こんにちは。ヤフーで画像認識技術の研究開発を担当している湛です。
この記事ではGPUを利用した推論サーバーのパフォーマンスチューニングから得られた知見をお伝えしたいと思います。チューニング方法とその結果を示すだけではなく、それぞれのチューニング方法がなぜ有効なのか、また本当に意図した通りの動作をしているかについて確認するためのメトリクスの見方についても解説します。
私たちのチームではヤフーのサービスで利用するための画像特徴量抽出モデルや物体検出モデルの開発を行っています(例: Yahoo!ブラウザー、Yahoo!ショッピング)。またこれらのモデルをWeb APIとして便利に利用できるようにするための推論サーバーも開発しています。推論サーバーの実装にはTriton Inference ServerというOSSを採用し、CuttySarkという社内プラットフォームにデプロイしています。最近CuttySarkではGPUを利用できるようになったため、GPU推論の検証を行ったのが執筆のきっかけです。
推論サーバーとは
今回扱う推論サーバーは入力された画像ファイルに対して特徴量ベクトルを返すようなWeb APIになっています。われわれの開発しているシステムでは、このサーバーから得られた特徴量をNGTやValdに保存して類似画像検索を実現しています。
画像の読み込みやリサイズなどの前処理をPythonで行ったあと、ONNX形式で表現されたニューラルネット(以下NN)のforward処理を行います。Tritonの用語ではこれらの処理はどちらもモデルと呼ばれるのでこの記事でもその用語法に従います。前処理モデルはCPU、NNモデルはGPUで動かしています。
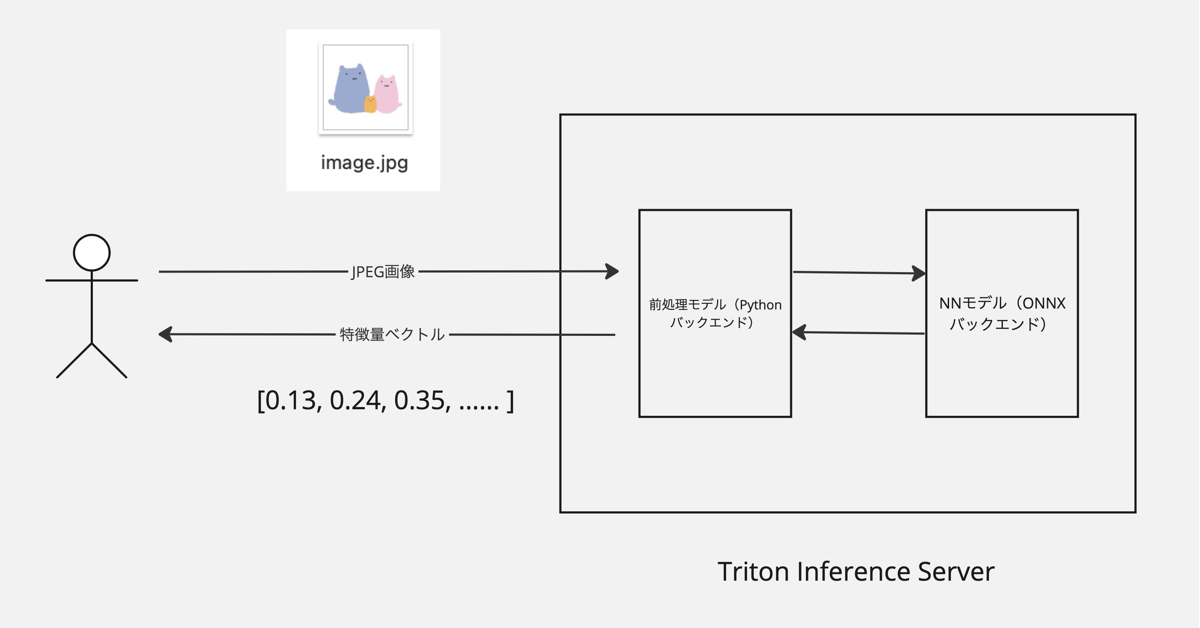
ヤフーにおいては、この推論サーバーはCuttySarkという社内プラットフォームにデプロイされユーザーから利用可能になります。CuttySarkでは2023年8月現在A30というGPUを分割して提供していますが(Multi-Instance GPU)、今回のチューニングでは実験環境の都合上V100を利用しています。
チューニングの手順
