ヤフーのData Solution事業(以下、DS事業)では、データの力で「日本全体を元気にしたい」という思いから、これまで自社サービス改善のために活用してきたビッグデータを使ったデータ分析サービスを展開しています。
(プライバシーポリシーの範囲内で取得したデータを個人が特定できない状態に加工しています)
ビジネスの上流工程における商品企画のほか、物流の最適化など、さまざまな用途にご活用いただけるサービスです。具体的なプロダクトとしては、「DS.INSIGHT」「DS.API」「DS.DATASET」の三つのほか、アナリストが最適なソリューション提案を行う「DS.ANALYSIS」を合わせた4種類を提供しています。
DS.INSIGHTは、消費者理解のためのWebツールです。検索ログを活用し、ユーザーの興味・関心を捉える機能や、位置情報ログを活用して人流分析を行う機能などを提供しています。 DS.APIは、ヤフーのビッグデータを、システム連携するためのサービスです。DS.DATASETは、市場分析や商品分析など、お客さまのニーズにあった分析データを提供しています。
今回は、この中から検索ログデータを軸に、ユーザーニーズへどのように応えているのかを紹介します。
アナリストが膨大なデータ分析で直面する課題
ヤフーが提供しているサービスには月間8,400万人のアクティブユーザーがおり、日本人の5人に4人が利用しているサービスです。そのため、年間におけるユニークな検索クエリは約81億にも及び、そのログのデータ量だけで年間約100TBとなります。なおDS事業ではコロナ禍以前のデータ分析も行いたいということで、約500TBのデータを扱っています。
こうした膨大なデータを分析することで、ユーザーの関心やユーザーが抱える課題への理解を深めることができます。例えば、日ごとに検索ランキングを比較することでユーザー興味の変化が明らかになったり、クエリごとの検索ボリュームを比較することで自社と他社の違いを明らかにしたりできるでしょう。
