こんにちは。ヤフー株式会社のシステム統括本部クラウドプラットフォーム本部に所属している寺田です。
クラウドプラットフォーム本部は、弊社のアプリケーションが稼働する基盤となるプラットフォームを開発運用する組織となっています。内製のプライベートクラウドプラットフォームに加え、他社製品も多く存在します。
本稿では、システム運用者が避けて通ることのできない「事故」について、組織としてどう向き合ってきたのか、2年間の取り組みの変遷と成果をご紹介いたします。
なお本稿での事故という表現は、プラットフォーム利用者に影響のあったシステム障害を指しています。
事故対策の背景
まずはじめに、なぜ私たちが組織として事故対策にアプローチしはじめたかですが、最もシンプルな目的は増え続ける事故に組織として対策を打つ必要があったためです。
複数のプロダクトを抱える組織としての視点で見たときに、例えば以下のような課題感を抱えていました。
- 同じような原因の事故が異なるプロダクトで発生している
- 再発防止策の共有といった組織感連携が出来ていない
- オペレーションミスが減らない
こういったプロダクト単位の事故対策のみではカバーしづらい課題に対して、組織としてアプローチすることで、より効率的で効果的な対策を打つことができ、ナレッジとして今後の財産にできるのではないかと考えました。こうして私たちは事故対策プロジェクトチームとしてこの問題に取り組むこととなりました。
事故要因分析と分類
まず何からはじめたかというと過去の事故の分析です。どういう事故が多いのか、クラウドプラットフォーム本部ならではの特徴はないかなど、過去の事故を分析し事故要因の特定を行いました。
分析にはヒューマンエラーの発生要因を洗い出すためのフレームワークであるm-SHELLというモデルを参考にしました。事故を起こした当事者のみの問題ではなく、環境や体制など周囲を取り巻く要素が複雑に絡んでくるため、それらの関係性を明らかにするところからはじめる必要があったためです。
