こんにちは、検索統括本部の山本です。
Yahoo!検索では、入力補助機能の精度の改善をめざしています。検索クエリには地域によって検索数の分布が異なるものがあり、例えば「翔んで埼玉」というクエリは埼玉県を中心に検索数が多いです。そこで検索の入力を支援する機能にユーザの地域情報を用いるようにしたところ、CTR等の指標を改善できました。
本記事ではこのユーザの地域情報を用いた施策の検討、オフライン検証、A/Bテスト、本番リリースまで行った一連のプロセスを紹介します。先日開催されたYahoo! JAPAN Tech Conference(以下、YJTC)でお話しした内容をベースに、当日いただいた質問にもお答えします。
検索時にユーザを支援する機能
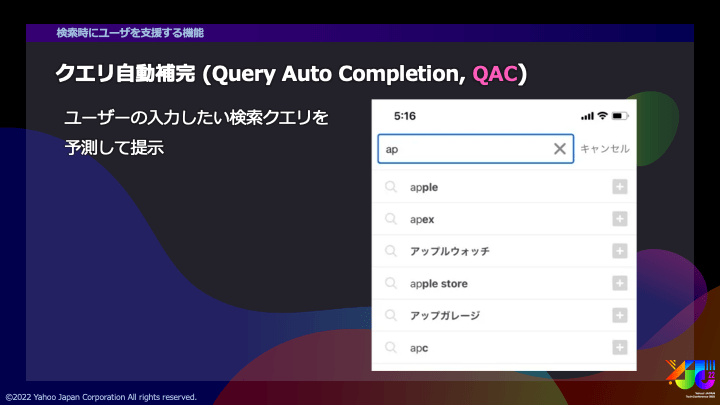
検索時にユーザを支援する機能として、クエリ自動補完、英語ではQuery Auto Completion (以下、QAC) と呼ばれる機能があります。
画像のように、検索窓に検索するための文字列を入力すると、ユーザの入力したいクエリを予測して提示します。
もう1つ、関連検索ワードという機能があります。こちらは検索結果画面で、ユーザの入力したクエリに関連するクエリを提示する機能です。
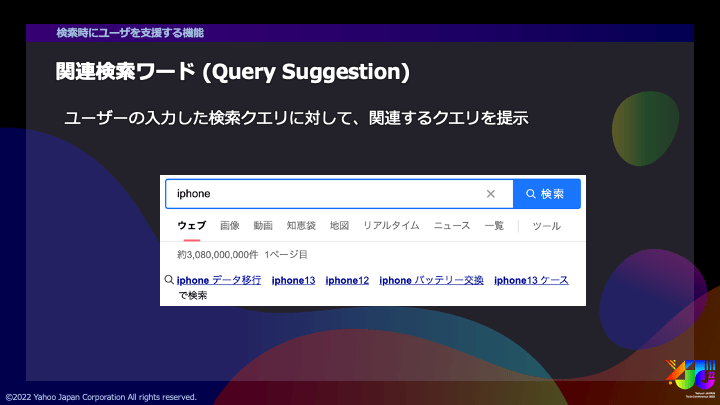
Yahoo!検索の持つこれらの機能について、より精度を改善することを日々目指しています。具体的には、ユーザが入力したい、あるいは提示された場合に選択したいようなクエリをより上位に提示することを目指しています。
ここで、最も単純な手法として、ユーザの入力にマッチする候補を、図のように過去の検索頻度順に表示することが考えられます。
われわれはさらに、機械学習モデルを使って、それよりも精度を改善しようとする取り組みを行っています。

地域を考慮する施策の有効性は?予備的な確認
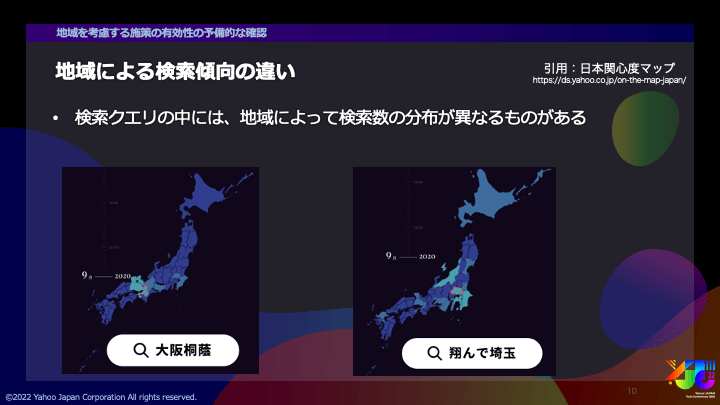
検索クエリの中には、日本全国どこでもたくさん検索されるようなクエリもありますが、その一方で、地域によって検索数の分布が異なるものもあります。画像は、ヤフーの「日本関心度マップ」より引用したものですが、たとえば、「大阪桐蔭」というクエリは大阪を中心とした関西圏、冒頭でも例に挙げた「翔んで埼玉」というクエリは埼玉県を中心に検索数が多いことが見て取れます。
そこで、各地域で検索されやすい検索クエリをその地域での検索時に掲出されやすくすることでユーザの利便性を改善できないか、と考えました。
われわれが改善施策を考えるときには、国際学会で発表される論文を調べ、アイデアや知見を得ることが多くあります。
