※2014/4/17 記事の内容に関していくつか訂正させていただきました。 ご指摘いただいた皆様ありがとうございました。
- 誤字脱字を修正しました。
- ソースコードの間違いを修正しました。
- BOMの記述を分かりやすい表現に修正しました。
- 合字に関する記載を追記いたしました。
こんにちは。
Yahoo! JAPANで通知プラットフォームの開発をおこなっています佐々木海(@Lewuathe)と申します。
普段は全社向けのPush通知プラットフォームやメール配信プラットフォームの開発、保守をしています。通知というのはPush通知にしろ、メール配信にしろ基本的には「テキストデータ」を送ることになります。プラットフォーム内ではこれらのテキストに対してさまざまな処理をかけることになるのですが、さすが日本語といったところでしょうか、一筋縄ではいかない部分が出てきました。具体的にはUTF-8でエンコーディングされた文字列の文字境界を知りたかったわけですが、今回はどうせならと思いそもそもUnicodeって何? UTF-8とは違うの? という話をしたいと思います。
そもそもUnicodeって?
恥ずかしながら今までUnicodeとUTF-8に違いがよくわかっていませんでした。どっちも符号化方式のことなんだろうと考えていたのですが、よくよく調べてみると違いました。そもそものレイヤーが違うんですね。Unicodeはすべての文字を2byte(16bit)で表現しようという思想の下にAppleやHP, Microsoftなどが採用し、Unicode ConsortiumがPromoteしている文字集合と文字コード体系のことです。
Unicode provides a unique number for every character, no matter what the platform, no matter what the program, no matter what the language. by Unicode Consortium
Unicode以前に存在していたさまざまな文字コード体系は互換性がなく、またサポートしている文字集合自体もバラバラでそれぞれ十分ではありませんでした。Unicodeではこの文字集合に含まれる文字それぞれに対してUnicodeスカラ値という非負整数値を対応づけています。実際コンピューターで利用する際にはこれらの値をbyte列に直す必要があります。この変換方法を文字符号化方式といいます。UnicodeではUnicodeスカラ値を定義するだけでなく、この文字符号化方式をも標準化したため文字コードの選択による混乱を避けることに寄与しています。そしてこの文字符号化方式の一つがUTF-8です。つまりUnicodeがUTF-8よりも上位の概念にあたるわけです。言ってみれば仕様と実装といったところでしょうか。よくよく見てみると(よくよく見てみなくても)全然違うものですね。
| Unicode | UTF-8 |
|---|---|
| 文字集合 | 符号化方式 |
