インフラエンジニア見習いの森本です。これまで数年ほどサーバーサイドエンジニアとして開発ばかりをしてきた人が最近インフラエンジニアになりました。
3月末に開催された Go Conference 2017 Spring で開発チームの後藤から弊社で開発・運用している AWS S3 互換の分散オブジェクトストレージ Dragon についての発表がありました。
私は Dragon の運用を担うチームに所属しており、本稿ではその業務の中で発生したトラブルシューティングについて紹介したいと思います。
分散オブジェクトストレージ Dragon で発生していた課題
Dragon で goroutine リークが起きているようなので調査するという課題の担当になりました。 Dragon は Go 言語で開発されていてランタイムの状態情報をメトリクスとして取得しています。以下はその状態情報を時系列に取得してグラフ化したものの一部になります。
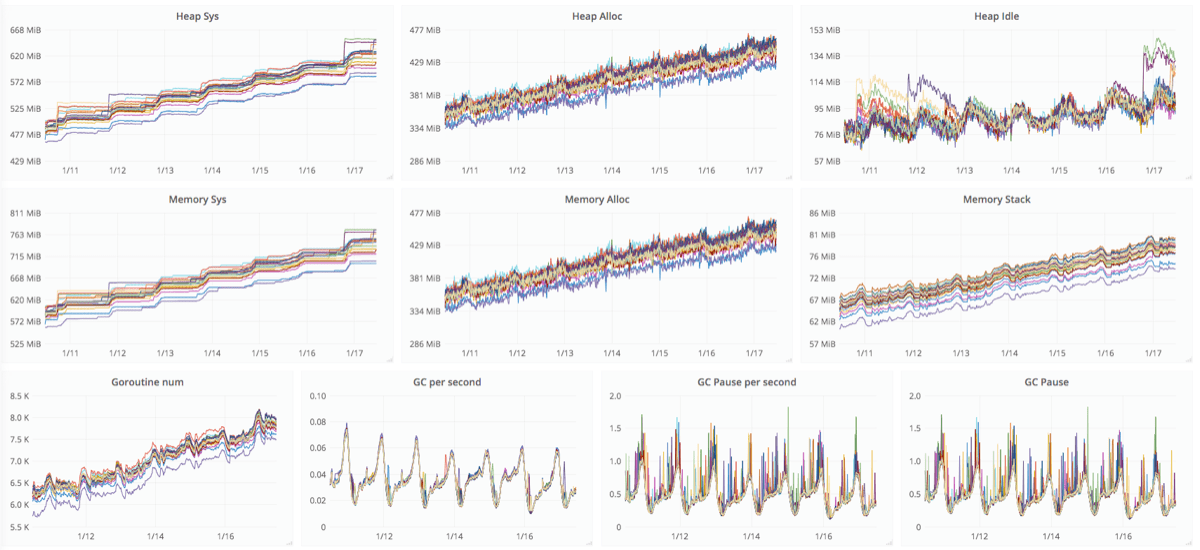
このグラフの Heap/Memory の利用状況、ならびに Goroutine num のグラフに着目してください。確かにこのグラフだけをみたら明らかな goroutine リークが発生しているようにみえます。この課題をどのように調査して解決したかについて本稿で紹介します。
Go 言語のプロファイルを取る
前節で紹介したグラフでは goroutine とメモリ使用量が増えています。なんらかの理由により goroutine の終了が行われず、その分のメモリ使用量が徐々に増えているのでは?と推測するのが普通ではないでしょうか。私もそのように考えて調査を始めました。
Go 言語では pprof というランタイムのプロファイルを行うためのツールが標準ライブラリとして提供されています。このツールを使うことで Go 言語で開発したアプリケーションのプロファイリングが簡単に行えます。
pprof では大別して CPU とメモリのプロファイルを取得できます。ここではメモリのプロファイルを取得して調査を進めます。
サーバーアプリケーションや長時間実行するようなアプリケーションなら net/http/pprof を使って、以下のようにプロファイル取得用の http サーバーを起動することで任意のタイミングでリモートからでもプロファイル情報を取得できます。
import _ "net/http/pprof"
func main() {
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
...