パフォーマンスチューニングの目標として今回はスループットの向上に集中します。われわれのユースケースである検索システムについて考えると、検索インデックスの構築のために利用される推論サーバーでは大量のデータを処理するためにスループットが最優先です。一方でユーザーからの検索リクエストを処理する推論サーバーについてはスループットとレスポンスタイムのバランスを考える必要があるでしょう。
今回行ったチューニングの手順は以下の通りです。このステップを実行することによりスループットが3倍以上になりました。これは試行錯誤して得られた暫定的な手順なので今後の改善により変更する可能性が高いです。またTensorRTによるモデルの最適化やINT8での推論などいくつかの重要な高速化手法についても検証できていません。
- 低精度計算の活用
- リクエストの並列処理
- パイプライン最適化
この手順でははじめにNNモデルを単体で最適化し(1, 2)、その後パイプライン全体を最適化する(3)という流れになっています。NNモデルは推論サーバーの中で一番重い処理であり、また高価なハードウェアであるGPU上で実行されているのでチューニングの優先度が最も高いです。前処理モデルはNNモデルの処理能力の足を引っ張らないようにモデルインスタンス数をスケールさせる程度に留めます。
ステップ2, 3でチューニングする設定値についてはmodel analyzerを使って自動的にチューニング可能なので実際はこのツールを使った方がいいのですが、この記事では解説の都合のためそれぞれ独立したステップとしてチューニングを実施します。
低精度計算の活用
解説
NNモデルのパラメーターはFP32で保存されることが多いですが、推論時にはFP16などの低精度計算を活用することで高速化が期待できます。FP32よりFP16の方がGPUの演算性能が高いので、同じ計算をする場合でもFP16の方がパフォーマンスが向上するのです。スカラー1つあたりのデータ量が半分になれば転送効率は2倍になりますし、また演算器の回路サイズも小さくできるので効率が上がります。V100以降のGPUについては専用回路であるTensorコアが導入されましたが、FP32ではこれを利用できないため、Tensorコアを利用できるFP16演算と比べてさらに大きな差が付きます(NVIDIA A100 Tensor Core GPU Architectureの表4より作成)。
| 項目 | V100 | A100 |
