はじめに
こんにちは。
ヤフー株式会社 データ&サイエンスソリューション統括本部データプラットフォーム本部データデリバリー部の井島&大戸です。
今回は、ヤフー株式会社(以下ヤフー)が OSS として公開したカラムナストレージファイルフォーマットの Multiple-Dimension-Spread について、開発の背景を交えて紹介します。
Multiple-Dimension-Spreadとは
Multiple-Dimension-Spread(以下MDS)はヤフーが開発したカラムナストレージフォーマットです。
大規模なデータを蓄えておく仕組みを湖として捉えたものをデータレイクといいます。
MDS はデータレイクにデータを保存、利用するためのフォーマットで、データの書き込み時にスキーマを必要とせず、カラムナフォーマットの利点である高い処理性能を両立しました。データとは行方向に複数種類の要素を持つ情報(レコード)が列方向に積み重なったもので、スキーマとは一列に含まれる要素の構造を示したものです。
これまでのデータレイクでは、データの保存形式として、主に2つの選択肢が存在しました。一方はデータを集めることに、もう一方は処理性能を高めることに注目したものです。
前者としては、テキスト形式や JSON などがあります。データの保存時にスキーマを必要とせず データの利用時に適宜設定するため、データを集める効果が高いものの、処理性能でデメリットがあります。
後者としては、Apache ORC や Apache Parquet などがあります。これらはカラムナフォーマットと呼ばれており、列単位でのデータを扱うことで、処理性能を上げることができます。しかし、データを保存するさいにスキーマが必要になる事から、データ保存時にどのように使うかの設計を行う必要があるため、気軽にデータを保存できなくなるというデメリットがあります。
このように、データ保存時の柔軟性と処理能力の間にはトレードオフの関係がありました。
この状況に対応すべく、MDS は、データレイク向けのファイルフォーマットとして、JSON のような柔軟性を持ち、カラムナフォーマット並の処理性能をコンセプトに開発されました。
ヤフーにおけるデータレイクの歴史
HDFS の導入
2010年ごろから、ヤフーでは全サービスで発生するアクセスを活用するために Apache Hadoop を利用してデータレイクの構築が始まりました。Hadoop のストレージである HDFS にはヤフーの全サービスのアクセスログが集まりました。
この頃のデータレイクのアーキテクチャは schema-on-read の考え方が主流で、データを保存するときにはスキーマやフォーマットの定義はせず、利用する時点でスキーマやフォーマットの定義を行っていました。