}例えば、後述する https サーバーの動作中に、ヒープ領域のうち使用中のメモリ使用量を降順に取得するには、以下のように -top -inuse_space オプションを指定して go tool pprof コマンドを実行します。
$ go tool pprof -top -inuse_space http://localhost:6060/debug/pprof/heap
Fetching profile from http://localhost:6060/debug/pprof/heap
Saved profile in path/to/pprof/pprof.localhost:6060.inuse_objects.inuse_space.180.pb.gz
2088.22kB of 2127.03kB total (98.18%)
Dropped 297 nodes (cum <= 10.63kB)
flat flat% sum% cum cum%
884kB 41.56% 41.56% 884kB 41.56% crypto/tls.(*block).reserve
368.44kB 17.32% 58.88% 368.44kB 17.32% net/http.newBufioReader
365.62kB 17.19% 76.07% 365.62kB 17.19% net/http.newBufioWriterSize
152kB 7.15% 83.22% 152kB 7.15% crypto/elliptic.initTable
67.50kB 3.17% 86.39% 97.73kB 4.59% crypto/tls.(*listener).Accept
50.62kB 2.38% 88.77% 50.62kB 2.38% crypto/aes.(*aesCipherGCM).NewGCM
37.50kB 1.76% 90.53% 37.50kB 1.76% runtime.malg
30.94kB 1.45% 91.99% 30.94kB 1.45% crypto/aes.NewCipher
19.69kB 0.93% 92.91% 28.03kB 1.32% net/http.readRequest
18.28kB 0.86% 93.77% 1950.20kB 91.69% net/http.(*conn).serve
18.05kB 0.85% 94.62% 18.05kB 0.85% runtime.deferproc.func1
16.19kB 0.76% 95.38% 97.75kB 4.60% crypto/tls.aeadAESGCM
14.06kB 0.66% 96.04% 14.06kB 0.66% bytes.makeSlice
11.91kB 0.56% 96.60% 11.91kB 0.56% crypto/tls.(*halfConn).newBlock
11.34kB 0.53% 97.14% 11.34kB 0.53% syscall.anyToSockaddr
11.25kB 0.53% 97.67% 11.25kB 0.53% net/http.(*Server).newConn
9.84kB 0.46% 98.13% 29.53kB 1.39% net.(*netFD).accept
0.67kB 0.032% 98.16% 181.59kB 8.54% crypto/tls.(*serverHandshakeState).doFullHandshake
0.19kB 0.0088% 98.17% 113.43kB 5.33% net/http.(*Server).ListenAndServeTLS
0.12kB 0.0059% 98.18% 113.55kB 5.34% net/http.ListenAndServeTLS
0 0% 98.18% 720.23kB 33.86% bufio.(*Writer).Write
0 0% 98.18% 720kB 33.85% bufio.(*Writer).flush
...crypto/tls.(*block).reserve や net/http.newBufioReader といった処理が数百KBのメモリを使っていることが分かります。このコマンドを定期的に実行するだけでもどの処理のメモリ使用量が増えているか、つまりメモリリークが起きている可能性がある場所を推測する手掛かりになります。
今回はこの手法で crypto/tls.(*block).reserve のメモリ使用量が徐々に増えていることが分かりました。この処理は Go 言語の標準ライブラリの処理なのでこの処理の呼び出し元を調べることにしましょう。いくつか方法はあると思いますが、graphviz のコールグラフを出力するのが最も直感的に分かりやすいのではないかと私は思います。以下のように -svg オプションを指定することで svg フォーマットのコールグラフが出力されます。
