こんにちは。システム統括本部でソフトウェアエンジニアをしている鈴木です。ヤフー全社で利用されているユーザコンテンツ判定プラットフォーム(以下UGC判定PF)のプロダクトオーナー兼テックリードをしていました。
本記事では2021年4月から実施した機械学習モデル作成の効率化の取り組みを紹介します。以前はAPIとして提供するまで6週間かかっていたものが、最終的に学習データさえあれば1日(実質数時間)で個別チューニングされたモデルが作成され、ボタンクリックでAPIとして利用可能になるところまできました。
UGC判定PFの紹介
UGC判定PFの概要
UGC判定PFはNGワードやURLなどの登録データや、事前に作成された機械学習モデルによりユーザ投稿を判定するためのプラットフォームです。データの登録や機械学習モデルを作成運用するためのツールはUIとして提供し、判定処理にはAPIを提供しています。現状ではNGワードを利用して判定しているサービスがほとんどで、最大で3,000RPSぐらいの処理を行っています。
NGワードの登録は確実に特定の投稿をブロックすることが可能ですが、一方でいたちごっこになりやすいのが難点です。PF利用者である各種ヤフーサービス側の担当者にとっては、常にNGワードのメンテナンスが必要になり、かなり負担になります。また明確なNGワードを利用しなくてもコンテキストを駆使して悪意のある投稿は可能ですが、そのような投稿に対してNGワードによるブロックはおおむね無力です。こういった欠点を補完するため機械学習モデルによる判定機能を提供しています。
(※モデル作成にあたり、ヤフーではお客様のプライバシーの保護に細心の注意を払っています。詳しくはYahoo! JAPAN プライバシーセンターをご覧ください。)
UGC判定PFの利用者と機械学習モデル判定の利用例
UGC判定PFを利用しているのは、ユーザがコメント投稿できるような機能を持つサービスの担当者や、カスタマーサポート(以降はCSと記載します)の方などです。サービスへの組み込み例としては、ヤフオク!で不正な投稿を検出するモデルを開発し、利用者の通報を97%削減できたという実績を上げています。
パトロール業務への組み込み例では、ヤフーニュースや知恵袋のユーザ投稿の判定や、オークションの違反出品の判定に利用されています。モデル判定を利用する前に比べてニュースコメントのパトロール業務効率が4倍になったり、知恵袋では過去の膨大な質問回答についても、機械学習で不適切な投稿の検出と削除に取り組めるようになりました。
機械学習判定が利用可能になることで、業務の効率が改善され、これまでリソース不足で対応を諦めていた部分にも取り組めるようになったようです。サービスやシステムに機械学習モデルの判定を直接組み込む場合に比べて、CSのパトロール業務では判定スコアをフィルタ用途に利用し、最終的に人が判断するフローになっているので、比較的安全にモデルを利用できるというのも導入がしやすかった理由の一つかなと思います。
