こんにちは。Yahoo! JAPAN研究所の鍜治です。
みなさんはコンテンツにメタデータを付与したいとき、どのようにしていますか? もちろん手作業で付与することもできますが、コンテンツ量が膨大なときには、自動的にメタデータを付与できる仕組みがあると便利だと思いませんか?
私がリーダーを務めている研究開発チームでは、Yahoo!ショッピングの商品に属性というメタデータを自動付与するため、BERTを用いた商品属性推定モデルを開発しています。本記事では、そもそも商品の属性とはどういうものなのか、どのようにBERTを使っているのか、既存モデルと精度はどのくらい違うのか、などについてお話したいと思いますので、よろしくお願いします。
Yahoo!ショッピング検索を使いやすくする商品属性
まず予備知識として、商品の「属性」についての説明から始めたいと思います。Yahoo!ショッピングに出品されている商品には、検索を補助することを目的とした属性というメタデータが付与されています。例えば、ビールカテゴリーの商品には「容量」「本数」「ビールの種類」などのメタデータが、オフィスチェアカテゴリーの商品には「色」「肘掛けタイプ」「素材」などのメタデータが付与されています(下図)。
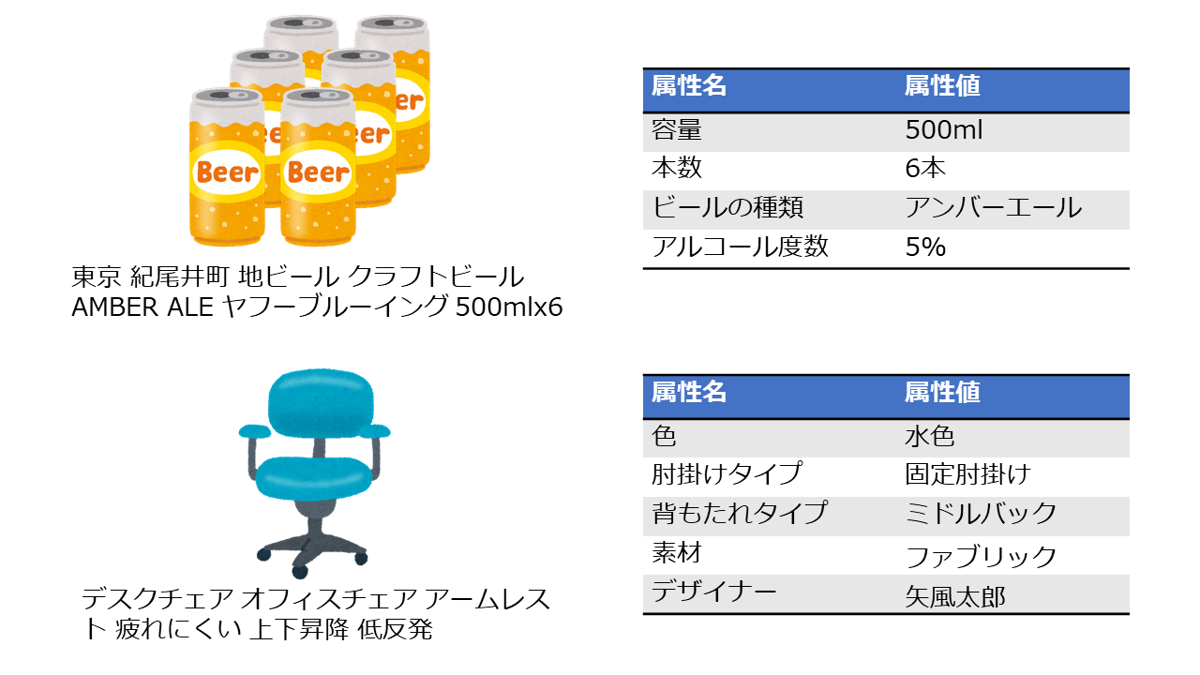
このように商品の特徴を記述したキーバリュー形式のメタデータのことを属性と呼びます。また「容量」や「色」などのキーのことを属性名、「500ml」や「水色」などのバリューのことを属性値と呼びます。
商品の属性を利用すれば、例えば「500ml缶のアンバーエールが欲しい」や「アジャスタブルな肘掛けがついている椅子を調べたい」といった、きめ細かい検索ニーズに対応することが可能になります。
機械学習を用いて属性の付け忘れに対応
しかし、Yahoo!ショッピングには何億点もの商品が出品されているので、その全てに属性を付与するのは簡単なことではありません。属性はその商品を出品するストアさんが手作業で付与してくださっているのですが、どうしても付け忘れが発生してしまいます。
この問題を解決するため、Yahoo!ショッピングでは商品のタイトルテキストからその属性を推定する機械学習モデルを開発し、ストアさんが属性を付け忘れた商品に対して、属性を自動的に付与しています。この処理のことを本記事では商品属性推定と呼んでいます。機械学習モデルとしてはロジスティック回帰を採用しています。また、学習に必要なラベル付きデータは、ストアさんが付与してくださった属性を正解ラベルとみなし、Yahoo!ショッピングの商品データベースから自動生成した大規模なものを利用しています。
BERTを用いた商品属性推定モデルの学習
ここからが本記事のメインパートです。商品属性推定モデルを、近年自然言語処理のさまざまなタスクで最高性能を達成しているBERTを使って学習する方法を説明していきます。
商品属性推定タスク
技術的な話に入る前に、商品属性推定というタスクについて、もう少し詳しく説明をしておきます。本記事で言う商品属性推定とは、次のような流れに従って、ストアさんが付け忘れた属性を自動付与するタスクのことです。
- 推定対象となる商品(= 属性を付け忘れた商品)のカテゴリー情報から、そのカテゴリーの商品が取りうる属性名のリストを取得します。例えば、ビールカテゴリーの商品であれば、容量や本数といった属性名が得られます。カテゴリー情報も、属性と同様にストアさんが手作業で付与してくださっているメタデータなので、付け忘れられている場合があります。しかし、属性に比べると付け忘れの割合は無視できるくらいに低いので、ここではカテゴリーが付け忘れられている商品は属性推定対象から外します。
- 各属性名に対して、それが取りうる属性値の候補を取得します。例えば、「ビールの種類」という属性名には、IPA、アンバーエール、スタウトなどが属性値の候補となります。
- 各属性名に対して、属性値候補の中から適切な属性値を選択します。
先頭2つのステップは単純なデータベースの検索によって実現可能なので、本記事では特に詳しく説明しません。例えばステップ1であれば、カテゴリーと属性名の対応関係を登録したデータベースが社内に整備されているので、それを検索しています。ステップ2も同様です。
