こんにちは、Yahoo! JAPAN 研究所のエンジニアの田口・山下と、Yahoo!ニュースエンジニアの小林です。
さっそくですが、皆さんはYahoo!ニュースを利用している中で、「ココがポイント」というアイコンを見たことはありませんか?これは読者の理解をよりいっそう深めるための施策として、そのニュース記事を作成した編集者が作っているQ&A コーナーです。ニュースに関する情報をQ&A形式で整理して読者の理解を支援することを目指す一方で、編集者は編集時に大量の時間と労力がかかってしまうという課題を抱えています。
今回、私たちはこの課題を解決するためのAIシステムを開発し、編集者の業務効率化とニュース記事に対する読者の理解支援を目指しました。
ニュースの「Q&A コーナー」とは
Yahoo!ニュース トピックスでは、提携するコンテンツパートナーから配信されるニュースの中から価値が高いと編集者が判断したものを厳選して掲載しています。
また、読者がニュースに対する理解をより深めるため、ニュース画面の下部に Q&A コーナーを設けています。ニュースでの知りたいポイントに対し、その解を得られる記事を Q&A 形式で提示しています。読者はニュースの理解を深め、情報をより効率的に吸収できます。
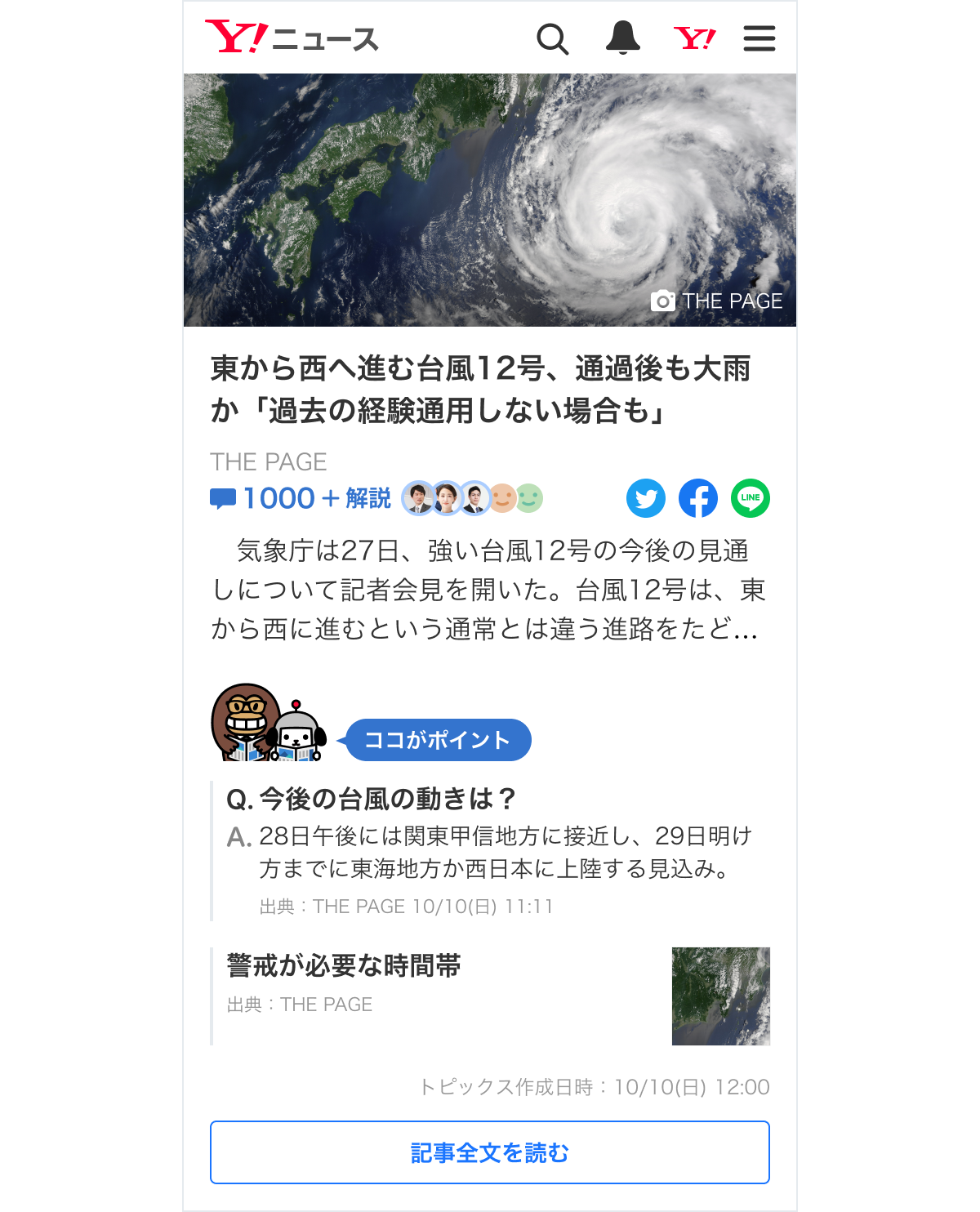
膨大なコンテンツ作成を AI で効率化したい
しかし、この Q&A コーナーの運営には独自の難しさがあります。Yahoo!ニュース トピックスでは、毎日約 100 本のニュースを選んで掲載しており、それぞれのトピックに対して Q&A や図解、テキストリンクを使って詳しく解説する作業が必要です。
この多くのトピックスに対する Q&A の作成は、その作業量や作業の複雑さから、編集者にとって大変な労力を要しています。
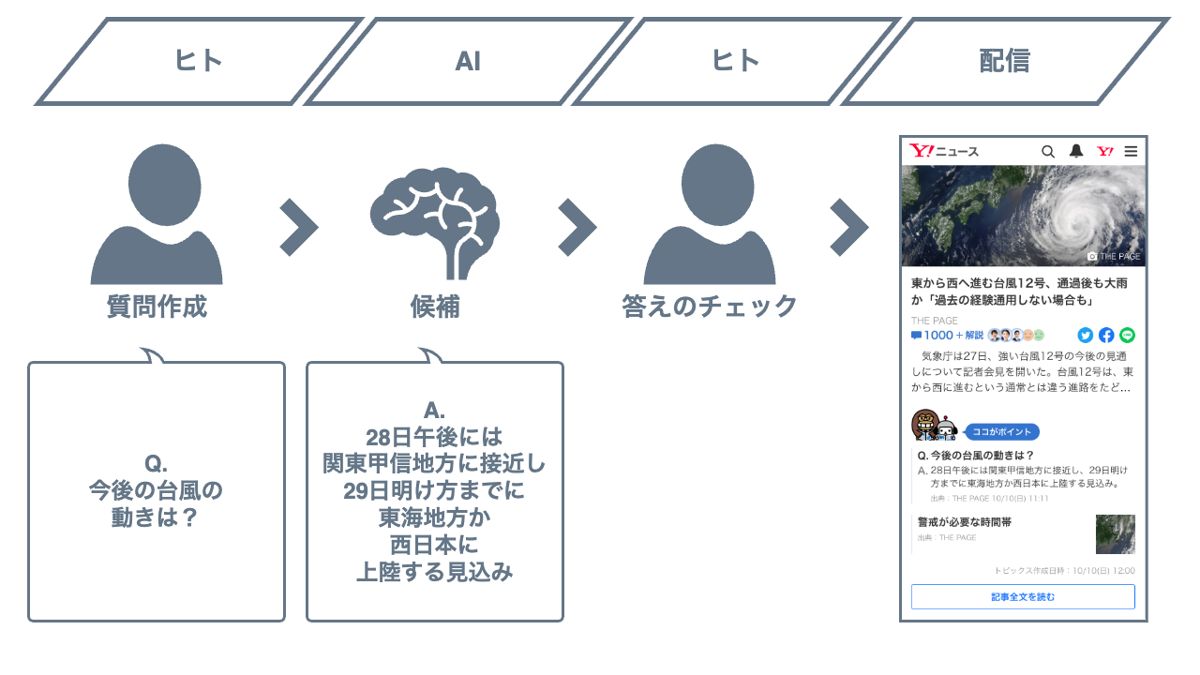
「多くの Q&A コンテンツを作成するのは大変」という課題に対し、人間と AI の協調によって編集作業が効率化する解決策を考えました。具体的には、Yahoo!ニュース上で公開されている膨大な記事から質問に答える記事を見つけ出し、記事の中でどの部分が答えに該当するかを示す AI システムを開発しました。
