こんにちは。Yahoo!検索で機械学習エンジニアをしている由川です。
Yahoo!検索では、ユーザーが入力した検索クエリに関連する内容を掲出する関連検索ワードという機能があります(検索結果ページ上部と下部にあります)。従来の方法では、この関連検索ワードを出したくても掲出できないケースがありました。本記事では、高品質な文ベクトルを生成する手法SimCSEを用いて検索クエリと意味が類似する内容を掲出することで、関連検索ワード機能を改善させた事例を紹介します。
※この記事で取り扱っているデータは、プライバシーポリシー の範囲内で取得したデータを個人が特定できない状態に加工しています。詳しくはYahoo! JAPAN プライバシーセンターをご覧ください。
1. これまでの関連検索ワードの課題とベクトル検索の導入経緯
1.1 これまでの関連検索ワードの課題
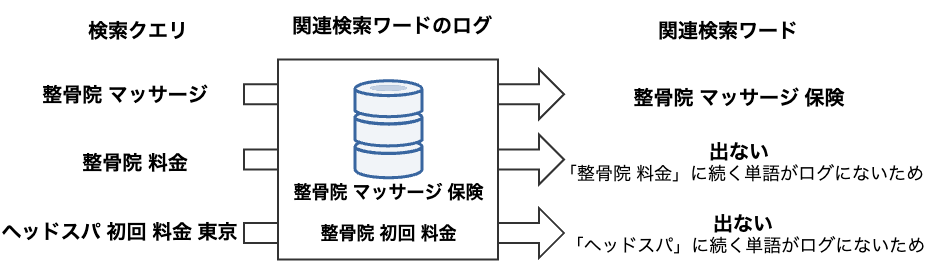
ベクトル検索導入前の関連検索ワードでは、検索クエリと前方一致するクエリが関連検索ワードのログにあれば掲出するという方法を中心に掲出していました。しかし、この方法には以下の問題があるため、カバレッジ(関連検索ワードを1件以上出せた検索クエリの割合)が低くなってしまいます。
- 関連する内容がログにあっても、順番が少し違うだけで掲出できない
- 下図の検索クエリ「整骨院 料金」
- 対応する内容がログに残りにくいので、マイナーな検索クエリに対して関連検索ワードを掲出できない
- 下図の検索クエリ「ヘッドスパ 初回 料金 東京」
1.2 ベクトル検索の導入経緯
カバレッジが低いままでは、ユーザーの知りたい検索結果にたどり着くためのヒントを十分に提示できないことになり、不便な関連検索ワードになってしまいます。また、カバレッジだけでなく、検索クエリとの関連性も保つ必要があります(カバレッジの改善だけなら関連性のない内容でも出せばよいことになり、それでも不便になってしまうため)。
解決策として、ベクトル検索ならば、検索クエリのベクトルと関連検索ワードのログのベクトル間で類似度を計算することで意味が似ている内容を掲出できるので
- 検索クエリの順序を気にすることなく、関連する内容を出せる
- マイナーな検索クエリに対しても、何かしら関連する内容を出せる(適切なフィルタリングは必要になるが)
と思い、導入することにしました。
2. SimCSEに関して
ベクトル検索を行うには、クエリと関連検索ワードのログのベクトルを作る必要があります。これらのベクトルを作る手法としてSimCSE(Simple Contrastive Sentence Embedding)[1]を採用しました。
この章では、SimCSEの概要、採用理由、質の高い文ベクトルを作るための学習方法について紹介したいと思います。
2.1 SimCSE とは
対照学習と呼ばれる学習で文ベクトルを生成する手法で、ある文ベクトルに対する正例(同じ意味)のベクトルとは距離が近くなる(類似度が大きくなる)ように、負例(違う意味)のベクトルとは遠くなる(類似度が小さくなる)ように学習します。
正例の作り方で
- 教師なし(Unsupervised SimCSE)
- 同じ文をDropoutの異なるEncoder(BERTなど)に2回入力。
- 正例=異なるDropoutから得られた同じ文のベクトル同士、として対照学習
- 教師あり(Supervised SimCSE。今回はこちらを採用。詳細は2.3節)
- 含意(entailment)、矛盾(contradiction)関係を表すデータセットを利用
- 正例=含意となる文ベクトル同士、として対照学習
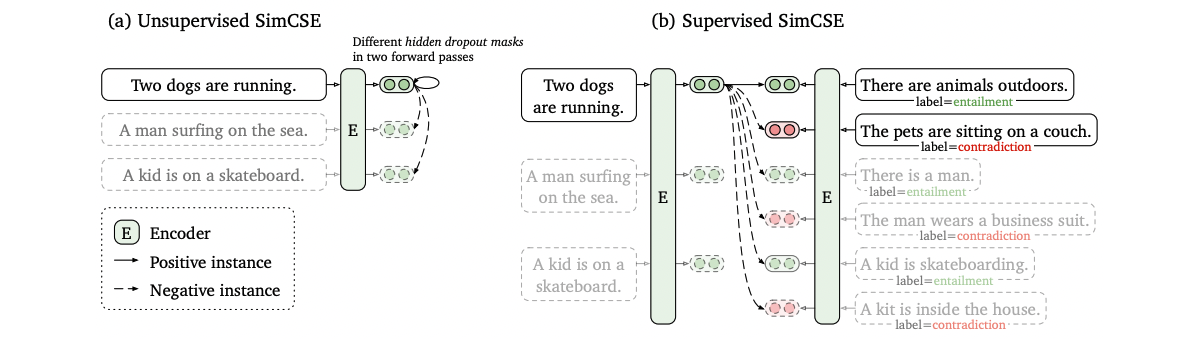
という2つの学習方法が提案されています(図は[1]より引用)。