$ go tool pprof -svg -inuse_space http://localhost:6060/debug/pprof/heap > heap-$(date +"%Y%m%d%H%M%S").svg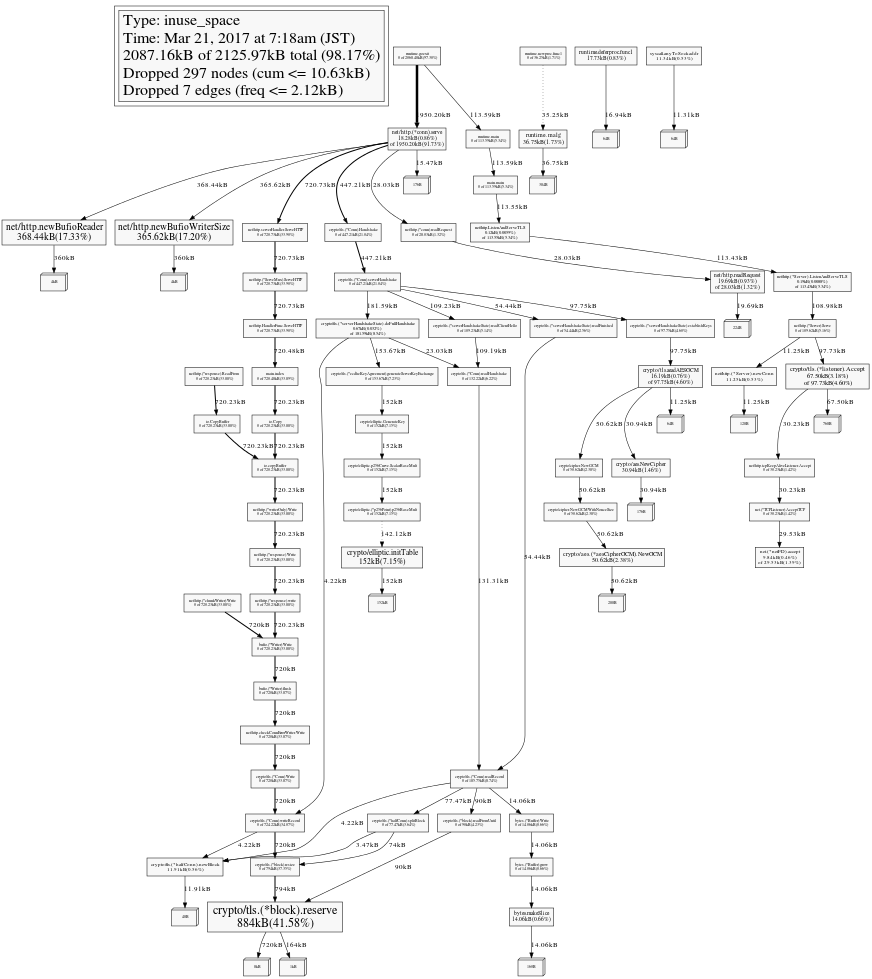
メモリプロファイルの精度を小さくしているのでコールグラフが複雑になっていますが、最もメモリ使用量の多いパスを辿ると良いでしょう。このコールグラフを辿っていくと crypto/tls(*block).resize <- ... <- io.copyBuffer <- io.Copy <- main.index と main パッケージの index という関数から呼び出されていることが分かります。このようにして、自分たちが開発しているアプリケーションのどの処理が起点となってメモリ使用量が増えているかを調べられます。時系列に heap のプロファイル結果を取得することを考慮しても数日もあれば見分けがつくでしょう。
ここまでは一般的なプラクティスとして広範囲のアプリケーションで適用できます。Go 言語は標準のプロファイルツールが必要十分な機能を提供しています。そのため、こういったリソースの利用状況に関する調査を行う敷居が低いです。
リファレンス
pprof ツールの使い方については @methane が紹介されている記事が分かりやすいです。私もこれらの記事を参考にしながらプロファイリングを行いました。
起こっている現象を再現させる
前節で行ったプロファイリングにより、どの処理が起点となって goroutine リーク、ひいてはメモリの浪費につながっているかが分かりました。実際に Dragon では、GET Object に相当する HTTP API が呼び出され、そのレスポンスを返すときに io.Copy -> ... -> crypto/tls.(*block).reserve といった呼び出しとなっていました。また後ほど再現コードを紹介します。
それでは なぜその現象が発生しているのでしょうか?
ここでは私の考えたことや試したことをなるべく時系列に書いていきます。
自分たちのアプリケーションコードを疑う
まずは自分たちが開発しているアプリケーションのコードになにかしら問題があるのではないかと疑います。一般論として Go 言語ほどの多くの開発者に使われている処理系や標準ライブラリに不具合があるとは考え難いです。そこでアプリケーションの該当処理のコードを読んでみました。goroutine やチャンネルを使っている箇所などを注意深く調べましたが、特に問題なさそうです。全く分かりません。
次に今回の調査専用に Dragon の開発環境を構築しました。コードを読んでも分からないので実際に動かしながらデバッグしてみることにしました。 Dragon は S3 互換なので aws-sdk-go を使って調査ツールを作りました。そのときに作ったツールが以下になります。
こういうリクエストを送ったらどうなるか、を調べるために検証しながら機能を追加していきます。実際に私がリクエストを送って調べたのは以下のような内容です。
- 数百KBから1GBぐらいまでのファイルを送受信する
- 通常リクエストと Range Requests を行う
- 1 と 2 を組み合わせたリクエストを数十から数百ほど並行にリクエストする
- リクエスト中にサーバーアプリケーションの構成や状態を変更する
これらのことを試しながら Dragon のプロファイル情報を監視しました。同じようなプロファイル結果自体は検証を開始したときから出たりしていたのですが、どうにも goroutine リークの再現条件が分かりません。大量にリクエストしているあいだはメモリ使用量が増えるといったことしか分かりません。たくさんリクエストを送っているのだからメモリ使用量が増えるのは当たり前の話です。ここではリクエスト中にメモリ使用量が増えて、リクエストが完了した後でもランタイムのガベージコレクションによって開放されない現象を再現したいわけです。
上記のことをツール作ったり条件を変えたりしながら2-3日試しましたが、全く再現条件が分かりません。なるほど、やばいです。。。
クライアントライブラリのソースコードを読む
前節では aws-sdk-go を使って調査ツールを作りました。何を思ったか、このライブラリを使っているから再現しないんじゃないかと aws-sdk-go を使うこと自体を疑い始めます。これは原因箇所を特定できているにも関わらず、その現象を再現できない焦りから精神的に情緒不安定になり始める兆しです (笑) 。
ライブラリのエラー処理を適当に読んでいて、ふと HTTPS リクエスト終了後にクライアントがコネクションを保持したままクローズしなかったらどうなるんだろう?と思いつきました。試しに複数のクライアントプロセスから HTTPS リクエストを送信し、HTTP Keep-Alive した状態でコネクションを保持するように調査ツールを実装しました。そして再度プロファイルを取得したところ、コネクションを保持している期間にサーバーの goroutine 数とメモリ使用量が解放されない現象を再現できました。
