初めに
こんにちは、Yahoo!知恵袋でシステム開発を担当している村上です。
Yahoo!知恵袋(以下、知恵袋)では利用者の皆さまに快適なサービス体験をしていただくため、日々改善が行われています。しかし、サービスができる事が増える度に、コードベースや連携先が増えていくのは常であり、その変化の影響でシステムトラブルが起きることもあります。
今回は、拡張されていくシステム構成という視点で、万が一のシステムトラブルが発生した時に備えて、被害を最小限に食い止める方法を紹介します。
背景
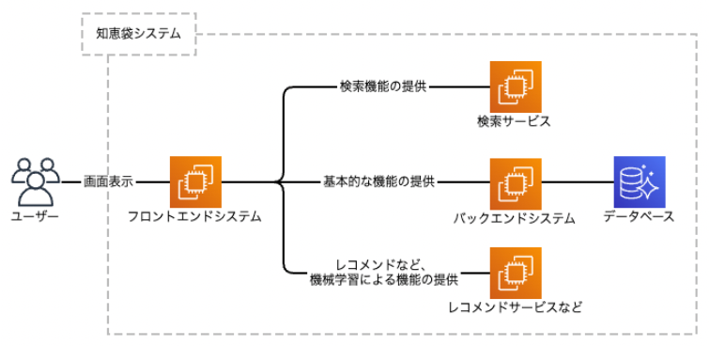
知恵袋では、以下のようなサービス構成を取っています。
フロントエンドシステムは基本的にAPIを通じて複数のバックエンドシステムと疎通することでサービスを提供しています。
ある時から、新機能提供のため、社内の連携先が増えて以下のような構成になりました。
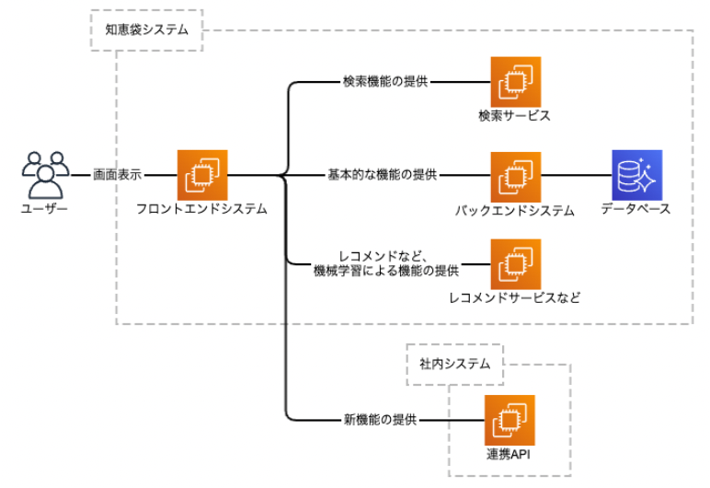
しかし、この新しい連携先において、知恵袋から流れてくるアクセス量が想定を超えており、レスポンスが返せない状況になりました。
この当時の設計では、知恵袋フロントエンドシステムは、新しい連携先が応答できなくなった際に自動でエラーページに遷移するようになっており、ユーザーがサービスを利用できない状況が発生してしまいました。
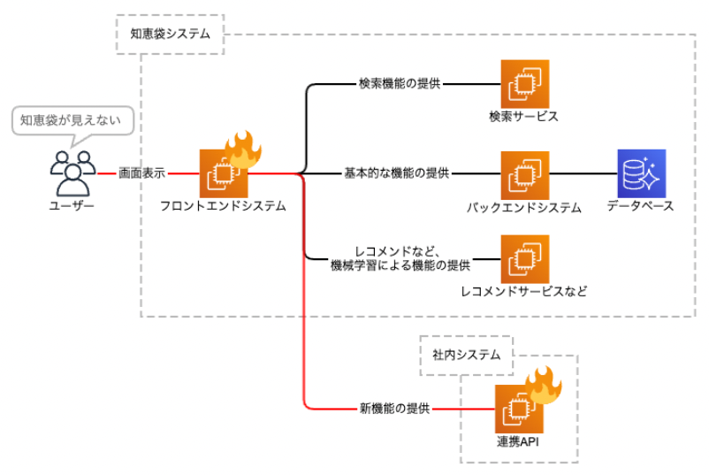
この時は緊急で新しい連携先との疎通を取りやめる対応を実施して応急処置としました。
問題が発生した原因はいくつも考えられます。例えば、リリースまでのテスト不足、予想負荷の見積もり不足、異なるサービス間における認識のすり合わせ不足など。
しかし、このような高負荷によるシステムトラブルが発生したら、新機能として掲出したいコンテンツは一時的に非表示にし、それ以外のコンテンツだけでサービスの提供を継続するという方法もあったはずです。
このようなトラブル時でもサービスを継続するための防波堤のような仕組み(以下、フェイルセーフと表現)をシステム的に実現する必要がありました。
Webページが何のために存在しているのかを考える
実装の話に移る前に、Webページにとって重要なこととは何か? ということを考えてみます。
例えば、Yahoo!知恵袋は質問ユーザーの問いかけに対して回答ユーザーが回答をつけていき、ユーザー間でさまざまな知見を共有するためのWebサービスです。
知恵袋では、オススメのQ&Aページや、よく見られているQ&Aページ、検索機能や、サービス運営のための広告の掲出などさまざまな機能を提供しています。本来であれば質問とそれに対する回答を表示するというのがユーザーにとって最も重要な部分であり、ユーザーの満足度を考慮すると、これを安定して提供できることを第一に考えるべきです。

そのため、Q&Aページとして必須な構成要素は何か? と考えると、それはヘッダーと質問文と回答文であり、それ以外の要素が非表示になったとしてもページを表示すべきと考えました。
逆に、質問文と回答文の取得に失敗してしまった場合、それはQ&Aページとしての最低限の体裁を保つことができないため、エラーにしてしまうのが適当だと考えました。
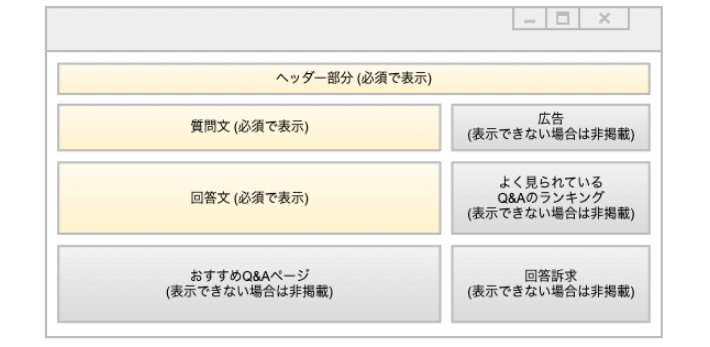
このように、まずはWebページにとって何が重要であり、何が重要でないかの切り分けを行い、組織として合意しました。
そうしておくことで実際にトラブルが起きた時でも、想定の範囲内の挙動としてビジネス側の心理的な負担を抑えることにもつながります。
フェイルセーフを実装すべき箇所を考える
