こんにちは。テクノロジーグループ サイエンス統括本部で画像認識領域の技術開発や応用を担当している土井です。
ヤフーは、特許庁が初めて開催した「AI×商標 イメージサーチコンペティション」において、第1位を獲得しました。(プレスリリース)
本記事では、社内の画像検索に関わる有志で参加した、「AIx商標イメージサーチコンペティション」(特許庁主催、Nishika株式会社開催/以降、本コンペまたはコンペとする)の概要と弊チームの優勝解法について紹介します。
目次
コンペの概要
特許庁では、年々増加している商標出願件数に対して、より効率的かつ品質の高い審査業務を実現するために、画像検索により類似商標を検索する画像検索システム(イメージサーチツール)を試験的に導入しています(2021年10月時点)。このツールは、一定の評価を得ているものの、商標の部分的な一致や色彩の濃淡などに係る画像検索の精度には特に改善の余地があり、より優れた予測モデルを特許庁のイメージサーチツールに採用するために本コンペが開催されました。
本コンペは、特許庁から提供される実際に商標審査に用いる画像データをもとに、大量に存在する図形商標から正解(類似)画像を予測するAIモデルの開発を行い、その精度を競うものです。概要は以下の通りです。
- 開催期間: 2021/11/26 〜 2022/1/31
- 参加: 641人 投稿(submission数): 1,537件
- データセット
- 特許庁が提供する約80万枚の商標画像検索用データセット
- 実際に審査される商標画像の実データおよび審査官による審査結果の正解データから成る
- 評価方法
- クエリに対する検索結果のRecall@20
- Recall@20が同一の場合にはMRR
- Recall@20もMRRも同一の場合には検索速度がより速いものを上位とする
- モデル実行環境
- vCPU8コア、32GBメモリ、1TBストレージ、Tesla T4 GPUx1
- 実行環境で、画像一枚の検索処理を8秒以内に完了すること
コンペの結果
最終スコア 0.734111(Recall@20)で優勝しました(チーム名 tmsbir)。

(画像はAI×商標:イメージサーチコンペティション(類似商標画像の検出)の最終ランキングを元に作成)
今回開発したAIモデルは、特許庁が試験的に導入している先行図形商標検索ツール(イメージサーチツール)への搭載も検討される予定です。
基本的なアプローチ(類似画像検索について)
本コンペで取り組む内容はクエリ画像に対して、約80万枚の商標画像の中から類似しているものを探し出すという類似画像検索のタスクです。
類似画像検索では、まず対象となる画像をベクトル化し、そのベクトル同士の類似度(ユークリッド距離やコサイン類似度)に基づいて類似画像を検索することが一般的です。 本記事では、類似画像検索についての基本的な説明は割愛しますが、詳細を知りたい方は以前のYahoo! JAPAN Tech Blog記事などで類似画像検索のイメージを図解していますので参考にご覧頂ければと思います。
- Tech Blog記事: 出品をもっと手軽に 〜 ヤフオク!の出品時タイトル推薦機能の裏側
- 発表スライド: ヤフオク!における出品時タイトル推薦機能の裏側 / YJTC19 in Shibuya A-2 #yjtc
ソリューション概要
最終的に提出した解法は、5つのモデルをアンサンブルして抽出した画像特徴ベクトルを利用し、近似最近傍探索により類似画像を検索するものです。
最終的な検索モデルの概要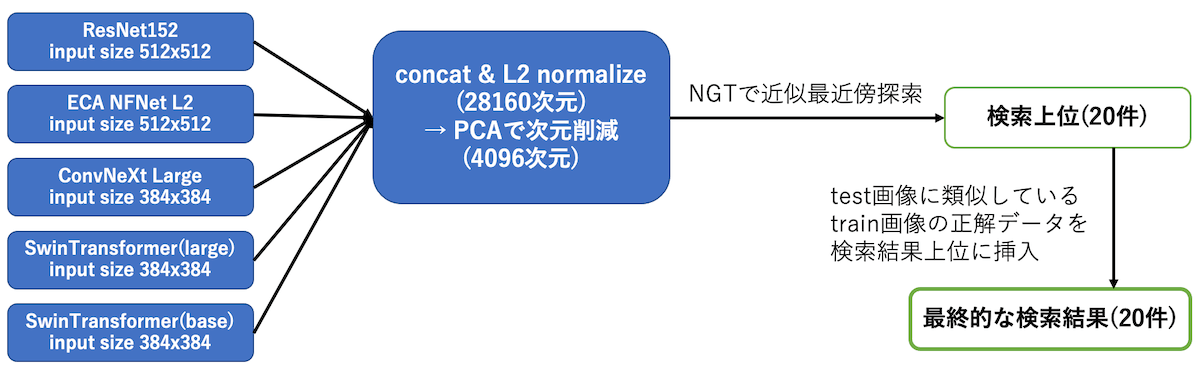
以降では、本コンペへの取り組みの流れも含めて詳細を説明していきます。
データセットの正解ラベルの修正