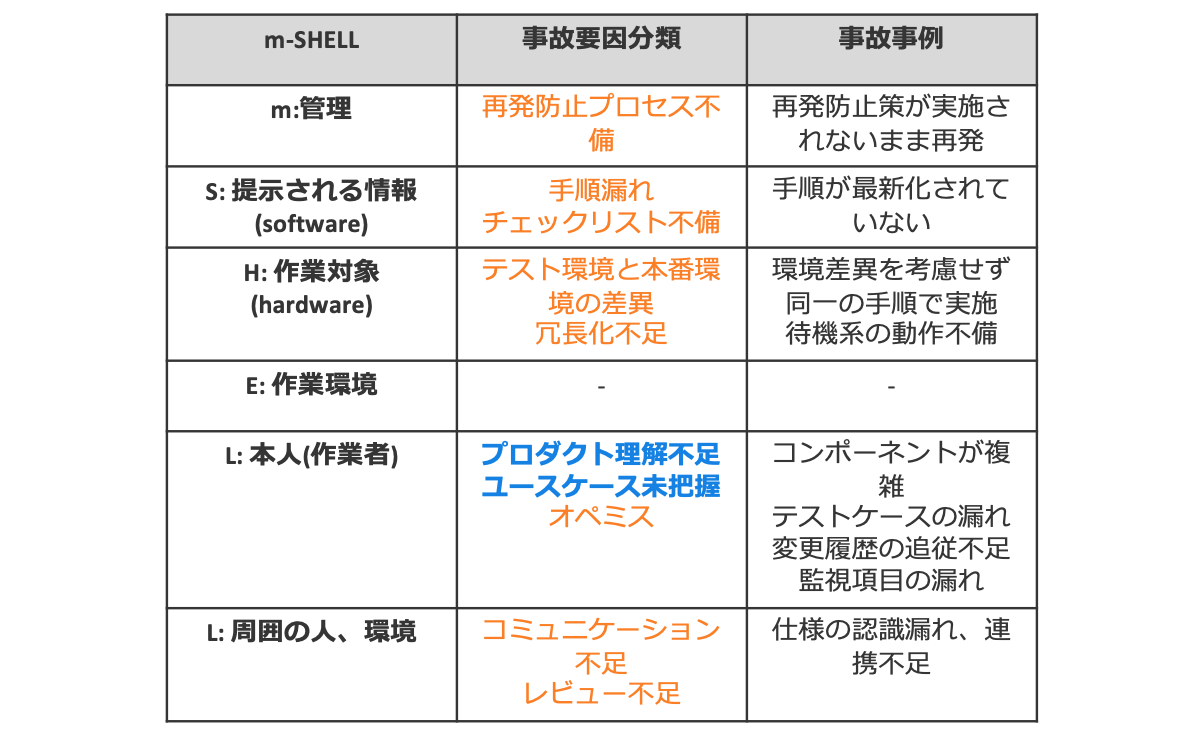
分析した要因をまとめてみると、事前に防げたであろうという予見できる事故と、気づくことは難しかったであろうという予見できない事故に大きく分類できそうだとわかりました。
さらに事故数と照らし合わせると、私たちの組織は予見できない事故に分類されるプロダクト理解不足やユースケースの未把握といった要因がもっとも事故発生傾向にあることに気づきました。
他社製品を扱うプロダクトを多く持つ組織の特性のためか、製品仕様やユースケースの理解が追いついていないケースが多く、アップデートなど変更点を追従しきれず事故につながるというようなパターンが複数見られました。
これらの結果より、まずは予見できない事故を防ぐ戦略を進めることにしました。
1. 予見できない事故への対策
発生が予見できないということは、自分たちの理解の範囲外にあるということです。
気づかない場所で障害が発生するため、当然監視も不十分であり、MTTD(平均検出時間)が伸びる傾向にあります。また影響範囲もすぐにはわからないことが多く、障害収束までも時間がかかり、MTTR(平均修復時間)も同様に長期化することになります。この場合、自分たちの理解の範囲を広げるアプローチも選択肢としてあるとは思いますが、一朝一夕に効果がでることでもなく継続性にも難があります。
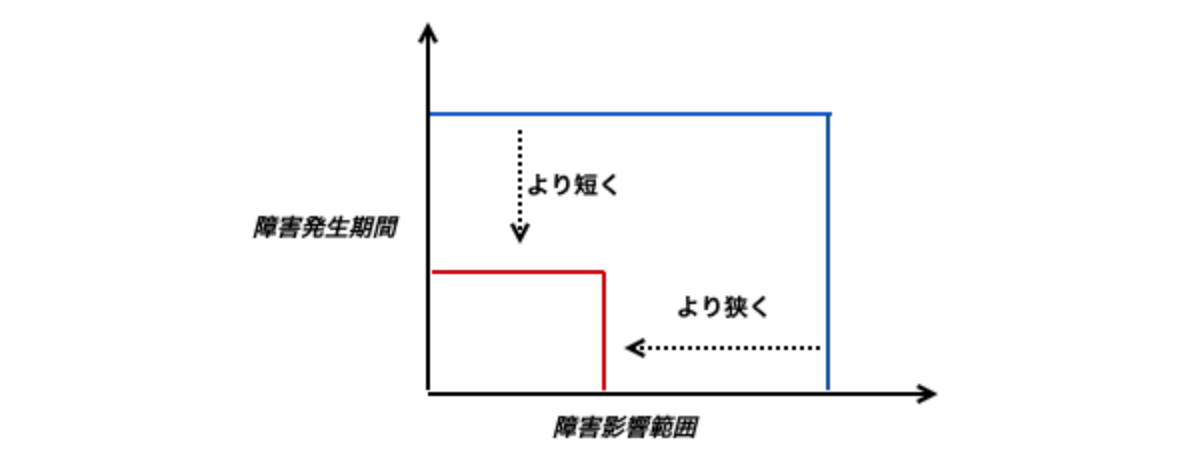
そのため予見できない事故に対する基本的な対策は、障害発生後の影響をいかに最小限に抑えるかというダメージコントロール施策を選択しました。
施策:カナリアリリース
1つ目の施策としてはカナリアリリースの導入推進を行いました。
カナリアリリースとは、影響範囲を小さくデプロイ、メトリクスをもって評価を行い、本番リリースの安定性を確保する目的のデプロイ手法です。プロダクトの理解不足やキャッチアップ不備は発生しうるという前提の中、小さい単位でコントロールされたリリースを行うことで事前の検知や影響範囲の局所化をすることが狙いです。