今度はフェイルセーフを実現すべき箇所をアーキテクチャから掘り下げて考えてみます。
知恵袋のフロントエンドシステムではMVCをカスタムしたアーキテクチャを取り入れていて、以下のような構成になっています。
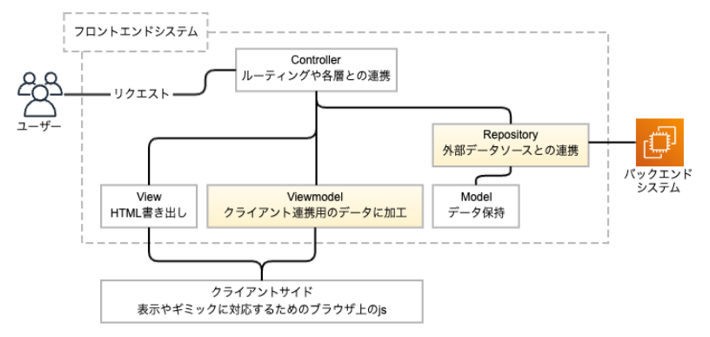
各層の役割を整理したところ、データの異常を検知できそうな箇所が以下の2つあることがわかりました。
| 層 | ポイント |
|---|---|
| Repository | ■役割 外部のデータソースと連携 ■データの異常に気づく方法 異常系のレスポンスコード、エラーメッセージ ■ユースケース 高負荷の対策 |
| Viewmodel | ■役割 クライアントサイドの処理に必要なデータを生成 ■データの異常に気づく方法 データを開いていく中で本来必要なプロパティが存在していない ■ユースケース バックエンド側のバグ対策 |
まず、Repositoryでは、データソースと連携している部分でステータスコードに着目してエラーハンドリングができます。
これは、バックエンド側の高負荷によって正常にレスポンスができない状態に陥っていることを検知するのに役立ちます。
次に、Viewmodelでは、クライアントサイドの処理に必要なデータを生成していることから、各層で最も深く取得したデータを展開することとなります。
ここで必要なプロパティがそもそも存在していないような場合、また、存在していないことが仕様外であると判断できる場合、これもバックエンド側で不正なレスポンスをしていると判断できます。
今回は、この2カ所でフェイルセーフを検討・実現しました。
フェイルセーフの実装方法
さて、次にフェイルセーフを実現するコードを考えてみます。
まずは、クライアントサイド側で非掲出にする際の振る舞いを実装しておきます。
データをリストのように表示するUIであればデータ0件の時は非掲出にするようにしてみたり、特定のオブジェクトが連携されてきた時に非掲出にするなど考えられます。
その上で、フロントエンドシステムのサーバーサイドが正常なデータを連携できないと判断した時、先ほど確認した非掲出用のオブジェクトをクライアントサイドへと返せるようにしてみます。
Repository層(データソースとの連携部分)の実装について
まずは、Repository側から考えてみましょう。
以下はここで例に取るRepositoryの仕様です。
- このRepositoryが受け取るレスポンスのJSONは、
res.contentまでは固定で存在していて、その中にデータを詰め込むような形を取る - 正常時のリクエストは全て
200を返しており、それ以外のステータスコードはハンドル外の挙動とする - さらに、空のオブジェクトを返却すれば、返却先のControllerでは例外が発生しないような作りであったとする
このような前提の場合、フェイルセーフを実現するコードは以下のようになります。
const axios = require('axios');
class Response {
constructor(response) {
if (!!response?.res?.content) {
this.content = response.res.content; // 取得したオブジェクトがresponse.res.contentまでは固定で存在しているため、開いてから定義。
} else {
this.content = {}; // 開けなかった場合、仕様外のデータとして空のオブジェクトを定義
}
}
getContent() {
return this.content;
}
}
class Repository {
async fetchQuestion() {
try {
