こんにちは。サイエンス統括本部で検索エンジンのプラグイン開発を担当している真鍋です。
ヤフー社内には、機械学習したモデルを実行してドキュメントの順序を決めるためのApache Solr(以下Solr)プラグインが存在します。
しかし、このようなプラグインを書く方法がまとまったコンテンツは多くありません。 日本語であればなおさらです。そこで先日、Solrプラグイン開発チュートリアルとデモ用のプラグインの完成品を公開しました!
この記事では、まずSolrについて簡単に説明し、続いて、このチュートリアルの内容を簡単に紹介します。
Solrとは

Solrは、The Apache Software Foundationがメンテナンスしているオープンソースの検索エンジンです。ここでいう検索エンジンとは、例えばYahoo!検索のようなWeb検索サービスのことではなく、そういったサービスの裏側で動作するソフトウェアのことです。
検索エンジンの動作はWeb検索サービスに似ています。Web検索サービスにキーワードを入力するとWebページのランキングが表示されるのと同様、基本的にはSolrにもキーワードを入力するとドキュメントのランキングが表示されます。
ここで何をドキュメントにするかは自由に決めることができます。例えばWebページをドキュメントにすればWeb検索サービスになりますし、商品情報をドキュメントにすればECサイトの検索機能になります。ヤフーでも、Solrで多くのサービスの検索機能を実現しています。
Solrの特徴として、プラグインによって非常に柔軟に動作を変更することが可能です。例えば、Solrには検索結果のドキュメントを指定の順序に並べる標準機能がありますが、サービス開発者としては標準機能では表現できない複雑な順序を指定したいことがあります。そこで、ヤフー社内には、機械学習したモデルを実行して順序を決めるためのプラグインが存在します。
参考スライド:Solrで多様なランキングモデルを活用するためのプラグイン開発
Solrプラグイン開発チュートリアルとは
冒頭でも触れたように、このようなSolrのプラグインを書く方法がまとまったコンテンツは多くありません。そこで、このような問題意識を受けてこのチュートリアルを書きました。具体的には今のところ、このチュートリアルを読めば「検索結果上位のドキュメントを、そのフィールド値に基づいて並べ替える」プラグインを書けるようになることを目指して書かれています。
1. プラグインの動作の起点をつくる
Solrのプラグインを書くとは、Solrの処理の要所で自作のコードを呼んでもらう、ということです。そこで、SearchComponentを実装してみましょう。これは、まさにSolrの検索処理の要所で呼ばれるコンポーネントで、ここに自作のコードを書くことで、Solrのプラグインを書くことができます。
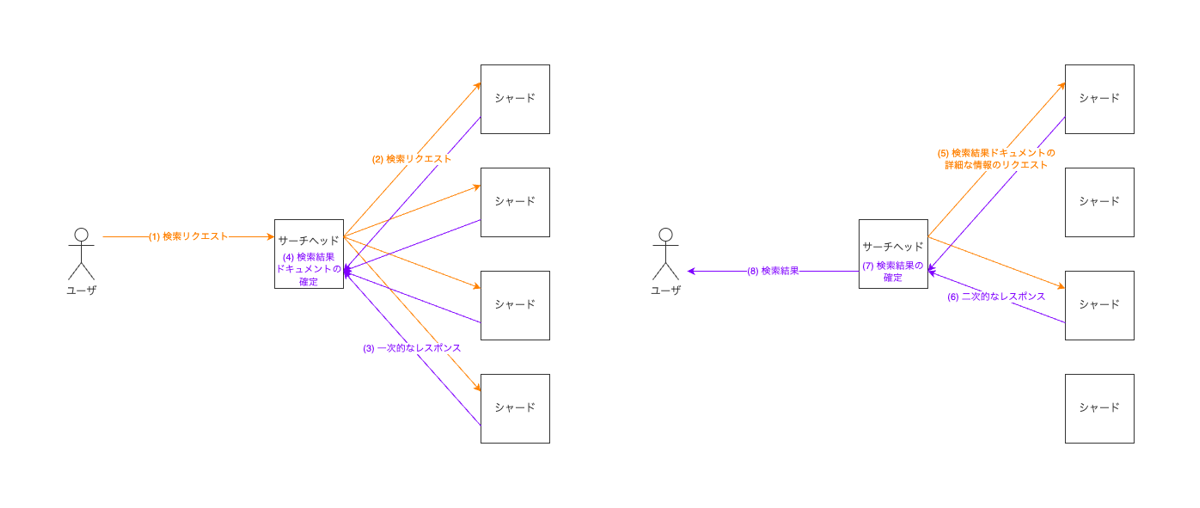
しかし、SearchComponentを書くのは非常に簡単というわけではありません。これは主に、Solrには大量のドキュメントを複数のサーバに分割して保存する機能が備わっているためです。このため、SearchComponentに書いたコードは異なる役割を持った複数のサーバで呼ばれますし、さらに複数のタイミングで呼ばれます。
また、SearchComponentはプラグインの動作の起点ですので、ここをテストすればプラグインの全体的な動作をテストすることができます。
詳しくは、プラグイン開発チュートリアル第1章をご覧ください。多くをSolrの挙動の整理に割き、テストについても簡単に触れています。
2. 検索結果上位のドキュメントを並べ替える
通常、検索エンジンはキーワードに対して各ドキュメントのスコアを計算し、その降順にドキュメントを並べ替えます。しかし前述の通り、それだけで検索結果の質が担保できるとは限りません。サービス開発者としてはコードの表現力で高度な並べ替えを行いたいこともあります。たとえばECサイトの検索機能で旬のフルーツの検索結果において、イチゴだけが上位に並んでいるよりも、ミカンも適度に並べた方が全体の売り上げが上がるといったケースです。
そこで、RankQueryを実装します。これは、まさに検索結果のドキュメントを並べ替えるためのコンポーネントです。RankQueryもやはり異なる役割を持った複数のサーバで呼ばれることになります。
詳しくは、プラグイン開発チュートリアル第2章をご覧ください。
3. ドキュメントのフィールド値にアクセスする
並べ替えの際には、通常、ドキュメントのフィールド値にアクセスする必要があります。フィールド値とはドキュメントの一部のことで、例えば商品情報のフィールド値には商品名、説明文、価格、カテゴリなどが考えられます。たとえば先ほどのケースでは、カテゴリがイチゴであるか、ミカンであるかを判定して処理を分岐させる必要があります。
フィールド値へのアクセスは簡単そうですが、主に高速なアクセスのためいろいろな制約があります。例えばSolrは内部的には通し番号によってドキュメントを区別し、プラグインはこの順でフィールド値にアクセスすると高速になります。また、ここでもやはり複数のサーバに対応する必要があります。特に、ドキュメント自体を保存しているわけではないサーバにおいて、あるドキュメントのフィールド値を使うためには、明示的に送受信する必要があります。
詳しくは、プラグイン開発チュートリアル第3章をご覧ください。ドキュメントのフィールド値にアクセスするためのDocValuesオブジェクトの扱いや、フィールド値の送受信について説明しています。
おわりに
お読みいただきありがとうございました。前述の通り、Solrの動作はプラグインによって非常に柔軟に変更できます。このたび公開したチュートリアルが、そのポテンシャルを活かすための一助となり、Solrコミュニティの発展につながれば幸いです。
Apache SolrおよびSolrのロゴは、米国およびその他の国におけるApache Software Foundationの登録商標または商標です。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 真鍋 知博
- 検索エンジン黒帯
- サイエンス統括本部で検索エンジンのプラグイン開発を担当しています。
-



