突然ですが、みなさんへ質問です。「今この瞬間にシステム障害が起こったら、自信を持って対処できますか?」システム運用者であれば、誰しもが考えたことがある内容かと思います。障害の影響範囲がどの程度なのか、ユーザーアナウンスの必要の有無、そして自動復旧のメカニズムが正しく動いたか。そのあたりが気になるポイントなのではないでしょうか。単純な質問ではありますが、とても考えることが多い不安な質問です。
システムは動いて当たり前と思われがちですが、実際は動いている方が奇跡、壊れて当たり前、という点はエンジニアのみなさんなら共感していただけると思います。どうやったら障害にアプローチできるか、ヤフーで取り組んでいるカオスエンジニアリングについて紹介します。
カオスエンジニアリング導入の理由
ヤフーでは、さまざまなシステムが稼働しております。そして現在、全社を挙げてシステム刷新を進めています。その中で、システムのモダナイゼーション、マイクロサービス化、冗長化のためのマルチリージョン・マルチAZ(MRMAZ)などを進めています。また、ヤフーではデータセンターを持っているので、プラットフォームやハードウェアを含めた冗長化や多重化を進めています。
この前提にあるのが、「障害はどうしても起きてしまう」という事実です。障害が起きても影響をなくす、または限りなく少なくするというシステム改善を行っています。
プロダクション環境が改善され、システムを日々変化させやすくなるということは、その結果としてシステムが複雑化し、人間が全ての動きを追い切れなくなりがちです。「障害の影響範囲が分かりにくい」、「オートヒーリングされると思ったのにされなかった」といった社内からの声もあがってきます。こうしたものは、障害が実際に起きるまで気づきにくいという課題があります。開発者や運用者の認識と実際のシステムの動作にギャップが存在するということです。このような状況に対して、しかるべき対策を行う必要がありました。
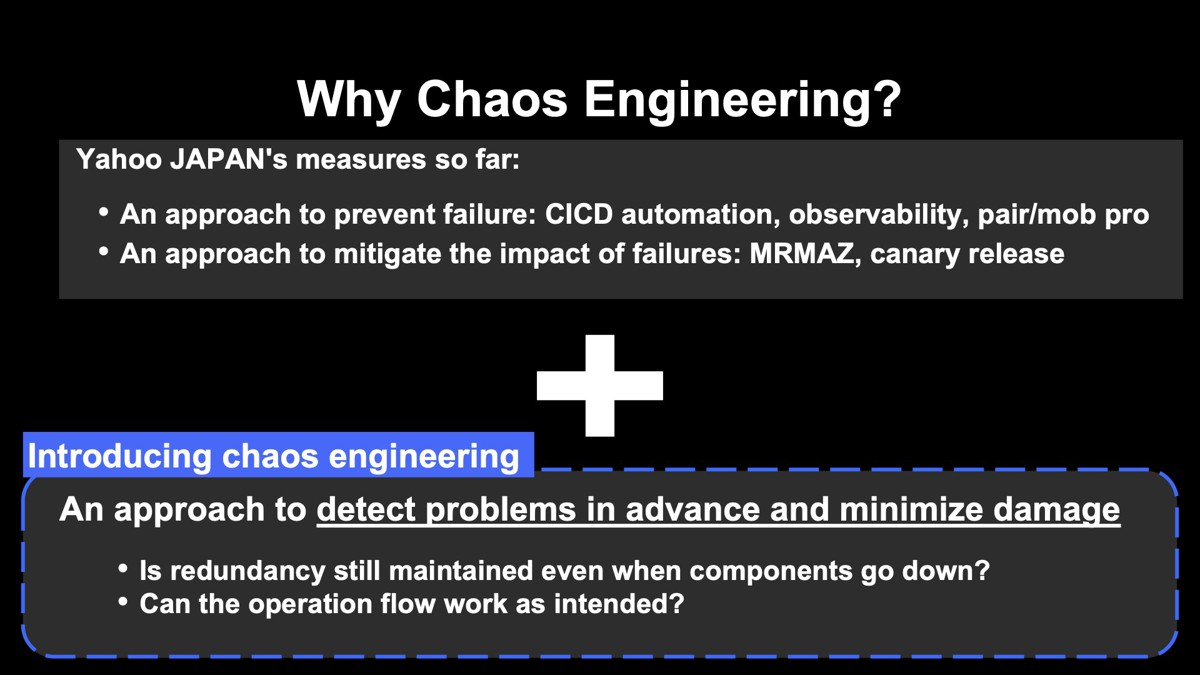
ヤフーでも、これまでにさまざまな対策を進めてきました。障害を防止するためのアプローチとしてはCI/CDに代表される自動化、オブザーバビリティの向上などがあります。また障害を緩和させるためのアプローチにはMRMAZでサービスの障害範囲を極小化するなどがあります。
これらに加えて、問題を事前に発見して被害を最小限に抑えるというアプローチを行っています。例えばあるコンポーネントがダウンしても、プロダクションシステム全体としてはサービス継続できるよう担保しておく。または障害が起きたときに意図したオペレーションができるかを事前に確認していくということです。このアプローチがまさにカオスエンジニアリング導入の理由です。
カオスエンジニアリングは定義が明文化されています。