ここではUTF-8をあげましたが、もちろんこれ以外にもUnicodeを実現する文字符号化方式はあります。(UTF-16とかUTF-32など)大事なことはこれらが「世界中にあるすべての文字を一つの一貫した方法で表現したい」というモチベーションに基いて定義されたということです。なんとも壮大で夢のある話ですね。
UTF-8とは?
私はWeb屋さんなのでUTF-8をよく見ます。実際今回の自分の開発しているプラットフォームで扱わなければならなかった文字もUTF-8で定義された文字列でした。ここで少しUTF-8について見て行きたいと思います。UTF-8については以下のような特徴があります。
- 可変長(1-4byte)を使って一つの文字を表現する
- 文字の境界が明確
- ASCII互換
- byte順の影響がない(エンディアンの影響を受けない)のでBOM(Byte Order Mark)の必要がない
- 31bitまで表現できるのでサロゲートペアが必要ない
これらの特徴を実際のbitパターンを見ながら考えてみたいと思います。

まず表1の見方です。一番左のカラムが先ほど説明しましたUnicodeスカラ値を表しています。そして大きなひとつ右のカラムがそれを表すUTF-8のbit列です。上のbit列から、下のbit列までの範囲を表します。例えば一行目の文字集合は8bitで表現され00000000~01111111の範囲に収まります。赤文字はUTF-8の文字境界の識別に使われるbitで実際の文字表現には使われないので、これを除いたbitを有効bitとして3カラム目に格納してあります。
さて先ほどの特徴をひとつずつ見てみましょう。
可変長(1-4byte)を使って一つの文字を表現する
Unicodeで定義されている文字集合は基本多言語面から第16面までなので、U+0000からU+10FFFFまであれば事足ります。よってUTF-8では1-4byteあれば一つの文字を表すことができることがわかります。

面というのは符号空間を指す一部分のことで、Unicodeでは0から16までの面に分かれています(表2)。それぞれの面に含まれる文字集合は区別されていますが、日常使うほとんどの文字はBMP, 基本多言語面に含まれます。
文字の境界が明確
表の赤文字で表現されているbitを見てください。一行目を除いてすべてその文字を表すbyte数の分だけ1が連続していることがわかります。また2byte目以降はすべて10で始まっていることがわかります。このことから文字境界を知りたければ0で始まっているか、1が2つ以上連続しているかをbyte毎に見てあげればいいことになります。これがUTF-8の文字境界が明確である理由です。
ASCII互換
一行目の有効bitが7bitである範囲を見てください。元々ASCIIコードは7bitで表現できますので、この一行目の範囲をASCIIと同じ文字コードにすることで互換性を保っています。
byte順の影響がないのでBOMの必要がない