今回は、SIGIRという国際学会において2013年に発表された、Learning to Personalize Query Auto-Completion という論文を参考にすることにしました。これは、地域ごとに掲出候補をパーソナライズすることを目的とした論文であり、全米を10地域に分け、地域別検索数 (ユーザと同じ地域からの検索数)を集計し、機械学習モデルの素性 (feature) に追加しています。
この論文を参考に、機械学習モデルで地域を考慮する施策を実施することにしました。
まず、ヤフーでも地域を考慮する効果がありそうか、予備的な検証を行いました。
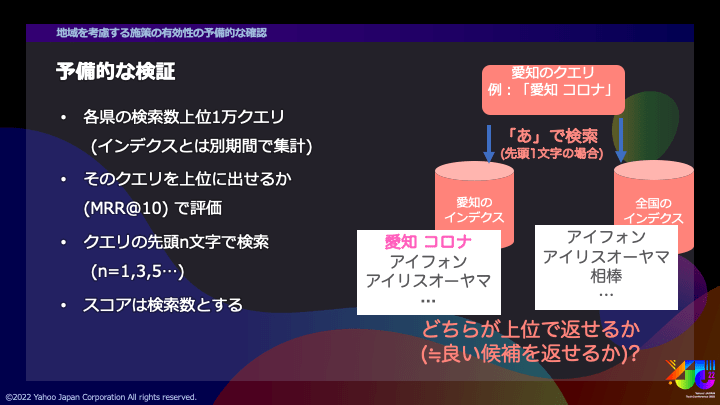
従来の日本全国で集計したインデクスとは別に、都道府県単位で集計したインデクス (例:愛知県からの検索クエリのみ)を用意しました。この集計はそれぞれ2週間分の検索数上位10万クエリを用いています(予備的な検証として少なめの量となっています)。
そして、作ったインデクスに対し、各県の検索数上位1万クエリを使って検索します。
QACではなるべく少ないキー入力で望む候補が上位に出ることが望ましいので、入力途中での性能を考慮して、クエリの先頭n文字 (例えばn=1,3,5) で検索します。この文字数は、日本語であれば読みがなの文字数としました。
たとえば愛知県のクエリ「愛知 コロナ」で検索するときに、n=1であれば先頭の1文字「あ」で候補を検索します。これで、全国と愛知のみのどちらのインデクスがより上位に出るかをMRR@10という指標で評価します。
検索に用いるクエリはさきほどのインデクスを作るのに使ったログとは別の期間のものを使っています。また、検索結果を並べるためのスコアは集計したログの期間中の検索数としています。
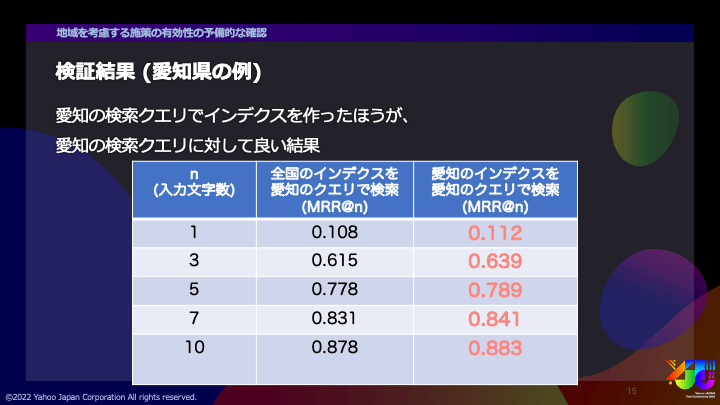
検証結果の一例として愛知県の結果を示します。いずれのnについても、全国のインデクスを使ったときよりも、愛知だけのインデクスを使ったほうが良い結果となりました。
機械学習モデルへの素性の追加
次に、実際に機械学習モデルに素性を追加することを考えます。機械学習モデルとしては、GBDT (Gradient Boosted Decision Tree) を用いていました。ここでは関連検索ワード用のモデルを題材とし、図のように、表示した関連検索ワードのうち、実際にユーザがクリックした候補を正例、それ以外の候補を負例として扱います。