カオスエンジニアリングは、システムが本番環境における不安定な状態に耐える能力へ自信を持つためにシステム上で実験を行う訓練方法です。
私はこれを「分散システムに対して、プロアクティブなアプローチを取りましょう」という風に解釈しています。
二つのフェーズで進めるカオスエンジニアリング
では具体的に、どうアプローチしていけばいいでしょうか。手順を図にしてみると、次の図に示すサイクルのように表現できます。こちらの図を大きく分けると、前半の準備フェーズと後半の実行フェーズがあります。
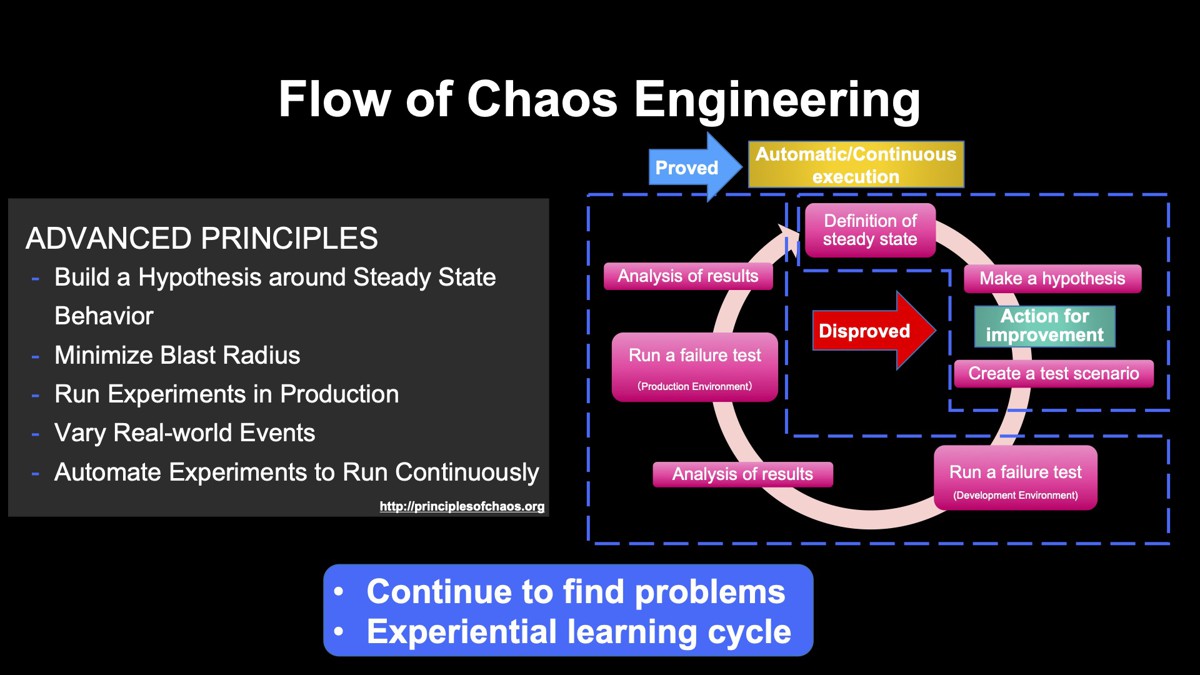
前半の準備フェーズは、まず定常状態を定義してテストシナリオを作ります。何かの障害が起きることを想定して、その時システムがどう動くかをドキュメントに書き出します。
後半のフェーズは実行フェーズです。先ほど作成したシナリオに基づいてプロダクション環境でシナリオを実行します。障害範囲をなるべく小さい範囲にして始めることが推奨されています。小規模な障害だと思っても、影響範囲が予想以上だったということも起こりえます。これは深刻な障害につながりかねないので注意が必要です。
テストシナリオの実施結果を見て、もし仮説が間違っていれば、改善を加えていきます。ここでいう改善とは対象システムの改善だけではなく、SLAの値やアラートのしきい値を適正化することも含みます。つまり、システムの状態と開発者や運用者の認識のギャップをこの時点で埋めていきます。
仮説が正しかったとしてもそれで良いと安心するのではなく、さらにシナリオの自動化や継続化を進めていきます。システムは日常的に変更されるので、またいつ認識のギャップが生まれるかは分かりません。そこでカオスエンジニアリングを継続することで、システムが常に意図通り動いているかを担保できます。カオスエンジニアリングとは、問題を発見し続ける、経験学習サイクルを回すこととも言えます。
カオスエンジニアリングと聞くと「ランダムなもの」、「無計画なもの」と想像される方もいますが、実際は真正面から改善に取り組む計画的なサイクルです。ここがカオスエンジニアリングの本質です。
カオスエンジニアリングの実践
ヤフーで実際に行った内容を、前半と後半のフェーズに分けて紹介していきます。
前半:準備フェーズ
準備フェーズでは「システムの障害が起きても、システムの定常状態は変わらない」という仮説を作ります。このシナリオに従って、後半の実行フェーズはこの仮説が正しいかを確認します。
作成した仮説のシナリオが下図です。大きく分けて前半と後半があり、前半部分ではさまざまな障害を想定して、何がどう壊れるかを全て書き出しておきます。

後半は、障害の結果としてSLIがどう変化するか、アラートが何分で飛ぶか、何分で自動復旧するか、もしくはしないのかをまとめて書きます。このように具体的な障害を書き出すことが「シナリオを作る」ということです。