しかし、これだけ膨大なデータを分析しようとすると「データ集計に時間を要してしまい作業が非効率になってしまう」、「単純にデータベースに保存して活用するだけでも難しい」といった問題に直面するはずです。
分析の目的は、データからインサイトを獲得して事業に役立てることです。その目的をスピーディに達成するには、「データをどう効率的に扱うのか」を考えることが重要です。
そこで次項からは、データ分析環境に関する問題に対してヤフーではどのように取り組んできたのかを三つの観点から紹介していきたいと思います。
ポイント1:分析者を待たせない高速レスポンス
分析者を待たせないというのは、言い換えればデータ集計にかかる時間をいかに短縮化できるかということでもあります。データ分析で注力するべきことは、集計作業ではなく集めたデータを活用していくことです。
下図は、ヤフーが提供する分析ツールの実際の画面です。同ツールでは特定のキーワードに関するランキングと統計情報を参照できます。例えば、「ヤフー」に関連したキーワードとして、「ヤフートラベル 全国旅行支援」、「ヤフーショッピング お得日」が上位にランクインしており、サービスをお得に利用したいという検索意図が分かります。
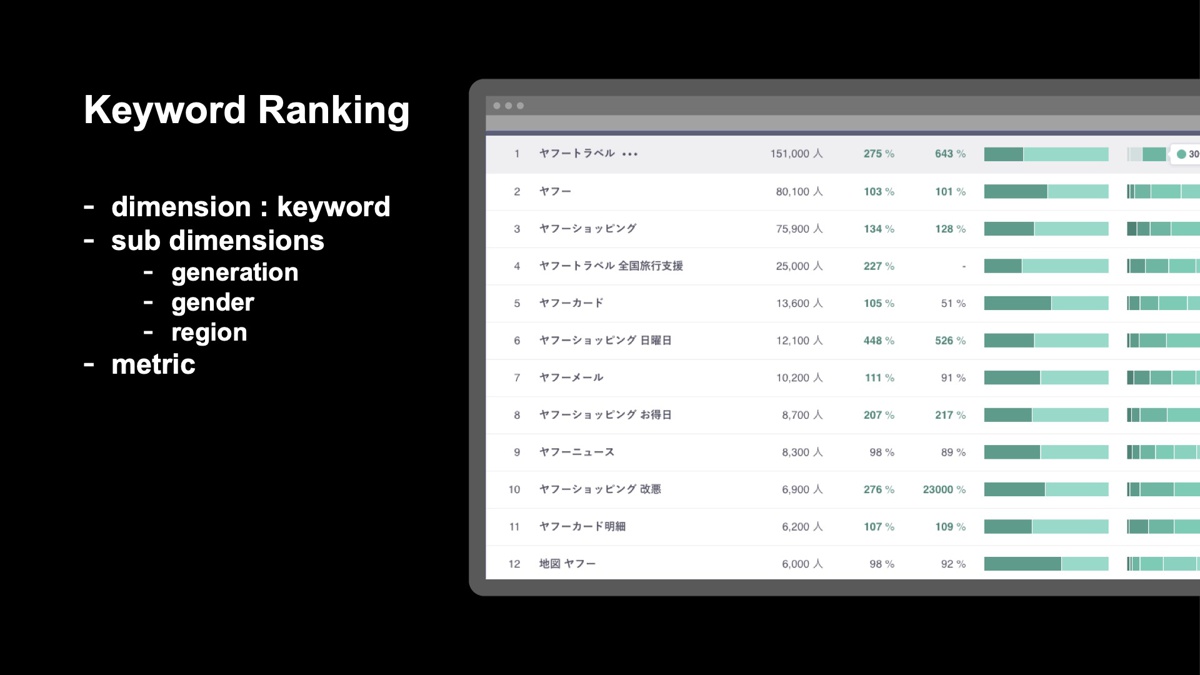
また、検索や分析を行う際には、ヤフーだけではなく他社サービスのキーワードも含めて調べることで、ユーザーの興味・関心をより深く調べられます。
こうした分析結果は、「ユーザーに何をすると効果的か」を考えるヒントになり、企画立案にも活用できます。
では、これをローデータから取得する場合はどうなるでしょうか。キーワードを抽出し、年代や地域ごとの割合などを集計していきますが、これを複数のキーワードでこの作業を進めるとデータの抽出だけに時間を要してしまい、本来注力したい分析作業に注力するためには、このような抽出作業などを高速化することが必要とされます。