const response = await axios.get('https://backend.com/question');
if (response.status !== 200) { // ステータスコードが仕様外の場合、例外を出力
throw new Error(`API response status is ${response.status}`);
}
return new Response(response).getContent(); // 受け取ったデータの確認をしてから返却
} catch (error) {
return new Response().getContent(); // 空のオブジェクトを返却
}
}
}
module.exports = Repository;まず、 /question に対してfetchを行った後、ステータスコードの検証をしています。ステータスコードが 200 以外の場合は、例外を飛ばしています。
また、正常経路や例外ハンドリングでも、Response というクラスに定義したエンティティを経由しています。
これの意味するところは、正常系のレスポンスに存在する response.res.content までのプロパティにデータがセットされているかどうかの確認となります。
この時点でデータの形がおかしい場合は、異常とみなして、クライアントサイド側がモジュール非掲出にできるようなデフォルト値を設定して返却しています。
これで、データソースから正しくレスポンスを得られている場合は値が返り、それ以外の場合は {} が返却されるようになりました。
Viewmodel層(フロントエンド側に必要データを生成する部分)の実装について
次に、クライアント側のレンダリングに必要なデータを生成する部分でのフェイルセーフを考えてみます。
ここでは、データを組み替える過程で、深く取得してきたオブジェクトのプロパティに触ることとなります。
その過程で、undefined なプロパティに対して参照を行うことで例外が出力されることを利用したフェイルセーフを実装していきます。
class Viewmodel {
convert(content) {
try {
return {
name: content.name,
question: content.detail.question // detailプロパティが存在しない場合は例外を出力する
}
} catch (error) {
return { name: "", question: "" }; // 正しくViewmodelを生成できない場合、クライアントサイドで非表示となるようなデータを返却する
}
}
}コード上ではRepository層で返却した content オブジェクトの中身を開いて、クライアントサイドのレンダリングに必要なデータに絞る処理をしています。
ここで、プロパティが存在しない場合の例外をハンドリングし、クライアントサイド側で非表示となるようオブジェクトを出力しています。
このように対策しておくことで、一部のバックエンドが高負荷ないし、実装ミスによって正常にレスポンスが返せないような状況が発生しても、フロントエンド側で該当モジュールのみを非掲出とすることによって、部分的にサービスを継続できるようになります。
フェイルセーフの副作用とその対策について
さて、ここまでフェイルセーフの考え方、設計、実装について触れていき、バックエンド側のトラブル時に備えたフロントエンドの仕組みを考えてきました。
しかし、これをそのまま運用してみると、今までエラー画面に遷移していたものが一部非掲出という状態になるため、ディレクターやエンジニアまで問題に気づきにくくなるという性質がサービス運用面では一部デメリットとなることに気がつくことでしょう。
