AutoFMという、基盤モデルの学習推論を自動化できるプラットフォームについて紹介します。
BERTの概略
近年、基盤モデル(Foundation Model)と呼ばれるモデルが注目を集めています。基盤モデルとは、テキストや画像などを含む大規模なデータから学習し、それを用いることによって質問応答や評判分析など、さまざまなタスクに利用できるモデルのことで、スタンフォードのグループが論文で提唱した言葉です。

基盤モデルには、言語処理のモデルである「BERT」や「GPT-3」、言語と画像のマルチモーダルモデルである「CLIP」などが含まれており、言語処理や画像処理の分野で大成功を収めています。今回はBERTにフォーカスして紹介します。
BERT(Bidirectional Encoder Representations from Transformers)は、Googleが2018年に発表した自然言語処理のモデルで、近年さまざまな分野で利用されているトランスフォーマーをベースにしています。
BERTはさまざまな言語処理のタスクで、一昔前のモデルに比べて大幅な精度向上を達成しています。BERTの特徴として、事前学習である「プレトレーニング」と、「ファインチューニング」の2ステップから成り立っていることが挙げられます。
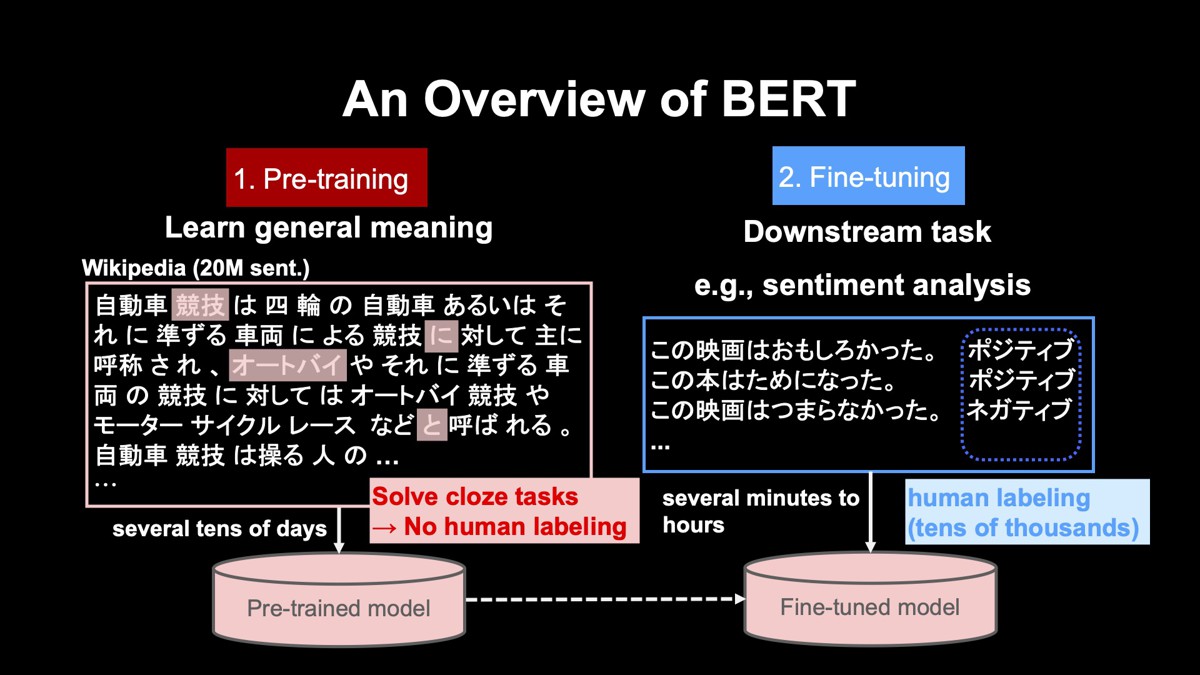
プレトレーニング
まず左のプレトレーニング(事前学習)では、大規模なテキストを用いて、言葉の一般的な意味を学習します。例えば、日本語のWikipediaは約2000万文からなりますが、こうした大規模なテキストを用いて事前学習を実施します。
この事前学習では、ランダムに隠した単語を周りの単語から推測する、いわば“穴埋め問題”をひたすら解きます。例えば1行目で隠されている「競技」という単語は、周りの「自動車」「四輪」などの単語から推測します。同様に、2行目で隠された「に」という単語は、周りの「競技」「対して」という単語から推測します。このような穴埋め問題をひたすら解くことで、各単語がどのような意味を持つかを学習できます。
この穴埋め問題は、ランダムに単語を隠すことによって自動生成できます。つまり、人の手によって正解を付与する必要がありません。従って、いくらでも大規模なテキストを用いることができます。事前学習は非常に計算に時間がかかり、おおよそ数十日かかります。ただ、学習は一度行えば良いため、学習したモデルは社内で共有しています。
ファインチューニング
次に、右のファインチューニングを行います。ファインチューニングでは下流タスク、すなわち実際に解きたいタスクの学習を行います。ここでは例として評判分析、つまり入力文がポジティブであるか、ネガティブであるかを分類するタスクを扱います。
この例では、「この映画はおもしろかった。」という入力文に対してポジティブ、次の「この本はためになった。」もポジティブ、最後の「この映画はつまらなかった。」をネガティブと分類します。ファインチューニングでは、入力文に対するラベルを人手で付与する必要があります。