本コンペのデータセットは画像検索用データセットとして整備されたものですが、各クエリ画像に対する正解データが1枚のみとなっています。しかし、クエリ画像に類似している画像が実際に1枚しか存在しないというわけではなく、よく似た画像が複数枚ある場合にも1枚のみ正解画像が設定されています。これは、本コンペのデータセットが特許庁の審査官が審査結果に掲載した類似商標画像を正解データとすることで整備されたことによるものです。(現実的には、似ている画像をすべて列挙することは確認作業が膨大になるため難しい)
コンペの評価自体は、クエリに対して1枚のみ設定された正解データに基づいて評価されますが、モデルを学習する際に実際にはよく似ている画像を不正解として学習するのは悪影響が大きいと思われます。 上記を踏まえて、モデル開発の前に、まずはデータセットの正解ラベルの修正に取り組みました。
画像をグループ化し同一グループの画像を正解画像とする
データセットは検索クエリとなる出願画像(以降trainまたはtestとする)と約80万枚の引用画像(以降citeとする)から構成されており、train画像に対してのみ正解データとして類似しているcite画像が1枚設定されています。(testについては画像のみ)
まず、train全体およびcite全体のそれぞれに対して、画像のphash値を計算し、似ている画像(phashが近いもの)をグループにします。さらに、trainの正解ラベル(画像1対1のペア)を元にtrain全体、cite全体の中でグループ同士をマージしていき、最終的にできあがったグループを学習に利用するラベルとします。
データのグループ化とマージのイメージ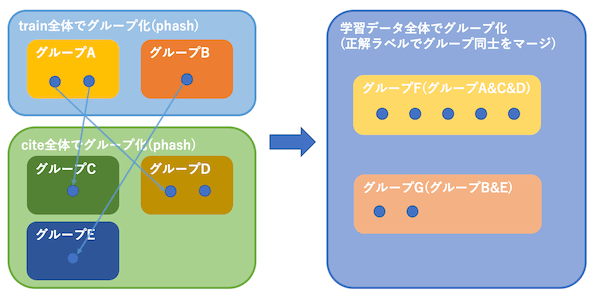
(誤検出を減らすため、phashは通常の64bitではなく576bitの値を計算し、ハミング距離が64未満になる画像をグループにします)
評価指標の変更
本コンペの評価指標はRecall@20ですが、新たなラベルで正解データが1枚のみではなくなるため、正解データを上位に予測するほど評価が良くなる指標を採用するほうが良いと考えたため、mAP(mean Average Precision)をモデルの評価指標として利用することとしました。
Cross Validation
新たに生成したラベルをもとにGroupKFoldでデータを分割して5fold Cross Validationでモデルを学習します。 計6,000iteration学習し、100iterationごとにcite画像から20%サンプリングした画像をindexとして類似画像を検索し、新たなラベルにおけるmAP@100を評価指標としてベストモデルを選択しました。(20%サンプリングは計算時間削減のためです。)
Loss
モデルはDeep Metric Learningで学習し、すべてのモデルでMultiSimilarityLossを利用しています。ContrastiveLossもパラメータを変えていくつか試しましたが、一貫してMultiSimilarityLossのほうが良好な精度でした。 Pytorch Metric LearningのMultiSimilarityLossの実装を利用し、パラメータは以下のとおりです。
alpha=2, beta=50, base=0.5
モデル
下記の5つのモデルをDeep Metric Learningで学習し、アンサンブルして利用しました。
- resnet152d
- eca_nfnet_l2
- convnext_large
- swin_large
- swin_base
実装はPyTorch Image Models (timm)を利用しており、各モデルのpooling層とクラス分類層を外してbackboneとして利用しています。 モデル全体の構造は以下の通りです。
CNN系モデル (convnext_large, eca_nfnet_l2, resnet152d)