ロジスティック回帰やBERTといった機械学習モデルが必要になるのは最後のステップ3です。ここでの処理は、与えられた候補の中から適切なものを選択する分類問題として定式化できます。そこで、商品テキストを入力として、適切な属性値を出力する分類モデルを学習します。このとき、分類モデルは属性名の数だけ必要になることに注意してください。
以下では、そのような分類モデルをBERTを使って学習する方法を説明し、その精度をロジスティック回帰と比較した実験の結果を報告します。
事前学習
まずはじめにBERTの事前学習を行います。事前学習のデータには、Yahoo!ショッピングの検索クエリと商品タイトルの2種類を試しました。いずれの場合も、文字列をsentencepieceでサブワード列に変換し、その先頭にCLSトークンという特殊トークンを連結したものを入力とします。そして、マスク言語モデル(Masked Language Model)を学習することによって事前学習を行います。なお、商品タイトルを使って事前学習を行う場合、属性が付与されているものも付与されていないものも、全て事前学習に利用できることに注意してください。
BERTの元論文では、マスク言語モデルに加えて次文予測(Next Sentence Prediction)モデルを学習することも提案されていますが、ここでは採用していません。次文予測は効果が小さいことが後続研究で報告されているのがその理由ですが、商品タイトルについては、そもそも次文を定義することが難しいという事情もあります。
ファインチューニング
次に、事前学習済みBERTをファインチューニングすることによって、商品タイトルから属性値を予測する分類モデルを学習します。まず、商品タイトルに事前学習と同じ前処理を施したものをBERTに入力し、その出力からCLSトークンの埋め込みを取り出します。そして、それに線形変換を適用したものが分類スコア(ロジット)となるように学習を行います。学習に必要なラベル付きデータは前述のように商品データベースから自動生成します。
このとき単純に学習を行うと、1,000以上ある属性名ごとに別々のモデルを学習することになり、大量のメモリが必要になってしまいます。そこで、最後の線形層以外のパラメータを全てのモデルで共有することによって、メモリ使用量を削減するという工夫を行っています。
評価実験
BERTを用いることによって商品属性推定の精度がどのくらい改善するのかを調査するために評価実験を行いました。この実験では、Yahoo!ショッピングの商品データベースから自動生成したラベル付きデータを学習用と評価用に分けて、評価用データ上での適合率と再現率を最終的な評価値としました。なお、ここでの適合率と再現率は全ての属性値に対するマイクロ平均です。
実験の結果は下表のようになりました。比較のため、現在Yahoo!ショッピングで稼働中のロジスティック回帰モデルの結果を表の1行目に記載しています。また、モデルを変更した効果と、事前学習を行った効果を切り分けて分析するため、事前学習を行わずにファインチューニングだけを行ったBERTの結果を2行目に記載しています(事前学習を行わないものをBERTと呼んでよいのか議論があるかもしれませんが、ここでは便宜上それもBERTと呼びます)。最後に、検索クエリと商品タイトルで事前学習を行ったBERTをファインチューニングした結果を、それぞれ3行目と4行目に記載しています。
| 適合率 | 再現率 | |
|---|---|---|
| ロジスティック回帰 | 86.2% | 66.0% |
| BERT(事前学習なし) | 97.2% | 92.3% |
| BERT(検索クエリ) | 97.4% | 93.6% |
| BERT(商品タイトル) | 97.4% | 93.7% |
この表を見ると、3種類のBERTはいずれもロジスティック回帰を大きく上回る性能を達成していることが確認できます。とりわけ、再現率において顕著な改善が見られます。
