シュティフ ロマン(データプラットフォーム)
Apache Igniteコミッター
@rshtykh
はじめに
近頃、急激に増量していくデータはもはやタイムリー且つ正確なデータ処理を困難にする。そのような中で、複雑なETLを無くしてコストを削減でき迅速なデータ処理の可能性を実証するインメモリコンピューティング技術が注目されている。例えば、2015年からスタートしたIn-Memory Computing Summitだが、年1回の少人数イベントから、1年にインメモリシステムの開発者と利用者を2回集めるイベントまで発展してきた。
インメモリコンピューティングプラットフォーム(データベースシステム)では、なるべくメモリ上で高速なデータ処理を行うが、メモリの有限性をはじめ様々な理由によりディスクの利用もまだよく求められる。そのため、高速なメモリ上の処理を中心に据え置きながらビッグデータシステムに必要とされるディスクを用いた永続性機能を提供するチャレンジがある(不揮発性メモリ利用も考えられるが、本稿では対象外)。
本記事では、Apache Ignite(執筆時点のバージョン) 2.0から新オフヒープページメモリアーキテクチャを紹介する。このアーキテクチャは2.1から公開されるメモリ空間をディスクまで拡張するdurable memoryアーキテクチャの中核となる。
インメモリコンピューティングプラットフォームにおけるビッグデータチャレンジ
RAMの価格低下の傾向、使用量増加や性能向上に伴い、一般的なデータベーステーブルやアプリケーションデータをメモリ上に持ち高速なデータ処理が可能となってきた。そのなか、メモリをキャッシュではなくプライマリデータストアにし、ディスクのレイテンシーやそのI/O制御の遅延を無くした高性能データ処理を実現するインメモリデータグリッドは、インメモリコンピューティングシステムの大半を占めると言える。そういったデータグリッドは一般的に多機能であるため、グリッドと呼んでもいいデータベースやプラットフォームにまで発展してきたので、以降はインメモリデータプラットフォームと呼ぶこととする。
ディスクストレージ
Apache Ignite(以下、Ignite)をはじめ、Apache Geode, Hazelcast等のような代表的なインメモリデータプラットフォームは、基本的にメモリ上にデータを持ち処理を行うが、億単位のレコード数になると、データの永続化を行う永続的ストレージ(Persistent Storage)の力を借りることも可能としている。メモリ上のホットデータにms以下のスピードでアクセスでき、永続化レイヤーを用いることによりメモリにないデータもディスクから持ってきて処理を行うこともできる。それに、障害発生時のデータの永続性、データプリロードなしのクラスター再起動などもできる。
Igniteの場合、オープンソースとしてリリースされた時点から、データ永続化はjavax.cache.integration.CacheLoader と javax.cache.integration.CacheWriterAPIを用いたJCache仕様(JSR 107)により可能である。そのAPIを使ってOracle, MySQL, Cassandraのようなデータベースを外部永続化レイヤーに利用し、ライトスルーやリードスルーを実現する。また、ライトパフォーマンスの向上のため、非同期のライトビハインドも実現できる。
Igniteは両方のインターフェースを継承しトランザクション処理に優しいorg.apache.ignite.cache.store.CacheStoreを提供している。
データ永続化を実装するには、最低限、次のステップを実行する。
- CacheStoreインターフェースのメソッドを実装する
- リードスルー(ライトスルー)を
CacheConfigurationのcacheStoreFactoryプロパティにて設定する
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<!-- キャッシュ名 -->
<property name="name" value="myCache"></property>
<!-- cacheStoreFactory設定 -->
<property name="cacheStoreFactory">
<bean class="javax.cache.configuration.FactoryBuilder" factory-method="factoryOf">
<constructor-arg value="my.company.store.MyObjectStore"></constructor-arg>
</bean>
</property>
<!-- read/write throughを有効に -->
<property name="readThrough" value="true"></property>
<property name="writeThrough" value="true"></property>
<property name="queryEntities">
...