素性としては、以前から使用しているモデルに、ユーザの位置情報の都道府県での過去の検索頻度や、その全国における割合などを新たに追加しています。検索頻度については例えば過去X日分など、期間を区切って集計しています。地域・位置情報については都道府県単位となっています。
また、オフライン・オンラインともに、位置情報の利用を許可する設定にしていただいているユーザの情報のみを、特定の個人を識別できないよう加工した形で使用しています。
オフライン検証の結果、以前からプロダクションで使用しているモデルと比較して、オフラインのMRRが0.56%改善しました。改善が見られたことから、本番環境でのA/Bテストを実施することにしました。
A/Bテストの実施と本番環境への100%リリース
2021年9月に実施したA/Bテストで、CTR (クリック率) がおおむね改善し、その後の100%リリースにつなげられました。

関連検索ワードに関して実際の事例として、例えば「イオンモール」というクエリについて、大阪と愛知で表示される候補が変わることが確認できました。

登壇時にいただいたご質問
YJTC開催時に、「地方と都市部での使用感に違いはありますか?」というご質問をいただきました。今回のアプローチでは都市部のほうが地方よりも地域に関連した候補が出やすいと考えています。 その理由として、検索数が候補のランキング与える影響が強いため、地方での地域系クエリの候補の検索数が他のメジャーなクエリ候補(全国どこでも検索数が多いクエリ)よりランキングで上位になるのが難しくなっていることが挙げられます。
また、別のご質問として、「単語によってローカライズされた方が適切なものと、そうでないものがありそうに思えますが、何か使い分けの施策はあるのでしょうか?」というご質問もいただきました。ご質問の通り、入力されたクエリの意図によって、地域性のある候補を出したほうが良いかどうかが変わるというのはたしかにありそうですが、今回のアプローチでは、明示的な使い分けのようなことは行っておらず、ランキング対象の各候補の過去の検索数などを元に機械学習モデルがランキングを決めています。
おわりに
本記事では、地域を考慮することによる検索入力補助の改善を題材に、改善の施策検討からオフラインでの実験、A/Bテスト、リリースまでの改善を回すプロセスを紹介しました。 ヤフーの持つ日本全国の検索データを活用することでこの施策を実施しました。今後もデータを活用してサービスを便利なものにしていきたいと考えています。
Yahoo! JAPAN Tech Conference登壇時のアーカイブ動画もありますので、よろしければご覧ください。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 山本 浩司
- Yahoo!検索 データサイエンスチーム