ラベル付与は、数千から数万件、必要になります。このファインチューニングは、事前学習で学習した左下にあるモデルをスタートとし、下流タスクが解けるようにチューニングする形で学習が行われます。ファインチューニングは事前学習と異なり、数十分から数時間と比較的短時間で終わります。短時間でできるのは、事前学習でひたすら鍛えたモデルをスタートとしているからです。
以上がBERTの概要で、このように二つのステップに分けることによって、強力なモデルを学習できます。
BERTの問題点
BERTは非常に強力なモデルですが、使う上で問題が二つあります。
一つ目の問題は、BERTのような基盤モデルを使いこなすのは、そんなに簡単なことではないということです。基盤モデルを正確に理解するには、さまざまな知識が必要です。自然言語処理になじみのないエンジニアにとってはとても難しいことですし、自然言語処理のエンジニアにとっても難しいことです。
二つ目の問題は、基盤モデルを使いこなせたとしても、各部署が単独でモデルを開発すると無駄が発生してしまうことです。BERTのような基盤モデルは、非常に汎化されているため、一昔前のモデルとは異なり、各タスクで独立にコードを書く必要はありません。
ヤフーでは、この二つの問題を解決するために、基盤モデルの学習を自動化する「AutoFM」というプラットフォームを開発しています。
AutoFMの基本的な思想、動かし方
AutoFMとは何か
まずAutoFMとは何かを説明します。AutoFMは造語です。AutoML(Automated Machine Learning)という機械学習を自動化する考えの「Auto」と、Foundation Model(基盤モデル)を略した「FM」をくっつけて、AutoFMという名前にしました。
AutoFMは、より具体的には基盤モデルの学習・推論を自動化するためのプラットフォームで、ヤフー社内のAIプラットフォーム上で構築しています。AutoFMの目的は、基盤モデルの学習または検討、デプロイなどをできるだけ簡単に実施できるようにすることです。
キーコンセプトは、ユーザーがここに示すような学習、もしくは評価ファイルを用意するだけで、ファインチューニングからデプロイまでできるようにすることです。下図では、各行が1つの学習データを表しています。左の「この映画はおもしろかった。」などの文が入力文、右の「ポジティブ」「ネガティブ」が入力文に対する正解ラベルです。先述したように、正解ラベルは人の手で構築する必要があります。

このような学習データのみを与えることによって、ユーザーはコードを一切書かなくてもよくなり、実装の手間やミスを防ぐことができます。
設計思想
システムのデザインには、二つの大きな設計思想があります。
一つ目は独自コードを避けることによって、属人化しないようにすることです。属人化しないようにすることは、長期的にコードをメンテナンスする上で非常に重要です。このためにTensorFlow 2のOSSである公式スクリプトをベースに、それを少し改良する形を採っています。また独自の学習推論システムを構築するのではなく、社内のAIプラットフォーム上で動くようにしているため、属人化を避けることができています。