編集者は質問を考えてシステムに入力するだけで、AI がその答えとなる候補を迅速に見つけ出せます。これにより、Q&A コンテンツの作成の効率化が可能となります。
しかし AI の判定も100%正解ではないため、この候補を編集者がレビューしてから配信するという流れを組むことで、コンテンツのクオリティーを担保しています。
「検索システム」と「自然言語処理 AI」を組み合わせ解決
編集者が入力した質問をもとに、膨大な数の記事からその答えを見つけ出すための、具体的なロジックと実装のポイントについて解説します。
この課題に対処する一つのアプローチとして、検索システムと自然言語処理 AI を組み合わせる方法があります。
私たちの開発した AI システムでは、検索システムと自然言語処理 AI の組み合わせる方法である Retriever-Reader アーキテクチャ[1] を応用しています。Retriever-Reader アーキテクチャは、大量の文書から質問文への答えを含む文書を取得する「Retriever」と、取得した文書から具体的な答えを抽出する「Reader」の 2 つの部分から構成されています。
まずは検索によって質問文への答えが含まれそうな記事を絞り込み、次にその中から答えとなる引用箇所を抽出、という2ステップにすることで効率的に結果を得られる仕組みです。
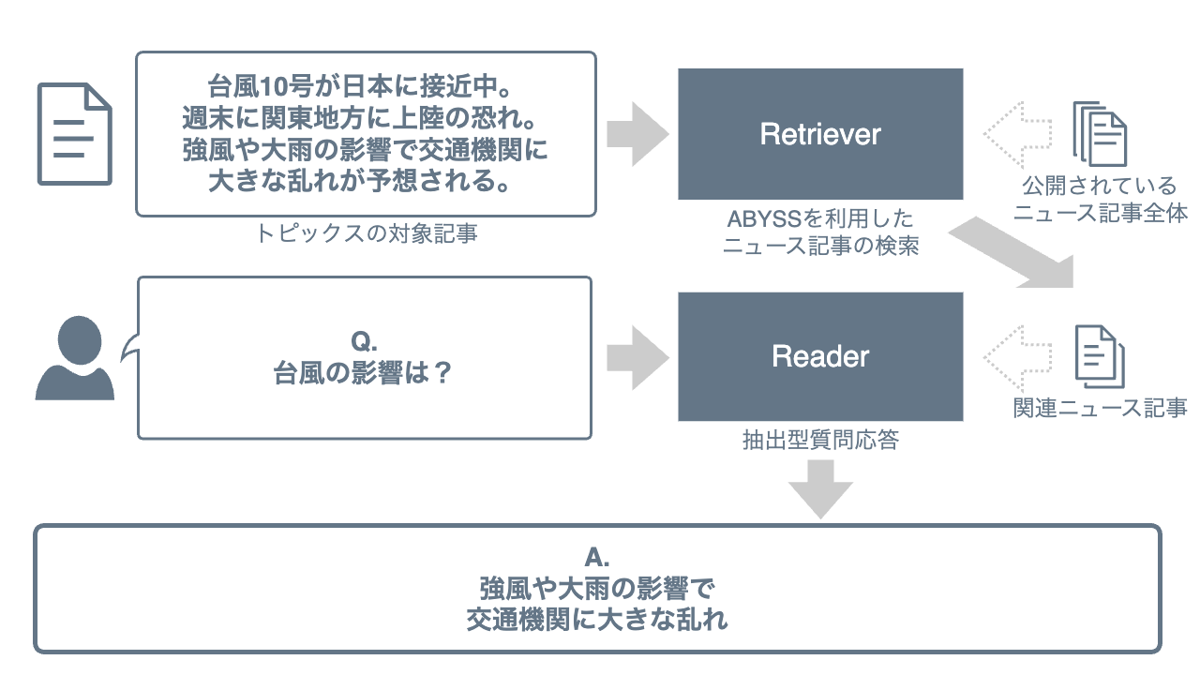
Retriever:「検索システム」で答えを含みそうな記事を見つけ出す
質問文に対する答えを含む記事を探すために、Apache Solr ベースの検索システム、ABYSSを活用しました。質問文は「背景は?」「何があった?」などと簡潔に提示されることが多いです。
これら質問では、何の話題について尋ねているのか、コンテキストが明確ではありません。そのため、私たちはトピックスに採用された記事に類似する記事を探し、その中から答えを見つけるというアプローチを採用しました。このアプローチは、「同じ話題の記事であれば質問に対する答えを含む可能性が高い」という仮定に基づいています。
類似する記事を探すために、Solr のMoreLikeThisという機能を利用しました。MoreLikeThis は、特定のドキュメントに対して類似した記事を検索できる機能です。この機能は、BM25 のような単語とドキュメントに対するスコアリングアルゴリズムを用いて実現しています。