|---|---|---|
| Peak FP32 TFLOPS (non-Tensor) | 15.7 | 19.5 |
| Peak FP16 TFLOPS (non-Tensor) | 31.4 | 78 |
| Peak FP16 Tensor TFLOPS | 125 | 312 |
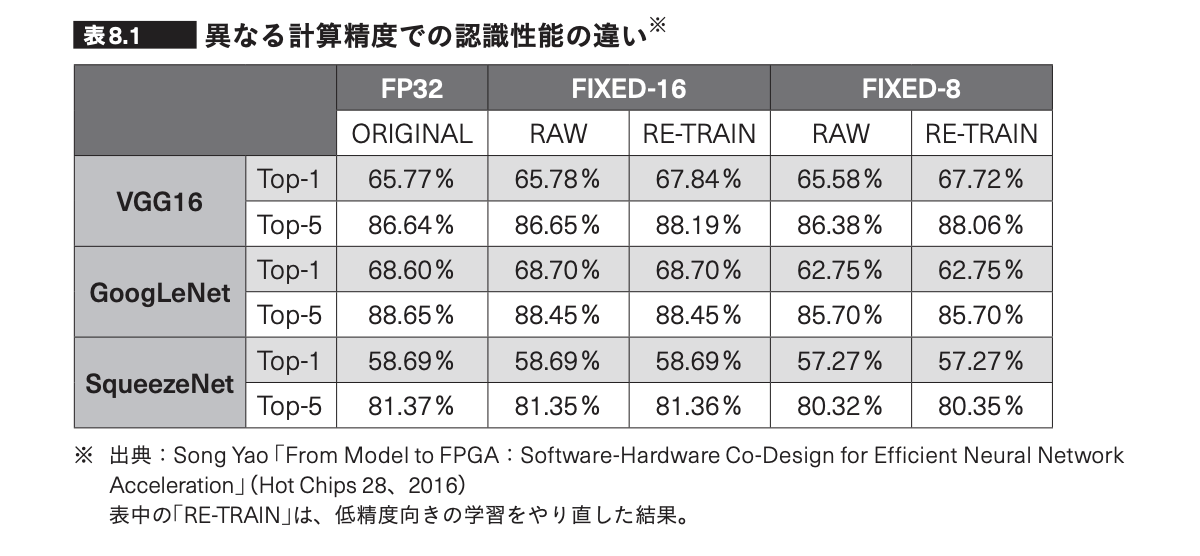
低精度計算を使うことで数値誤差は大きくなりますが、下表(『GPUを支える技術』増補改訂版の表8.1)の通りディープラーニングにおいてはその影響はあまり大きくないと考えられています。いずれにせよモデルの評価は自動化されていることが望ましいので、低精度計算を適用したことによって最終的に解きたいタスクに対する評価結果が悪化していないか確かめたほうが良いでしょう。私たちのチームでは類似画像検索タスクで評価を行いMAPなどのランキング指標が問題ないことを確認しました。
実験
まずONNXモデルファイルをFP32からFP16に変換する必要があります。この手順はONNXのドキュメントに従いました。こちらのページではFP16と混合精度の2通りの方法が紹介されていますが、今回はFP16の手順で行いました。
以下に実験結果を示します。FP32の代わりにFP16を使うことでスループットが1.7倍になっています。
| 実験ID | 数値精度 | クライアントの並列数 | スループット (infer/sec) | 計算時間 (usec) |
|---|---|---|---|---|
| 1 | FP32 | 2 | 166.683 | 5958 |
| 2 | FP16 | 2 | 290.371 | 3405 |
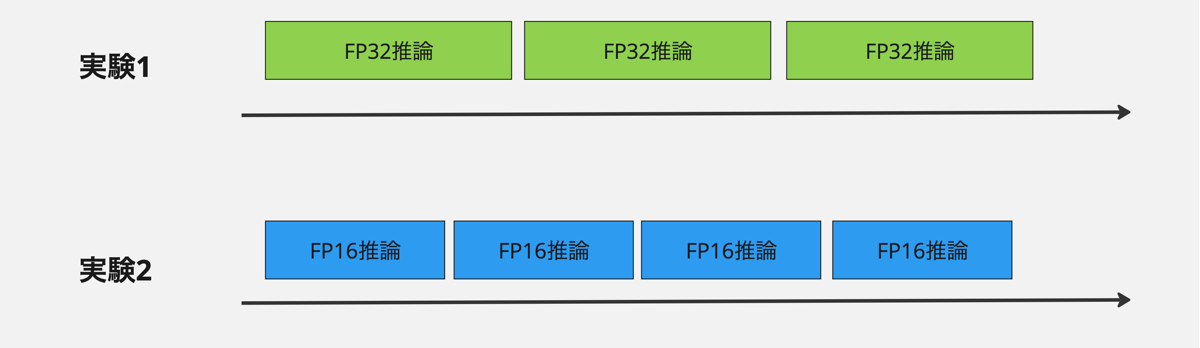
またスループットが計算時間 (compute input + compute infer + compute output) の逆数と近い値になっていることに注目してください。これは下図のようにGPUがリクエストをすき間なく直列的に処理していることを示しています。仮にGPUが遊んでいる時間があるとするとスループットは計算時間の逆数より小さくなるはずです。このようにGPUがすき間なくリクエストを処理している状況で、低精度計算によって計算時間が減ればその分、スループットが上昇することが見て取れると思います。