学習方法がシンプルであるにもかかわらず、質の高い文ベクトルを獲得できると話題になった手法です。
2.2 採用理由
自然言語処理のさまざまなタスクにおいて、BERTの有効性が示され、広く利用されるようになってきました。しかし、今回のベクトル検索のように文ベクトルを利用したタスクには不適切だと考えられます。理由は、BERTには異方性という特徴があると確認されているためです[2]。これは、文ベクトルが特定の方向に偏っているために単語の類似性を適切に捉えきれないというものです。
SimCSEは、正例のベクトル同士は距離が近くなるようにし、かつベクトルの分布が一様になるように修正することで異方性を解消しました。
以上を踏まえて
- BERTには異方性があるため、不適切な関連検索ワードを出す可能性が高くなる
- 公式実装があり、比較的簡単に利用できる
- 異方性に対応したBERTの派生形を使ったとしても、SimCSEのほうが精度が良いと論文で示されている
ためSimCSEを採用することにしました。
2.3 学習方法
事前学習
ヤフー社内では、BERTのような大規模言語モデルを基盤モデルとして扱い、学習や推論をしやすくするための取り組みがあります。
今回は、その取り組みの一環で使われている検索クエリのログを事前学習したBERTを利用しました。GPUを使ったとしても何日もかかる事前学習を自前で行わずに、モデルを利用できるのが大きなメリットです。
ファインチューニング
今回の関連検索ワードのタスクに適用させるために、先述の事前学習済みモデルを教師ありSimCSEのEncoderとして利用し、ファインチューニングさせました。
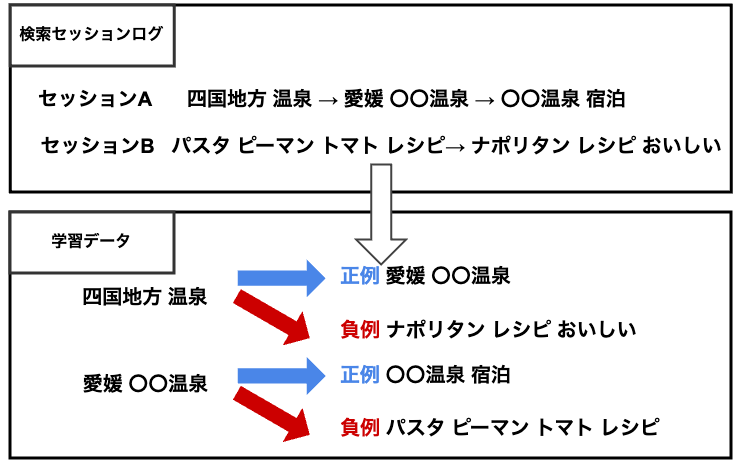
学習データとして、下図のようなユーザーの検索セッションログを利用しました。このログは、ある時間内でユーザーが検索したクエリの遷移を収集したものです。
今回は正例を同じセッションの中で隣接する検索クエリ、負例はセッションログの中からランダムに選んだ検索クエリとして学習しました。
正例は、同じセッション内にある検索クエリならば、類似性やドメイン知識を捉えた内容が出るだろうという仮定をおいて選びました。
しかし、現行の学習方法だと以下の問題があります。そのため、これらを解決してより良い関連検索ワードを出せるようにするという課題が残っています。
- 負例はランダムに選んだものしか使っていないので、質が低い
- 解決策として、SimCSEでは Hard Negativeを導入できます(一見すると正例に見えるが、実は負例になる内容。今回のタスクの場合、英単語や地名のように文字は似ているが関連性がないといった性質が出やすいもの)
- 現在、収集方法を模索中です
- 同じセッション内で隣接するクエリしか正例としていないので、特定のクエリに対する正例を十分に増やしきれていない
- 例:セッションAにおいて、「四国地方 温泉」に対して「〇〇温泉 宿泊」を正例にできていない
3. ベクトル検索のシステム化
この章ではベクトル検索のシステム化方法について紹介します。類似事例として Deep Metric Learningによる、ホテルや飲食店などの拠点検索改善(Yahoo! JAPAN Tech Blog) があります。
システム構成図は以下の通りです(理由は5.2節)。このうち、検索クエリのベクトル化とベクトル検索に関して詳細をお話しします。
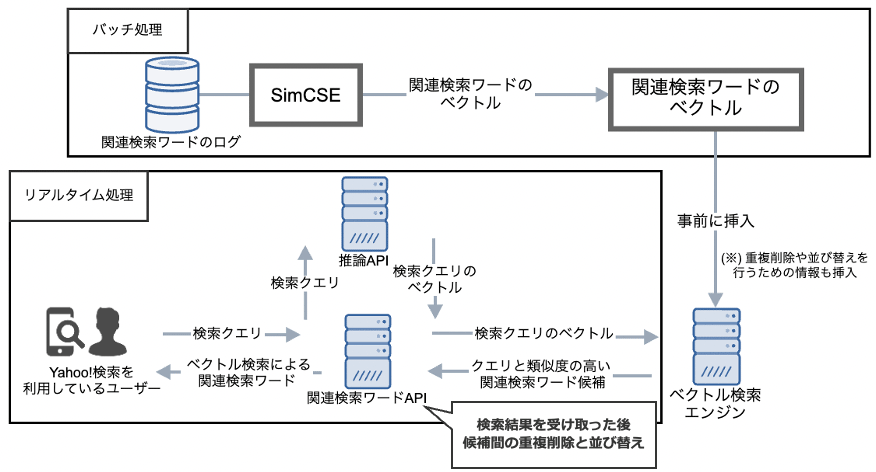
3.1 検索クエリのベクトル化
検索クエリはユーザーから入力されるためベクトルを事前に用意することができません。そのため、リアルタイムに検索クエリのベクトル化を行う必要があります。