具体的には、カナリアリリースとはどういうものであるかの認識合わせのため、まずは定義や進め方の原則を作成しました。
- 原則1. 変更を本番環境の一部へデプロイすること
- 原則2. ロールバック戦略が存在すること
- 原則3. メトリクスによるリリースの評価プロセスがあること
加えて、こういう事故は防げるよね、こういう構成はカナリアに向いてないよねといった議論をもとに、アンチパターンなど導入のためのプラクティスを作成し展開しました。
施策:SLI/SLO可視化・監視
2つ目の施策はSLI(サービスレベル指標)/SLO(サービスレベル目標)の可視化と監視です。
これまで予見できない障害に関しては、システムで検知できず、運用者あるいはプロダクト利用者からの申告で気づくパターンが多くを占めていました。これでは運用者が気づくまで影響時間が伸び続け、プロダクト利用者からの信頼度も下がる結果につながります。
そこでまずは自分たちのサービスレベルをしっかり定義し、可視化と監視をすることで何が起こっているかを瞬時に判断できる体制を目指しました。
具体的には各プロダクトごとにSLIの洗い出しとSLOの定義をしてもらうところからはじめました。事故対策プロジェクト側でもいくつか目を通しレビューし、順次可視化と監視の実装を進めてもらいました。当然プロダクト側でやらなければいけない案件との兼ね合いもあるため、優先順を決めつつ長期にわたりカバレッジの向上に取り組んでいます。
これら取り組みにより、システムによる事故検知数が上昇し人の目による事故発見件数が減少するといった効果が得られています。
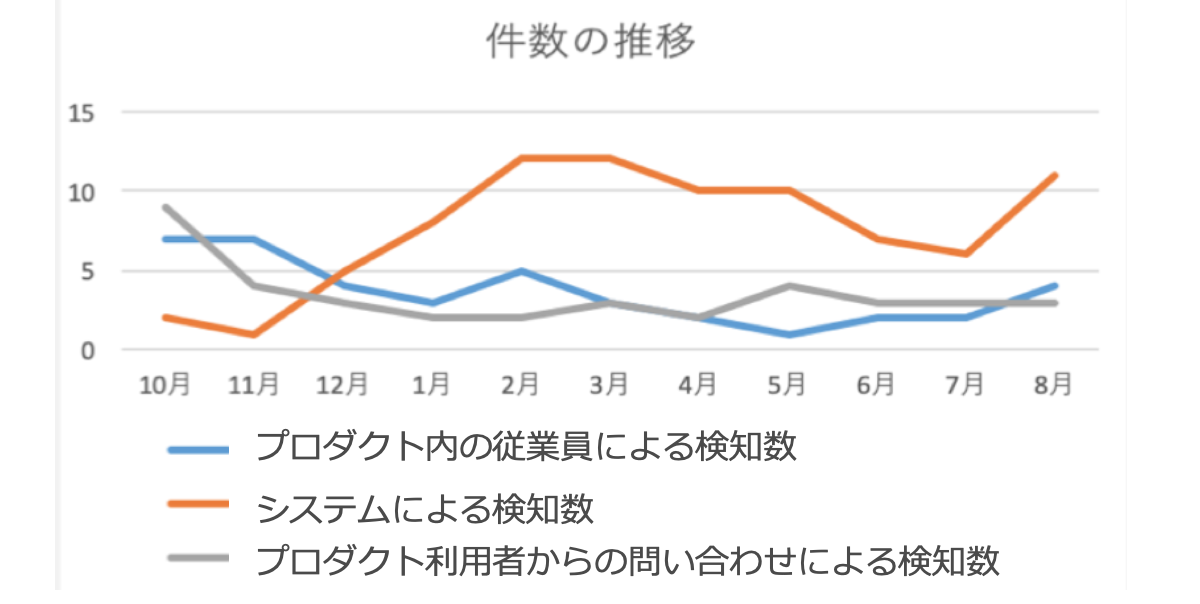
今後も監視範囲のカバレッジを上げていくことでより高い数値を目指せると考えております。
2. 予見できる事故への対策
次に対策に乗り出したのは予見できる事故です。
前もって防ぐことが出来た事故、気づくことが出来た事故を予見できる事故と定義し、発生前に防ぐアプローチを模索しました。