Hadoop を導入した初期の頃は、HDFS 上にあるデータを処理するために MapReduce フレームワークを用いたプログラミングを行っていました。
簡単な処理でもプログラミングをする必要があり、目的の結果を得るまでに時間がかかりました。また、プログラミングには専門知識が必要なことから、データを利用し始める際の抵抗要因ともなっていました。
簡単にデータを利用する
実際に Hadoop の処理に関するニーズを調査したところ、大半が簡単な集計でした。schema-on-read のアーキテクチャではデータを保存する時点では要件は厳密に定義せず、データを処理するさいに試行錯誤を繰り返します。
試行錯誤の回数を増やしたい要求に対して MapReduce によるプログラミングでは実装のコストが高いため、簡単な方法で集計を行いたいという需要が高まりました。
その後、MapReduce 上で動作し、SQL 形式でデータが処理できる Apache Hive が登場しました。SQL 形式という手軽さからエンジニア以外の人でも簡単に Hadoop を使った処理が可能です。
また、SerDe という仕組みを用いて参照したデータの解釈の方法を登録する事により、構造化データから非構造化データまで SQL 形式でデータが処理できる仕組みを提供しています。
この手軽さから、Hive はヤフーでも取り入れられ、さまざまな業務で利用されるようになりました。
データ量の増加
データの処理が身近になったことにより、データレイクで保存されているデータに対しての処理量は爆発的に増えていきました。
データはイベント発生時にテキストやバイナリ形式のメッセージとして発生します。schema-on-read のアーキテクチャでは、このメッセージを一つの単位としてそのまま書き込み、利用時に複数フィールドからなるレコードとして解釈します。このため、データの展開、データ利用ツール内部のデータ形式への変換などに多くの CPU リソースが消費されてしまいます。
Hive の普及により処理が爆発的に増加したため、ハードウェアでのスケールだけでは、増え続けるデータ量に追いつかなくなっていきました。
データ利用要件の変化
当初、データ処理はバッチ形式で行われることが多く、一定時間あたりの処理件数としてのスループットが重要でしたが、ビジネス要件としてインタラクティブにデータ処理を行う需要も増えてきたことから、要求を出してからレスポンスが来るまでの時間としてのレイテンシも重要になってきました。