機械学習モデルの開発における課題
今回の取り組みの前はモデルを開発するのに3週間、判定APIとして利用可能にできるまでさらに3週間程度の時間がかかり、モデル開発は属人化し、情報の管理はばらばらで、モデル構築を別のメンバーが再現するのも難しい状況でした。
そこで、ヤフーのAIプラットフォーム(以下AIPF)を活用したMLOpsの導入、MLOpsに最適化したモデル開発フローの刷新、BERTの導入、一連の処理をパイプライン化したモデル作成自動化ツールの開発などさまざまな施策を実施し、1年程度かけて段階的に効率を改善してきました。
課題が生まれた背景
機械学習モデルの作成代行を開始したのは2020年の4月からです。それまでも簡単な機械学習モデル作成支援システムを提供していましたが、ほとんど利用されていない状態でした。NGワードによる判定は登録したワードで確実に検出できる明快さがありますが、機械学習モデルを作成してどのような効果・成果が得られるかわからないため、それを利用したり調査をするという工数をそもそも確保できないというようなことを言われたこともあります。機械学習モデルを作成するための準備の仕方、精度の評価など、経験も知識もない方が多く、利用するためのハードルが高かったのかもしれません。
そのようなハードルを少しでも下げられるように、機械学習の導入支援を開始し、その一環でモデルの作成代行を請け負うことにしました。すると、CSの方が機械学習の利用に大きな興味を示してくれました。パトロールの人たちは毎日大量のユーザコメントに対応し、違反かそうではないかの判定をしています。
我々はデモ用にユーザ投稿を判定するUIを提供していたので、簡単な修正でCSの方がパトロール業務に利用できるようにしました。判定はUIで可能ですし、判定のためのモデルは我々が作成できます。学習データはこれまで蓄積された違反投稿のデータから作成できました。
カスタマーサポートでは多数のサービスの対応をしています。まずは規模が大きいニュースコメント向けのモデルを作成し、現場での運用を開始してみたところ、けっこう効果があると判明しました。このため知恵袋やオークションなど他のサービスでも機械学習モデルを導入していくことに決まります。CS側では多くの関係者を巻き込んで機械化推進PJが立ち上がり、CS業務の機械化を推進するための独立したチームも作成され、本格的に機械学習モデルの導入が推進されていくことになります。
UGC判定PFのメンバーは当時も今も2〜3人(しかも複数PFの掛け持ち)で、モデル提供まで6週間ほどかかるような状況です。せいぜい月に1つぐらいしかモデルを提供できません。CSのモデル需要は無尽蔵に見えます。できるだけ短時間で精度の良いモデルを作成し提供できる体制が必要です。
モデル開発からAPIデプロイまでのタイムラグと運用コスト
