こんにちは。PayPayフリマでiOSアプリ開発を担当している續橋(@tsuzuki817)です。
PayPayフリマは2021年に画像の代わりに動画で商品の動きや細部を伝えられる動画出品機能をリリースしました。(プレスリリース:PayPayフリマ、5~30秒の動画で商品の動きや細部を伝える「動画出品」機能を提供開始)
動画投稿できるということは、撮影時にBGMなどの音楽が混入すると著作権侵害になる可能性もあります。今回は、iOSの音声認識機能「Build In Sound Analysis」を活用してユーザーに注意を促せるようにした事例を紹介します。
PayPayフリマとは?
PayPayフリマは、誰でも気軽に、安心して個人間取引ができるフリマアプリです。(PayPayアプリの中からも使えます)
動画出品機能は他のフリマサービスにはないユニークな機能で、多くのユーザーに利用していただいています。
悪意なくユーザーの動画にBGMが混入してしまうことがある
著作権に気をつけて動画を投稿するユーザーは多くはありません。部屋で音楽を流したまま商品を撮影してしまうなど、意図せず著作権侵害をしてしまう可能性が考えられました。著作権侵害をすると、著作者だけでなく違反を犯したユーザーまで不利益を被ることになってしまいます。そのため、初めて動画をつけた商品を出品するときにだけ、ユーザーに著作権侵害に注意してもらうためのアラートを表示するようにしていました。
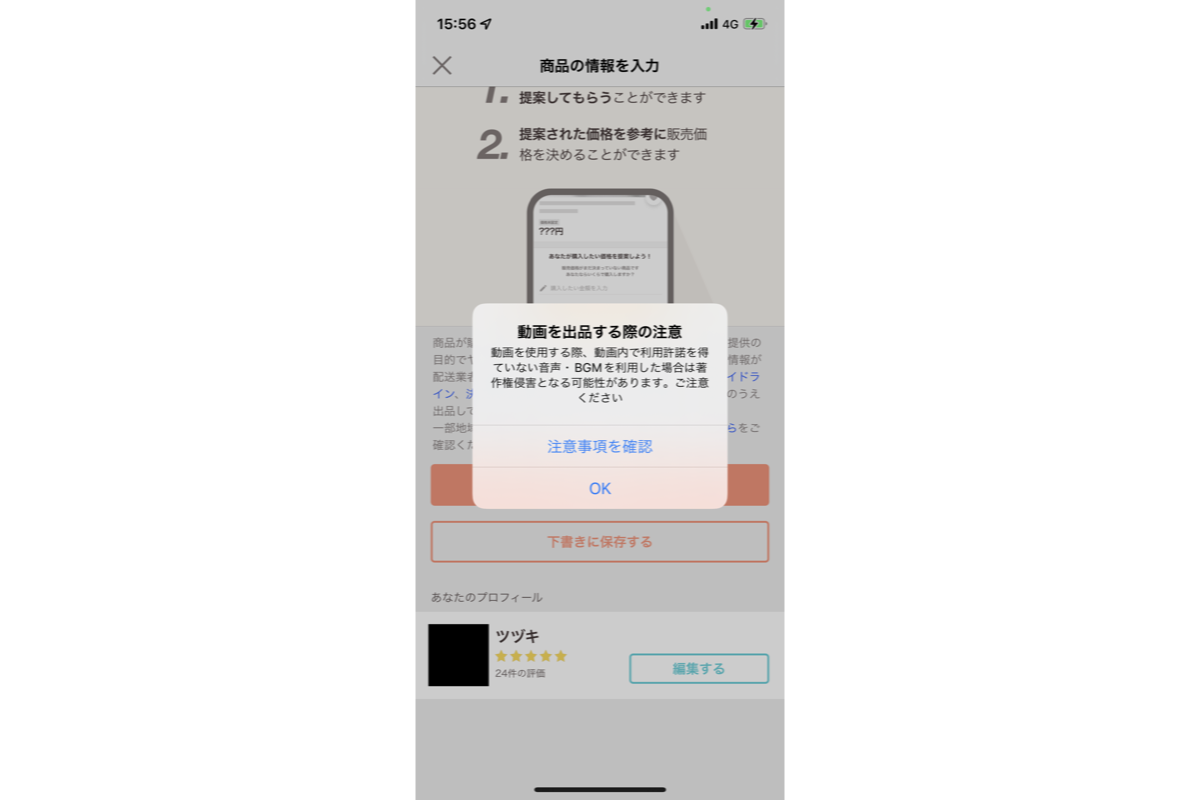
このアラートで注意喚起を促せているとも言えますが、実際に音楽が入っている動画かどうかの判断はユーザーに委ねられている状態になっています。そこでユーザーの注意力に頼らず、より必要なタイミングで注意を促すことはできないか検討しました。今回組み込みのSound Analysisを使うことで、動画撮影直後に動画内に音楽が流れていた場合に著作権侵害注意喚起のアラートを表示させられるようになりました!