再現条件を整理する
前節の調査から HTTPS の HTTP/1.1 で接続するとき、クライアント数に比例して crypto/tls.(*block).reserve のメモリ使用量が増えることが分かりました。crypto/tls/conn.go の周辺コメントをみると reserve では TLS の処理に必要なバッファ領域を確保しているようにみえます。クライアントとのコネクションの増加に伴い、バッファ領域が増えるのは処理として正しいように思えます。
クライアントが実際にデータを通信していなくてもコネクションをクローズしない限り、バッファ領域を開放しないかどうかを検証するために以下の再現コードを書きました。もしこの現象に興味がある方は試してみてください。
ここまでの調査結果をまとめると、なんらかの理由によりクライアントとのコネクションがクローズされずに日々増えていっているのではないか、という推測がつきました。
本質的な原因を追求する
コネクション数の増加に気づかなかった理由の1つとして、サーバーのコネクション数がメトリクス監視の項目に含まれていなかったことが挙げられます。その後、日々のコネクション数を計測していくと、1つのサーバーで百数十程度のコネクション数が日々増えていることが分かりました。
これが数千といった数であれば実運用にも影響があるため、もっと早くに気付いたことでしょう。このぐらいの数だと1-2ヶ月ほどサーバーを連続稼働した状態でないと実運用には影響が出ません。 Dragon は開発が活発なため、1ヶ月もまったく新バージョンをリリースしないというのは稀でした。そのため、新バージョンをリリースするときにサーバーを再起動してコネクション数がリセットされるため、この現象に気付くのが遅れてしまった次第です。
Dragon で監視している他メトリクスの情報をみる限り、API のユーザー別リクエスト数や通信量が日ごとに増えているわけではありません。そのため、毎日ずっと通信しているクライアントが増えているとは考え難いです。
それでは なぜコネクションはクローズされないのか?
ここからは TCP/IP やネットワークの背景知識も必要になっていきます。
TCP コネクションは誰がいつクローズするのか
まずサーバーアプリケーションのコードからみていきましょう。
Go 言語の net/http/ResponseWriter のインターフェースには Close メソッドがありません。これはサーバーアプリケーションのハンドラー処理ではレスポンスを書き込んだ後にコネクションのクローズをしないことを表しています。
TCP Connection termination によると、コネクションのクローズは 4-way handshake (またはサーバーから ACK & FIN を一緒に送るなら 3-way handshake) で行われるとあります。以下は wikipedia で紹介されている図ですが、クライアントから FIN パケットを送ることでコネクションのクローズ処理が行われることが示されています。

それでは今回のようにクライアントがクローズしないときにサーバーはどうすれば良いのでしょうか。
keepalive
サーバーでコネクションを確立した状態からクローズする方法を調べていきます。いくつか方法があると思いますが、クライアントとサーバー間のコネクションを維持したり、切断したりする方法の1つに Keepalive があります。keepalive で調べると次の2種類がみつかると思うので簡単に説明します。
- HTTP Keep-Alive
- TCP keepalive
HTTP Keep-Alive
aws-sdk-go を使った調査過程でも出てきました。HTTP Keep-Alive は HTTP プロトコルの仕様であり、確立したコネクションを再利用して複数の HTTP リクエスト/レスポンスをやり取りする仕組みです。HTTP persistent connection から図を引用します。

右側の図が HTTP Keep-Alive の状態になります。この図では3回の HTTP リクエスト/レスポンスの後でコネクションをクローズしています。
rfc2616 によると、HTTP/1.1 ではデフォルトで HTTP Keep-Alive が有効とみなされます。
A significant difference between HTTP/1.1 and earlier versions of HTTP is that persistent connections are the default behavior of any HTTP connection. That is, unless otherwise indicated, the client SHOULD assume that the server will maintain a persistent connection, even after error responses from the server.