施策:リリースチェックリストの作成
事故分析結果より、コンポーネントのリリース時や設定反映時に初歩的な考慮漏れによる事故が複数のプロダクトで発生していることがわかりました。作業内容の誤認識や誤操作がトリガーとなり発生するいわゆるオペレーションミス起因の事故です。当時はリリースの品質担保を各プロダクトあるいは各個人に任せている状態だったため、ここにメスを入れ組織として一定の品質を担保できるようにならないかと考えました。
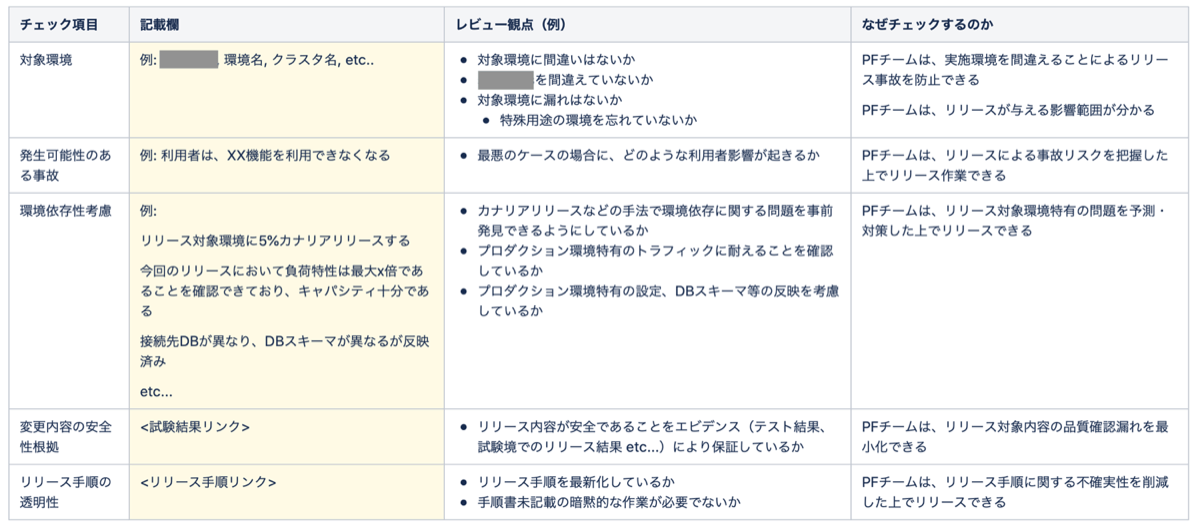
まずは過去の事故を見直し、「どういう点をリリース時に考慮できていればこの事故は防げた、もしくは影響を最小化できただろうか?」を議論し、リリース時に必要ないくつかの観点を整理しました。
- リリース対象環境の明確性
- リリースにより発生可能性のある事故の把握
- 環境依存性がないか考慮しているか
- 変更内容の安全性確認
- リリース手順の透明性
- リリース結果確認手順の透明性
- 切り戻し手順の透明性
これら7つの観点をベースにリリース時に考慮すべきチェックリストを作成し、組織内へ展開しました。
本チェックリストはリリース前のレビュープロセスや承認プロセスの中へ組み込んだり、チェック項目自体の自動化を試みたりといった使われ方がされています。また、本施策は、オペレーションミス事故数を可視化し定量的に効果分析するとともに、導入済みプロダクトへインタビューを行い定性的な評価を集め、結果をもとにチェックリストのブラッシュアップを行う運用をしています。
施策:ポストモーテムテンプレートの作成
事故分析を進めていくうちに、再発防止したはずの事故が再発していたり、根本原因に有効な再発防止策が打てていない事故の存在が明らかになりました。例えば、オペレーションミス起因の事故であるのに「なぜミスが発生したのか」といった根本原因まで掘り下げられておらず、表面的な監視導入施策でとどまっているといったケースです。