判定プラットフォームで利用する機械学習モデルを作成してからAPIとして利用できるようになるまでには、2020年当時は3週間ぐらいかかっていました。モデルごとに受け取るデータの特徴量も違っていたので、個別に判定APIを実装し、単体テスト、統合テストの作成、Dockerコンテナ化、CI/CD対応、ログ確認や監視の設定などを行う必要があります。似たような作業なので、この時間をなんとかして短縮する必要がありました。
またモデルごとに独立したコンポーネントとしてデプロイするような体制では、モデルが増えるごとにその後の運用負荷が増加していくことも大きな懸念としてありました。我々はモデルの開発もAPIの開発も行っていますが、リリース後は自分たちですべて運用しており、運用負荷が増えると開発工数がその分減っていくことになります。どんなに単純なコンポーネントでも利用するライブラリに脆弱性が見つかれば修正する必要があり、依存するライブラリやプラットフォームがEOL(サポート停止)になればその対応が必要になるなど、運用コンポーネントの数が増えてくるとメンテナンスコストが重くのしかかってくるのです。
モデル開発の属人化と乱雑な情報管理
機械学習モデルの開発は2020年の後半から開始したばかりで、チームとしてのノウハウもなく、機械学習モデルの開発について明確にはフローが定まっていませんでした。モデル開発は担当エンジニア個人のスキルや創意工夫に頼っており、モデル開発が属人化していました。このため誰かが作ったモデルを別の人が再現するのが難しかったり、途中でモデルの開発を別のメンバーが引き継ごうとしても、これまでどのようなことをトライしたのか、何をまだやっていないのかも十分には管理されていない状態でした。
モデルの精度改善と手作りの限界
ヤフーでは機械学習を活用しているチームはデータ系やサイエンス系の組織に集中していて、我々のようなプラットフォーム系のチームにはそれほど機械学習、特に自然言語処理に強いメンバーはいません。なんとなくモデルを作成し、なんとなく精度が出ていることは確認していましたが、ユーザからはさらに精度を上げてほしいという要望が届きます。そしてモデルの数も大量に必要だということもわかっていました。質も量も必要なのです。
課題の解決のための取り組み
デプロイタイムラグと運用コストの撲滅
まず着手したのはモデル開発とAPIデプロイのタイムラグの圧縮です。2020年当時モデル開発に3週間、デプロイまでさらに3週間という記録が残っています。モデル開発にかかる時間を短縮するのは難しいかもしれないけれど、デプロイまでの時間はかならず短縮できるはずだという見込みはありました。
そういう課題感を持っていた2021年3月ごろ、AIPFからCuttySarkがベータ公開されます。これはONNX RuntimeとTensorflow Servingを統合したモデル判定PFです。LightGBMやPyTorchなどのモデルはONNXというモデルの共通形式に変換することでONNX Runtime上で推論が可能になり、TensorflowのモデルはTensorflow Servingで推論可能になります。