ここで、重要になってくるのが適切な監視の仕組みです。
知恵袋ではPrometheusを利用して例外発生時のメトリクスを蓄積し、社内のモニタリングプラットフォームでダッシュボードを組むことで、状況の可視化やアラーティングを実施しています。
(もしOSSを利用するなら、Grafanaなどが利用の選択肢として上がると思います。)
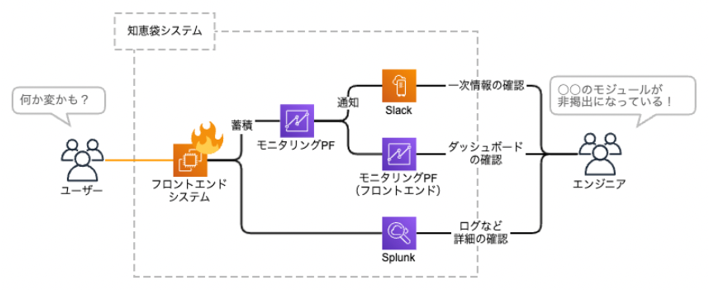
ダッシュボードを組む際はRepositoryとViewmodelで出力しているエラーメトリックを一体にして、画面に対してどのような影響が起きているのか? という観点でまとめておくと、エンジニアだけではなく、ディレクターにとってもわかりやすいサービス運用状況の可視化ツールとして活用することができ、緊急時の対応で合意が取れやすくなります。
このようにフェイルセーフの実装とともに適切な監視の仕組みを整えておくことで、ユーザーにはシステムトラブルによるご不便を軽減し、エンジニアにとっては具体的なアラートを軸に的確な対応を促せるようになります。
実際にフェイルセーフを導入してみてどうだったか?
実際にフェイルセーフの仕組みを導入してみてどうだったかご紹介します。
リリース前までの半年では、バックエンド起因でエラーページが掲出されるトラブルが数件発生していましたが、リリース後ではエラーページ自体が表示されるようなケースは0件に抑えることができるようになりました。
実際は、Q&A本体を組み上げるシステムはかなり強固に作られており、ほとんどトラブルを起こすことがなかったのです。
どちらかというと、新しく追加された機能や、新たな疎通先との連携でうまくいかず、ページ全体が落ちるという現象の方が多く、そういった場合に被害を限定的な範囲に抑えるという意味で、今回の取り組みは非常にうまくいったと評価できるものでした。
一方で、この対応のリリース後にRepositoryやViewmodelを開発する開発者に対してうまく意図が伝わっていないケースがあり、コードレビューでフェイルセーフを意識したコードを組んでもらうように指摘するケースもいくつかありました。
そこで、啓蒙活動の一環として、コーディングガイドを整備したり、概念やコーディング方法のシェアとして勉強会などを開いたところ、徐々にフェイルセーフを意識したコードを書いてもらえるようになりました。
このように、フェイルセーフは導入するだけではなく、それを陳腐化させないためにしっかりと啓蒙していくことも重要であることがわかりました。
まとめ
さて、今回はシステムトラブルに強いWebフロントエンドシステムを作る方法として、フェイルセーフの仕組みを導入する方法や、注意点についてご紹介いたしました。
システムは大規模になるにつれ、想定しない経路でのトラブル発生などが増えていくものです。そのような場合に、フロントエンドシステムはただエラーページに飛ばすだけではなく、フロントエンド側で妥協してでもサービスを継続するための手段を講じることで、最終的にユーザーにとって、本来サービスが果たすべき役割を提供し続けることができます。
この記事を読んで、共感された方は、ぜひフェイルセーフを意識したフロントエンドシステムの構築についてご検討いただければと思います。
ここまで読んでいただき、ありがとうございました。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 村上 賢達
- Yahoo!知恵袋 Web領域 フロントエンド・バックエンドエンジニア
- Yahoo!知恵袋のWebエンジニアを担当しています。設計、開発、運用、シェル芸まで何でもやります!
-