ShazamKitの利用は断念
課題感を抱えている中、WWDC21の中でShazamKitが発表されました。
ShazamKitは音声認識のフレームワークです。Shazamの豊富な楽曲カタログから動画中に流れる音楽を認識させタイトル情報を取得し、アプリ内で著作権侵害をしているかどうかの判定をできるのではないかと考えました。しかし、ShazamKitは外部との通信を行って音楽を探すため、Appleにこのような使い方をして良いのか確認したところ、推奨されない使い方という返答でした。ShazamKitは音楽の著作権や商標権を確認するように設計されていないので、著作権侵害の検知にShazamKitを使うことは断念しました。
Sound Analysisを採用
WWDCの他のセッションを見ているうちに、Build in Sound Analysisについてのセッションを見つけました。Sound Analysisとは、WWDC19にて発表されたiOS 13から使える音声認識のフレームワークです。今までは音声を分類するにはCoreMLのモデルを自作する必要がありましたが、iOS 15からSound Analysisの機能がアップデートされ組み込みのモデルの利用が可能となりました。
組み込みのSound Analysisを使えるということは、以下の作業が不要になります。
- 大量のデータ収集や分類の手間
- 機械学習や音声に関する専門知識
- 高精度のモデルを開発するための処理能力
また組み込みのモデルを利用できるため、音声をオンラインに転送する必要がなくなりユーザーのプライバシーを保護することが可能になりました。さらに、組み込みのモデルで分類できる音の種類は303種類あり、大きく分類すると以下の4種類になります。
- 動物(犬、猫、牛、鳥など)
- 音楽(単に音楽かどうか、楽器の種類など)
- 人が出す音(話し声、ささやき声、歌声など)
- 生活音(水の音、食器の音など)
この中から、”music”という識別子を使えば、音楽を検知できることがわかりました。

以上のことより、動画内の音楽を検出でき、なおかつオフラインでセキュアに高速に検知できるSound Analysisを使って課題を解決しようと考えました。
検出時間(windowDuration)の設定
音声を分類する際に検出する音の範囲を設定する必要があります。例えば、楽器のような一瞬の音を判断したい場合は検出時間は短くし、救急車のサイレンを判断したい場合には長くする必要が出てきます。これは各々のサービス、検出したい音の特性によって変わるため適宜変える必要があります。
音楽を検出するためには、検出時間を伸ばしたほうがより正確になるので検出時間を伸ばそうと考えましたが、著作権は短いフレーズであっても発生するため短くても検出できるように特に長くはしませんでした。サンプルアプリの設定が1.5秒でしたのでそちらで試したところ問題なく検知できたので1.5秒に設定しています。
信頼度(confidence)の設定
検出された音声がどのくらいの精度で一致しているかを表す値です。
信頼度の閾値を高くすれば、誤検出される確率は低くなりますが十分な強さでないと見逃す可能性が高くなってきてしまいます。そのため、検出時間同様で使用事例に応じてバランスが取れた値を見つける必要があります。こちらは、値をいろいろと調整した結果、音楽を漏らさず、雑音には反応しないバランスの取れた値だった0.75としました。
音声分類する上で必要な要素
実際に音声分類をする際に登場するクラスを紹介します。
- SNClassifySoundRequest
- CoreMLモデルを使って音分類器を設定する
- 音分類モデルを用いて、音声データを分析する
- SNAudioFileAnalyzer or SNAudioStreamAnalyzer
- 対象とするファイルを指定 or AVAudioEngineのフォーマット
- それぞれオーディオファイルまたはストリームを処理する
- Custom Observer
- 分類結果を処理するオブザーバーを定義する
これらを使って試していきます。
Build In Sound Analysisの実装
全て記述すると長くなってしまうので重要な箇所だけ切り取って説明します。
最初に解析結果を受け取るためのオブザーバークラスを用意します。解析結果を受け取るためSNResultsObservingを継承し、request(_:didProduce:)で結果を受け取ります。
import SoundAnalysis
import Combine
// SNResultsObservingを継承
class SampleObserver: NSObject, SNResultsObserving {
// 分析結果を処理するsubject
private let subject: PassthroughSubject<SNClassificationResult, Error>
init(subject: PassthroughSubject<SNClassificationResult, Error>) {
self.subject = subject
}
// 失敗した場合に呼ばれる
func request(_ request: SNRequest, didFailWithError error: Error) {
subject.send(completion: .failure(error))
}
// 分析が完了した際に呼ばれる