DS事業では「検索ボリュームの推移」や「キーワードの時系列変化」など、汎用的に使える分析機能を提供しており、いずれの機能でも数秒程度で可視化できることを目指しています。こうした高速なレスポンスを実現するためには、ローデータをそのまま利用するのではなく専用のデータマートを作ることが重要です。
しかし、ローデータから目的に応じた分だけ専用のデータマートを作っていくと、ストレージコストが上昇してしまい、これは効率的な状態ではありません。そのため、「ストレージコストをいかに抑えるか」という課題にも対処する必要があります。
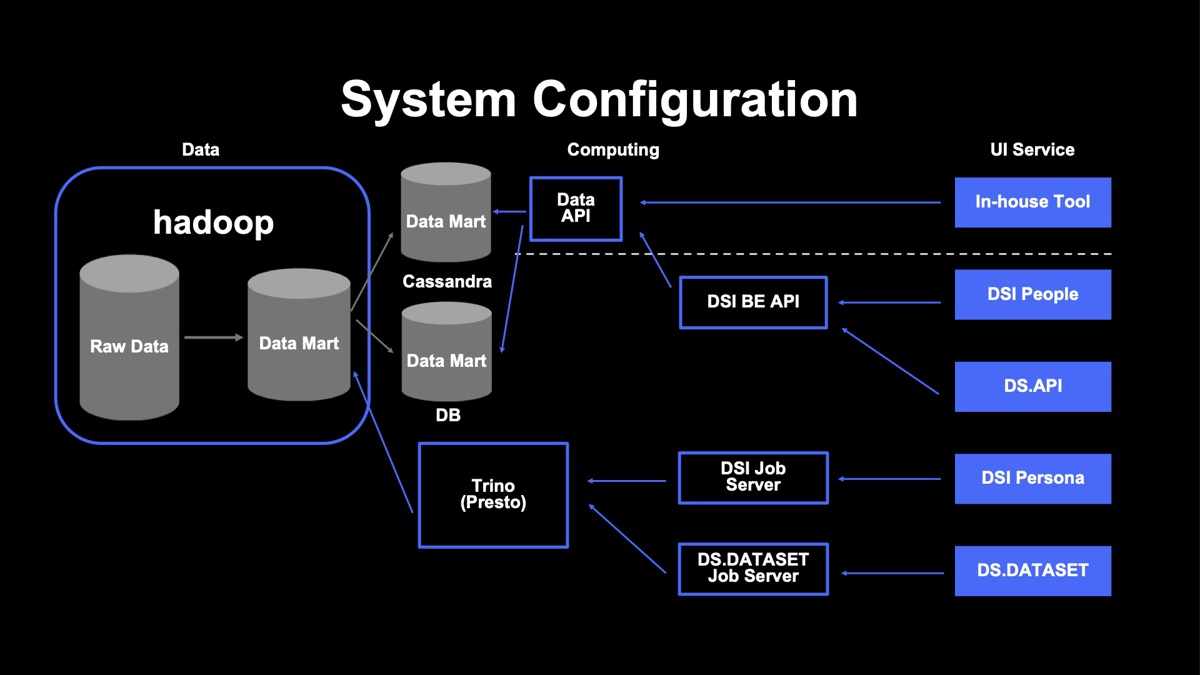
下図は、低レイテンシーでユーザーに結果を返すために実際に構築しているデータマートの構成です。DSI PeopleやDS APIでは低レイテンシーを担保しつつ、合理的にデータを扱うために専用のデータマートを作成しました。
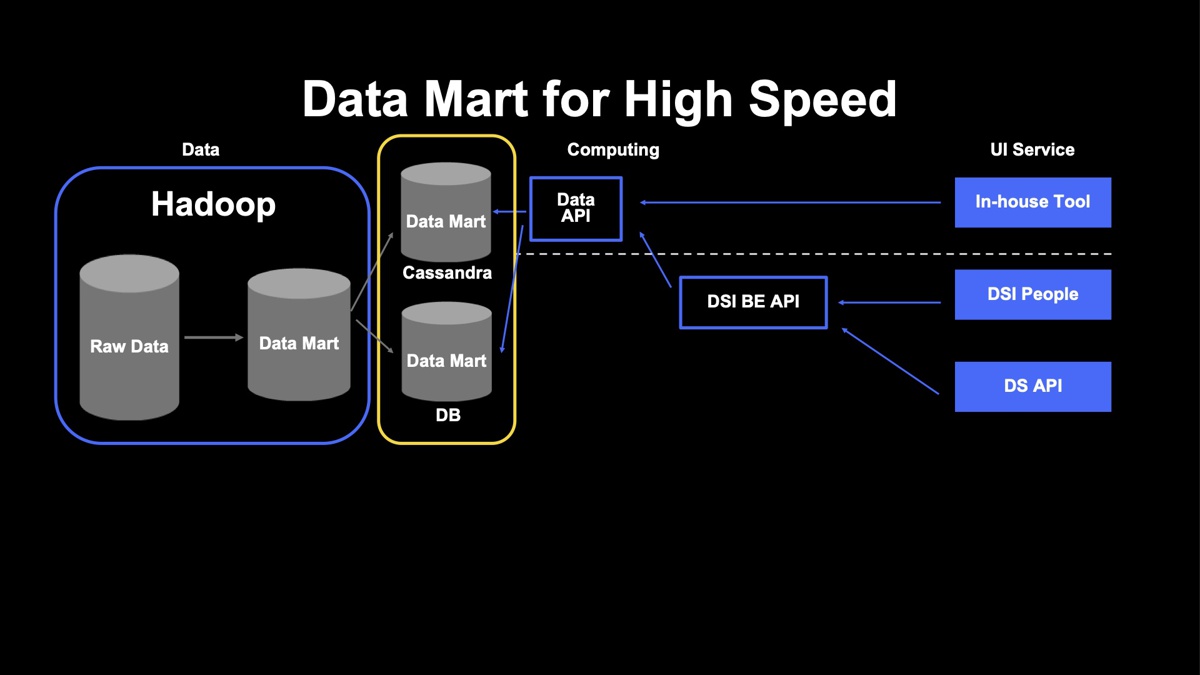
図内のApache Hadoop上にあるデータマートは、事業全体で利用するメインのデータマートであり、そこからキーワードごとの年代割合や機能に依存せず使えるような統計情報をApache Cassandra に、一方でランキング情報や時系列変化などといったデータを別途データベースに保存して扱っています。
この構成により、Apache Hadoopから低レイテンシーでデータを取得することが困難だった部分を解決し、ユーザーへデータを素早く返すという意味で、高速なレスポンスを実現できています。また、ランキング情報などのデータは統計情報に比べると小さいため、機能が増えた分、専用データマートを構築したとしてもストレージコストを抑えられます。
このデータが実際にどのような構成で保存されているかという点に関しては、例えばランキング情報は専用のデータとして切り出しています。一方で、統計情報は汎用的に扱っており、こちらはワイドテーブルでキーワードごとに性別年代の割合などを保存しています。これら二つのデータを組み合わせ、実際に活用しています。