作成したモデルのパスや必要リソースを指定してAPIを叩くだけで推論APIが立ち上がるという仕組みです。とても簡単に使えたので、まだベータ段階でしたがすぐに導入を決断しました。これにより、モデルを作成とAPIへのデプロイのタイムラグはほぼ無くなるはずです。ただ、実際にはONNX Runtimeに置けるのはモデル本体だけで、前処理が必要な場合はそれは別途処理する必要があるとわかりました。たとえばmecabによる形態素解析など外部ライブラリが必要な部分は判定APIに渡す前に自前で処理する必要があります。
前処理だけではなく、既存の判定APIとCuttySarkの判定APIのインタフェースをそろえる必要もあります。そのため、この2つを吸収するアダプタを開発しました。ここでは判定に利用するモデル名をキーにして渡されたデータを前処理し、CuttySarkのインタフェースに変換してリクエストを処理します。
新しいモデルを追加するたびに前処理モジュールを追加する必要がありますが、その部分はPythonパッケージとして別途管理し、推論環境と学習環境での共有をすすめました。モデルごとに行う前処理もパイプラインとして定義されているため、前処理のロジックはどのモデルでも共通に処理できます。複数のタイプの異なるモデルに一箇所で対応できるため、コードは簡潔になり、改修コストも最小限ですみます。
Tensorflow Servingの場合はほとんどの前処理をモデル側に持てるため、後述のBERTでは特別な前処理は不要になっています。そのためBERTモデルについては特に新しいコードを追加する必要なしに新しいモデルが利用可能になります。
CuttySarkに対応するためにはONNX RuntimeのgRPCベースのインタフェースを理解する必要があったり、前処理とインタフェース調整をするためのアダプタを開発する必要があったりといった困難はありましたが、そこを乗り越えてしまえば、結果として、LightGBMを使ったモデルなどONNX変換が必要なモデルの場合でもデプロイのタイムラグは2,3日程度。Tensorflowモデルについてはタイムラグは0日に短縮できました。
タイムラグの短縮だけでも大きな成果でしたが、CuttySark本体は別のチームが管理してくれているので追加の運用コストもほぼ0になります。自前でAPIを作っていたら数十ものAPIを自分たちで運用する必要があったかと思うとぞっとします。プロジェクトごとのモデルの一覧やリソースの利用状況、モデルごとのメトリックスなど必要な情報はCuttySarkチームが準備してくれたgrafanaでモニタリングができます。レイテンシの悪化などがあれば通知することも簡単に設定できます。
CuttySark環境のモニター画面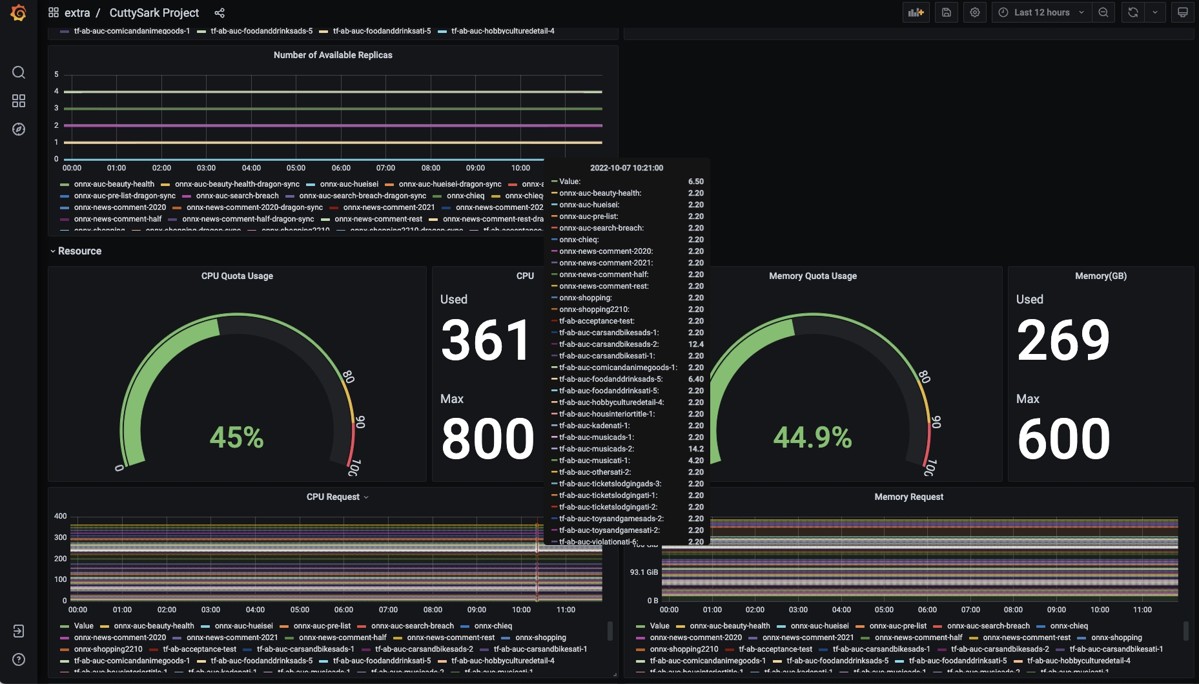