シナリオを作るにあたってのポイントをいくつか紹介します。1点目として、実はこのシナリオ作るだけでも、システム安定性向上につながることがあるということ。このシナリオを作ることでSLIや監視状況を把握でき、現状のシステムのどの部分に穴があるか分かることがあります。
2点目として、障害によっては「結果がよく分からない。不明」という項目も出てくると思いますが、そのときは仮説で良いのでいったん書いておくことが重要です。例えば、復旧までの平均時間はすぐに数字を思いつかないかもしれません。しかし後半の実行フェーズになれば、実際の数値が出てきます。そこでシステム改善につなげていけば大丈夫です。
3点目は初めて準備するときの注意点です。シナリオをたくさん作るとか中身のブラッシュアップに注力してしまいがちですが、その必要はありません。まずはシステムで起こりそうなことをいくつか抜き出して、カオスエンジニアリングのサイクルに乗せていくことが重要です。
後半:実行フェーズ
このフェーズでは作成した仮説シナリオに基づき、実際の本番環境でテストを実施して、仮説が正しいかどうかを確認します。
安定性を向上させたいのは本番環境なので、当然ながら本番環境で実行します。ただ、最初は本番環境で障害を起こすことに対して不安を抱くかもしれません。私も開発・運用経験が長いので、この気持ちはよく理解できます。
しかし、一度でも開発・運用を経験されている方なら、「開発環境で起きなかったことが、なぜか本番環境で起こる」という不都合な真実を知っていると思います。このことについて、一歩踏み込んで考えてみましょう。
本番環境を改善するタイミングは2通りあると考えています。一つは、意図しない大きな障害が起きた後に改善する。もしくは小さな障害を意図的に起こして、日々改善を積み重ねる。このうち後者がまさにカオスエンジニアリングの考え方です。
実際のビジネスインパクトを考えると、後者が選ばれるでしょう。また、開発のベロシティが大きいシステム、つまりマイクロサービスや分散システムを利用しているなら、前者のようなウォーターフォール型の改善手法は原理的には選びにくいかと思います。そして何よりもエンジニアとしては、障害後に対応するよりも平常時に気持ちよく改善をしていきたいですよね。
もちろん、本番を落とすのはリスクがありますので、ここからはカオスエンジニアリングを進めるにあたっての工夫を紹介します。

まずはユーザー影響のない環境で試して、復旧手順をまとめましょう。始める場合は「小さな障害範囲から」が推奨されています。最初はAPIを1個だけ落として、大丈夫そうなら少しずつ増やしていきます。Podを落としたり、VMを落としたり、一番大きな範囲だとAZごと落とすなどです。