このように穴をふさいでいるつもりがふさがっておらず、人や組織が変わることで同じ問題が起こり続ける構図になっているプロダクトが多いのではないかと感じました。予見できる事故を防ぐためには、再発防止プロセスを強化する必要性があったのです。
具体的な対策としては、ポストモーテム(失敗や障害からの学びや振り返りをまとめ、再発を防ぐためのフォローアップアクションを記録するドキュメント)の品質を上げる取り組みを実施しました。発生した事故を振り返り、今後の事故防止に関する議論を整理・透明化し、組織の共通認識とすることを目的に、ポストモーテムを実施しやすくするためのテンプレートを用意しました。
- 事故概要
- 事故のタイムライン
- 真因分析と再発防止策
- ダメージコントロール改善の検討
といった各項目を穴埋めしていけば必要な情報が補完されるテンプレートとなっています。前述した予見できない事故への対策も考慮できるように、ダメージコントロール文脈での振り返り要素も盛り込みました。加えて、真因分析力強化のため、なぜなぜ分析をベースとしたmiroテンプレートも用意し、真因にたどり着きやすい環境も整備しました。
これらのテンプレートを利用することで、
- 事実を収集する
- 事実から真因を分析する
- 真因と再発防止策をリンクさせる
といったプロセスを踏むことができるようになっています。
3. 数値可視化の取り組み
また事故関連の数値を可視化する取り組みも並行して行いました。
現在、事故数、稼働率に加え、オペレーションミス起因事故数、性能不足起因事故数、システム未検知率といった原因種別ごとの数値や、MTTD/Rといったダメージコントロールにつながる数値などを可視化しています。
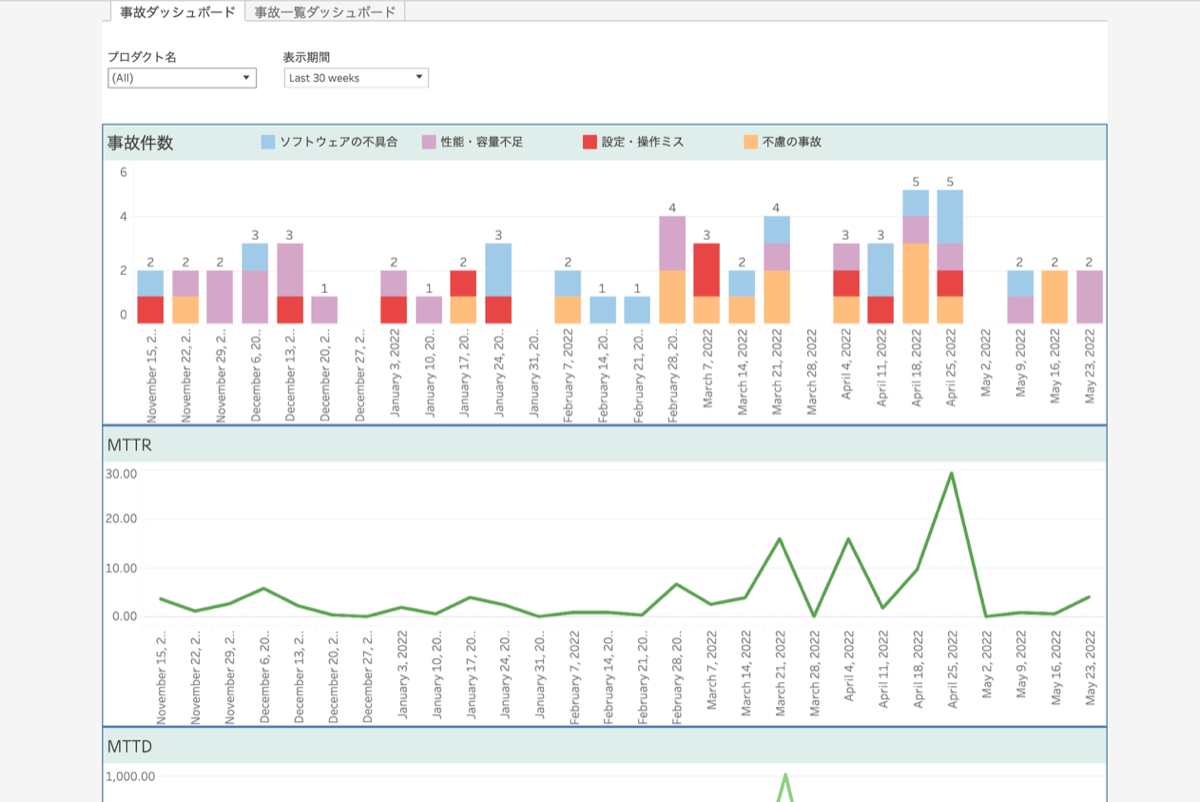
可視化には施策の定量的な成果計測や事故分析といった目的もありますが、プロダクト側の事故対策施策の導入判断指標とする目的もあります。