(下図はeca_nfnet_l2の例)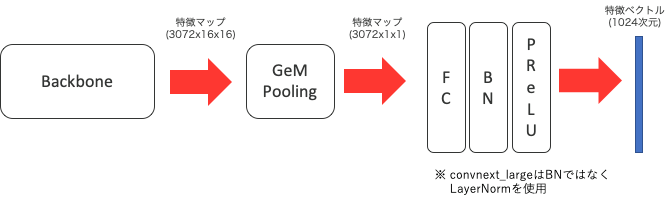
ViT系モデル (swin_large, swin_base)
(下図はswin_largeの例)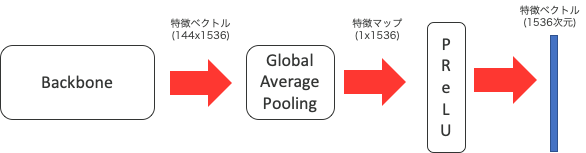
各モデルの詳細は以下の通りです。(括弧内は出力特徴ベクトルの次元数)
- resnet152d
- backbone → GeM(p=3) → FC → BN → PReLU (1,024次元)
- eca_nfnet_l2
- backbone → GeM(p=3) → FC → BN → PReLU (1,024次元)
- convnext_large
- backbone → GeM(p=3) → FC → LayerNorm → PReLU (1,024次元)
- swin_large
- backbone → GAP → PReLU (1,536次元)
- swin_base
- backbone → GAP → PReLU (1,024次元)
コンペ開始当初から基本的なモデル構造は上記のとおりで、resnet34dなどのbackboneで検証を行っていました。出力特徴ベクトルの次元数については、当初は256次元や512次元としていたものの、1,024次元や1,536次元に増やすことでスコアの改善がみられたため、この値を採用しています。
Batch Samplingの工夫
データセットにおけるcite画像の割合が非常に多い(約80万枚)ため、ランダムサンプルでDeep Metric Learningをすると、バッチ内のポジティブペアが極端に少なくなるため、学習時のBatchの作り方を工夫しています。
事前に、データセット全体をtrain画像(trainとラベルが同じならcite画像もtrainに含める)と残りのcite画像に分けておき、バッチ生成時には、バッチサイズにおけるtrain画像の割合およびラベルごとの画像枚数を指定可能なsamplerを実装しました。 いくつか設定を試したところ、train画像の割合をバッチサイズの50%とし、train画像についてはラベルごとに2サンプル、cite画像についてはラベルごとに1サンプルを1つのバッチに入れる設定が良好な精度でした。

例えば、バッチサイズが64の場合には、32枚のtrain画像(16ラベルでラベルごとに2枚の画像)と、32枚のcite画像(32ラベルでラベルごとに1枚の画像)で構成されます。
モデル学習時の設定
ハイパーパラメータ
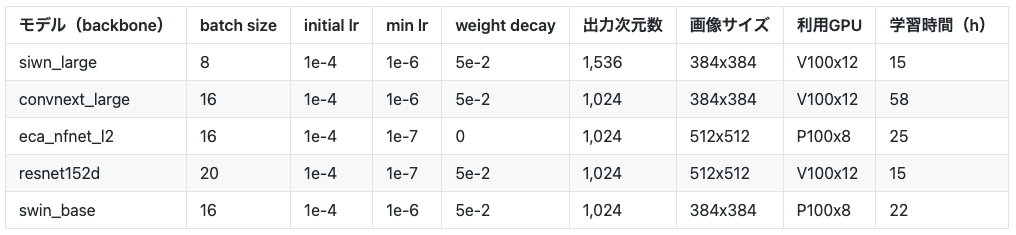
各モデルの学習時のハイパーパラメータの設定は以下の通りです。
共通設定
- Horovodによる分散学習(GPU数はモデルにより異なる)
- 6,000イテレーション学習(100イテレーションを1epochとして60epoch)
- LR調整: LinearWarmupCosineAnnealing(warmup=3, epoch=60)
- Optimizer: FusedLAMB
- CrossBatchMemory)(memory_size=2048)を利用
モデルごとの設定
データ拡張
データ拡張の設定は以下のとおりです。
- train時
- 画像が正方形になるように白い余白をpadding
- HorizontalFlip
- ColorJitter
- ShifScaleRotate
- RandomResizedCrop
- ImageCompression
- Downscale
- RandomGrayScale
- ランダムに余白を除去した画像に入れ替え(50%)
- test時
- 画像が正方形になるように白い余白をpadding (のみ)
検索結果の可視化と後処理の導入