二つ目は、汎用的な部分とプロジェクト固有の部分を切り離すことを常に意識していることです。プロジェクト固有の部分をメインのプログラムにハードコーディングしていくと、複数のプロジェクトで同じシステムを使うのが難しくなっていきます。そうならないように汎用的な設計を行い、プロジェクト固有の処理が必要であればシステムの外に出すようにしています。
社内のAIプラットフォーム上でのシステムの動かし方
まず、モデルの学習すなわちファインチューニングする方法を紹介します。
これはLakeTahoeと呼ばれる社内の学習システムを使っています。先ほど説明したような学習ファイルをサーバー上に置き、こちらに示すようなジョブをサブミットするだけで、ファインチューニングを行うことができます。また、ハイパーパラメーターのサーチも簡単に行えます。

上図の左下に示したような設定ファイルを記述します。青字で書いたところには、検証セットでの精度の最大化が目標であることを記述し、その下にはエポック数と学習率の組み合わせをいくつか探索することを記述します。
このような設定ファイルを用意し、同じジョブをサブミットするだけでハイパーパラメーターサーチを行うことができ、上図右下に示すような結果が得られます。
繰り返しにはなりますが、これは新たに実装したわけではなく、既に社内にあるAIプラットフォーム上の機能を利用しているだけです。
MLFlowを用いた実験管理
次に、OSSであるMLFlowを用いた実験管理について紹介します。
いろいろと条件を変えてファインチューニングを行うと、どの条件でファインチューニングを行ったモデルなのかよく分からなくなります。そこでMLFlowを用いて、下図に示すような実験管理を行います。
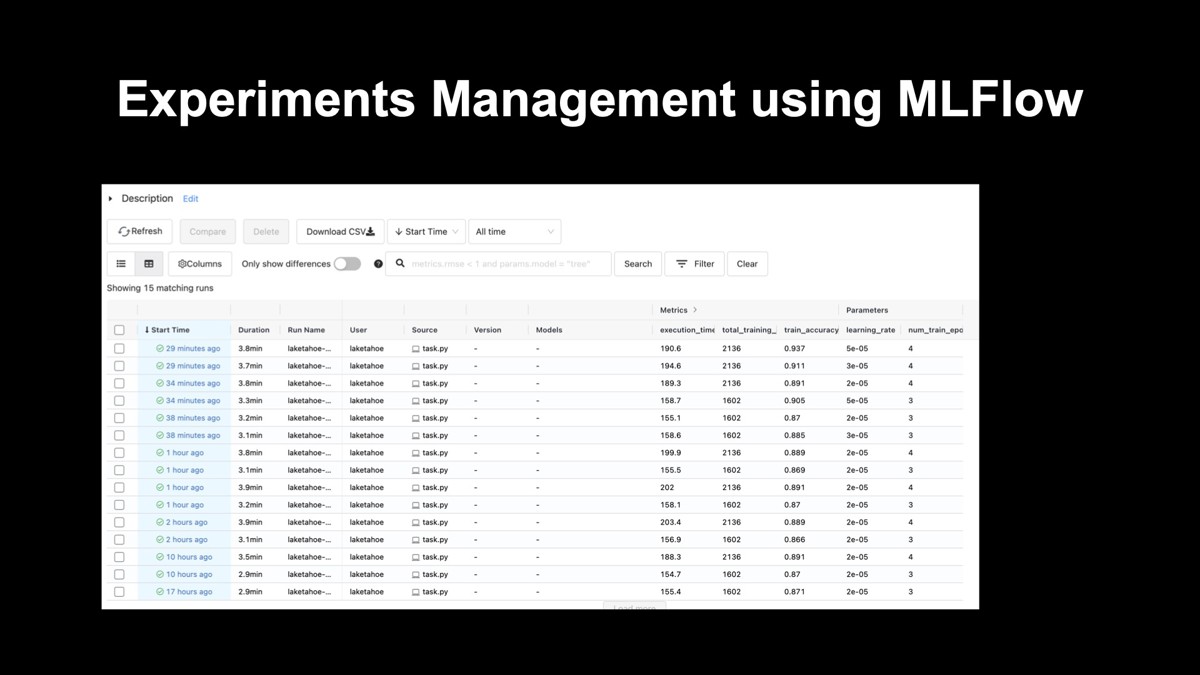
1行が一つのファインチューニングに対応し、そのファインチューニングのハイパーパラメーターや精度が記録されています。システムの出力と成果を見やすくすることは、モデルを検討する上で非常に重要です。
このような解析結果のビューアーを提供することで、システム出力や成果を見やすくしてモデルの検討を行いやすくしています。
マネージド推論サービス「CuttySark」を利用したデプロイ
最後に、モデルのデプロイです。これは社内で内製している「CuttySark」と呼ばれるマネージド推論サービスを用いています。コマンドをたたくだけで簡単にモデルをデプロイすることができ、デプロイした後にこのようなコマンドを発行するだけで、システムの解析結果を得ることができます。
この例では、先ほど説明した文がポジティブなのか、ネガティブなのかを分類する極性分類のタスクを行っています。入力文の「この本を買ってよかった。」を入れると、システム出力が「ポジティブ」で、確信度がその上に示されています。