これを実現するために、CuttySarkという社内プラットフォームを利用しました。CuttySarkでは、TensorFlowやPyTorchで作成した機械学習/深層学習モデルを事前にデプロイすることで、モデルを推論API化することができます。
今回は、検索クエリをリクエストしてそのベクトルをレスポンス(推論)するTensorFlow SavedModelを事前にデプロイし、推論API化させました(詳細は類似事例と同様です)。
注意点として、検索クエリのベクトルと関連検索ワードのベクトルは、異なる深層学習フレームワーク(TensorFlow、PyTorch)から生成しています。経緯は以下のとおりです。
- SimCSEがPyTorchで実装されている(PyTorchで関連検索ワードのベクトルを生成)
- 当時のCuttySarkの都合上、SimCSEによるファインチューニング済みモデルをTensorFlowに変換して、クエリのベクトルを生成する必要があった
深層学習フレームワークの違いにより起きてしまった問題があります。それは、利用できるTokenizerの有無が原因でトークナイズ結果が異なり、その結果おかしな関連検索ワードを出すというものです。応急処置として、トークナイズ結果が揃うような補正をTensorFlowのコードに加えることで解消しました。
今回のように、機械学習システムではコンポーネント間や学習・推論などで条件(今回の場合、深層学習フレームワーク)がズレやすいです。問題を未然に防ぐためにも、なるべく条件を揃えてシステム化すべきでしょう。すると、思わぬミスや応急処置的なコードのメンテナンスコストが減ってくると思います。
3.2 ベクトル検索
通常のベクトル検索では、検索クエリと候補のベクトルとの類似度を総当りで計算し類似度が高い候補を検索結果として返します。しかし、この方法だと候補の数が大きくなるにつれ、結果が返ってくるのに時間がかかってしまいます。
今回の関連検索ワードでは、大規模な候補数を抱えたうえで、1秒間に膨大なリクエストがくる高スループットな要件と99パーセンタイルで数百ミリ秒以内にレスポンスするという低レイテンシな要件があります。これらの要件を満たすため、検索結果の精度は多少下がるが高速にレスポンスできる近似近傍探索(Approximate Nearest Neighbor、ANN)を使ったベクトル検索をすることにしました。
ANNが使える検索エンジンとして、ABYSSというApache Solrをベースとした社内検索エンジンを利用しました。ABYSSにはANNプラグインという独自機能が実装されており、検索精度とレイテンシのトレードオフを制御するオプションを利用者が調節できます。これをチューニングすることで、スループット/レイテンシ要件を満せるようになりました。
また、ABYSSではベクトル検索の後処理(今回の場合、重複削除とベクトル検索の結果がクリックされやすくするための並び替え)をするための情報もレスポンスできるので、さまざまな観点からの改善ロジックを実装しやすかったのも大きなメリットでした。
4. ベクトル検索の効果
上記のモデルとシステムに基づいたベクトル検索のA/Bテストをしました。
その結果、ベクトル検索導入前と比べてカバレッジ、CTR(関連検索ワードのクリック率、関連性を表す指標として利用)ともに大幅に増加しました。よって、関連性を保ったままカバレッジの改善ができると分かりました。
大きな成果をあげることができたので、2023年2月にYahoo!検索のPC版、スマートフォン版ともにリリースしました(2023年5月時点では、一定の掲出制約を設けた上で検索結果ページ下部のみリリースしています)。
ベクトル検索の導入によって、以下のケースが増えました。検索結果のイメージは以下表のとおりです。
- 導入前:数件しか出せなかった