TCP keepalive
TCP keepalive は、TCP コネクションのノードが定期的に空のパケットを送り、コネクションが有効かどうか確認する TCP のオプション仕様です。
W.Richard Stevens 氏の 詳解TCP/IP〈Vol.1〉プロトコル によると、TCP keepalive の仕組み自体は TCP プロトコルの仕様には含まれていないと書かれています。以下がその理由ですが、いまとなっては歴史的経緯に受け取れます。
キープアライブは TCP 仕様にはない。ホスト要求 RFC は、それを用いない理由として以下の3点を挙げている。
- 完全な状態のコネクションが一時的な事故のために切断されてしまう可能性がある
- 帯域幅を不必要に消費する
- パケット単位の課金システムを採用するネットワークではコスト高になる。しかし、それでも多くの実装はキープアライブ・タイマーを用意している
そして Linux カーネルには TCP keepalive の仕組みが実装されています。例えば、CentOS 7 ではデフォルトで以下のパラメーターが設定されています。
$ sudo sysctl -a | grep keepalive
net.ipv4.tcp_keepalive_intvl = 75
net.ipv4.tcp_keepalive_probes = 9
net.ipv4.tcp_keepalive_time = 7200Linux Programmer’s Manual (7) TCP から引用します。
- tcp_keepalive_intvl (integer; default: 75; Linux 2.4 以降)
TCP keep-alive のプローブを送る間隔 (秒単位)。- tcp_keepalive_probes (integer; default: 9; Linux 2.2 以降)
TCP keep-alive プローブの最大回数。 この回数だけ試しても接続先から反応が得られない場合は、 あきらめて接続を切断する。- tcp_keepalive_time (integer; default: 7200; Linux 2.2 以降)
接続がアイドル状態になってから、keep-alive プローブを送信するまでの時間を秒単位で指定する。 SO_KEEPALIVE ソケットオプションが有効になっている場合のみ keep-alive は送信される。 デフォルト値は 7200 秒 (2 時間)。 keep-alive が有効になっている場合、 さらにおよそ 11 分 (75 秒間隔の 9 プローブ分) 経過するとアイドル状態の接続は終了させられる。
Linux のデフォルト設定ではソケットに SO_KEEPALIVE オプションが有効になっているとき、クライアントとの通信がない状態になってから2時間経つと、サーバーからプローブパケットをクライアントへ送ります。ここでクライアントが応答すればコネクションは維持されます。クライアントから応答がない場合、75秒ごとに9回プローブパケットを送った後でコネクションがクローズされます。つまり2時間11分経つと切断されます。
もしなんらかの理由でクライアントがコネクションをクローズせずにいなくなってしまった場合でも TCP keepalive の仕組みが有効であれば、サーバー側でコネクションがクローズされるようにみえます。
Linux で TCP コネクションの状態を調べる
多くの Linux Distribution では標準でネットワーク周りの調査に使えるコマンドがインストールされていると思います。
例えば、以下のように netstat コマンドに --timers オプションを指定すると、TCP keepalive の秒数やプローブ数が表示されます。この例では CentOS 7 で 44443 のポート番号を HTTPS の通信に使っています。
$ sudo netstat --all --numeric --tcp --program --timers
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp6 0 0 :::44443 :::* LISTEN 15081/./server_main off (0.00/0/0)
tcp6 0 0 172.21.103.140:44443 172.21.133.106:43726 ESTABLISHED 15081/./server_main keepalive (34.92/0/5)
tcp6 0 0 172.21.103.140:44443 172.21.133.106:43748 ESTABLISHED 15081/./server_main keepalive (165.35/0/0)
tcp6 0 0 172.21.103.140:44443 172.21.133.106:43756 ESTABLISHED 15081/./server_main keepalive (86.16/0/3)
...もし TCP keepalive が無効になっているときは以下のように表示されます。
tcp6 0 0 172.21.103.140:44443 172.21.133.106:37342 ESTABLISHED 15081/./server_main off (0.00/0/0)運用環境で調査したところ、TCP keepalive が無効になっていることが分かりました。
ソケットオプション
それでは なぜ TCP keepalive が無効になっているのか?