</property>
</bean>これにより、データロード、PUTやDELETEを行う際、永続的ストレージへのアクセスが行われる。詳しくは、このサンプルを参照のこと。
同様に、Hazelcastはデータ永続化のためにMapStoreとMapLoaderを提供している。またHazelcast IMDG Enterprise HDはHot Restart Persistenceクラスターのノード状態の永続化により迅速な再起動を実現している。Apache Geodeはディスクのみの永続化をサポートしているが、データストアのサポートも計画しているようである。
JVMベースのシステムにおけるガベージコレクション
本稿で言及してきたインメモリデータプラットフォームはJVMベースのシステムであるため、大量データを扱う時にガベージコレクション(GC)による性能低下の可能性がある。
その対策として、Azul Zing with Azul C4 (Continuously Concurrent Compacting Collector)のようなクラスターのスケーラビリティを低下させるstop-the-world (SWT)現象を除外するJava仮想マシンを使う方法がある。
そのほかに、Javaヒープ領域の利用を最低限にしヒープ外のメモリを利用する方法もある。オフヒープメモリを活用することにより、Java GCの対象となるオブジェクトの数を減らしSWTを避けることができる。
現在、全ての人気インメモリデータプラットフォームにはオフヒープ機能がある。例えば、Apache Geodeのオフヒープ機能についてここで参照できる。
また、有償だがオフヒープはHazelcast IMDG Enterprise HDは一機能としてオフヒープを提供している。
Igniteにはバージョン2.0まで階層メモリアーキテクチャの一レイヤーであり、LIFO, FIFO等の除去ポリシー設定によりヒープメモリから溢れたデータをオフヒープ領域に移動させる機能がある[図1](OFFHEAP_TIEREDモードに設定すれば、ヒープメモリを迂回することもできる)。
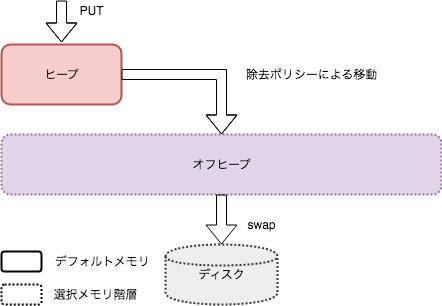
図1 階層メモリアーキテクチャ: ONHEAP_TIEREDモード
Apache Ignite新メモリアーキテクチャ
Ignite v2.0から、オンヒープ中心の仕組みは破棄され、新オフヒープページメモリアーキテクチャが導入された。データはオフヒープに格納され、必要に応じて(例えば、READパフォーマンス向上のために)オンヒープを有効にすることができる。これにより、大量データをメモリ上に展開してもJava GCによる性能低下を発生させず、高速かつ安定したデータアクセスが可能となった。また、システムのメモリ使用の詳細なチューニングが容易になった。例えば、どのノードにどのようにメモリを割り当てるか、個別に各キャッシュのメモリ使用ポリシーを何にするか、が自由に決められる。
オフヒープ構造はOS仮想メモリのページング概念に類似している。オフヒープに使われるメモリ領域は固定サイズのページに分割されメインメモリにマッピングされる。そのため、メモリだけではなく、ディスクへのページマッピングが容易に実現できる。また、既存のRDBMS SQLエンジンは基本的にページ扱いに最適化されているため、SQLパフォーマンス向上も見られる。
さらに、IgniteコミュニティーがSQLサポート(SQL ANSI-99準拠)を向上させる多大な努力も踏まえ、Igniteはメモリファーストな分散データベースシステムとは呼ばれている。
実際、バージョン2.1から、GridGain社からASFに寄贈されたIgnite Persistent Store(別の機会で紹介)というディスクベースの分散データストアがIgniteの一部になり、オフヒープメモリとの透過的連携も実現される。これにより、この後で詳しく説明するページメモリアーキテクチャをディスクまで拡張し、全データはディスクに保存され、そのサブセットをメインメモリへ(RAMにあるデータは必ずディスクにも存在する)というdurable memoryアーキテクチャを可能とする。
このアーキテクチャを用いることによって、例えば、クラスターにあるデータに対してクエリーを発行すると、メモリ上やディスク上の両方の全データが両方対象となり、全データをメモリに持って行かずに高速な処理が可能となる。また、今まで実現困難だったクラスタースナップショット(バックアップ)が実現できる。
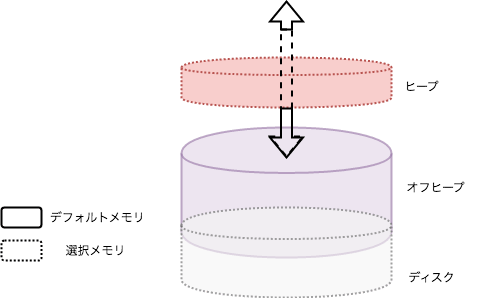
図2 durable memory
ページメモリアーキテクチャ
Igniteノードの使用メモリはメモリリージョンに分けられそれぞれはキャッシュのメモリに用いられる。
デフォルトで一つのメモリリージョン(RAMの約8割)が割り当てられ全キャッシュに使われるが、複数のメモリリージョンを作成しキャッシュに特殊な設定を持たせることも可能である。
例えば、以下はorg.apache.ignite.configuration.MemoryPolicyConfigurationを設定しmyCacheに8Gbのメモリリージョンを割り当てる。
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<!-- メモリ設定 -->
<property name="memoryConfiguration">
<bean class="org.apache.ignite.configuration.MemoryConfiguration">
<!-- デフォルトメモリリージョンサイズ変更 -->
<property name="defaultMemoryPolicySize" value="#{4L * 1024 * 1024 * 1024}"/>
<!-- カスタムなメモリポリシー -->