2021年の7月にはCuttySarkに最初のモデルをデプロイしています。モデル作成依頼されてAPIとして提供するまで6週間だったものが3週間程度にまで短縮しました。
モデル作成実験の管理、再現性の確保、属人化の防止
CuttySark対応と同時にモデル作成プロセスも定式化していきました。ここで重要な役割を果たしたのはMLflowです。これもAIPFとして提供されています。
MLflowにはUIとWeb APIの他にPython APIが存在し、モデルの作成コードにMLflowのコードを追加しておくと学習するたびに自動的に実験記録を保存できます。ソースコードや利用したデータセットのパスなどMLflowに保存する項目を決め、MLflow apiを呼び出すコードサンプルを共有することで、誰がモデルを作成しても最低限の情報が確実に保存されるようになります。こうしてどのような実験をしているかという記録は常に保存されるようになり、他の人がモデルを再現することが可能になりました。
評価情報についてはテンプレート化したJupyter Notebookの内容をpepermillで実行し、それをHTMLに変換した形でMLflowに保存しています。MLflowに保存するメトリックス情報以外にもグラフィカルな形でモデルの情報を保存することができ、モデルについてのすべての情報がここで一元管理できるようになりました。
MLflowに保存されているメトリックスや評価ページ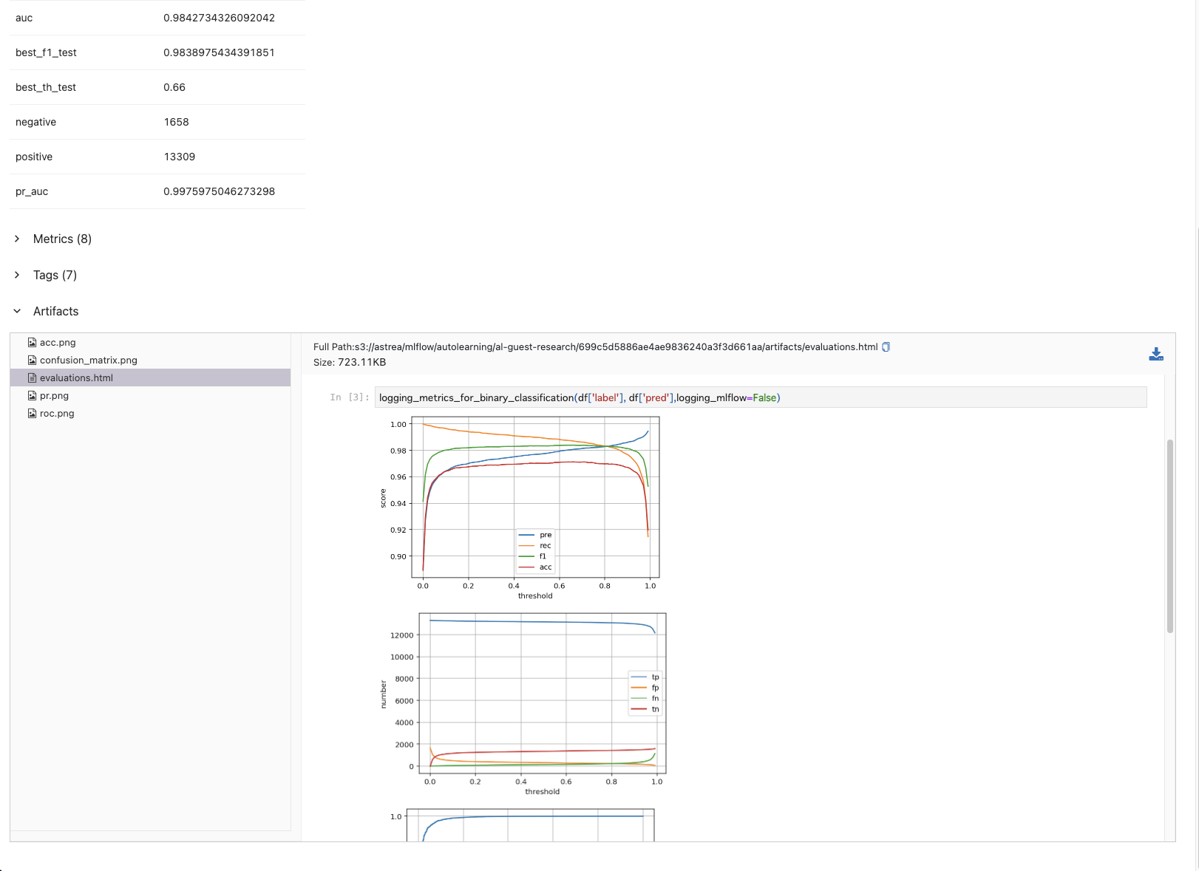
モデルの比較はMLflowで簡単に行える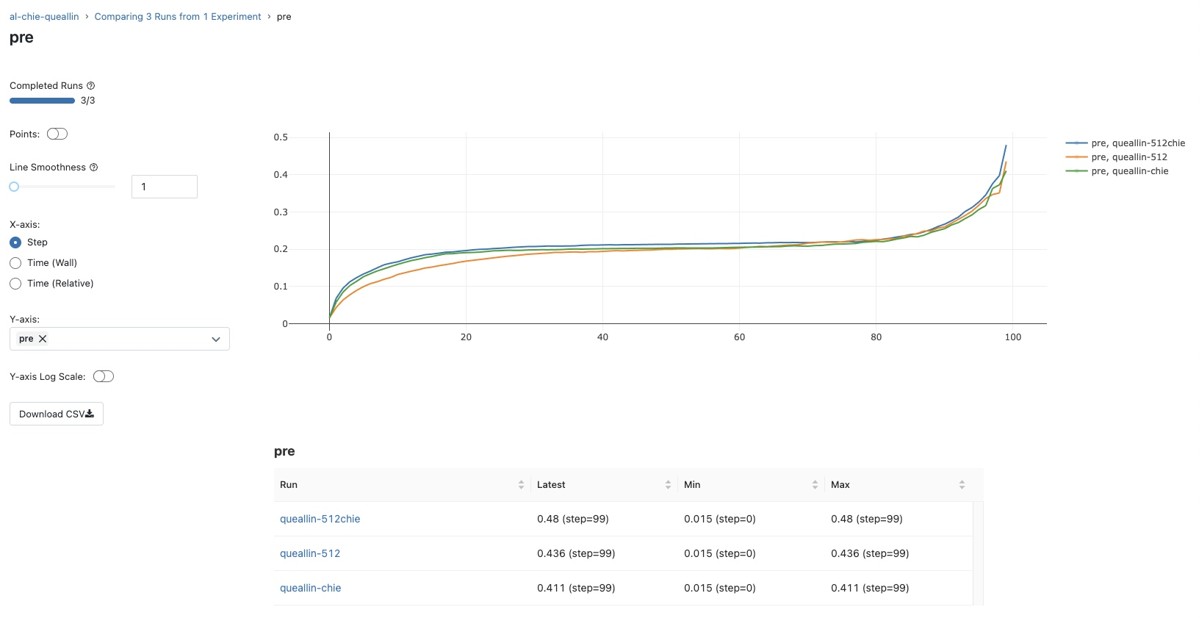
また、ONNXモデルに前処理の一部を組み込むためにはscikit-learnのPipelineの利用が必要なため、前処理のコード、モデル本体のコードはすべてPipeline形式で記述するのがチームのルールとなっています。Pipelineに組み込める形でコードを準備する必要はありますが、形式がコンパクトで一定なので誰がコードを書いても簡単に理解できます。
前処理のモジュールは必要に応じて追加する場合もありますが、たいていの場合は既存のモジュールを組み合わせることで前処理のPipelineもモデル本体のPipelineも実装できるようになっています。ライブラリはpipパッケージとして社内のartifactoryに置いているので、Jupyter Notebookなどモデル作成環境からも簡単に利用することができ、モジュールの再利用率が非常に高くなりました。
MLflowの利用方法を含めたモデル作成の基本的な流れは詳しくドキュメントにまとめてあり、基本ツールのpipモジュール化とあわせて属人化の解消につながっています。
BERTの採用とGPUの活用