まずBOM(Byte Order Mark)の話を簡単にします。通常ネットワークや異なるプラットフォームにテキストを渡すとき、そのエンディアンを気にする必要があります。これはbyte順を入れ替えた際に異なる文字になってしまうような文字コードの場合は特に大事です。そのためBOMという仕組みがあります。BOMはテキストデータの先頭につける数バイトのデータでこれを元にコンピュータは符号化形式などを判断し適切に復号することができます。ただUTF-8に関してはどの2つのbyteを見てもその順番を調べればビッグエンディアンなのか、リトルエンディアンなのかの区別をつけることができます。これは表1の各文字の1byte目と2byte目の先頭が必ず異なるためです。オーバヘッドなども鑑みて通常はUTF-8の場合はBOMが付けられない場合が多いです。

31bitまで表現できるのでサロゲートペアが必要ない
まずサロゲートペアの話をしましょう。はじめに少し書きましたがUnicodeは世界中のすべての文字を2byte(16bit)で表そうとしたと書きました。最大65536種類の文字を集録することができます。ところが上記のUTF-8の表を見ておかしいと思いませんか。UTF-8でも結局4byte程使ってしまっているわけですね。いろいろな言語がUnicode文字に組みいれてほしいということを言ったために結局65536種類では足りなくなってしまいました。UTF-8の場合はそもそも可変長文字として定義されているので上記のように定義すればもっとたくさんの文字を表すことができるので問題ありません。ところがUTF-16など一部の符号化方式は固定長でした。そのためUnicodeに新たに取り込まれた文字たちを表すにはすでに容量が足りなくなっていたわけです。そこで考えられたのがサロゲートペアです。サロゲートペアは以下のような仕組みです。
- 16bitで従来使用していなかった0xD800~0xDBFFを上位サロゲート、0xDC00~0xDFFFを下位サロゲートとして「上位サロゲート + 下位サロゲート」の4バイトで1つの文字を表す
- つまり今まで通り基本的には2byteで表し、一部の文字については4byteで表現するという方法
- この方法によりUnicodeでは新たに約104万(~1024*1024)の文字を扱えるようになった
ただ先程も書きましたが、UTF-8は可変長1~4byteを利用できる符号化方式ですのでめんどくさいサロゲートペアを使用する必要がないわけです。
冗長なUTF-8
ここまでUTF-8の特徴を見てきました。UTF-8は素晴らしい文字コードです。何より互換性の高さは文字コードとしては大事な特徴だと思います。しかし、そんな完全無欠に見える符号化方式であるUTF-8にも弱点があります。
ここでは冗長なUTF-8と呼ばれる脆弱性を紹介したいと思います。通常、文字と文字コードは一対一に対応しなければなりませんが、UTF-8ではそうならない場合があるという話です。
通常Unicodeの符号からUTF-8で文字コードを当てはめる場合は以下のように行います。
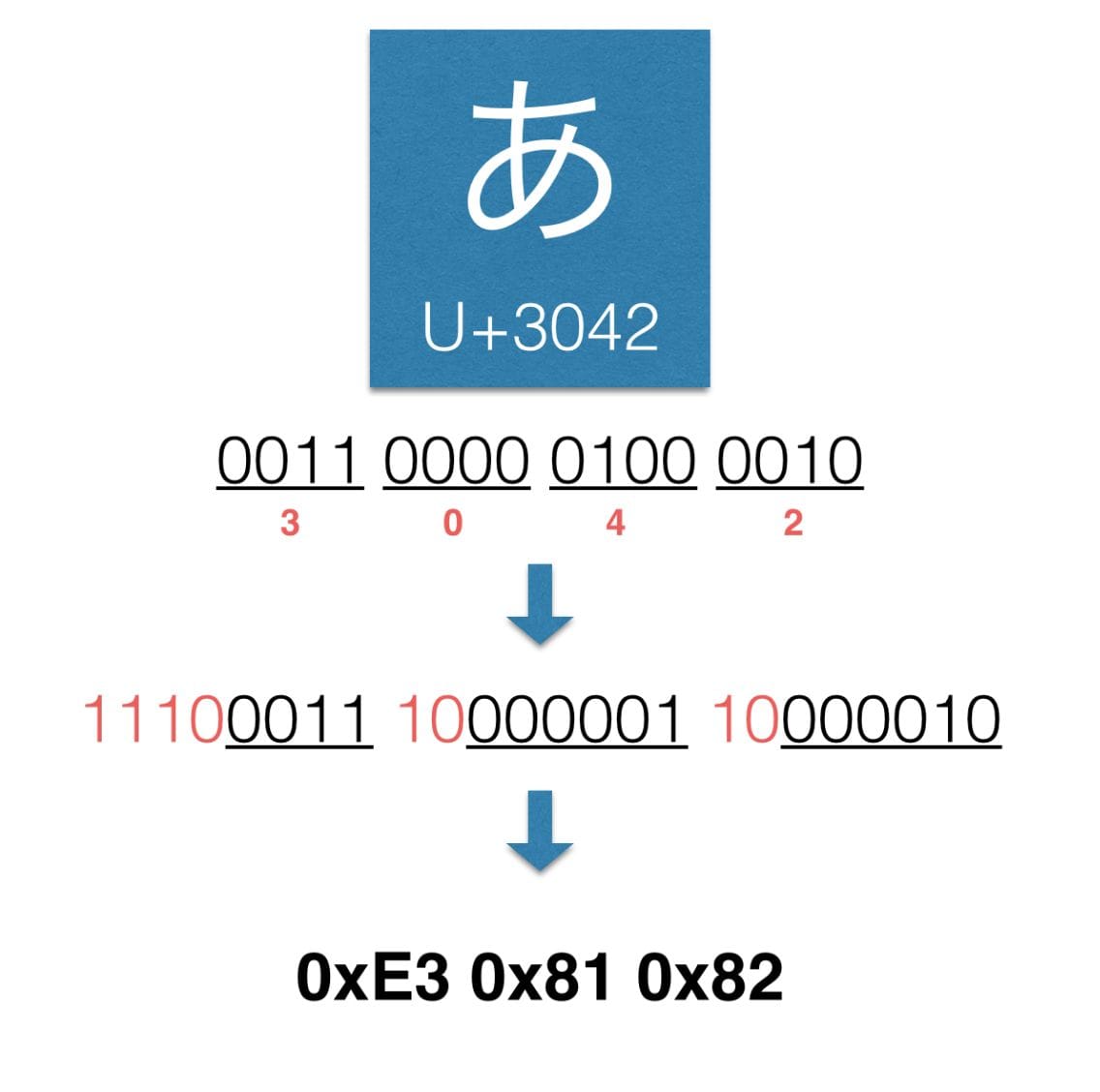