これらに加えて、ヤフーでは独自の工夫も行いました。実際の問題として、すでに稼働しているシステムに対して、カオスエンジニアリングを導入することは非常に難しい状況にありました。そもそもカオスエンジニアリングの文化が弊社にはなかったというのもあります。そのため、ヤフーではこれから新たにリリースするプラットフォームをターゲットに絞りました。
ターゲットにしたのはCaaS(Container as a Service)のプラットフォームです。導入するにあたり、社内にはメリットをアピールしていきました。一つは、プラットフォーム自体が安定するだけではなく、「このプラットフォームを利用するユーザー(社内の開発者や運用者)にとっても安定したプラットフォームが使える」という宣伝になること。そのほかにも、定期的にカオスエンジニアリングを実施してそれがデフォルトになると、プラットフォーム上のアプリに冗長化対策が実施され、結果的にアプリの堅ろう性につなげられる、という良さをアピールして導入にいたりました。
なお、当時はこのプラットフォームのリリーススケジュールがすごくギリギリで、カオスエンジニアリングを導入すると、リリースが間に合わないという状況でした。しかし、CaaSプラットフォームの開発者たちはカオスエンジニアリングのメリットをちゃんと理解してくれていたので、リリースを少し遅らせてでもカオスエンジニアリングを導入してくれた。そんな裏話もあります。このような流れで、実際の本番環境での実施に至りました。
カオスエンジニアリングのシナリオ例1
実際にプロダクション環境で実施したシナリオを紹介します。今回紹介するシナリオは二つ。一つ目のシナリオはCaaSのハイパーバイザーダウン、ワーカーノードダウンの事例です。
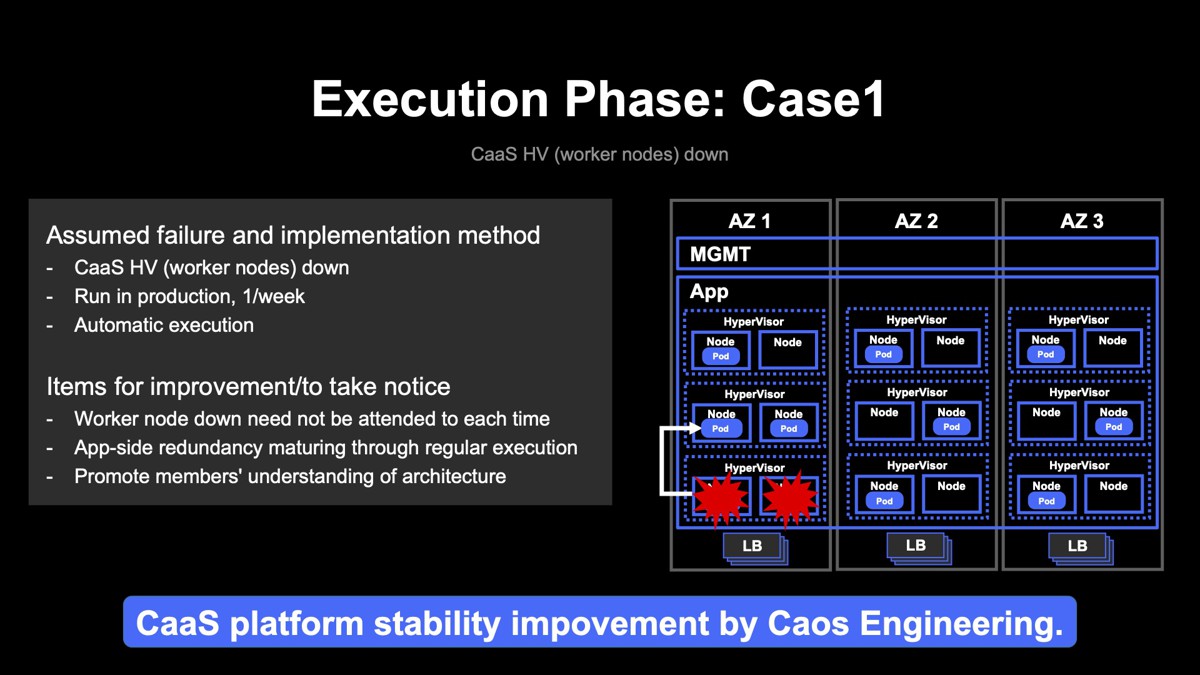
CaaSの中身はKubernetesなのですが、同一ハイパーバイザー上のワーカーノードを落とすというシナリオです。上図の右側が実際のインフラ構成です。各AZにハイパーバイザーがあり、その上でVMが動いています。このVMがワーカーノードです。同一ハイパーバイザー上のワーカーノードが落ちるということですが、落ちたとしても、Podは生きているノードから復活するというシナリオです。これをプロダクション環境で週に1回、自動的に行っています。
カオスエンジニアリング実施後には次のような改善と気づきがありました。1点目はワーカーノードがダウンしても、都度対応する必要がないということ。この程度の障害でわざわざ人間が対応する必要は全くないことが担保できるようになりました。
2点目は実際のプロダクション環境で継続して実施しているので、ここで稼働しているアプリケーションも冗長化しておく必要があるということです。こうしてアプリケーションの対策を行い、結果的に安定性向上につながりました。