baselineとなるモデルをいくつか学習した後に、モデルの検索結果を可視化して確認できるデモアプリケーションを実装しました。
このデモでtrainデータをクエリとして検索した結果を観察していると、正解データの画像以上に見た目が類似している画像が多数あり、結果的に正解ラベルが上位20件から漏れてしまっていることが多くありました。(コンペの評価指標はRecall@20で正解は1件だけのため、正解画像が20件以内に含まれていないとスコアは0になってしまう)また、モデルをアンサンブルすることで、実際に似ている画像がより上位に集まることで結果的に不正解となる場合が多くなる傾向が見られました。 一方、各モデルのローカルでのcross validationのスコアと実際にsubmissionしたスコアの相関については、モデルサイズが大きくなるほど、アンサンブルするモデル数を増やすほど、相関がなくなる傾向がありました。この傾向は、デモアプリで確認できるように正解ではないが類似している画像をより多く検索できることで、結果的に1枚だけの正解画像を上位20件から落としてしまう事例が増えているのだろうと推測しました。
この問題を回避するために、クエリ画像(test)に類似しているtrain画像を検索し、ある程度似ている(コサイン類似度0.95以上)train画像が存在した場合には、その正解画像を予測結果に追加する後処理を試してみたところ、testデータのスコアが改善するとともに、ローカルのCVスコアとも相関するようになりました。
最終的には、クエリ画像とのコサイン類似度が0.5以上のtrain画像(最大10件まで)の正解画像を予測に含めています。 この後処理のみで、最終スコアが 0.679636 から 0.734111 へ約5pt程度改善します。
※ デモで確認する限りは、後処理を実施しないほうが、見た目としては自然な検索結果になります。
PCAによる特徴ベクトルの次元削減
最終的に5foldx5モデルの計25モデルをアンサンブルする場合、特徴ベクトルをconcatすると28,160次元となり、コンペ実行環境のメモリに収まらない問題が発生するため、PCAによる特徴ベクトルの次元削減を行いました。
各モデルの特徴ベクトルをnormalizeしてconcatし再度normalizeして28,160次元になった特徴ベクトルをPCAで4,096次元まで削減し、さらにnormalizeしたものを最終的な特徴ベクトルとし、この特徴ベクトルのコサイン類似度を商標画像の類似度として類似商標の検索を行います。 28,160次元のまま検索した場合と、PCAで4,096次元まで削減後に検索した場合を比較しましたが、PCAのほうが少しだけスコアが良い結果(計算過程における誤差などで偶然正解が増えた?)となり、スコアへの影響はなさそうでした。
NGTによる検索処理
特徴ベクトルのコサイン類似度計算はGPU上であれば高速に処理可能ですが、計25個のモデルをGPUに読み込んだ状態でTesla T4の16GBメモリのうち14GBを消費します。
検索対象のcite画像約80万枚分の特徴ベクトル(4,096次元、float32の場合)は約12GBで、GPUメモリ上に25個のモデルと一緒には載せられません。 残りの約2GBのGPUメモリを利用し、特徴ベクトルを分割しGPU上で検索することは可能ですが、逐次GPUに転送する処理のoverheadで規定の処理時間内(8秒以内)に検索できませんでした。そのため、事前にNGT(ヤフーがOSSとしても公開している近似近傍検索ソフトウェア)のindex(ONNG)を作成し、CPU上で検索処理を行う構成としました。
コンペのルールで定められている、8コア、32GBメモリ、Tesla T4環境で処理時間を計測した結果、画像一枚あたりのトータルの処理時間は平均で2.13secでした。
後処理の効き具合