次に Go 言語の net/http のソースコードをみてみます。ListenAndServeTLS で https サーバーを起動するときに tcpKeepAliveListener という listener を生成していることが分かります。
func (srv *Server) ListenAndServeTLS(certFile, keyFile string) error {
...
tlsListener := tls.NewListener(tcpKeepAliveListener{ln.(*net.TCPListener)}, config)
return srv.Serve(tlsListener)
}この tcpKeepAliveListener の実装をみていくと、
func (ln tcpKeepAliveListener) Accept() (c net.Conn, err error) {
tc, err := ln.AcceptTCP()
if err != nil {
return
}
tc.SetKeepAlive(true)
tc.SetKeepAlivePeriod(3 * time.Minute)
return tc, nil
}SetKeepAlive をしたときにソケットに SO_KEEPALIVE を設定していることが分かります。
func setKeepAlive(fd *netFD, keepalive bool) error {
err := fd.pfd.SetsockoptInt(syscall.SOL_SOCKET, syscall.SO_KEEPALIVE, boolint(keepalive))
runtime.KeepAlive(fd)
return wrapSyscallError("setsockopt", err)
}さらに SetKeepAlivePeriod(3 * time.Minute) したときには TCP_KEEPINTVL/TCP_KEEPIDLE を3分に設定していることも分かります。
func setKeepAlivePeriod(fd *netFD, d time.Duration) error {
...
if err := fd.pfd.SetsockoptInt(syscall.IPPROTO_TCP, syscall.TCP_KEEPINTVL, secs); err != nil {
return wrapSyscallError("setsockopt", err)
}
err := fd.pfd.SetsockoptInt(syscall.IPPROTO_TCP, syscall.TCP_KEEPIDLE, secs)
...まとめると、Go 言語の net/http の ListenAndServeTLS を使うとき、デフォルトで TCP keepalive が有効となり、クライアントから通信がない状態で3分経つとプローブパケットを3分間隔で送ります。プローブ回数がデフォルト設定なら3分ごとに9回プローブを送り、最終的に30分経つとコネクションがクローズされます。