このアルゴリズムは、文章内で頻繁に出現し、他の文章ではあまり出現しない単語に高いスコアを付けるという特性を持っています。その結果、ドキュメント中から重要単語を抽出し、それらの単語を用いて他の記事をスコアリングすることで、類似記事を探せます。

この機能を活用すると、同じ話題の記事の、質問文への答えが含まれると期待される記事を効率的に探せます。
Reader: 「自然言語処理 AI」で記事から質問に対する答えを見つけ出す
Readerでは、抽出型質問応答という自然言語処理技術を活用しています。これは、テキストから質問に対する具体的な答えを直接抽出するもので、文書内の特定の部分を直接引用して答えを提供します。
AI が文書と質問を入力として受け取り、答えが文書内のどの範囲に存在するかを出力します。これにより、対象となる情報の位置を特定し、必要な情報を取り出せます。
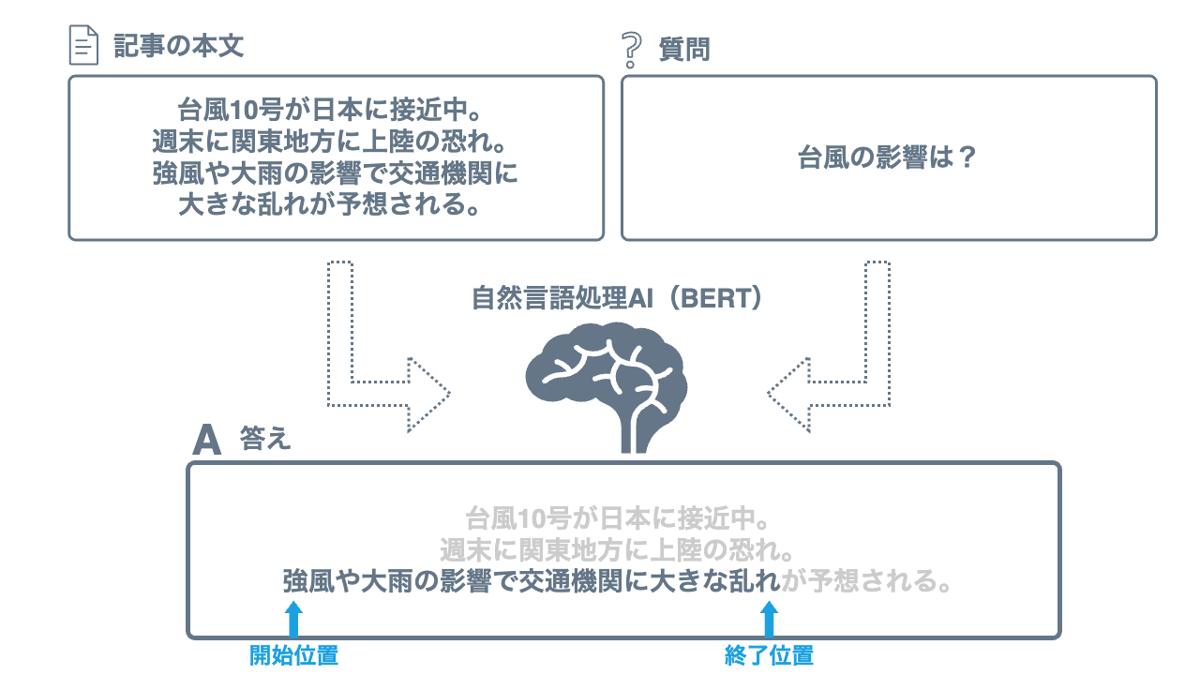
Readerの背骨となるのが、自然言語処理の世界で注目を浴びている BERT[2]というモデルです。BERT は、Transformer という強力な構造を背後に持ち、文章の文脈を深く理解できます。具体的には、質問や記事の文脈を考慮して関連性の高い部分を抜き出せます。
一方、ChatGPT などの生成 AI を使うアプローチも考えられました。しかし、生成 AI のアウトプットはうそを含む可能性があり、その真偽の確認に編集者が時間を費やす可能性があります。そのため、情報の信頼性と効率性を重視して、今回は BERT を利用した抽出型の手法を選択しました。これにより、読者に対して信頼性の高い情報を迅速に提供できます。
この BERT モデルは、日本語言語理解ベンチマーク JGLUEの質問応答データセットである JSQuAD や、社内で作成した文書と質問と答えのデータセットを使用して作成しています。このデータセットを利用することで、システムは読者の質問に対する最も適切な答えを抽出できます。
リリースの流れ