3点目は自動化に関連したものです。カオスエンジニアリングのプロセスは自動化されていますが、アラートは人が受け取って、人がアラートや各種メトリクスを目視で確認するプロセスとなっています。これを行うことで、特に年次の浅い方は複雑なアーキテクチャの理解につながることが分かりました。
これらの結果、CaaSプラットフォームは意図した通りに動いていることが担保できて、システムの安定性向上につなげることができました。
カオスエンジニアリングのシナリオ例2
二つ目のシナリオはAZダウンです。名前の通りAZごと落ちる、VM、ハイパーバイザー、ロードバランサー、まるごと影響を受けるので大きな障害を想定しています。

CaaSプラットフォームでは、ヤフーのさまざまなサービスやシステムが実際に動いているので、かなり注意して進めていく必要があります。カオスエンジニアリングでは、このような大規模シナリオ実行を「GameDay」と呼んでいます。
2021年6月から、およそ半年に1回はGameDayと称して、関係者(CaaSプラットフォーム担当、仮想化基盤インフラ担当、カオスのプロジェクトメンバー)が全員集まり、大規模シナリオを実施しております。
なお、AZごと落とす方法はいろいろありますが、ここではAZ内の全てのIPアドレスのBGP広報を止めてIPのリーチャビリティをなくすという方法を実践しました。実際にシナリオを実践したときのPodのメトリクスが下図です。
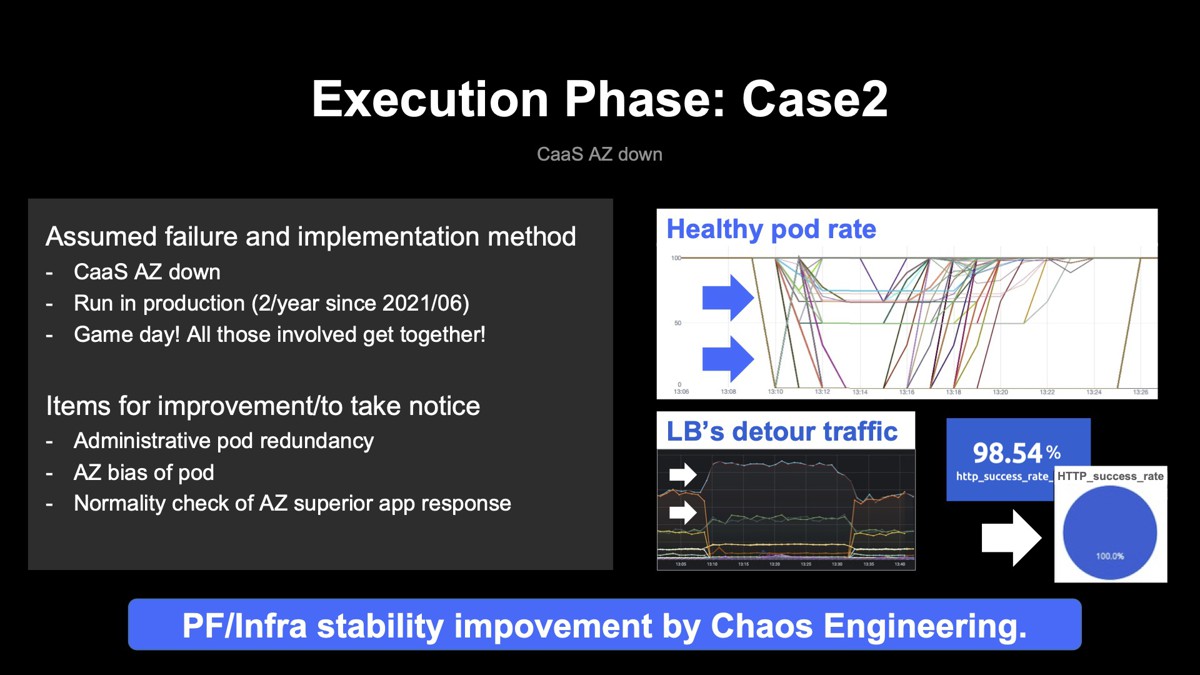
右上のグラフからAZが落ちた影響は受けつつも全てが落ちるわけではないので、CaaSは動作し続けて、サービス提供は継続していることが読み取れると思います。また、各AZのロードバランサーのトラフィックを見ると、落としたAZのトラフィックはもちろんゼロに落ちますが、その分は迂回して他のAZのロードバランサーが処理する様子もグラフから読み取れます。
最も直接的なメトリクスとなる、プラットフォームで動くアプリケーションのHTTPレスポンスを見ると、リクエスト換算で大体98%以上が成功していることが確認できました。
シナリオ実施後の改善と気づきは、1点目として管理系Podの冗長化で不備が見つかりましたが、こちらは設定の修正で改善できました。2点目はAZダウン後に戻した後に、Podが各AZに偏ってしまうということが起きました。これは発見しにくく、2回目か3回目でこの現象を発見しています。こちらは実装面と運用面の両方を修正して対応しました。
3点目は気づきです。このような大規模な障害でも、Pod上のアプリケーションは健全な状態であることが確認できました。インフラレイヤーの中だけを見るだけならやりやすいのですが、その上で動いているものの健全性までチェックするのは難しいものですが、今回はそれらも含めて全て確認できました。