こうすることで、キーワードのランキング情報やボリューム推移など、多くのユーザーが活用する機能において、データのストレージコストの抑制と、レイテンシーの短縮を実現しています。しかし、これらの専用データマートは集計済みのデータとなるため、より深い分析としてセグメントのまとめ上げなどを行うことは難しくなります。
ポイント2:分析者に柔軟な分析を可能にさせる
ここまで紹介した分析では、データの全体の傾向や動向を把握できます。しかし一方で「特定のユーザーグループはどんなことに興味を持っているか」、「特定の日程にどんなことが起きているか」といった詳細の分析は困難です。また検索データでは、「ヤフー ○○」と「○○ ヤフー」のような語順を入れ替えただけの同一意図も存在するため、これらをまとめ上げることも別途対策が必要です。
このように、データをもっと柔軟に扱いたいという課題に対してヤフーではTrinoを活用して、データマートから集計を行う方法で解決しています。特定のユーザー属性による抽出、任意期間での分析、カテゴリでのまとめ上げなどを実現しました。
もちろん、あまりにも柔軟にしてしまうと計算コストが増加し、実行が困難になります。つまり、「どれだけユーザーに柔軟な環境を提供できるのか」と「コンピューティングコストをどう扱っていくのか」という二律背反の問題に対して向き合っていかなければならないわけです。
下図が実際のシステム構成です。DS事業では、DS.DATASETとDSI Personaの二つのサービスで共通のTrinoを扱っています。メインのデータマートからSQLライクにデータを集計していますが、効率化のためにジョブサーバなども設置しました。
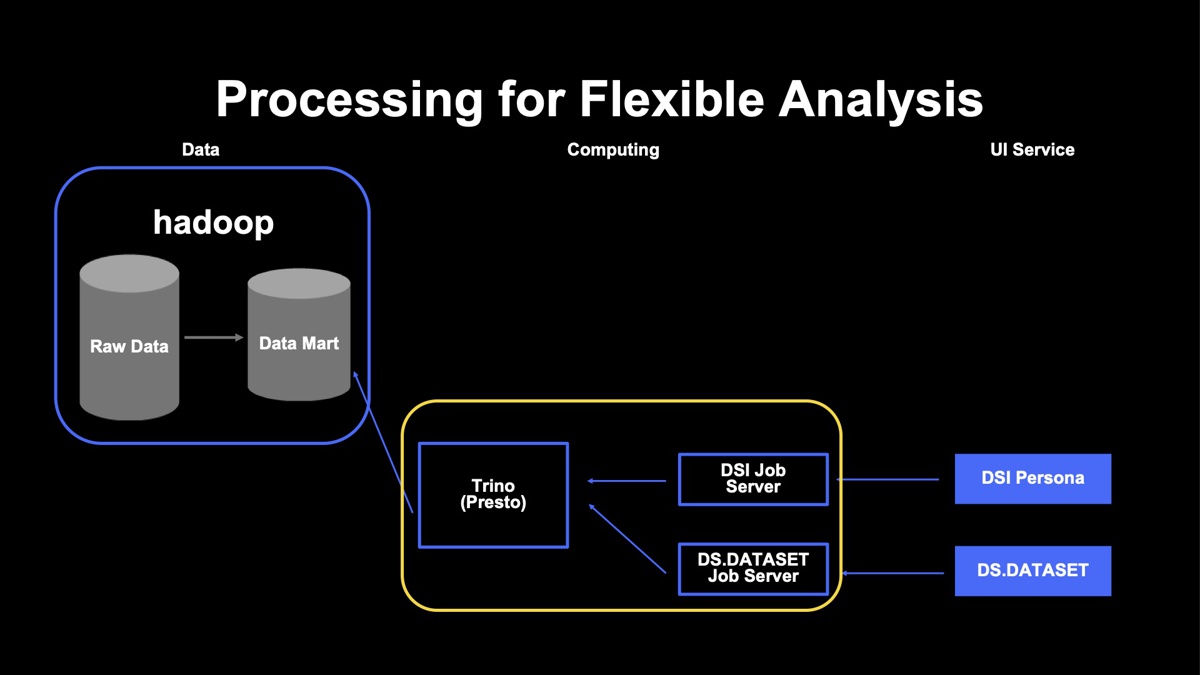
なぜこのような構成にしたのかについては、ヤフーがTrinoのコンピューティングリソースとどのように向き合ってきたのかという経緯とも関係しています。
Trinoに限りませんが、そもそも集計システムを活用していくと二つの課題が生じます。一つは「コンピューティングリソースの限界」をどう対処するか。もう一つは、分散システム固有の「ノイジーネイバー」の問題にどう向き合うかです。