また、このような日本語の文字列を扱う上で前処理、すなわち文字列から単語のIDへの変換処理が必要となる場合があります。それは隠蔽することによって、ユーザーは日本語文を入力するだけでよくなります。
ヤフー社内でのユースケース
検索クエリのカテゴリ分類
先述した通り、AutoFMは汎用的な設計になっており、学習データを変えるだけでさまざまなタスクに適用できるようになっています。
検索クエリのカテゴリ分類でも、検索クエリとそのカテゴリを与えるだけで動きます。例えば「マリトッツォ」というスイーツがグルメやレシピ・料理というカテゴリであることや、「ソフトバンク」というクエリはスマートデバイス、もしくは企業・組織というカテゴリであることを学習データとして与えます。
AutoFMは検索クエリの分類を行っていることを知りません。単にこの学習データを与えるだけで、ソースコードの中にクエリのカテゴリ分類を行っていることは記述されていません。ヤフー社内のタスクには、BERTによるテキスト分類と見なせるものがたくさんあり、いろいろなサービスで使われ始めています。
検索クエリのログはユーザーのニーズや課題を理解するために不可欠なものです。検索クエリのログを分析する上で、通常、クエリを人名や商品名などのカテゴリに分類し、カテゴリごとに分析されます。
検索クエリをカテゴリに分類する上で問題となるのは、クエリのログが非常にロングテールなことです。従って低頻度のクエリも高い精度で分類することが求められます。また、クエリのログには日々生み出される新語や専門用語がどんどん入ってきます。そうした新語に対しても、正しく分類できることが求められます。
そこでAutoFMを用いてBERTで検索クエリのカテゴリ分類を行っています。BERTはクエリのカテゴリ分類においても、一昔前の機械学習手法よりも大変良い精度を達成しています。

左の事前学習では、ヤフーの検索クエリのログを使っています。これはWikipediaではタイムリーに新語がカバーされていないからです。検索クエリのログは重複を除いた約5000万クエリを使っています。ここに示している通り、「YouTube」や「ヤフー ログイン」などのクエリを使っています。
先述したように、穴埋め問題をひたすら解くことによって言葉の一般的な意味を学習します。モデルの学習には約15日かかりますが、学習したモデルは社内で共有することによって、各プロジェクトで別々に学習しないようにしています。
次に、右のファインチューニングを行います。ここでは、検索クエリとそれに対応するカテゴリのペアからなる学習データを用意します。これは約3万件です。この分類においてはマルチラベル分類といって、一つの検索クエリに複数のカテゴリに分類されうる問題設定にします。例えばソフトバンクは、「スマートデバイス」と「企業・組織」の2つのカテゴリに分類されます。ファインチューニングは10分ぐらいですぐに終わります。
新語や専門用語のカテゴライズ
先ほど、スイーツの「マリトッツォ」の例を挙げました。なぜマリトッツォを「グルメ」と正しく分類できるのでしょうか?