こうした修正作業を継続しながら、不備がないことを確認していきました。実際カオスエンジニアリング実施後はアプリのリクエストで100%を維持できていることが確認できています。このような結果から、カオスエンジニアリングによって、CaaSプラットフォームだけではなく、その下のインフラも含めたヤフー全体のシステムの安定性向上が実現し、しかも継続的にそれを担保できたと言えるようになりました。
ヤフー全体のシステム安定性向上も狙う
今後の展望について紹介します。ヤフーではサービスを提供するアプリケーションのほか、それらを支えるプラットフォーム、物理インフラも開発・運用しています。今回紹介したカオスエンジニアリングの実践は、主にレイヤーの低い部分(プラットフォームやインフラ)にフォーカスして進めてきました。今後はプラットフォームやインフラのシナリオを拡充したり、よくある障害対応をテンプレート化して他のプラットフォームへの横展開を進めたりしたいと考えています。
もちろん、それだけでは全ての障害を100%防止はできません。今後はサービス側でも、障害が起きることを前提としたアプリケーションのデザインや、アプリケーション側でのカオスエンジニアリングの活用を進めていくことを見据えています。誰か1人で行うのではなくて、ヤフー全体としてシステム安定性の向上を進めていきたいと考えています。
最後に、全体のまとめです。はじめに、なぜヤフーがカオスエンジニアリングを行っているのかを紹介しました。システムは日々変化し、実際に問題が起きるまで気づきにくいという課題があり、さらに開発者や運用者の認識と実際のシステムにギャップがあるため、カオスエンジニアリングを導入したということをお伝えしてきました。
こうしたカオスエンジニアリングを実践した結果、プロダクション環境で実行することによってミスの発見などの気づきも多く得られて、改善につながりました。加えて、それを継続することで不備がないこと、意図した通りに動いていることを担保することができ、結果的に安定性向上を実現できています。
冒頭で「今この瞬間にシステム障害が起こったら、自信を持って対処できますか?」という質問をしました。いま、カオスエンジニアリングの話を聞いた後なら、「対処できる」と思えてくるのではないでしょうか。カオスエンジニアリングを実践していれば、例えば「その障害なら、この前カオスエンジニアリングで確認したからサービス影響は全然ない」と自信を持って答えられるようになるかもしれません。
システムの安定性をさらに向上させたいと思っている方は、ぜひカオスエンジニアリングに取り組んでみることをおすすめします。
アーカイブ動画
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 立見 祐介
- エンジニア
- 最近は物理インフラ、VM (IaaS)、Container (CaaS)など相互安定運用を目指し、カオスエンジニアリングプロジェクトを進めています。
-