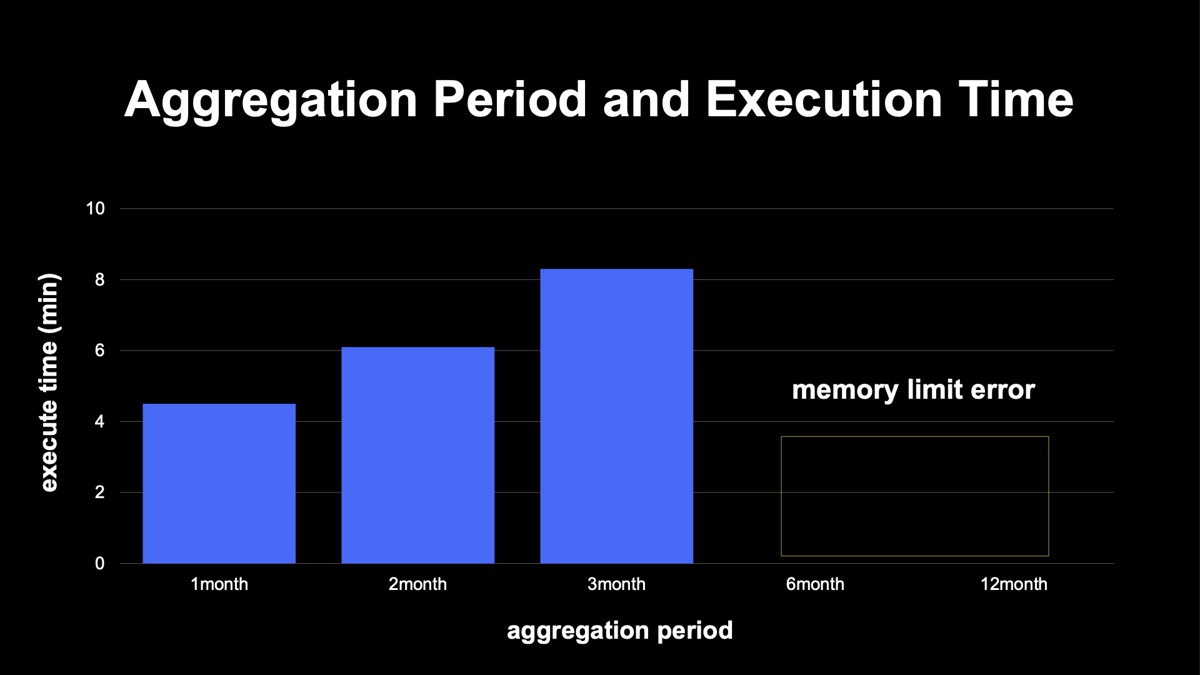
下図は、実際の検証結果のグラフです。横軸は一度の集計でどれだけの期間を扱うか、縦軸は実行時間を示しています。6カ月以上ではTrinoのクラスタのメモリ制限が上限に引っかかり、ジョブ自体が失敗しています。ユーザー数やユーザーニーズが増えた際に、扱うデータ量とコンピューティングリソースをコントロールしなければなりません。
続いて、集計期間と並列実行数の問題です。下図に示すように、1カ月と2カ月、どちらも並列実行していくとリニアに実行時間が延びていくことが分かります。ただ、1カ月の場合は6並列、2カ月の場合は3並列で、こちらの場合もクラスタのリソース上限に引っかかりジョブが失敗してしまいます。
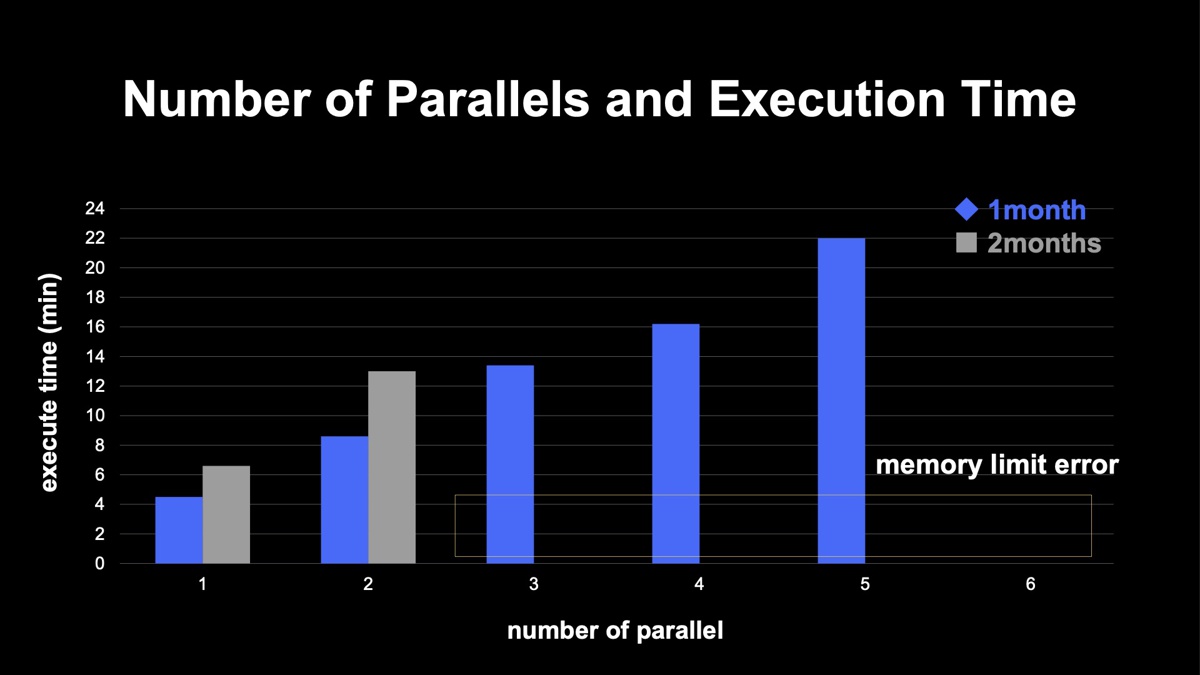
最大の問題は、ジョブが失敗した場合、その単一のジョブのみならず、全てのジョブが失敗してしまうことです。一度でも失敗するとユーザーに影響を及ぼすため、そうならないために、どのようにコントロールすれば良いかをノイジーネイバー問題では考えなければなりません。
私たちは一つのTrinoを複数サービスで利用しているため、お互いのジョブがノイジーネイバーとして影響を与えないように最小化していく方法を考えました。
その方法の一つが、サービスごとにリソースグループを分割することです。こうすることで、自分があとどのくらいのリソースを使用できるのかを把握できるので、サービスごとでコントロールが行いやすくなります。そのほかの対応方法としては、Trinoに直接リクエストするだけではなく、ジョブのマネジメントサーバも設置しています。これにより、クラスタに対して自分たちがどれだけ並列実行しているかもコントロールしやすくなりました。
ポイント3:分析の前処理を効率化する