この節のように、レスポンスタイムとスループットの両方の改善は、システムパフォーマンスの観点から見てもいいことずくめです。数値誤差が問題にならないことが確認できていれば低精度計算をぜひ活用すべきでしょう。一方で次節の内容はレスポンスタイムの悪化を許容した上でスループットの改善を目指す内容になっています。
リクエストの並列処理
解説
ユーザーから送信された複数のリクエスト(画像)を並列で処理することで性能を向上させられる可能性があります。これを実現するTriton Inference Serverの機能がインスタンスグループと動的バッチングです。これらの機能について、最大でいくつのリクエストを同時に処理するか設定するパラメーターがインスタンス数とバッチサイズです。たとえばインスタンス数2、バッチサイズ8に設定した場合16 (= 2 * 8) 枚の画像を同時に処理可能になります。GPUの並列計算能力をフルに活用するためには一定程度の並列度があったほうが有利ですが、最適な設定値はモデルとGPUの種類によるので実験によって決定される必要があります。
この節のチューニングにおいてはスループットとレスポンスタイムの間にトレードオフがあります。前節においてはレスポンスタイムが短くなったことによってスループットが向上しましたが、今節ではレスポンスタイムが長くなることを引き換えにスループットを向上させます。サーバーに対して一度に大量のタスクを与えてGPUを休みなく働かせることによって効率を向上させられる一方で、反応は鈍くなるというわけです。したがってメトリクスとしてはGPU使用率とスループットが向上し、レスポンスタイムが長くなることが期待されます。
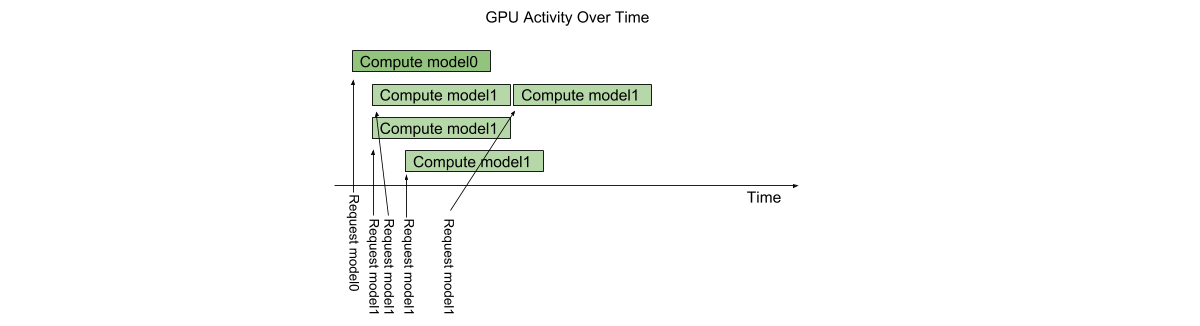
1つのモデルが同時に受け付けられる最大のリクエスト数を決めるのがインスタンス数という設定値です。以下の図はmodel1のインスタンス数を3に設定しときに3つのリクエストが同時に処理されている様子です (公式ドキュメントのTriton Architectureより)
モデルのインスタンス数は2以上に設定することが良いとされています。データの転送と計算処理をオーバーラップさせることによりスループットの向上が期待できるためです(公式ドキュメントのOptimizationより)。