また、この改善の大半は、事前学習ではなくモデルの変更によるものであることも分かります。事前学習を行っていないBERTでも、すでにロジスティック回帰よりも適合率が10ポイント、再現率が26.3ポイント改善しています。ここからさらに事前学習を行うと、検索クエリと商品タイトルのどちらを使った場合でも再現率がさらに向上していますが、その改善幅は1ポイント強に留まっています(適合率はほぼ変わりません)。商品属性推定のように大規模学習データが入手できるタスクでは、まずはモデルの表現力を高めることが重要であり、事前学習の有効性は相対的に小さくなるため、このような結果になったと考えられます。ただし、事前学習を実施することによって再現率が堅実に改善していることから、事前学習に一定の効果があると言うことはできそうです。
検索クエリと商品タイトルで事前学習を行ったBERTを比較すると、それらの精度に大きな違いがないことも分かります。これは意外な結果でしたが、検索クエリと商品タイトルはある程度似通ったテキストデータであるため、そこまで差が出なかったのだと考えられます。ただし、データの抽出条件や前処理などの影響を受けている可能性もあるので、今後さらに細かな調査を行っていく予定です。
BERTが推定した属性の例
最後に、ストアさんが属性を付け忘れた商品に対して、BERTが実際に推定した属性の例をご紹介します(下表)。なお、BERTは商品タイトルで事前学習を行ったものを用いました。この表から、商品タイトルという言語情報を手がかりとして、BERTが属性値を正しく推定できていることが確認できます。なかでも興味深いのは、3行目と4行目のように、商品タイトルに属性値が直接記載されていない場合でも正しい属性値を推定できている事例です。これらの推定結果は、「ウルフ」や「狼」という単語が「動物」を表しているという知識や、「MONE ECLOGO」という製品は金属製であるという知識を、BERTが学習していることを示唆しています。特に後者は人間でも正解することが難しく、大規模データから学習する機械学習モデルの利点が発揮されている事例と言えます。
| 商品タイトル | 属性名 | 属性値 |
|---|---|---|
| L/古着 ポロ シャツ ラルフローレン RALPH LAUREN ロゴ 鹿の子 紫 パープル 19jun13 中古 メンズ 半袖 トップス | 袖タイプ | 半袖 |
| GILIO ワークシューズ ブルー 26.0cm 6408 | 色 | ブルー |
| シルバーリング ウルフ 狼 ロイヤルブルームーンストーン 6月誕生石 メンズ 指輪 シルバー | モチーフ | 動物 |
| ポールスミス マネークリップ Paul Smith ブランド ブランドアイテム MONE ECLOGO | 素材 | 金属 |
おわりに
これまでの実験の結果、BERTを用いることによって商品属性推定の精度が大幅に改善することを確認することができました。この後はA/Bテストを実施して実サービスにおける効果を検証する予定です。リリースまで後一息という状況になっていますが、気を緩めることなく、引き続き研究開発を推進していきたいと思います。
BERTの導入によってモデルの精度は大きく改善しましたが、まだまだ改善の余地は残されていると考えています。例えば、現在のモデルは商品タイトルという言語情報しか利用していないので、商品画像など他のモダリティ情報も活用することができれば、さらなる精度の向上が期待できます。また、BERTに限らず機械学習モデル全般に言えることですが、学習データ中の出現頻度が小さい属性名はどうしても精度が低くなる傾向にあるため、この問題を緩和するための工夫(Zero-/Few-shot Learningの知見を取り込むなど)も必要であると考えています。これ以外にもさまざまな課題がありますが、さらなる改善に向けて、これからも技術的な挑戦を続けていきたいと思います。
最後になりますが、この記事を通して、読者のみなさんがヤフーのサービスや技術に少しでも興味を持ってくだされば、大変うれしく思います。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 鍜治 伸裕
- 上席研究員
- 本業はYahoo! JAPAN研究所の研究員ですが、最近はサイエンス統括本部で研究開発チームのリーダーも兼務しています。先日、Corporate Blogにもインタビュー記事(下のリンク)が出ました。
-