データの前処理の手間暇をいかに削減できるかというテーマについて解説したいと思います。データ分析にかかる時間の約8割はデータの前処理にあるとも言われ、この部分をいかに効率化できるかが、データを扱っていく上での鍵を握ります。
このテーマは、下図のシステム構成における一番下のDS.DATASETの部分であり、実際にどのような処理を行っているのかを見ていきたいと思います。
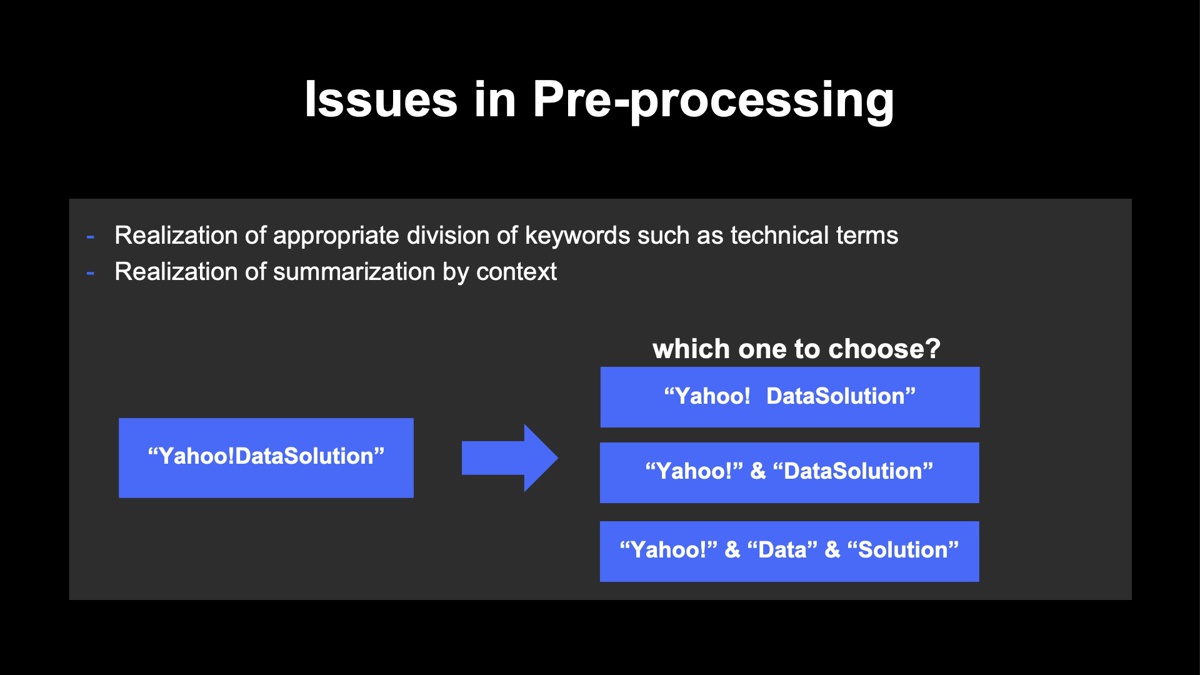
まず、検索キーワードの前処理について。ユーザーが検索時に入力するキーワードは、語順が異なったり、英語と日本語が混じったりするかもしれません。例えば「ヤフー DataSolution」と「データソリューション ヤフー」という別々の検索ログがあった場合、もしこれらを検索したユーザーの意図が、どちらも「Data Solutionの認知度を調べたい」というもので共通していれば、当然ながらこれらは同一のものとしてまとめ上げる必要があります。
しかし、こうした前処理をする際には「専門用語を正しく抽出できない」、「文脈を読み取ったまとめ上げが難しい」といった課題が生じます。例えば「ヤフー DataSolution」の例で言えば、それが単一の言葉なのか、あるいは複合語なのかという判断が難しいということです。商品・サービス名が混ざっていると、何をどう抽出すれば良いのかはさらに難しくなります。
こうした問題を解決するためにヤフーでは、実際にアナリストが行っている方法をヒアリングしながら、次の三つのルールを設けました。
1つ目に、検索キーワードをスペース区切りなどをベースに適切な単語で抽出し、トークンを取り出します。2つ目に、トークンごとにラベリングを行います。これは各トークンを分析の際にどのような意図で扱うかを目的としたラベル付けです。最後の3つ目として、ラベルを活用し、複雑な分析や集計ができるようグループ分けを行います。分析者の求めるデータを抽出するために、こうしたルールを適用しています。