複数のリクエストを合成して1つの大きなリクエストにまとめて処理するのが動的バッチングの機能です(公式ドキュメントのOptimizationより)。たとえばリクエストが(1, 3, 224, 224)という形のテンソルで表現されているとすると、4つのリクエストをまとめ大きなリクエスト(バッチリクエスト)は(4, 3, 224, 224)という形のテンソルになります。
バッチサイズがある程度大きい2の乗数になっているとGPUは効率的に処理を行うことができます。GPUが行列積を計算するときに次元が小さいとメモリ帯域に律速されてしまうのですが、次元を大きくすることによって演算器のポテンシャルをより引き出せるためです。またTensorコアが効率的に動作する条件として(FP16の場合)8の倍数であることが必要です。詳しくはNVIDIAのGet Started With Deep Learning Performanceというドキュメントを参照してください。
実験
以下に実験結果を示します(数値精度FP16, 最大バッチサイズ32は固定)。
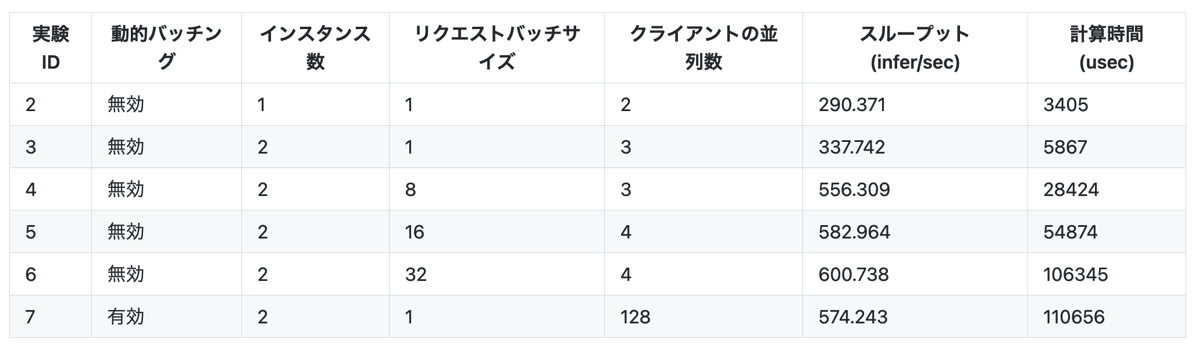
実験3ではモデルのインスタンス数を2にしたことで実験2と比べてスループットが1.2倍になっています。そのかわり計算時間が長くなっていることから、スループットとレスポンスタイムのトレードオフが発生していることがわかります。
さらに実験6ではバッチサイズを32にしたことで実験3と比べてスループットが1.8倍になっています。実験3から実験6にかけてバッチサイズを1, 8, 16, 32と増やしていますが、ここでもスループットの向上と計算時間の延長が観測されています。これも上と同様のトレードオフになっています。
実験7では動的バッチングを利用しています。動的バッチングはサーバー側のキューに並んでいるリクエストをまとめる機能なので、これを効率的に動作させるためにはキューの中に多くのリクエストが並んでいる状態を保つ必要があります。このためにクライアントの並列数には128と大きな値を設定しています。