- 導入後:前方一致しない、かつ関連性も問題ないものを多数出せるようになった
検索クエリ「ドーナツ カスタードクリーム」に対する関連検索ワード
| ベクトル導入前 | ベクトル導入後 |
|---|---|
| ドーナツ カスタードクリーム 賞味期限 ドーナツ カスタードクリーム 冷凍 |
ドーナツ レシピ カスタードクリーム ドーナツ ストロベリーカスタード ドーナツ クリームクリスピー ドーナツ キャラメルチョコ |
5. うまくいかなかったこと
モデルとシステム双方の観点でうまくいかなかったことを紹介します。
5.1 事前学習済みモデルの層の数や次元数を増やす
当初は、12層768次元のBERTをEncoderにしたSimCSEを利用していました。しかし、負荷検証の結果、数十rps(Request Per Second)に対してレイテンシが数秒になり、この層と次元数では本番導入できないとわかりました。
そこで、3層128/256/768次元に軽量化したBERTをEncoderとしたSimCSEを検証しました。レイテンシの制約がある中でもなるべく検索結果を良くしたいという目的で、次元数を増やしました。しかし、検索結果は128次元の時とさほど変わらず、レイテンシが悪化するだけでした。
5.2 推論APIの中でベクトル検索まで行う
システム簡略化のために、検索クエリを入力してベクトル検索の結果を出力する推論APIを構築しました。具体的には、検索クエリのベクトル化・ベクトル検索をまとめて行うTensorFlow SavedModelをCuttySarkにデプロイしました。
しかし、この方法だとメモリを多く消費するため、推論API入れられる関連検索ワード候補数が少なくなってしまいました。A/Bテストを実施したものの、少ない候補数が大きな原因となって問題のある検索結果を出す事例が多数見受けられました。そのため、リリースを断念しました。
その後の検証で、関連検索ワードの候補数を増やすと検索結果が改善しやすいとわかりました。これを受けて、3章で述べたシステム構成に変更しました。クエリのベクトル化とベクトル検索を別のプラットフォームで行うという複雑さがありますが、多くの関連検索ワード候補を入れられます。
6. おわりに
本記事では、高品質の文ベクトルを生成する手法SimCSEを使ったベクトル検索を実サービスに適用した事例を紹介しました。
ただ、検索クエリによっては関連しない事例を出してしまうという課題は依然として存在します。また、モデルとシステムの運用(e.g., モデルの更新方法など)でも課題が残っています。
今後はこれらの改善に取り組むことで、ユーザーの皆様にとって便利な検索機能を素早く提供できるようにしたいと考えています。
参考文献
[1] Gao, Tianyu and Yao, Xingcheng and Chen, Danqi. SimCSE: Simple contrastive learning of sentence embeddings. In Proceedings of Conference on Empirical Methods in Natural Language Processing (EMNLP), 2021.
[2]Ethayarajh, Kawin. How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019, pages 55–65.
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 由川 拳都
- Yahoo!検索 機械学習エンジニア
- Yahoo!検索の入力補助機能(サジェスト、関連検索ワード)に関する機械学習/深層学習モデルの開発を中心に取り組んでいます。