DS.DATASETでは、集計を実現するために「アグリケーションシステム」と「辞書システム」をジョブ管理サーバとTrinoの間に置いています。検索キーワードの分割、トークン化は単純なSQLでは難しいので、Trinoからはデータ抽出のみ行い、そのまとめ上げはアグリゲーションシステムで行っています。
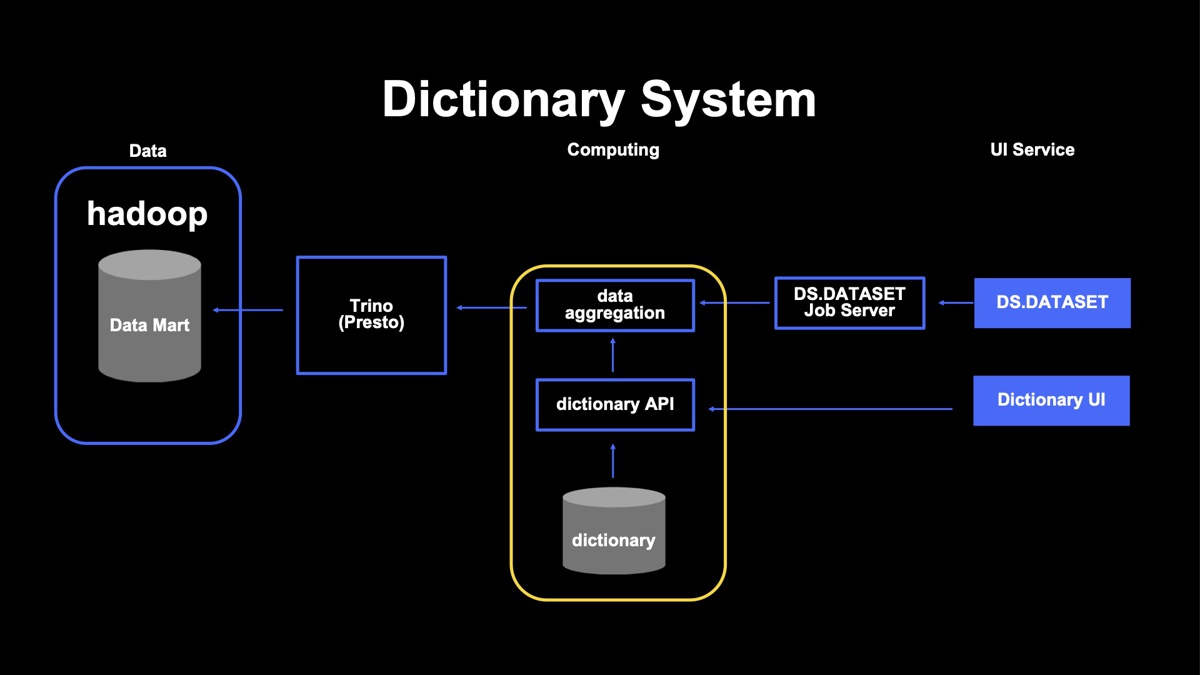
辞書システムには、集計に必要なルールを登録しておくことが可能です。一度登録すれば再利用もできます。また、独自にカスタマイズも可能です。
データの前処理に必要な三つのステップ
ここからは、具体的な処理について三つのステップに分けて紹介します。この例では、ある製品に対してユーザーの傾向分析を行うデータを作りたいという観点での前処理をテーマにしています。例えばエアコンの製品ごとにユーザーがどんなことに興味を持っているか、ユーザーが気にしていることは何であるのかを調べるためのデータを作るといったものをイメージしてみてください。
もととなる統計情報はキーワードごとに集計されるため、ユーザーの入力に影響を受け、語順や表記が入り乱れた状態です。まずはこうした単語を分割していきます。ただし、そこでは商品名などの専門用語も含まれるため、効率的に実行するためには処理の度に辞書システムから別の辞書を作り出して分割処理を行っています。

次に、分割したトークンに対して、最終的に分析したい意図のまとめあげを行うための準備です。例えば「激安」や「価格」というのは異なる言葉ですが、いずれも「価格」に興味があるということは共通しており、「価格」というラベルでまとめることができます。同様に「口コミ」や「人気」というキーワードも、「評価」というラベルでまとめることができます。このように、分析したい単位で集約するというのがラベリングです。
最後に、ラベリングしたものをさらにグループ化します。ラベル単体では商品ごとや製品ごとの分析が難しい状態になっているため、「どのような単位でまとめるか」を定めていきます。それが下図に示したものです。例えば、「商品」というグループには商品A~Cが含まれており、同様に価格のグループには、各価格のデータが含まれます。そうすることで、ラベルを持ったもの同士を分析対象にできます。