func requestDidComplete(_ request: SNRequest) {
subject.send(completion: .finished)
}
// 解析結果を返す
func request(_ request: SNRequest, didProduce result: SNResult) {
if let result = result as? SNClassificationResult,
// "music"を指定
let classification = result.classification(forIdentifier: "music"),
// 信頼度が0.75より大きい結果だけ結果を出力している
classification.confidence > 0.75 {
subject.send(result)
}
}
}マイクから取得した音声をストリームで分類したい場合
AVKit周りのコードは長くなるので省略しています。
AudioEngineを作り、オーディオフォーマットを使ってSNAudioStreamAnalyzerを作成しています。AudioEngineからの出力があるたびに分析処理を走らせています。マイクからの分析はオーディオ周りの実装があるので大変に見えますが、音声分類のためのコードはとても少ないです。
// オブザーバーの作成
let observer = SampleObserver(subject: subject)
let newAudioEngine = AVAudioEngine()
audioEngine = newAudioEngine
let busIndex = AVAudioNodeBus(0)
let bufferSize = AVAudioFrameCount(4096)
let audioFormat = newAudioEngine.inputNode.outputFormat(forBus: busIndex)
// 組み込みのモデルを使ったリクエストを作成
let analyzer = SNAudioStreamAnalyzer(format: audioFormat)
// リクエストとオブザーバーを設定
try analyzer.add(request, withObserver: observer)
audioEngine.inputNode.installTap(
onBus: busIndex,
bufferSize: bufferSize,
format: audioFormat,
block: { (buffer: AVAudioPCMBuffer, when: AVAudioTime) in
self.analysisQueue.async {
// オーディオエンジンからの出力があるたびに分析する
analyzer.analyze(buffer, atAudioFramePosition: when.sampleTime)
}
})
try audioEngine.start()ファイルから音声分類する場合
また、ファイルからの音声分類する方法はとても簡単でSNAudioFileAnalyzerに保存しているファイルパスを渡すだけで分類できます。
// 組み込みのモデルを使ったリクエストを作成
let request = try SNClassifySoundRequest(classifierIdentifier: .version1)
// 分類したいファイルのURLを指定して作成
let analyzer = try SNAudioFileAnalyzer(url: url)
let observer = SampleObserver(subject: subject)
// リクエストとオブザーバーを設定
try analyzer.add(request, withObserver: observer)
// 分析開始
analyzer.analyze()Sound Analysisの細かい注意事項
- MainThreadで動作させないようにする
- 音声認識中に画面がロックされないように、音声認識は別スレッドで行う
- AVAudioSessionの管理に気をつける
- ストリームの音声を検出したい場合はAVAudioSessionを使うが、すでに裏で動いている場合は新たに作る必要はない
おわりに
このようにSound Analysisを使うことで、ユーザーへの注意喚起を簡単に実現できました。
本来なら音声分類のための知識や準備が必要なところを数行のコードだけで叶えられてしまうSound Analysis、ぜひ皆さんもさまざまな課題解決に利用してみてください! よろしければPayPayフリマの他のiOS関連記事もご覧ください。
- iOSのVision.framework活用事例 〜 PayPayフリマのクレカ番号読み取り機能実装例
- iOSのCompositionalLayoutによるカスタムレイアウト実現と高速化 〜 PayPayフリマのグリッドレイアウトUI
また、PayPayフリマを一緒に育てるメンバーも絶賛募集中です。2次流通日本一のサービスを目指して、一緒に働きませんか?
参考文献(外部サイト)
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 續橋 涼
- iOSエンジニア
- PayPayフリマのiOSアプリ開発を担当しています。iOSアプリの個人開発が趣味でたくさんアプリをリリースしているのでぜひ使ってみてください。
-