動的バッチングを設定している場合は、期待した通りのバッチサイズで推論が行われているか確認するためにメトリクスを見ることが重要です。perf_analyzerを使っている場合はレポートにInference countとExecution count出力されているので、前者を後者で割った値が平均バッチサイズです。今回の実験ではこの値がちょうど32になったので、計測の間は最大バッチサイズで推論を実行できていることがわかります。
動的バッチングにはキューの中での追加の待ち時間やバッチ生成などのコストがあります。今回の実験ではスループットに5%弱程度の影響が見られましたが、これにはクライアント並列数、最大バッチサイズ、遅延の設定値(max_queue_delay_microseconds、今回はデフォルト値を使ったので遅延は0)などさまざまな実験条件や誤差の影響があるので一般的な状況でのコストを代表しているとは言えません。
パイプライン最適化
解説
今まではNNモデル単体のチューニングでしたが、この節では前処理を含めた推論サーバー全体の最適化を行います。GPU上で実行されるNNモデルの推論がいくら高速でもCPU上で実行される前処理モデルでは律速されては意味がないのでこのステップは重要です。どのモデルが律速しているかはキューに入っている時間を見ることで判断できます。前処理モデルが遅いのであればそこで一定の待ち時間が発生するはずですし、もしNNモデルが遅いのであればそこで待ち時間が発生しているはずです。Triton Inference Serverではnv_inference_queue_duration_usというメトリクスを利用することでどのモデルでどれだけ待ち時間が発生しているかを確認することができます。
パイプライン最適化が常に簡単にできるとは限りませんが、今回のパイプラインについては単純に解決できます。前節までのチューニングでNNモデル単体については1 GPUあたりの最大のスループットを達成しています(あくまで今回紹介した手法の範囲内ですが)。一方で前処理モデルについてはCPUしか使わないのでNNモデルと計算資源を取り合うことはありません。したがってNNモデル単体で達成したスループットに到達するまで前処理モデルのインスタンス数を増やせばいいことになります。
実験
以下に実験結果を示します。表にないパラメーターについては実験7から引き継いでいます。特にNNモデルの設定については実験7と同じものを使っています。