Retriever-Reader アーキテクチャのうち、「検索システム」である Retriever は既存システム(ABYSS)を利用しているのですが、「自然言語処理 AI」である Reader 部分は構築する必要があります。ヤフーでは AI システムを簡単に構築/管理できる仕組みがあります。
ヤフーの社内 AI プラットフォーム
世の中には、機械学習モデルのためのオープンソースサービングシステムがいくつか存在します。Tensorflow Serving や Triton Inference Serverなどが該当します。これらはインターフェースに HTTP/REST や GRPC を採用しており、API で推論できる AI システムを簡単に作れます。
CuttySark は上記のサービングシステムを簡単に構築/管理できるヤフー内製のマネージドサービスです。デプロイ/スケーリングする仕組みや、機械学習モデルデータを保管しておくための S3 との連携など、非常に柔軟なシステムを作れるようになっていますので、いちいち自前でサーバを用意し、システムを自作する必要がほとんどありません。
今回は CuttySark を活用し、サービングシステムに Triton を採用した上で爆速構築を実現しています。

上述したように、CuttySark の役割はオープンソースサービングシステムをより簡単に構築することです。つまり、CuttySark の上に Triton が乗っかってくるようなイメージです。さらに、 S3 とデータを同期してサービングシステムにロードする仕組みが備わっているため、任意のモデルデータを簡単に読み込めます。
また、一般的に推論システムのインターフェースにおいては、ユーザーと機械学習モデルが互いに内容を解釈できるための前後処理の必要な場合がほとんどで、今回も例外ではありません。
Triton ではバックエンドとして幅広いサポートを行っており、 TensorRT や ONNX Runtime、PyTorch などのさまざまな機械学習モデルに対応しているのはもちろんのこと、前後処理などのために Python にも対応しています。これらを組み合わせて1つの推論パイプラインを構築できるため、Triton だけでシステムが完結します。最低限の記述フォーマットに従って、さまざまな機械学習モデルの要件に合わせた柔軟な記述を行えます。