schema-on-read のアーキテクチャでは、データはテキスト形式としてそのまま保存、データ利用時に解釈が行われることから、これにかかる CPU コストの削減も必要でした。このように、データ量の増加と処理量の増加によって、schema-on-read のアーキテクチャでは利用者の要件を満たす事が困難になりました。
カラムナフォーマットの導入
そこで採用されたのがカラムナフォーマットです。
カラムナフォーマットは 2010年に Google が発表した Dremelについての論文 で述べられているストレージフォーマットです。これを元に OSS として実装された ORC や Parquet などが誕生しました。
カラムナフォーマットでは、イベント発生に伴い送られてくるメッセージを予め複数のフィールドからなるレコードデータへ変換したものについて、列単位でデータを保存し、処理に必要な項目のみを参照する事によって、データの展開、パース処理などにかかる CPU リソースを削減する事が可能です。また、列方向のデータ要素は同じ種類であることから圧縮効率が良くなるため、より多くのデータを保存することが可能です。
図:従来のフォーマットとカラムナフォーマットの読み込みの違い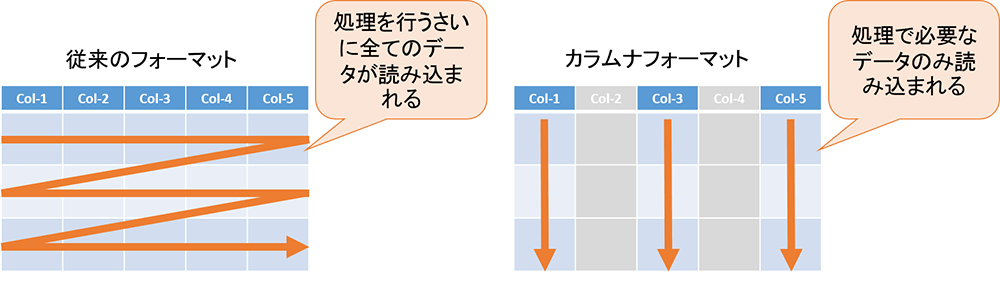
ヤフーでは ORC を採用し、これまでテキストデータで保持していたデータをカラムナフォーマットに変更した事により、データレイクの領域において処理性能の向上を実現しました。
MDS の開発・導入
既存カラムナフォーマットの課題
ORC の導入により、処理性能および圧縮効率の向上が行われたものの、ORC では書き込みの際にスキーマ情報が必要であったことから、データの保存に対する気軽さが失われてしまいました。
既存のカラムナフォーマットでは、レコードをカラム方向(フィールド単位)で扱うため、レコードのデータ構造(スキーマ)が必要です。レコードを格納する際に、スキーマを元にレコード形式のデータを分割、再構成することで、カラムナフォーマットへと変換します。
図:メッセージからカラムナフォーマットへの変換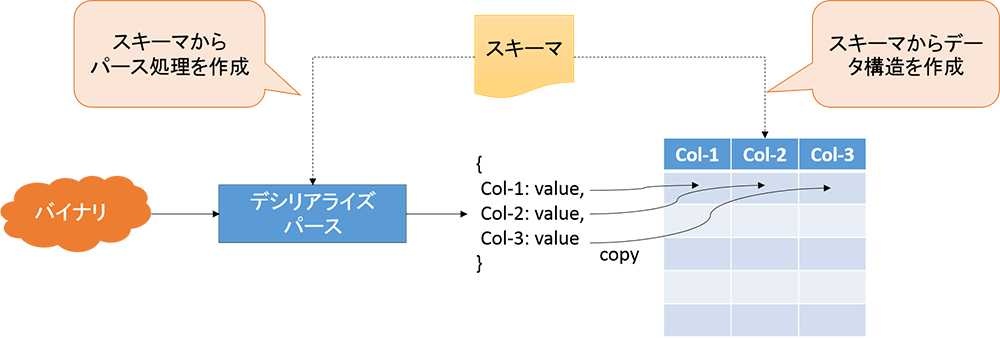
一方、データの利用時においても、保存時に用いたスキーマが必要です。このことから、既存のカラムナフォーマットでデータレイクを構築する場合には、保存時に用いたスキーマを管理し、利用時に不整合が起こらないようにバージョン管理を行う必要がでてきます。
図:スキーマ管理が必要な構成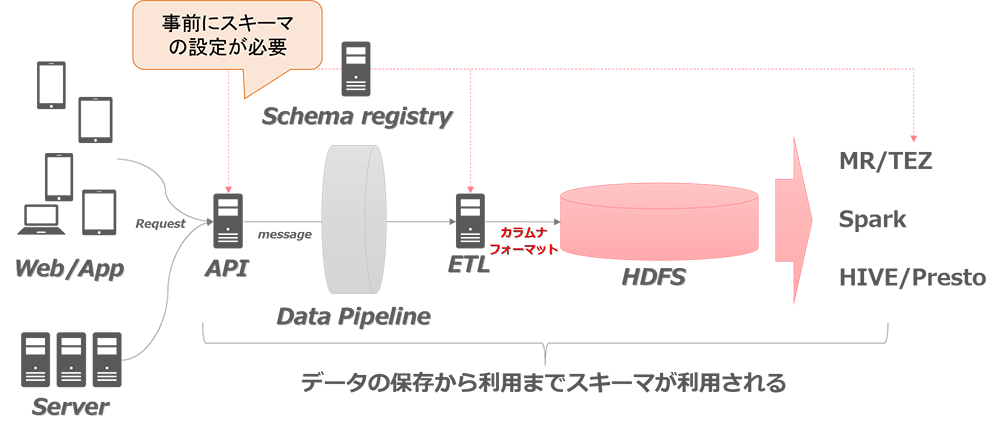
また、スキーマはデータの保存時と利用時で適切に同期が取られている必要があることから、その変更は簡便に行うことができません。そのため、変更が少なくなるようなスキーマの設計が必要になります。