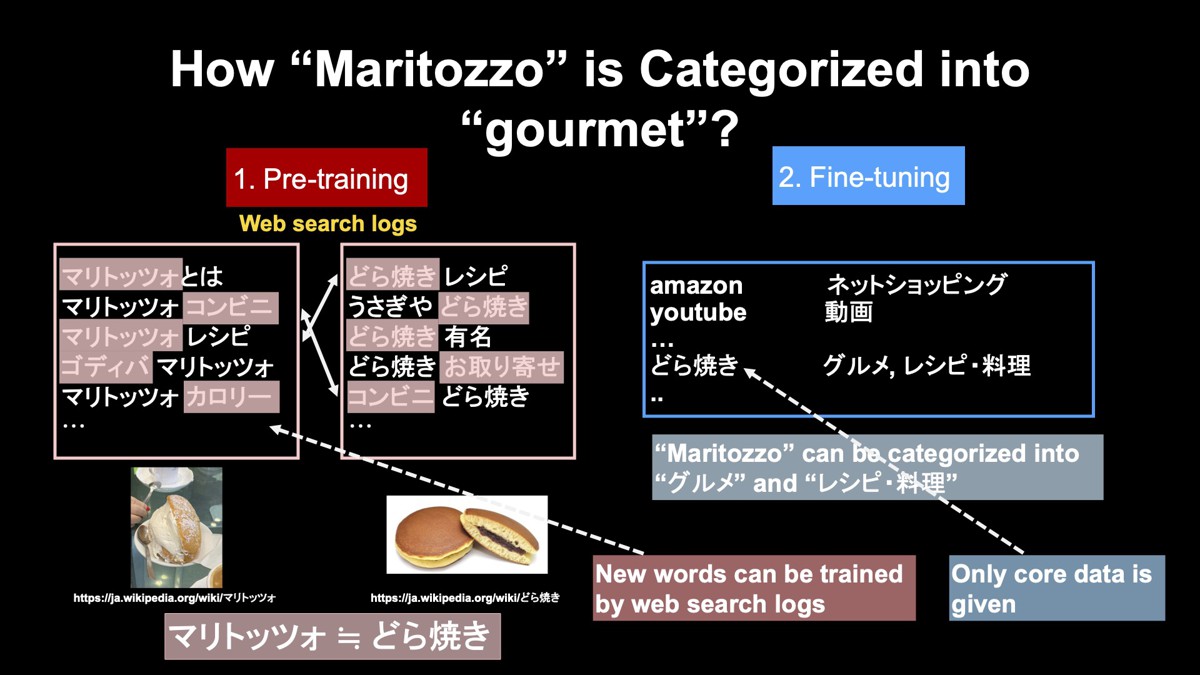
事前学習に用いた検索ログでは、マリトッツォは「マリトッツォとは」「マリトッツォ コンビニ」のように他の単語と一緒に検索されます。マリトッツォを知らない方でも、「コンビニ」「レシピ」「ゴディバ」などと一緒に検索されていることから、マリトッツォがスイーツであると推測できます。
これと同じようなことをBERTも行っています。マリトッツォと同じようなものとして「どら焼き」を考えてみましょう。どら焼きもレシピやコンビニなどと一緒に検索されています。これらの検索ログに対して、先ほど説明した穴埋め問題を解きます。
例えば、「レシピから隠されたマリトッツォを推測している行」と、「レシピから隠されたどら焼きを推測している行」を見比べると、同じことをしていることが分かります。また、他の行では、「マリトッツォから隠されたコンビニを推測している行」と、「どら焼きから隠されたコンビニを推測している行」があり、こちらでも同じことを行っています。
このような学習を続けていくと最終的には、マリトッツォとどら焼きは同じようなもの、もう少し詳しく言うと、同じようなベクトル表現であることが学習されます。
次に右側のファインチューニングを行います。ファインチューニング用の学習データでどら焼きが、「グルメ」もしくは「レシピ・料理」のカテゴリであることをモデルに教えます。事前学習で、マリトッツォとどら焼きが同じようなものと学習していることから、マリトッツォを正しく「グルメ」や「レシピ・料理」に分類できます。
つまり、マリトッツォのような新語や専門用語は、Webの検索ログから人の手で正解を作ることなく学習できます。そしてファインチューニングでは、コアとなる語、ここではどら焼きのカテゴリを人の手で教えるだけでよいということになります。
このように、BERTの2段階の学習の枠組みを使って、新語に対応できています。
システムの評価
システムの評価を行いました。カテゴリ数は約50個で、人名や組織名、グルメなどが含まれています。システムの出力と正解がどれぐらい一致するかの指標の一つであるMicro F1で評価すると75.5になりました。