グループ化したものを仮想的に一つのテーブルにまとめます。最終的には、データをBIツールなどに読み込ませて、すぐに分析できるようにすることが重要です。そのために、分析者が扱いやすいように仮想的な一つのデータテーブルの形をとっています。
まとめ
最後のまとめとして、要点を解説したいと思います。まず分析環境としては、汎用的な分析と柔軟性が必要な分析の2種類があり、それぞれのニーズに応じた構成があるということに触れました。その中では、活用するデータの整合性をいかに担保していくかを考慮しながらメインのデータを作っています。
また、データ分析における前処理の手間を減らすというアプローチでは、いかにルールを作っていくかという考えが必要です。もちろん、ルールを作るだけでなく、データは最終的にユーザーが扱うものということを念頭におき、テーブル構造を意識してアウトプットを出すことが必要であると考えています。
今後の課題としては、まだ長期間での柔軟な分析ができない部分も多いため、その観点での最適化を図ることが必要だと考えています。また、現状はルールベースで前処理を行っていますが、カテゴリ付与などはAIの得意分野であるため、AutoFMなどを活用し自動化を適用できないか、検証を進めていきます。
アーカイブ動画
Apache®, Apache Cassandra™, Apache Hadoop™, 及びCassandraのロゴ, Hadoopのロゴは、米国および/またはその他の国におけるApache Software Foundationの商標または登録商標です。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 山口 寛
- データ統括本部 リーダー
- DataSolution事業のプロダクトチームリーダーとしてDS.APIやDS事業業務基盤システムをみている傍ら、最近はデータ利用のためのセキュリティマネジメントなども合わせて取り組んでいます。