2021年6月にヤフー研究所の方がBERT推論環境をCuttySarkで実現する方法を紹介してくれました。Deep Learningによる大規模なモデルはGPUを利用しないとレイテンシ的に我々のPFには使えないかなと漠然と思っていたのですが、BERTでも特にサイズの小さいモデルであればCPU環境で十分小さいレイテンシで推論が可能であること、比較的少ない学習データでもファインチューニングをすることで簡単に高い精度のモデルが生成できることがわかりました。
ヤフーにはGPUを利用したモデル学習を行う環境としてAIPFからLakeTahoeという環境が提供されています。Googleで言うとVertex AI Trainingに相当するものです。これまでLightGBMなどでモデルを開発している分にはCPUだけでも学習できたので使っていませんでしたが、BERTの学習にはGPUが必要になるため、LakeTahoeの導入を決定しました。LakeTahoeでのモデル学習に必要な開発は次の2点です。
- GPUを利用してBERTのファインチューニングを実行するためのDockerimage
- 指定した学習データを取得してBERTのファインチューニングを実行し、評価データとモデルをMLflowに保存し、CuttySarkにデプロイするスクリプト
ニュースコメントのための判定モデルを作成するには、ニュースコメントのデータから作成された学習データと評価データを指定してジョブを実行します。知恵袋向けの判定モデルを作成する場合は、学習データと評価データを知恵袋用のものに変更するだけです。
学習スクリプトはまったく同一ですが、それぞれ専用の判定モデルが作成されます。BERTでは事前学習とファインチューニングの2つのフェーズでモデルを学習します。膨大な量の日本語テキストで長い時間をかけて作成された事前学習済みモデルは研究所の方が準備してくれていて、我々は追加の学習データでファインチューニングすることでそれぞれのドメインに最適化された判定モデルを作成します。
BERTではモデル作成に利用できる特徴量は限定されますが、何日もかけて手動でモデルを作成する必要もなく、本当に簡単にモデルが作成できます。学習スクリプトにはMLflowのコードが組み込まれているので、自動的に実験管理の記録は残されます。作成されたモデルは自動的にCuttySarkにデプロイすることも可能です。
2021年の9月からBERTを利用したモデル作成を開始します。これでモデル作成とデプロイに必要な時間は数時間程度にまで短縮されました。ほとんどはBERTのファインチューニングに純粋に必要なコンピューティングの時間だけです。半年前までは6週間ほどかかっていた作業です。
学習パイプラインの自動化
BERTとLakeTahoeで簡単にモデルは作成できるようになりましたが、まだ次のような手順が必要な状態です。
- ユーザから依頼を受けて学習データを受けとる
- オブジェクトストレージに学習データをコピーして学習ジョブを実行