| 実験ID | 前処理モデルのインスタンス数 | クライアントの並列数 | スループット (infer/sec) |
|---|---|---|---|
| 8 | 1 | 128 | 120.963 |
| 9 | 8 | 128 | 593.553 |
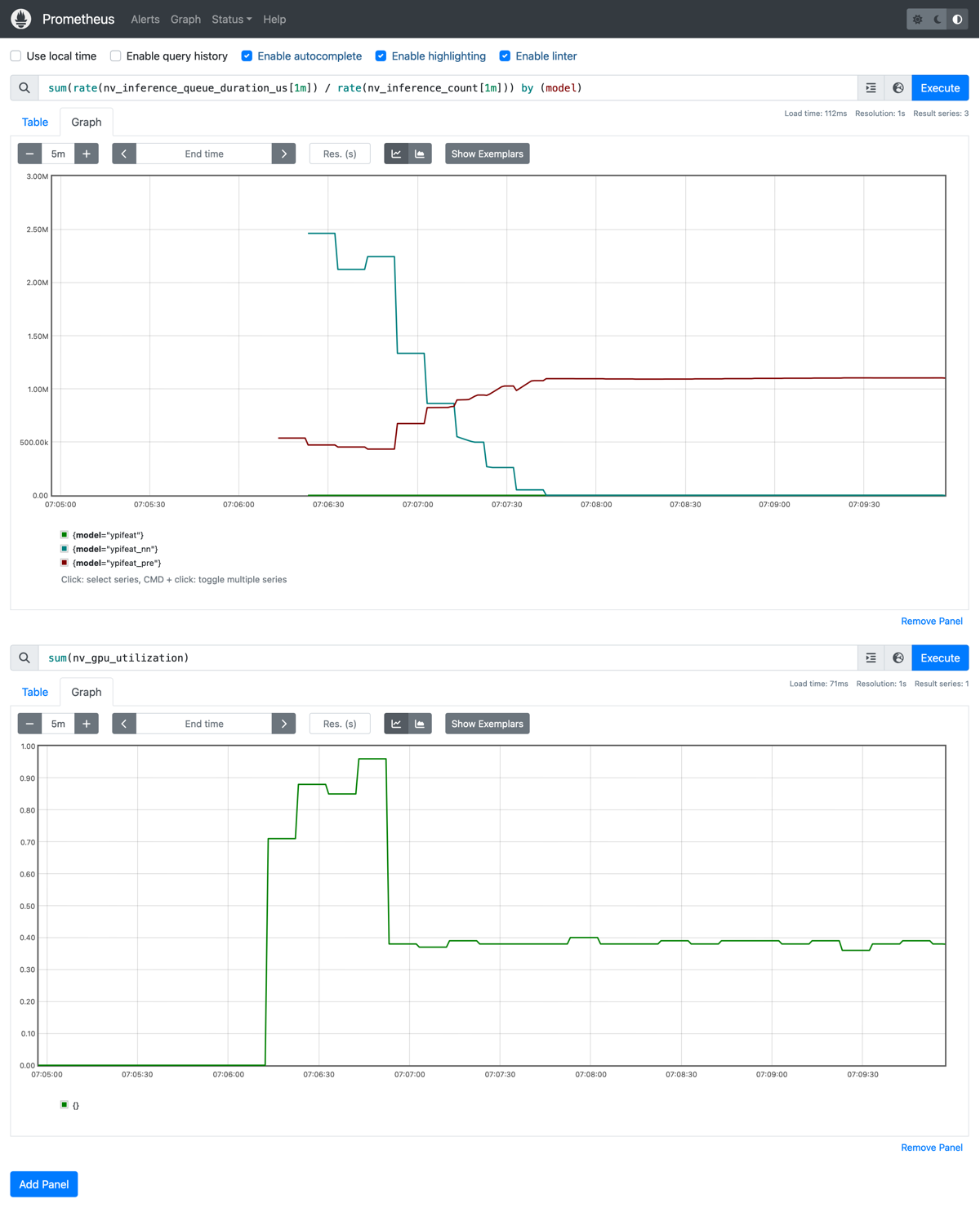
実験7では574.243出ていたスループットが実験8では大幅に下がってしまいました。これは前処理を追加したことで、そこがボトルネックになり全体のスループットが下がってしまったことが原因です。実際、以下の1番目のグラフから前処理モデル(ypifeat_pre)でのみ待ち時間が発生していることがわかります。また2番目のグラフからGPU使用率が40%程度になっていてNNモデルが遊んでいることがわかります。
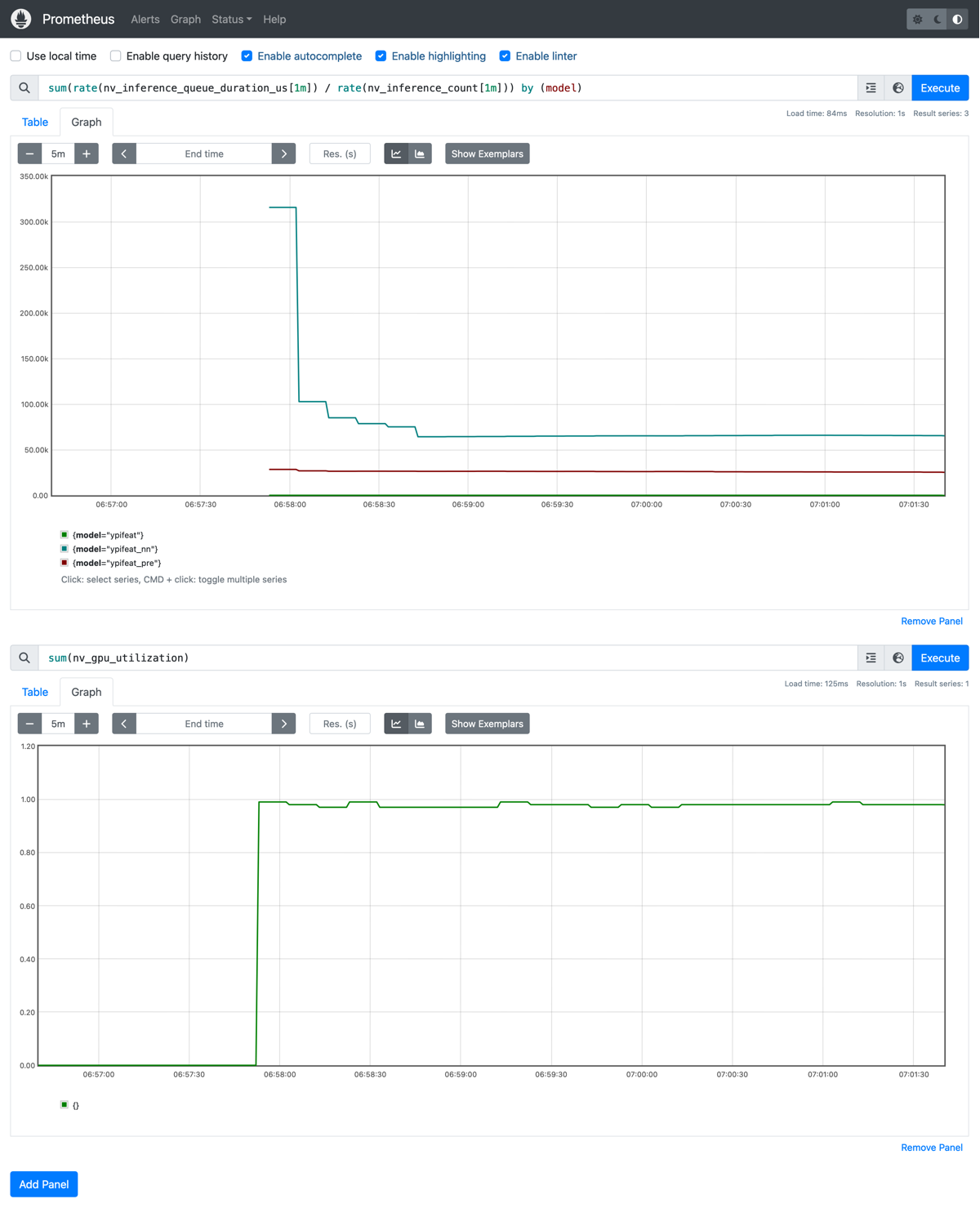
ボトルネックになっていた前処理モデルのインスタンス数を増やしたことにより、実験9ではスループットが大幅に向上しています。以下の1番目のグラフでNNモデルで待ち時間が発生していることからわかるようにボトルネックがGPUに移動しています。その結果GPU使用率が100%近くになっていることもわかります(2番目のグラフ)。
スループットが実験7の値を超えているのは少し変ですが、これはperf_analyzer実行時に固定データを利用したため、デフォルトのランダムデータと比べて、何らかのキャッシュが効いたのかもしれません。実験7で得られた574.243が本当の実力だと考えた方が良さそうです。
おわりに
この記事では推論サーバーの高速化手法として、低精度計算の活用、リクエストの並列化、パイプライン最適化という3つのテクニックを紹介しました。またわれわれのチームで開発している画像特徴量サーバーにこの3ステップを適用することでスループットが3倍以上になることを実験で示しました。今回の問題設定ではスループットを上げることに集中したので単純化された部分がありますが、スループットとレスポンスタイムのトレードオフを考慮するとより難しい問題になるでしょう。この記事が皆さんのチームでも役立てば幸いです。
