情報をより利用しやすくなる想定です。
UseによるKaaS改修
改修ゼロでマイクロサービス間を可視化
K8sの利用でマイクロサービス化が必須というわけではないですが、やはり開発のしやすさから取り入れるチームが増えてきました。 それにより開発が行いやすくなる一方、問題発生時の調査が難しくなってしまい、不具合調査系の問い合わせが増えてしまいました。 私たちKaaSチームは1チームですので、利用している150のチームのアプリケーションを個別に調査はできません。 利用者が簡単にそのような調査を行える仕組みを導入する必要がありました。
そこで、以前からパフォーマンス改善のために導入を検討していたDynatraceを実導入しました。 Dynatraceはマイクロサービス全体のパフォーマンスを分析するツールで、以下のような理由から採用を決定しました。
- KaaS以外のヤフーの別のPFでも利用可能
- 実際の開発サービスに低コストで導入可能
- ヤフーの膨大なトラフィックをトレース可能
一般的にサービス間のトレースを行うにはそのためのfunctionを埋め込む必要がありますが、Dynatraceはそれを自動で行ってくれます。 ヤフーのKaaSではDynatrace導入はaddon-managerのリストにDynatraceを記載するだけで導入完了ですので、つまりaddonの設定のみで可視化が完了します。
この導入により「検索APIの応答速度が遅いがどこを確認すれば改善できるかわからない」という問い合わせに、DynatraceのUIを参照するだけで例えとして下記の点にたどりつけます。
- バックエンドAPIを並列呼び出ししていない
- 特定のFunctionのパフォーマンスが低い
このようにDynatraceの導入によって、改修ゼロでのアプリケーションを解析できる、Updateが促進される環境が提供できました。
セキュリティ的な課題をすぐさま自動で検知
ヤフーでは、VM環境では脆弱性検出を自動で行っていました。 K8s環境ではまだ脆弱性検出に人の手が大きくかかっており、開発チームでもその手間はコストになっています。 かといって手を抜ける場所ではありません。できるだけコストがかからず、かつ網羅的な脆弱性検知の実現を目指しました。
KaaSの脆弱性検知は確認すべき箇所が多くあります。 K8s自体, Dockerイメージ, 稼働アプリケーションなど、それらを全て含んだ脆弱性検知を、低コストで実現するためにUseを選択し、そして現在Sysdigの導入によりこれらを実現しようと進めています。 Sysdigでは下記の機能を持っており、上記の脆弱性検知が包括的に行えるアプリケーションとなっています。
- システムコールからMachine上の不審な挙動を検知
- コンテナの脆弱性検知
- コンテナイメージのリポジトリ脆弱性検知
- Kubernetes CIS Benchmarkのサポート
- OSSのCloud Nativeな脆弱性ツールであるFalcoの活用
終わりに
ヤフーではミッションとして「UPDATE JAPAN」を掲げ「世界で一番、便利な国へ。」をビジョンとして目指しています。 これは技術の点でも同様で、私はMakeとUseを選択する重要性もこの点から来ていると考えています。 世の中にある技術と同等のものを作成してもUPDATE JAPANはなされません。 今ある技術は取り入れて、未成熟な領域は自分たちで伸ばしていき、そしてOSS貢献やConference参加を通じてUPDATE JAPANにつなげています。
私たちKaaSチームはこれらのようなUPDATE KaaSを通して、UPDATE JAPANを実現しようと日々改善を進めています。 本記事はKaaSの記事ということでKaaS周りのご紹介ですが、これはヤフー全体で取り組んでいるモダナイゼーションのほんの一部です。 今後もヤフーからの技術発信にご期待いただけますと幸いです。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