- 学習ジョブが終了したか確認
- 判定APIとして正常にデプロイされているか、レイテンシに問題がないか確認
- ユーザに完了連絡
次のステップはこの手順を僕らの介在なしにできるようにするというのは自然な流れです。
そのため、簡単に操作できるようなUIを準備することにしました。利用者が学習データをアップロードし、モデル名を入力し、モデル作成ボタンを押せば、内部的にLakeTahoeのジョブを起動するようなシステムです。モデルの作成が完了するとモデル一覧画面で確認でき、モデルの評価詳細はMLflowのUIに遷移するようにしています。モデルの評価を確認して実際にためしたいと思ったモデルについてはデプロイボタンを押すことでAPIとして利用可能になります。
機械学習判定システムの主要コンポーネント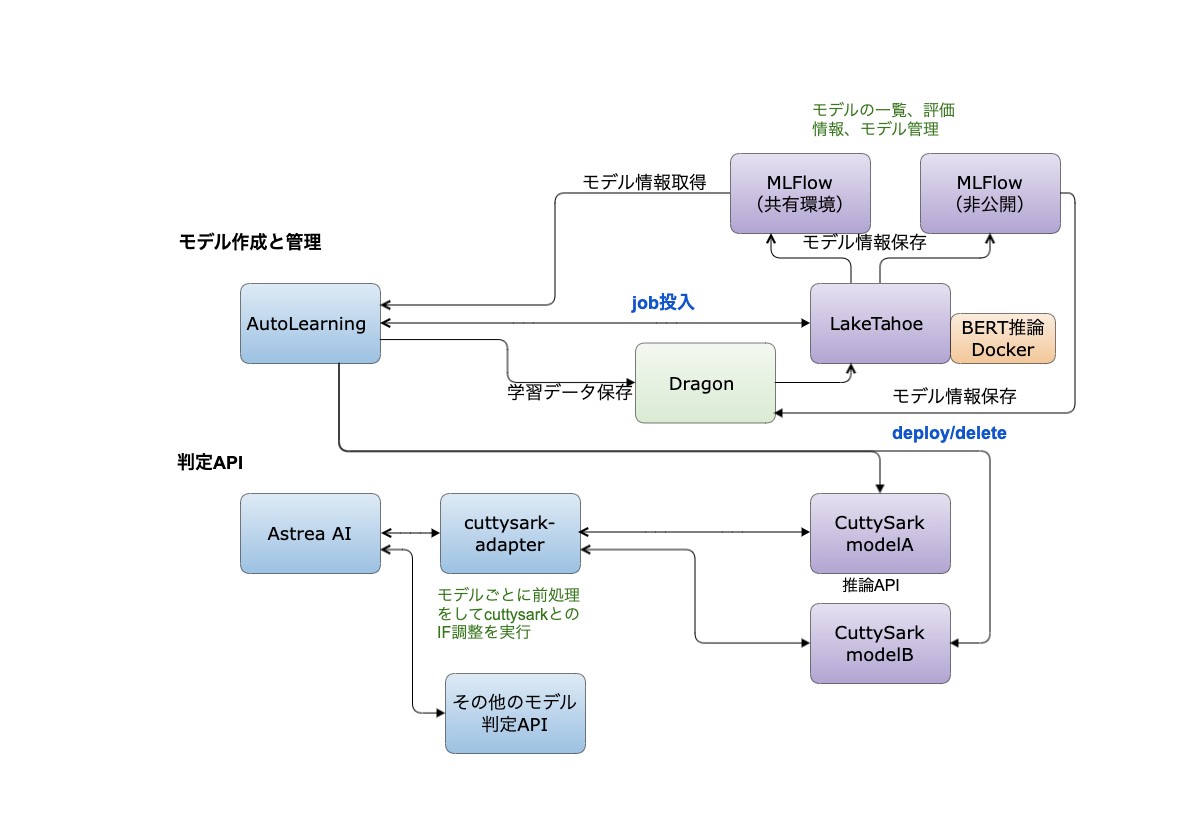
モデル一覧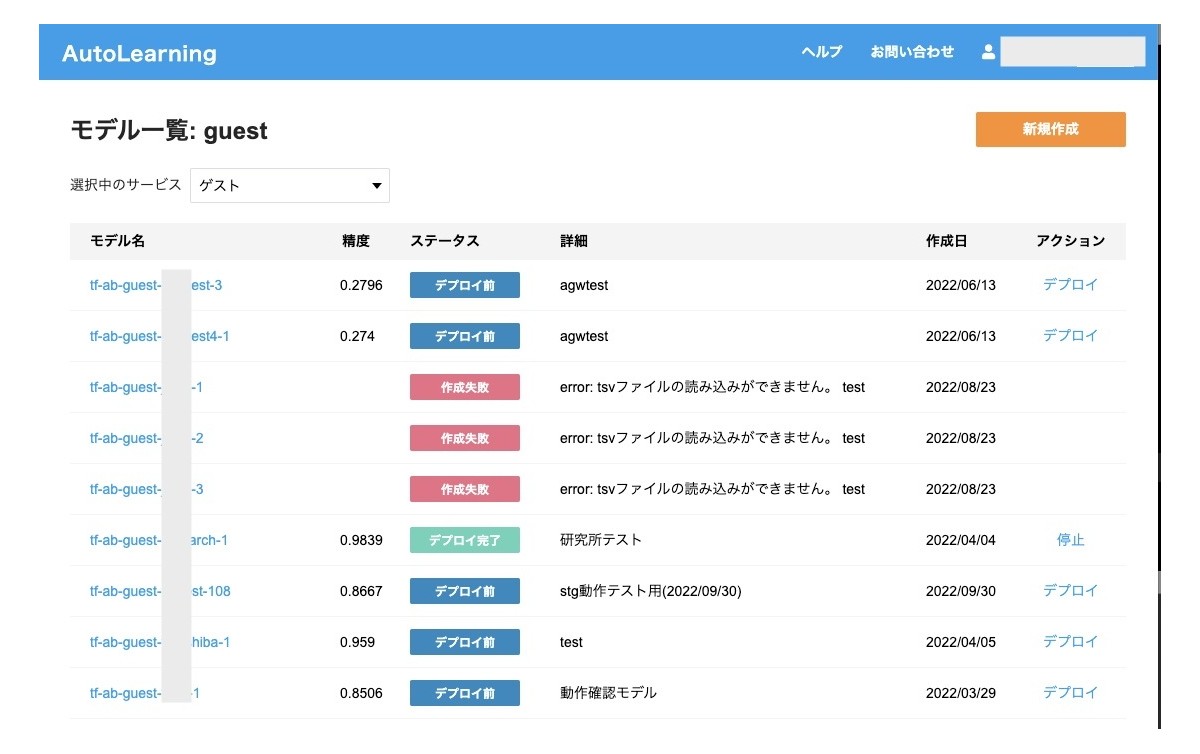
モデル作成画面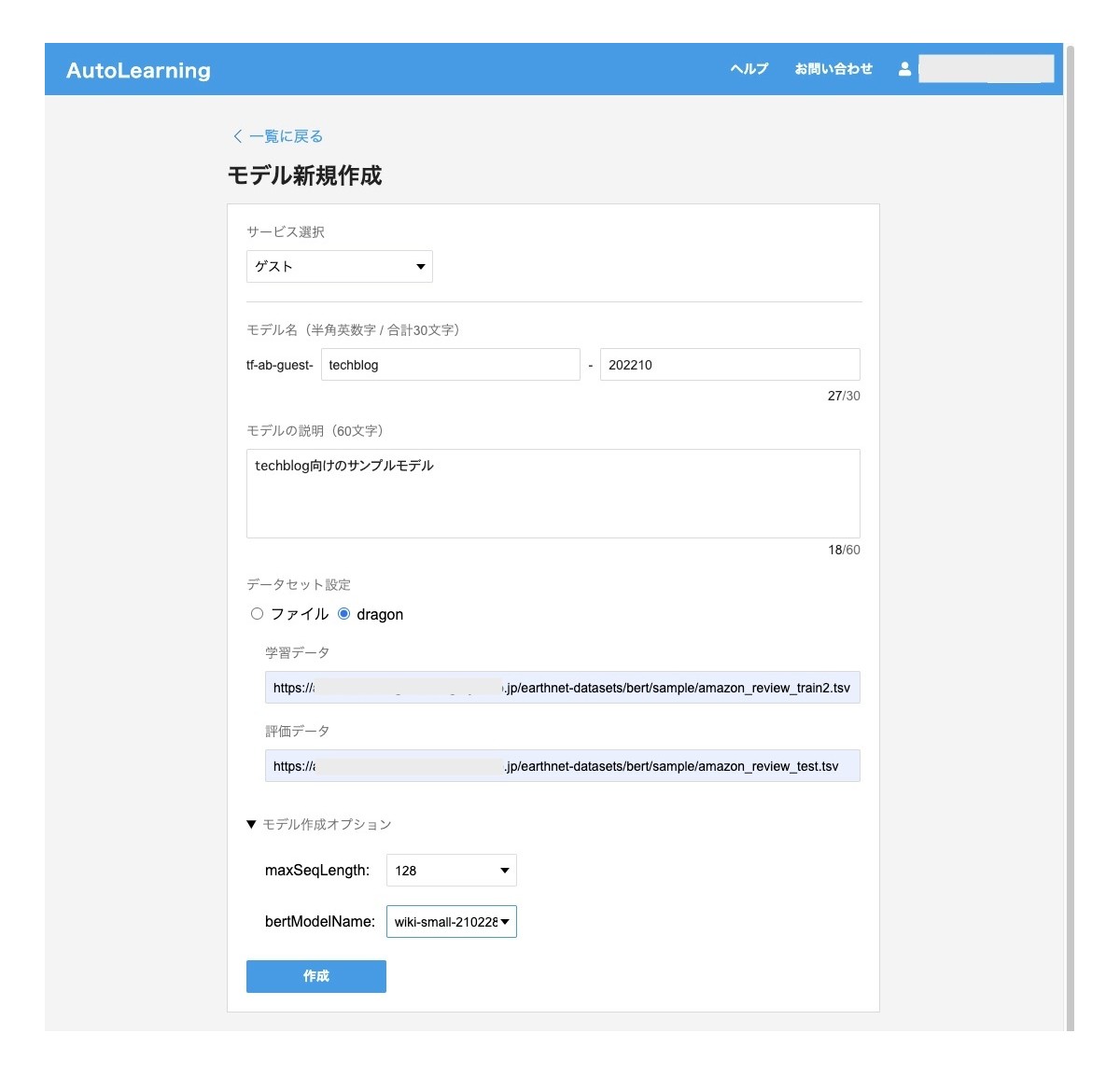
このシステムは2022年3月末から稼働を開始しました。
2022年9月現在、リリースから5カ月間にこのシステムで作成されたBERTモデルは106個、そのうち実際にデプロイされたモデルは22個になります。1カ月に20個以上のモデルが作成できたことになります。作成されたモデルはオークション、ニュースコメント、知恵袋などのおもにCS業務の支援に利用されています。CuttySark、MLFlow、LakeTahoe、BERTを使わず、2020年と同じように手作業でモデルを開発していたら絶対に達成できなかった数字です。
短期間に大量にモデルを作成できるということは、モデルの精度改善のためのトライアルの回数を増やせるということにつながります。学習データの作成方法を変更するなど様々なことが試されているようです。
今後の展開
モデル作成の多重化
現在は一度に一種類のモデルしか作ることができません。BERTの事前学習モデルも何種類かあり、最大トークン数の設定など調整可能なパラメタもいくつかあります。今は利用者が自分たちで複数のタイプのモデルを作成して比較している状態です。これをシステム側で一度に複数のモデルを作成できるようにする予定です。LakeTahoeの機能でサポートされているため、ここは比較的簡単に拡張できる見込みです。
モデル作成の多様化
現在はBERTだけを利用していますが、transfomerを利用した事前学習済みモデルは他にもRoBERTaやXLNetなどいろいろあります。このように多種類のモデルを同時に作成できるようにするためArgo Workflowsの導入を予定しています。Argo Workflowsから複数のLakeTahoeジョブを実行し管理します。BERTとそれ以外のモデルを同時に作成し、その中で一番良いモデルを選択できるようになります。