ひらがな「あ」の場合はUnicodeスカラ値をbitにあてはめ必要なbyte数が3byteだとわかります。先程の表を思い出してください。3byteであれば先頭は1110となります。あとは2番目以降のbyteの先頭が10となるようにbitを割り振っていけばよいです。そのため最終的な符号は0xE3 0x81 0x82となります。このようにUnicodeスカラ値から一意に文字コードが決められるはずなのですが、実はそうならない場合があります。
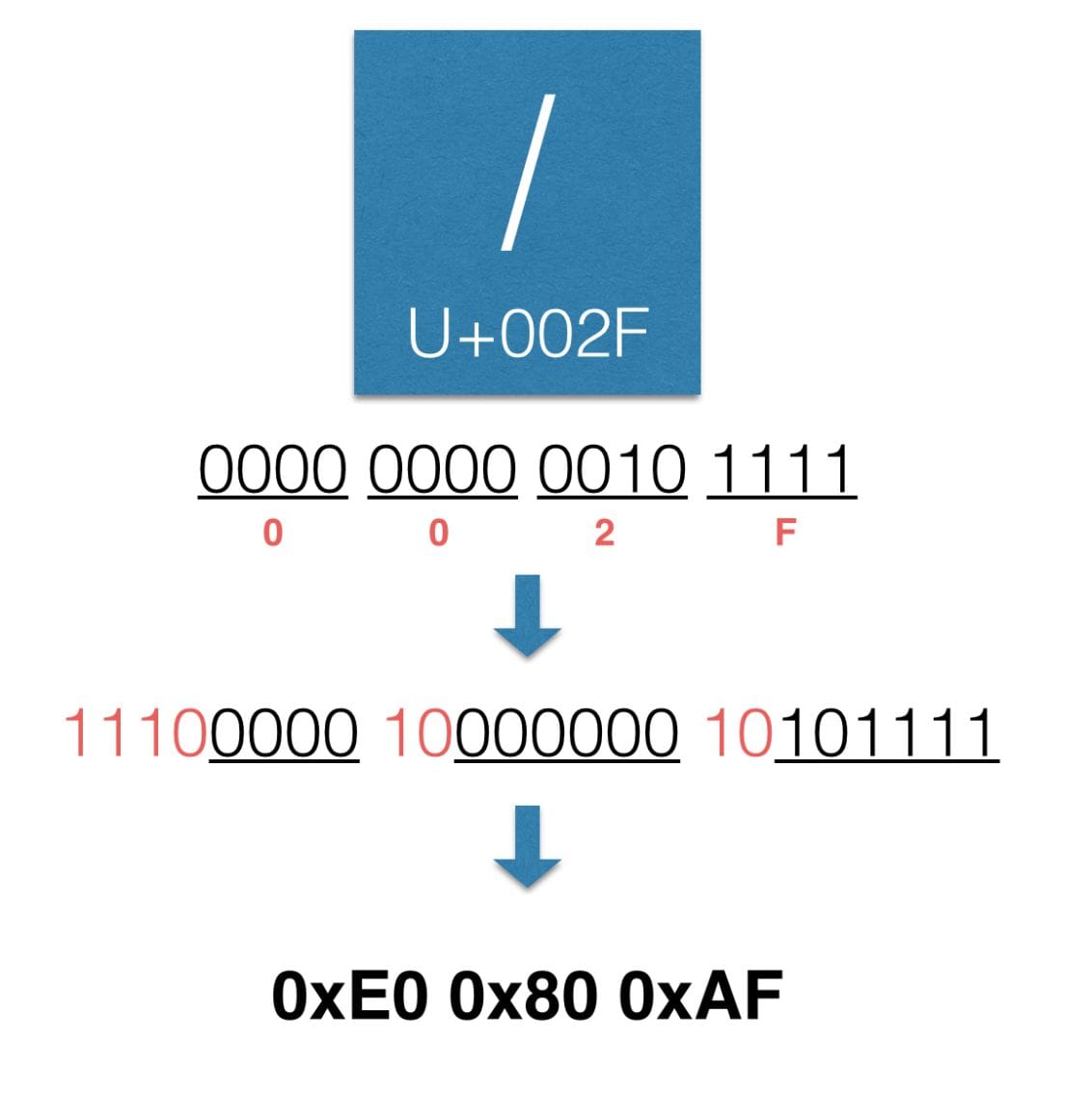
上の/の場合、本来はASCII 7bitの範囲に収まるはずなので1byteでいいのですがここでは余分な0を加えて無理やり3byte文字に仕立てあげています。これ自体はUTF-8の変換方式にはしたがっていないのですが、このような解釈に基いて変換を行うことがあると文字コードが何種類もできてしまうという事態が起きてしまうわけです。この文字コードが何種類もできてしまう問題はこの他にも「合字」により生じるものでもあるらしいです。 結局同じ文字として扱えるんだから別にいいじゃんと思うかもしれません。しかし、この脆弱性はディレクトリトラバーサルなどの攻撃に利用されることがあるのでやはり対策が必要です。
じゃあどうするの?
基本的には余計な0をつけてしまったことに問題があるので、これを判断してあげればいいです。例えばその文字に対して割り当てられている文字コードが最小のものになっているかの判断を加えることや0の区間が続いているだけのbyteがないかなどのチェックを入れるということです。
ようやくUnicodeを斬る
このブログを書く元々のきっかけは冒頭にも書きましたがUTF-8で送られてきた文字列の境界を調べたかったからなんですね。だいぶ脱線してしまいました。既に答えはこの記事に書いてあるのですが、最後に文字境界を判断するコードを書いてまとめとしたいと思います。今回のコードで処理される文字列はNFCで正規化されたものを入力として受け取ります。合成済みの符号が用意されていない文字に関しては今回は考慮していません。
char *bufp = original; // 斬りたい文字列
while (bufp < original + len) {
// lenはoriginalのうちの処理したい部分の長さ
if( *bufp == 0x00 ) {
// ここではbufpはnull文字を指しています
// ここに文字列が終わったときの処理を書きます
}
else if(( *bufp & 0x80 ) == 0x00 || (*bufp & 0xc0 ) == 0xc0 ) {
// 0x80 = 1000(2)なので第1bitが立っていないということはASCII互換の文字の境界に相当します
// 0xc0 = 1100(2)なので先頭2bitが1ということはこれは2byte以上で表現
// されている文字の先頭だということがわかります
// ここに各文字の先頭にきた場合の処理を書きます
}
bufp++;
}
これでUTF-8の文字列の境界を定めつつ処理を行うことができました。
今回はUnicodeをいろんな視点から斬ってみました。最後には実際に斬りました。文字コードって奥が深いなと感じていただければ幸いです。