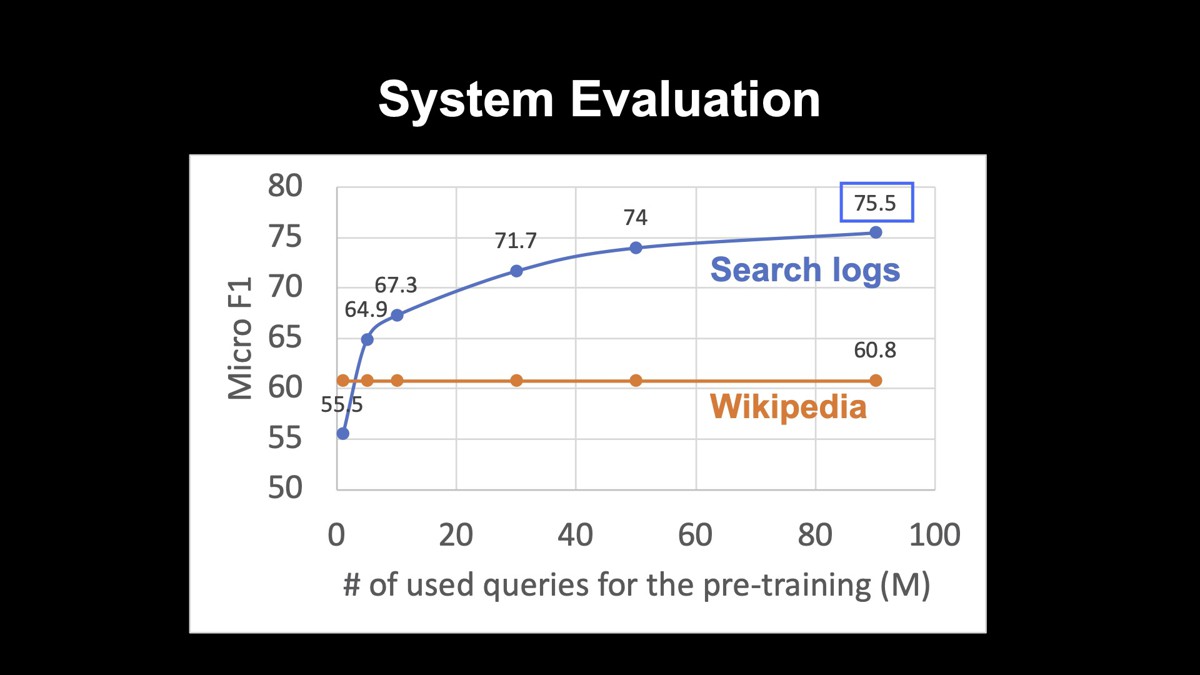
また、このグラフは、事前学習に用いたテキストを変えた場合の精度を表しています。事前学習に用いたテキストとして、一般的なWikipediaと、青字で示している検索クエリのログを使っています。縦軸にはMicro F1を採っています。
Wikipediaを用いるよりも検索クエリのログである青線の方が、精度が高くなっていることが分かります。また検索クエリの数を増やせば増やすほど精度が高くなっており、データが大きければ大きいほど良いということがはっきりと表れています。
下図はシステム出力の例です。左のクエリとそれに対応するシステム出力を右に表しています。マルチラベル分類ですので、システムの出力は複数のカテゴリからなっています。カッコ内の数字は確信度を表しており、0から1までの値をとって、1に近いほどシステムの確信度が高いことを表しています。ここにある通り、新語であっても正しく分類されていて、BERTが非常に強力なことが分かります。

例えば一番上の「オッドタクシー」の場合、このタクシーという文字列に引っ張られることなく、正しくタイトル名や映画に分類することができています。
また一番下の三つは「ワンピース」という曖昧性の非常に高いクエリの代表例ですが、正しく分類することができています。例えば「ワンピース ネタバレ」だと、正しく「タイトル名」や「マンガ・アニメ」、次の「ワンピース レディース」だと、「ファッション」や「製品・商品」に正しく分類されています。
この二つであれば一昔前のモデルでも正しく分類できるかもしれません。しかし、「ワンピース 1015」の1015は、「1015話」を表していますが、このように数字だけ書かれていても、「マンガ・アニメ」や「タイトル名」に正しく分類されており、BERTが非常に強力であることが分かります。
このように大規模にクエリを解析し、その解析結果をデータベースに登録することによって、社内の誰もが簡単にカテゴリの分類結果を使えるようにしています。