他にもユーザ投稿に関連する自然言語以外の特徴量を利用できるようなモデルを作成できるようにしたいため、グループ会社で開発されているAutoML的なプラットフォームを試してみる予定です。
データ作成フローの自動化
現在は学習データは完成されたものを提供してもらうフローになっていますが、学習データを作成する部分も我々のシステムに組み込むことができれば、利用者側の手間を減らすことができます。生データの取得、バリデーション、形式の変換、データのマージなどデータ取得にかかわる部分もArgo Workflowsに組み込むことを検討しています。
これが可能になれば定期的に更新された学習データからモデルを作成し、旧モデルと性能を比較して問題なければAPIとしてデプロイするといったことまで自動化できそうです。
ドリフトの検知
学習データのドリフト、モデルのアウトプットのドリフトなどを自動的に検出できるようにすることを検討しています。
説明可能なAI
機械学習判定の問題として、どのようにしてこの判定スコアになったかがブラックボックスで人間にはわからないという問題が指摘されています。limeなどそれを解決するための技術がいくつか利用できるようになっているため、導入を検討しています。学習データの作成やモデル改善のためのヒントにもなると期待しています。
おわりに
学習データの作成や評価などまだ難しい部分はありますが、少なくとも学習データができてからは非常に簡単に大量に高精度の機械判定モデルを作成できるようになりました。ここに大きな威力を発揮したのがMLOpsでありBERTのような基盤モデルです。比較的誰でも利用できるこれらの技術を組み合わせることで、ここで記載したことは再現できます。この記事を機会にいろいろなところで機械学習(あるいはAI)の民主化が進むことを期待しています。
機械学習の仕事に興味がありましたら、採用情報も見ていただけると幸いです。
また、この夏に開催したインターンでは、今回記事にした中の一部を開発してもらいました。Argo Workflowsで複数モデルの同時作成のワークフロー開発など担当してもらい、「Yahooで働く像が自分の中で明確化された」「自分の専攻分野につながる職業の様子が見れたのは興味深かった」「今まで知らなかった技術に数多く触れることができた」といった反応をいただけました。次のインターンの募集も確認いただけるとうれしいです。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 鈴木 一正
- 機械学習プラットフォームエンジニア
- Yahoo!メールや検索連動広告などのエンジニアなどを経て今は機械学習プラットフォーム周辺のエンジニア。システム企画、PJ管理、技術選定、機械学習の導入支援、機械学習モデルの開発、モデル作成の自動化ツールの開発、MLOps業務など行っています。ワインと旅行好き。
-