CuttySark の活用例や紹介は他記事でも触れています。ぜひご覧ください!
デプロイ
Triton 関連のセットアップを終えたら、あとは CuttySark にデプロイするだけです。CuttySark は、オープンソースサービングシステム起動設定をラップしているため、利用者はサービングシステムの選択や機械学習モデルを保存している S3 のパス、スケーリングの設定などの CuttySark 用の構成ファイルを1つ用意するだけでデプロイが完了します。
{
{
name: "qa-system",
model: { "name": "reader", "uri": "s3://<path>" },
deploy:
{
replicas: 2,
resource: { "cpu": "2", "memory": "5Gi" },
scheme: "https",
framework: "triton",
triton: { "version": "23.05" },
},
},
}上記は構成例ですので、実際はもっと細かい設定が必要になりますが、それでも数十行程度で完結できます。
デプロイコマンドもシンプルで、CuttySark に指定した構成ファイルを渡すのみです。更新する際も構成ファイルの差分を読み取ってくれるので、デプロイ時と同様のコマンドを実行するだけでローリングアップデートしてくれます。デプロイが完了したら、自動でエンドポイントが生成されます。
利用イメージ
今回は HTTP/REST を採用していますので、下記のようなイメージで利用します。なお、API のパス定義は採用しているサービングシステムの仕様に沿うので、今回は Triton のリクエスト形式で実行できます。Triton ではPOST /v2/models/:name/inferという形で推論リクエストを送ります。フォーマットもある程度 Triton のお作法にのっとる必要があります。
# request
curl -X POST -H "Content-Type: application/json" -d '{
"inputs": [
{
"name": "q",
"datatype": "BYTES",
"shape": [1, 1],
"data": ["台風の影響は?"]