今回の記事を執筆するにあたってNVIDIAの山崎和博さんから原稿について貴重なコメントをいただきました。ここで感謝申し上げます。
Appendix: メトリクス
この記事の内容と関係するメトリクスを表にまとめました。CPU使用率とCPUスロットルについてはcAdvisorが出しているもので、それ以外はTriton Inference Serverのものです。今回の実験のようにperf_analyzerを使っている場合はそのレポートからかなり多くの情報を得られますが、プロダクション環境をモニタリングしたい場合には以下のようなメトリクスを可視化しておくといいでしょう。
以下の5mという値は差分を取るための区間の幅を表しており、2mや30sなど適当な値でOKです。
| 項目 | PromQL | 主に関係するステップ |
|---|---|---|
| モデルごとのスループット | rate(nv_inference_count[5m]) |
すべて |
| モデルごとの計算時間 | rate(nv_inference_compute_infer_duration_us[5m]) / rate(nv_inference_count[5m]) |
低精度計算の活用 |
| モデルごとの待ち時間 | rate(nv_inference_queue_duration_us[5m]) / rate(nv_inference_count[5m]) |
パイプライン最適化 |
| GPU使用率 | nv_gpu_utilization |
リクエストの並列処理 |
| バッチサイズ | rate(nv_inference_count[5m]) / rate(nv_inference_exec_count[5m]) |
リクエストの並列処理 |
| CPU使用率 | rate(container_cpu_usage_seconds_total[5m]) |
パイプライン最適化 |
| CPUスロットル | rate(container_cpu_cfs_throttled_seconds_total[5m]) |
パイプライン最適化 |
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 湛 溢洋
- テックラボ エンジニア
- テックラボで機械学習系のシステムを開発しています。