なお、柔軟性の確保するために、Map 型を用いる方法が考えられます。Map 型はレコード内のデータ項目(フィールド)の追加、削除を行うことができます。しかし、Map 型のデータは key, value の2つ組データの配列として構成されていることから、カラムナフォーマットにおいても、Map 型データは列方向のデータとして扱われなくなってしまうため、カラムナフォーマットのメリットを活かすことができません。
図:Map型のデータ構造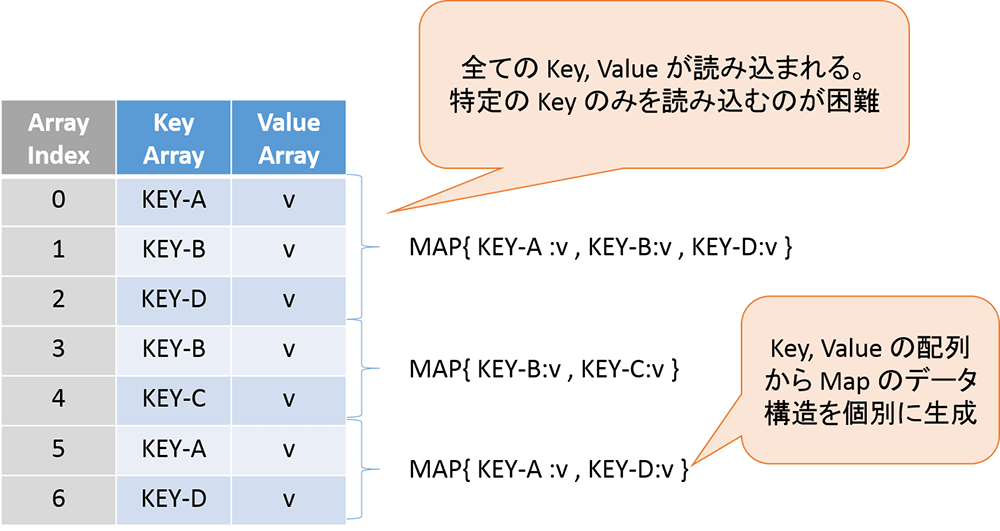
スキーマを必要としないカラムナフォーマット
この課題に対応するためには、データの保存時における書き込みにスキーマを必要とせず、カラムナフォーマット並みに処理性能に優れたフォーマットが必要でした。
MDS では入力されるメッセージから動的にスキーマを形成することによって柔軟性を実現するとともに、列方向でデータを保存することで既存のカラムナフォーマットと遜色ない処理性能を実現しています。
図:CPU 時間の比較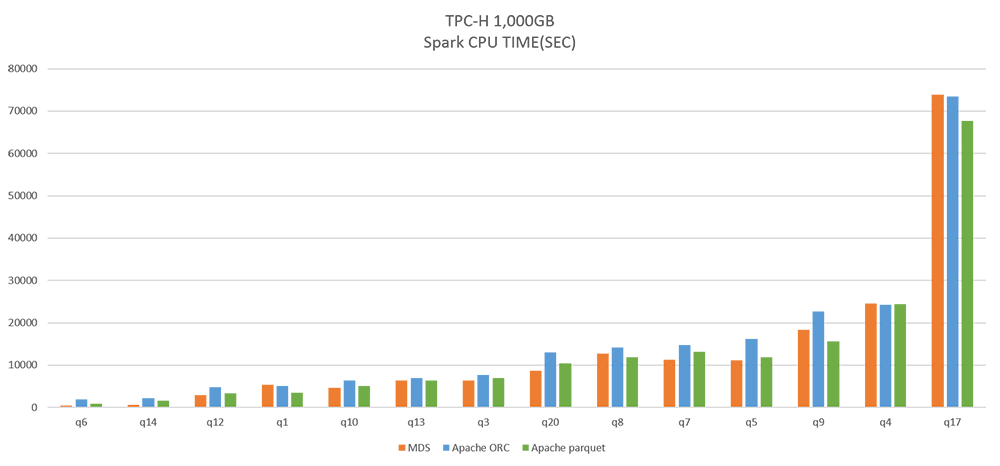
上図は、MDS と ORC, Parquet における処理性能の比較として、TPC-H 1,000GB のベンチマークを示しています。本ベンチマークによると、処理性能において同等のパフォーマンスとなっていることがわかります。
スキーマレスデータパイプラインの構築
現在、MDS はヤフーのデータレイクにおけるフォーマットとして利用されています。
各サービス、アプリなどから送信されるメッセージは API 層で JSON に変換しています。これによって、データレイクシステム内では、メッセージや書き込み時のスキーマを管理する部分を省略できるため、システム全体をシンプルに構築することが可能になっています。
図:スキーマレスの構成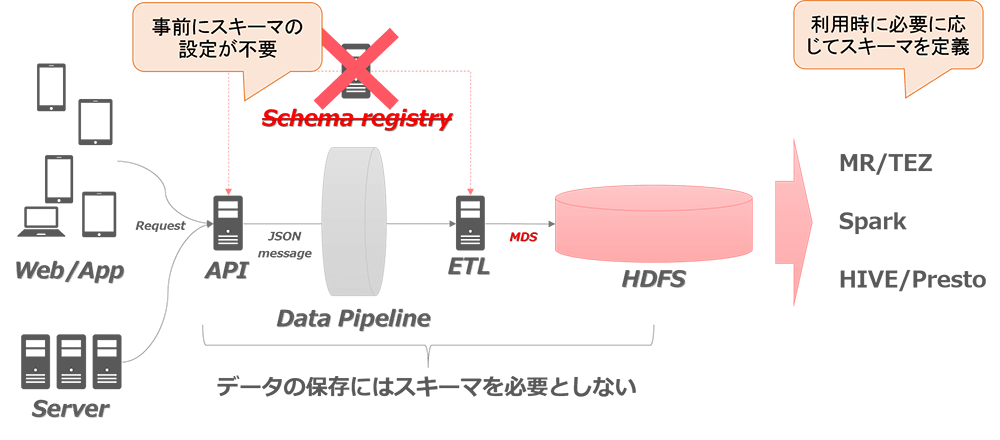
データの利用時において、Hive による処理を行う場合にはテーブル定義にスキーマが必要ですが、データ保存時におけるメッセージのスキーマと同じである必要は無く自由に定義することが可能です。
まとめ
今回はヤフーがOSSとして公開しているカラムナストレージファイルフォーマットである MDS と、開発の背景について紹介しました。
さいごに
MDS については資料も公開しています。また、MDS についての活動は リポジトリ にまとめています。興味を持たれた方はぜひアクセスしてみてください。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