},
{
"name": "context",
"datatype": "BYTES",
"shape": [1, 1],
"data": [
"台風10号が日本に接近中。今週末に関東地方に上陸の恐れ。
強風や大雨の影響で交通機関に大きな乱れが予想される。"
]
}
]
}' <CuttySarkエンドポイント>/v2/models/qa-system/infer
# response
{
"model_name": "qa-system",
"model_version": "1",
"outputs": [
{
"name": "start_and_end",
"datatype": "INT64",
"shape": [
1,
2
],
"data": [
198,
362
]
}
]
}GPU 対応
CuttySark は GPU による稼働も可能なため、GPUに対応している OSS のサービングシステムとの親和性が高まり、より高速な推論サーバを稼働できました。今回構築したシステムでは、CPU 稼働で推論のレスポンスは10 秒程度でしたが、GPU を利用することで250ms程度まで短縮できました。
成果
AI システムのパフォーマンス
AI システムのパフォーマンス結果をご紹介しようと思います。まず、ニュースの評価データについて説明します。
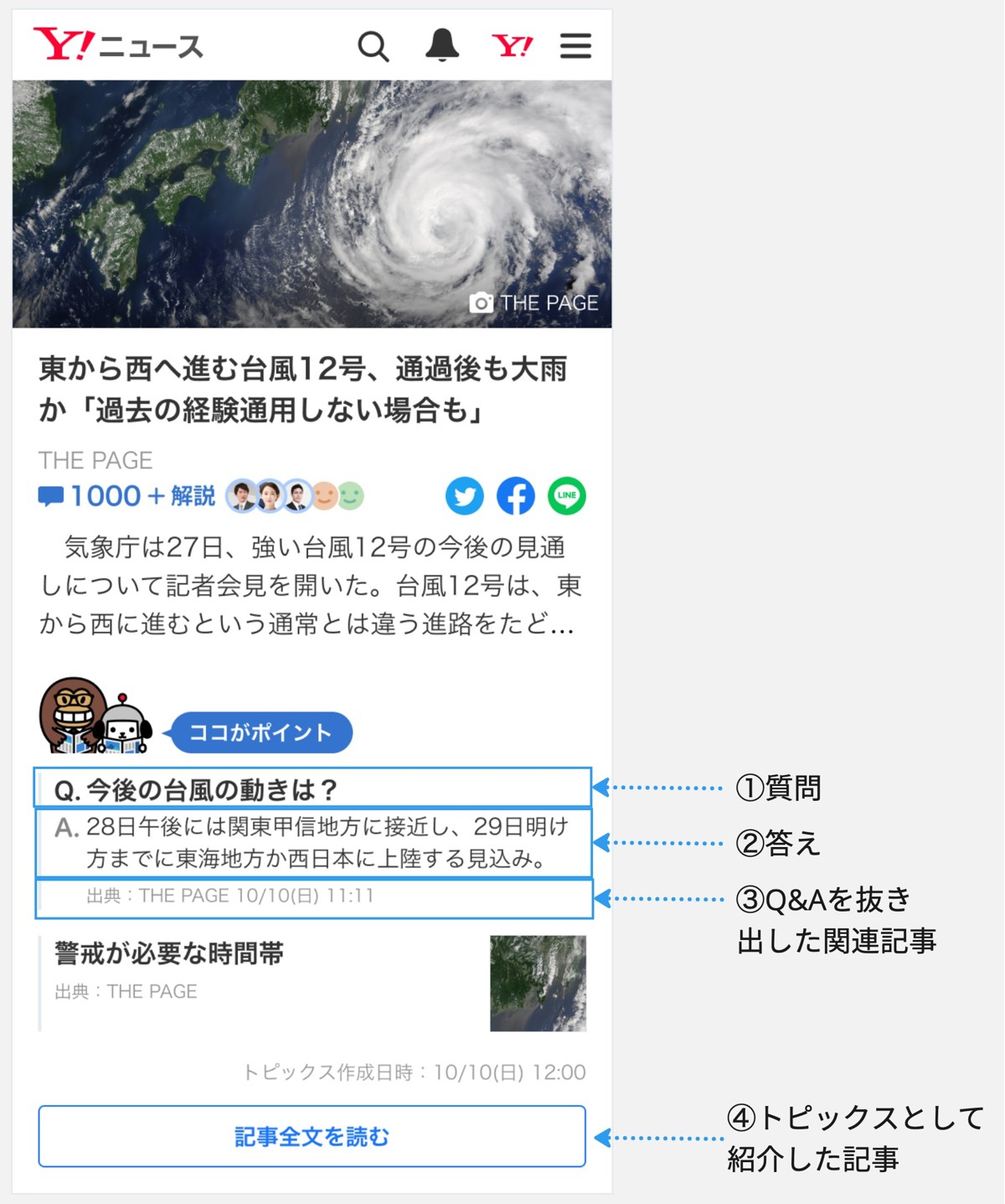
トピックスの記事ページを作る際、編集者はまず紹介するニュース記事を決めて、それをもとにページを作成します。その際、紹介する記事のリンク先は上図の(4)です。その記事に対して(1)質問と(2)答えを抜粋した記事(3)が紐づいているデータ構造となっています。
では、検索性能と質問応答性能について紹介します。
検索性能については、質問に対する答えを含む記事を Yahoo!ニュース上で公開されている記事全体から検索する能力を評価しました。具体的には、検索システムが類似記事を検索した結果の上位に、正しい関連記事が含まれているかどうかを調査し、その結果をもとに性能を測定しました。この正しい関連記事とは、編集者が人手で判断した関連記事です。

質問応答性能の評価は、BERT が記事から適切な答えを抽出する能力を検証しました。具体的には、編集者が選んだ関連記事と質問に対して、BERT が出した答えと編集者が提示した答えがどれほど一致しているかどうかを調査し、その結果をもとに性能を評価しました。
検索性能の結果からは、質問に対して検索結果の TOP5 のうち約 43%が正解であり、TOP10 だと約 63%が正解だと確認できました。また、編集者からは「正しい関連記事以外にも他にも多くの有益な記事が提供されている」という意見がありました。
● 検索性能の評価尺度
| 精度 (%) | |
|---|---|