TCP keepalive を考慮していないライブラリ
Go 言語の標準ライブラリ net/http の設定ではクライアントと通信ができない場合は TCP keepalive により30分でコネクションがクローズされることが分かりました。netstat の出力から TCP keepalive が無効であることを確認していたため、サーバーアプリケーションのどこかでこれらの設定を無効にしているのではないかという推測がつきます。
Dragon のサーバーアプリケーションでは Graceful Shutdown 機能を提供するために manners というライブラリを利用して https サーバーを起動していました。そして manners のソースコードを調べてみたところ、manners は GracefulServer.ListenAndServeTLS を独自実装しており、TCP keepalive を有効にするような設定が行われていないことが分かりました。
開発チームは TCP keepalive を無効にする意図で manners を使っていたわけではないため、TCP keepalive が有効になっていないことに気付いていませんでした。
ロードバランサーの振る舞い
クライアントから Dragon のサーバー群への通信はロードバランサー経由で行われます。ヤフーでは Direct Server Return という仕組みで通信が行われます。ロードバランサーはクライアントからのリクエストをまとめて受け付けますが、レスポンスは実際のサーバーから返す仕組みです。
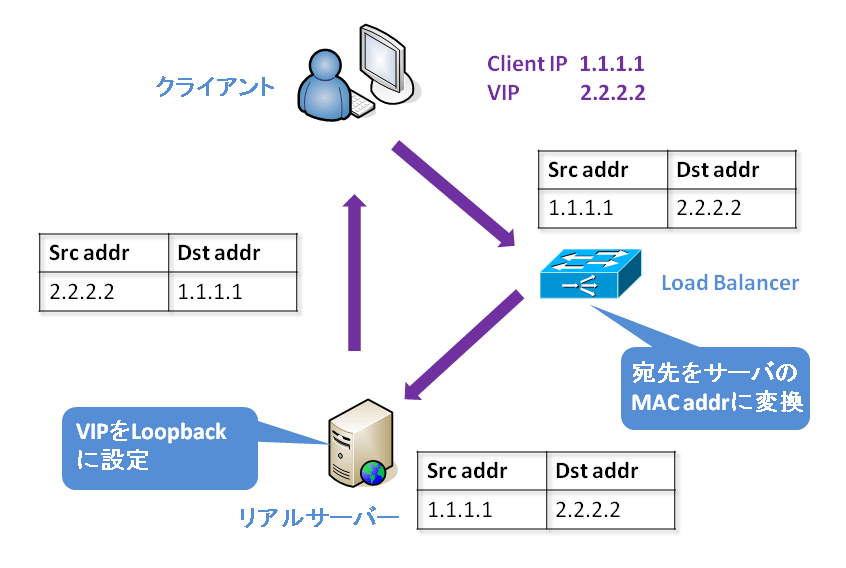
調査の後半になって分かったことですが、このロードバランサーのセッションテーブルの生存期間が2分でした。そのため、クライアントが HTTP Keep-Alive により確立したコネクションを再利用する場合、通信せずに2分以上経過すると、その前に通信していたサーバーと通信できなくなります。クライアントがクローズしようとして FIN パケットを送ったとしてもロードバランサーのセッションテーブルから削除されているため、実際のサーバーへそのパケットが届かないということも分かりました。
さらに前述した net/http の内部では TCP_KEEPIDLE を3分に設定しています。セッションテーブルの生存期間が2分だと、サーバー側から TCP keepalive の probe パケットをクライアントへ送り、その応答がサーバーに戻ってこないことも確認できました。そのため、ロードバランサーのセッションテーブルの生存時間も4分に変更することにしました。
課題を修正する
ここまでの調査結果を整理します。
- HTTPS のコネクションが確立されると、コネクション数に比例してメモリの使用量が増える
- manners ライブラリを利用していると、https サーバー側で確立したコネクションをクローズしない