事故対策チームはプロダクトには属さないプロジェクトという位置づけで進めているため、これまで述べた施策は各プロダクト側へ依頼して導入してもらう形となります。そのため、導入を推進する根拠としての数値は必要不可欠でした。また、プロダクト側も自身の案件との優先順を判断するために、どれくらいの頻度でどういった事故が起こっているかといった情報を必要としていました。
このように数値化の取り組みは各種施策と同様以上に重要な意味をもっています。さまざまな事故関連指標を可視化しオープンにしていくことで、プロダクト側が自発的に改善行動を行えるきっかけになることを期待しています。
特定プロダクトへの重点的強化
ここまでは汎用的な施策作成と展開にとどまっておりましたが、今後はよりプロダクトに寄り添ったサポートも必要になってくるのではと考えています。
可視化によって見えてきた各プロダクトの状況をもとに、事故対策が弱いチームへの支援や強いチームからの横展開など、横のつながりを作る取り組みを行っていければよりよい世界が目指せるのではないかと思います。
おわりに
以上がクラウドプラットフォーム本部における2年間の事故対策活動となります。
事故を0にする、といった大きな目標を定めることは簡単ですが、0にすることはやはり困難です。事故の性質や特性に目を向け、 防ぐことができる事故は確実に穴を防ぎ、防ぐことができない事故は影響を最小限に抑える。この両面から向き合うことが最も重要だと感じました。
まだまだ課題は残っていますが、変化に強い安定した組織を目指し、これからも継続して事故対策にチャレンジしていきます。
本稿は2022年夏に開催されたCloud Operator Days Tokyo 2022で、審査委員特別賞(変革編)を受賞したヤフー株式会社の講演をベースに記事化しています。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 寺田 圭太
- SRE Engineer/ScrumMaster/Manager