| 検索結果の TOP5 に正解を含む割合 | 43 |
| 検索結果の TOP10 に正解を含む割合 | 63 |
質問応答性能の結果からは、システムが予測した答え(最大 120 文字と設定)と正解の答えに対して類似度を ROUGE-Lの recall を使って評価しました。ROUGE-Lのrecallを利用した理由は、正解文に対して予想との長い一致部分を重視して評価したいからです。ROUGE-Lを調査したところ、約 69%でした。また、システムが予測した答えに正解の答えを全て含んでいるかを調査したところ、約 40%でした。
● 質問応答の評価尺度
| 精度 (%) | |
|---|---|
| ROUGE-L を使った類似度 | 69 |
| システムが予測した答えに正解の答えを完全に含むかどうか | 40 |
このROUGE-Lの数値は日本語言語理解ベンチマーク JGLUEの質問応答データセットであるJSQuADで調査されたパフォーマンスと比較してやや低い数値に見えるのですが、これには二つの理由があります。
一つ目は、今回編集者から提供された答えが、ニュース記事からただ抜粋したものではなく、部分的に手を加えられたものを含んでいるため、精度の上限が100%にはならず、精度が低くなる傾向にあるからです。
二つ目は、編集者から提供された答えの文字数がかなり長く、質問応答タスクとして難しいものとなっているからです。これらの違いが結果の数値に影響を与えています。
編集支援ツール導入と作業工数の削減成果
AI システムを活用して編集者の作業効率を高めるために、既存の編集支援ツールに AI システムを導入しました。ツールの UI は以下の図のようになっています。
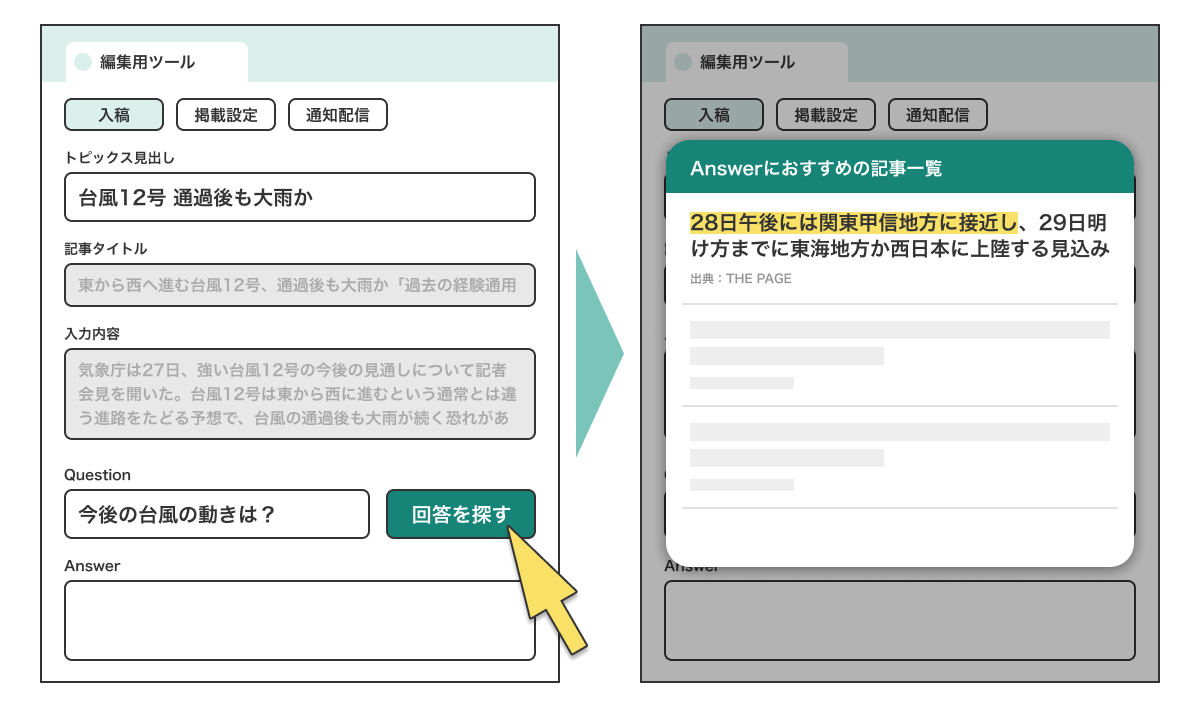
このツールは、編集者がトピックスと Q&A を配信する流れを効率化するために設計されています。まず、編集者は配信するトピックス記事を探し出し、決定します。その後、このツールを活用して Q&A の検索と入稿ツールへの入力を行います。
このツールは、質問を入力すると答えの候補が表示される機能を有しています。これにより、編集者は最適な候補を選択し、ツールに入力することが可能になります。一連の作業を終えたら、編集者はその内容を配信します。
このように、このツールは編集者の作業をスムーズに進行させ、全体のプロセスを効率化します。
フィードバックと課題
導入した AI システムが編集作業でどの程度役立っているかについて、編集部のメンバーからフィードバックを得ています。
- 関連記事を一から探す手間が省けている
- 求めている関連記事に早くたどりつけることがある
- 結果的に Q&A に採用しなかったとしても、その他の関連記事の作成のヒントを得ることがある
一方で、課題感を指摘する意見も多数寄せられています。