- クライアントから FIN パケットが https サーバーへ届かない可能性がある
ここまで分かれば、対応方法はいくつか検討がつきますね。課題の修正も開発チームと相談しながら私がそのまま担当しました。
Go 1.8 へアップグレードする
私が調査していたのは2月上旬で2月16日に Go 1.8 がリリースされる予定でした。ちょうど HTTP Server Graceful Shutdown 機能が提供されるというのが話題になっていました。
Dragon のサーバーアプリケーションは Graceful Shutdown のために manners ライブラリを利用していました。そこで Go 1.8 へのアップグレードすることで以下の改善が見込めました。
- 標準ライブラリの Graceful Shutdown 機能を使う
- TCP keepalive を有効にする
- manners の依存関係を解消する (保守コストの削減)
これらにより調査してきた課題を解決できそうです。
Go 1.8 の Graceful Shutdown 機能に移行していていくつか気付いたことを以下の記事にまとめました。興味のある方はこちらも参考にしてください。
対応の結果
実際に修正が施されたバージョンがリリースされた後のグラフが以下になります。4/4 がリリース直後です。リリース時にサーバーが再起動されるので数値は大きく下がるのですが、なんとなく横ばいになってそうな雰囲気がみえます。
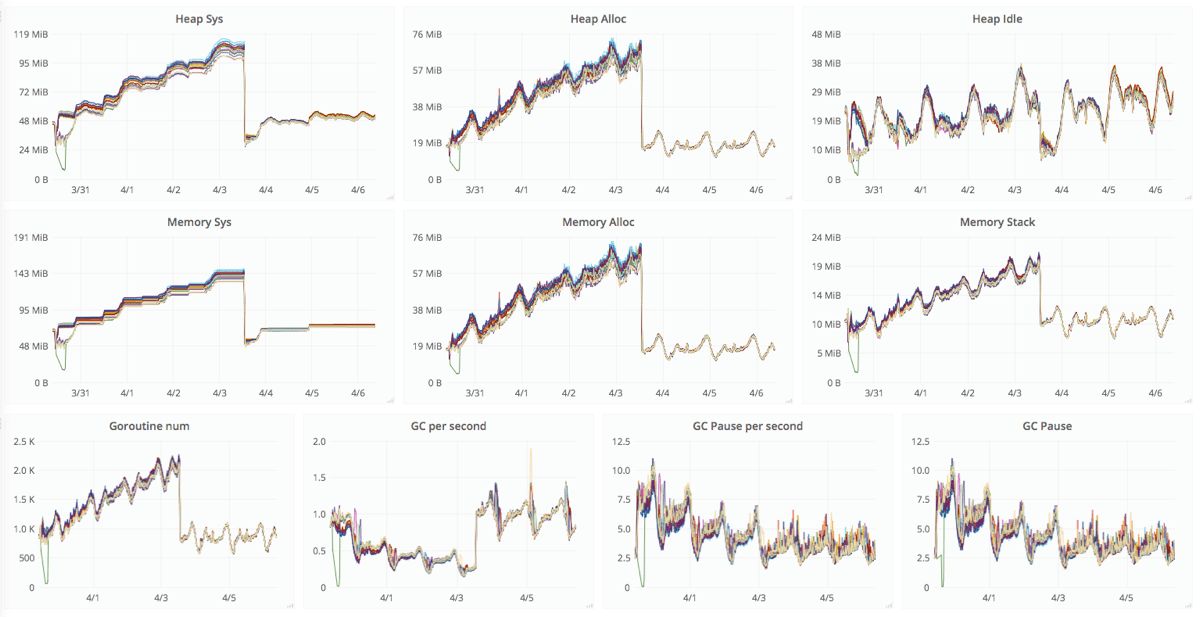
その後の経過状況も監視して改善前の右肩上がりの勾配をもつグラフから横ばいのグラフになりました。
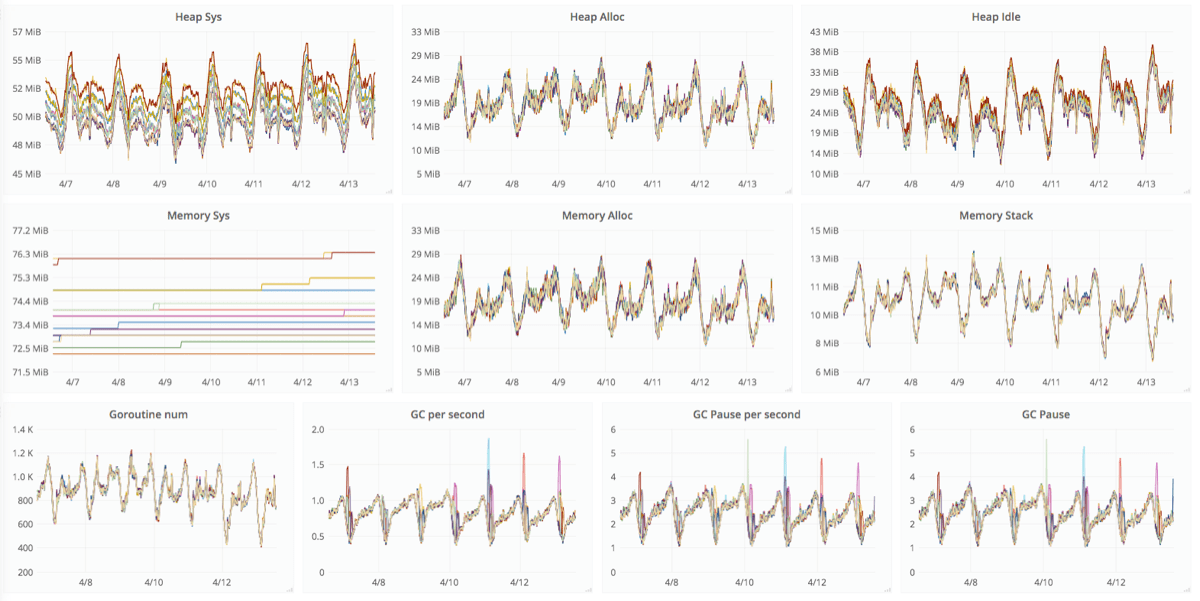
TCP keepalive が有効になった結果として通信していないコネクションがクローズされてリソース浪費の問題が解決しました。
まとめ
Dragon の運用で実際に発生したトラブルシューティングの1つを紹介しました。本稿の課題を解決するには以下のようなスキルや知識が要求されます。
- ソースコードを読んだりツールを作ったりするプログラミングスキル
- Linux のシステム管理やコマンドの知識
- ネットワークプロトコルや TCP/IP の知識
最近は SRE (サイト信頼性エンジニアリング) というキーワードを私はよく見かけるようになりました。私の所属するチームでも SRE の考え方を積極的に業務へ取り入れていこうとしています。私自身、まだまだ SRE の全体像を把握していませんが、本稿で紹介したようなトラブルシューティングはまさに SRE 業務の1つではないかと思います。
最後にヤフーではこのような課題に取り組むインフラエンジニアまたはサイト信頼性エンジニアを募集しています。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました




{kind=link}