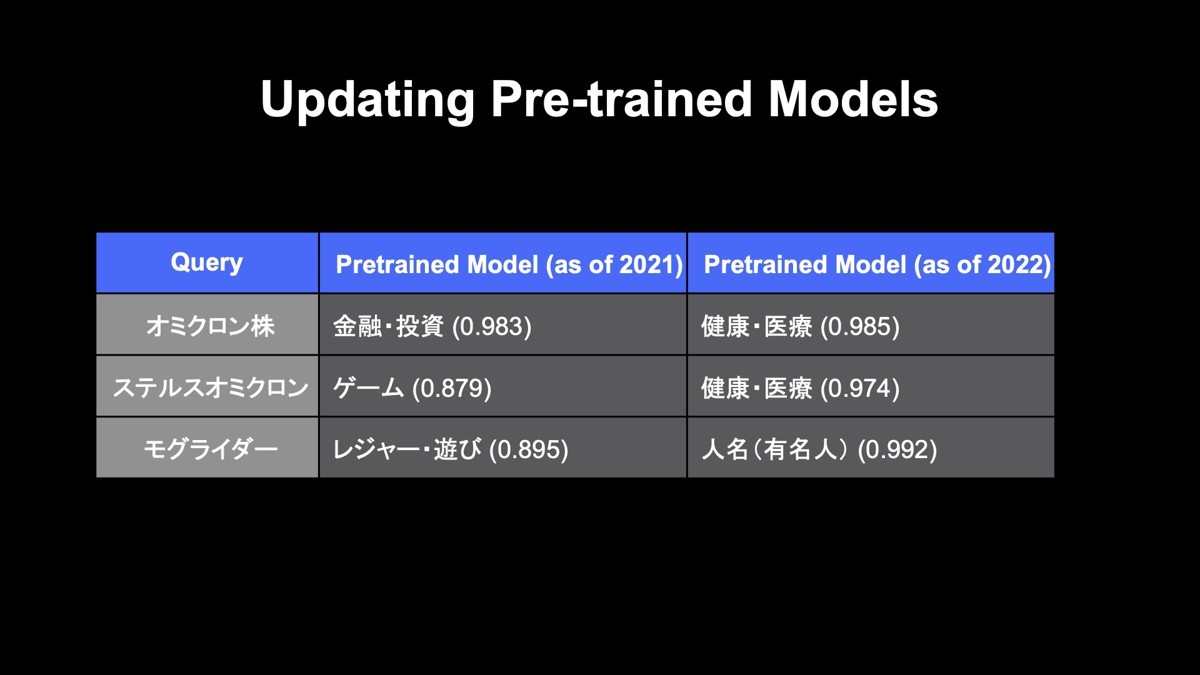
こちらは2021年に学習した事前学習のモデルの結果と2022年に学習した事前学習モデルの結果を示しています。2021年のモデルだと、「オミクロン株」は「株」に引っ張られて誤って「金融・投資」と分類されていました。しかし、2022年の検索クエリのログを使うことによって、正しく「健康・医療」に分類することができています。
その下の「ステルスオミクロン」も同様に、正しく「健康・医療」に分類することができています。また、一番下の「モグライダー」のように、最近の漫才師さんも正しく人名・有名人に分類することができています。このように、人の手でファインチューニングのデータを更新せずに新語への対応ができています。
今後は、例えば1カ月おきにモデルを定常的に更新するようなワークフローを作っていきたいと思っています。
今後の展望
最後に今後の展望です。現在は主にBERTによるカテゴリ分類を扱っていますが、トークンレベルの分類、主には固有表現解析を行えるようにすることや、BERT以外のモデル、例えばエンコーダ・デコーダモデルのような生成モデルや文ベクトル学習するタスクも同じように学習データを与えるだけで動くようにする予定です。
現在はTensorFlow 2の公式スクリプトをベースにしていますが、広く用いられているHuggingface Transformersもバックボーンとして使えるようにしたいと思っています。また、Web上でモデルの学習を行えるようなインターフェースを提供し、エンジニアではない方でも、AutoFMを使えるようにしたいです。こうすることで、もっといろいろな場所で使ってもらえることを期待しています。
AutoFMは、各プロジェクトの要望を聞きながら今後も機能拡張を行っていきます。
アーカイブ動画
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 柴田 知秀
- Yahoo! JAPAN研究所 上席研究員
- 自然言語処理に関する研究開発をしています。
-