<property name="memoryPolicies">
<list>
<bean class="org.apache.ignite.configuration.MemoryPolicyConfiguration">
<property name="name" value="8GB_MEMORY"/>
<!-- 1 GB initial size. -->
<property name="initialSize" value="#{1024 * 1024 * 1024}"/>
<!-- 8 GB maximum size. -->
<property name="maxSize" value="#{8* 1024 * 1024 * 1024}"/>
<!-- データページ除去 -->
<property name="pageEvictionMode" value="RANDOM_2_LRU"/>
</bean>
</list>
</property>
</bean>
</property>
<property name="cacheConfiguration">
<list>
<!-- 上記のメモリリージョンをキャッシュに使わせる -->
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="memoryPolicyName" value="8GB_MEMORY"/>
<!-- キャッシュ名 -->
<property name="name" value="myCache"/>
</bean>
</list>
</property>
</bean>メモリリージョンに割り当てられたバイト配列(セグメント)はいくつかの種類の固定サイズ(MemoryConfiguration#pageSizeにて設定可能)のページに分割される。
ページは、大きく以下の3つに分類される。

図3 ページメモリ構造
- データページ
- key&valueを格納
- B+ Treeやインデックスページ
- インデックス保持にB+ Treeが利用されいる
- データページを参照するインデックスは2種類がある
- プライマリキーにハッシュインデックスを利用
- カスタムインデックスにソートインデックスを利用
- カスタムインデックスは、例えば、
@QuerySqlField(index = true)アノテーションを利用して設定できる。詳しくは、Schema and Indexesを参照のこと。
- カスタムインデックスは、例えば、
- free listメタデータ
- free listはデータ挿入に必要なページが動的に割り当てられ、空ページの管理などに使われる双方向連結リスト(doubly linked list)である。全てのページをそれぞれのキャパシティー毎でグループ化し、リストで連結させ、ページプールによるページのアロケーション・デアロケーションを簡単にする(
org.apache.ignite.internal.processors.cache.persistence.freelist.FreeListやメモリセグメントのorg.apache.ignite.internal.processors.cache.persistence.pagemem.PageMemoryImpl$PagePool参照)。
これにより、動的ページ割り当てに生じるメモリ断片化が緩和され、コンパクションに必要とされるCPUサイクルをアプリケーション動作として使える。
- free listはデータ挿入に必要なページが動的に割り当てられ、空ページの管理などに使われる双方向連結リスト(doubly linked list)である。全てのページをそれぞれのキャパシティー毎でグループ化し、リストで連結させ、ページプールによるページのアロケーション・デアロケーションを簡単にする(
データ挿入やルックアップがどういう風に行われるかはIgnite Virtual Memoryを参照。
終わりに
本記事では、Javaガベージコレクションの影響を受けない安定した動作を目指してApache Igniteのオフヒープ中心なメモリアーキテクチャのシフトに注目して解説を行った。この新メモリアーキテクチャにより、メモリ空間をディスクまで拡張するdurable memoryアーキテクチャも可能となり、システムの耐障害性やパフォーマンス向上が実現可能となった。
また、インメモリコンピューティング分野は、開発中のアプローチが多く多様性のある分野のため、本稿ではインメモリコンピューティングプラットフォームにおけるビッグデータへのチャレンジの一部のみに焦点を当てた。
参考URL
- Apache Ignite: https://ignite.apache.org/
- JSR 107: https://github.com/jsr107/jsr107spec
- Apache Geode: http://geode.apache.org/
- Hazelcast: https://hazelcast.com/
- Apache Ignite: How to Read Data From Persistent Store: https://dzone.com/articles/apache-ignite-how-to-read-data-from-persistent-sto
- Azul Zing with Azul C4: https://www.azul.com/products/zing/
- Off-heap Tiered Memory: https://apacheignite.readme.io/v1.9/docs/off-heap-memory
- Ignite Virtual Memory: https://apacheignite.readme.io/docs/page-memory
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