- AIの精度には、まだ課題感が残っている
- AI を呼び出す UI が入稿ツール内の下部にあるため、該当の UI にたどり着く頃には Q&A が既に人力で完成していることがある
- Answer 抜き出しだけでなく、「質問」も AI に提案してほしい
以上より、
- 精度のさらなる向上
- より最適化された導線上での UI 改善
を主な今後の改善点として試行錯誤を始めています。
まとめ
Yahoo!ニュースでは、自然言語処理 AI を活用してトピックスの Q&A コーナーの編集作業を効率化しています。1 日約 100 本のトピックスに対して Q&A コンテンツを作成するため、AI システムを用いて質問に対する答えを迅速に見つけ出し、編集作業の時間と労力を大幅に節約しています。
具体的な仕組みとしては、検索システムと自然言語処理 AI を組み合わせた Retriever-Reader アーキテクチャを採用しています。このシステムは、一定の精度で動作しており、編集者の作業効率を大幅に向上させています。
ただし、ユーザーからのフィードバックには精度改善や UI の改良、機能追加などの要望が含まれており、これらを改善点として取り組むことを計画しています。
参考文献
[1] Fengbin Zhu, Wenqiang Lei*, Chao Wang, Jianming Zheng, Soujanya Poria, Tat-Seng Chua, (2021). Retrieving and Reading: A Comprehensive Survey on Open-domain Question Answering. https://arxiv.org/pdf/2101.00774.pdf
[2] DJacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. https://aclanthology.org/N19-1423/.
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 田口 拓明
- ソフトウエアエンジニア
- 2016 年、岐阜大学大学院工学研究科応用情報学専攻修士課程修了。同年よりヤフー株式会社に入社。2018 年より Yahoo! JAPAN 研究所勤務。研究所技術のサービス化の推進に従事。現在に至る。専門は自然言語処理・機械学習。
-

- 山下 郁矢
- Yahoo! JAPAN 研究所 エンジニア
- HCI、機械学習(画像、言語、コンテキストアウェアコンピューティング)などの分野でエンジニアリングを行ってます。

- 小林 一揮
- Yahoo!ニュース エンジニア
- Yahoo!ニュースでトピックス周りのシステム開発やフロントエンド開発を担当しています。