後処理としてtest画像に似ているtrain画像を検索し、その正解画像も予測に含める処理を行っていますが、どの程度似ているtrain画像を対象にするかで大きくスコアが変動します。trainの検索結果を定性的にみると、正解データよりも似ていると思わる引用画像が多数あり、これらの画像が検索結果を占め、結果的に正解データの順位を下げていると思わます。
下表が閾値ごとのスコアをまとめたものです。
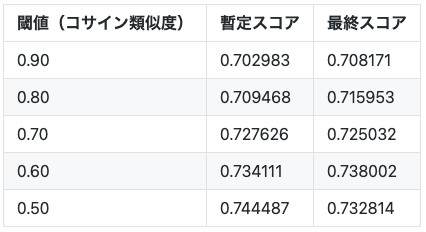
※ 最終モデルとは異なる組み合わせの5モデルアンサンブルの結果です
効果の得られなかった工夫について
データセットの正解ラベルの修正手順において、phashで画像をグループ化するのではなく、学習済みモデルで抽出した特徴ベクトルの類似度(コサイン類似度)で画像をグループ化した場合についても検証してみましたが、良い結果は得られませんでした。
検証条件
- phashによるグループ化
- 576bitのphash値のハミング距離が64未満になる画像をグループ化
- 画像特徴ベクトルによるグループ化
- コンペ中盤時点で最も暫定スコアが良かった3つのモデルのアンサンブルで抽出した特徴ベクトルを利用
- コサイン類似度が0.90以上、0.98以上、0.99以上の3パターンでグループ化
- backboneモデルにはresnet152dを利用
- 後処理の閾値は0.90で統一
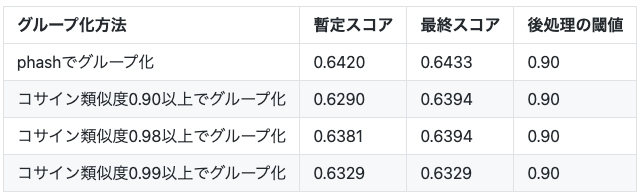
phashでグループ化した場合の結果が暫定スコア、最終スコアともに良好な結果でした。
生成されたラベルを可視化して定性的に評価する限りはphashによるグループ化よりもコサイン類似度によるグループ化の結果のほうが良好に感じました。また、検索結果を可視化して比較してみた感触としても類似画像の検索性能としては、コサイン類似度によりグループ化したラベルで学習したモデルのほうが良好な感触でした。
phashのほうが良いスコアになる要因としては、今回提供された学習データセットが実際の審査結果を元に作成されたものであるため、正解データが純粋な画像の類似度とは異なるバイアスを含んでいるのではないかと考えられます。
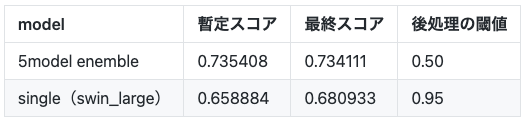
シングルモデルのスコア
モデルアンサンブルせず、swin_largeのみでsubmitした場合のスコアも確認しています。後処理の閾値が違うため直接比較はできないですが、ベストスコアに対して9割以上のスコアを出すことができます。(閾値をそろえるとまだ改善すると思われる)
おわりに
本記事では、特許庁主催、Nishika株式会社開催の「AIx商標イメージサーチコンペティション」の優勝解法の詳細を紹介しました。本記事の内容が、他の類似画像検索などのコンペに取り組む際の参考になれば幸いです。
コンペ終了から本記事の公開までかなり時間が空いてしまいましたが、改めまして、運営・ホストのみなさまコンペの開催ありがとうございました。また、コンペに参加されたみなさまもお疲れさまでした。
私の所属する画像処理チームでは、本記事で紹介した類似画像検索に関する技術にとどまらず、社内のさまざまなサービスと連携しながら、コンピュータビジョン、画像認識領域の技術開発や応用に取り組んでいます。 現在、弊チームの機械学習エンジニアのポジションを募集しておりますので、ご興味がありましたら、ぜひご応募ください。
References(外部サイト)
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 土井 賢治
- テクノロジーグループ サイエンス統括本部 機械学習エンジニア
- 社内のさまざまなサービスと連携しながら画像認識領域の技術開発や応用に取り組んでいます。
-