こんにちは。ヤフーでデータサイエンスを担当している山本です。今回はYahoo! JAPAN研究所の清水伸幸、サイエンス部門の松廣達也、山本康生、半熟仮想株式会社の清原明加氏(東工大)、齋藤優太氏(コーネル大学)、成田悠輔氏(イェール大学)による共著論文で、Webデータマイニングのトップカンファレンス「WSDM 2022」の本会議に採択された内容をお伝えします。
※この記事で取り扱っているデータは、プライバシーポリシーの範囲内で取得したデータを個人が特定できない状態に加工しています。
1.共同研究の概要とWSDMについて
Yahoo! JAPAN研究所は日本国内最大規模の利用者を誇るヤフーのサービスの課題解決に日々取り組んでいます。そのひとつに外部研究機関と協力関係を作り、新たなイノベーションを生み出す共同研究があります。
本記事で紹介する論文はその成果である、因果推論領域を中心に研究活動している半熟仮想株式会社の方々との共著論文です。
今回論文が採択されたWSDMはWebデータマイニングのトップカンファレンスに位置付けられ、2022年で第15回の開催です。また、今年の採択率は20.23%と、非常に完成度の高い研究が求められる権威ある国際会議です。
2.研究内容とヤフーの課題
皆さんは日々いたるところでリコメンデーション・検索に触れていると思います。多くのリコメンデーション・検索は、AI(人工知能)や機械学習を利用し、ユーザーごとにアイテムとよばれる商品やコンテンツの順位付けをします。皆さんがYahoo! JAPANで検索をしたときの検索結果をイメージしてもらうとわかりやすいかと思います。これを「ランキング推薦」とよびます。私たちの研究は、このランキング推薦に用いられるモデルの正確な性能評価が目標です。
ところで、モデルの正確な性能評価とは一体どんなものだと思いますか? それは、モデルがユーザーの行動にどのような影響を与えたか、その原因と結果を解析的に求めることです。このようなアプローチを「因果推論(および効果検証)による評価方法」といいます。
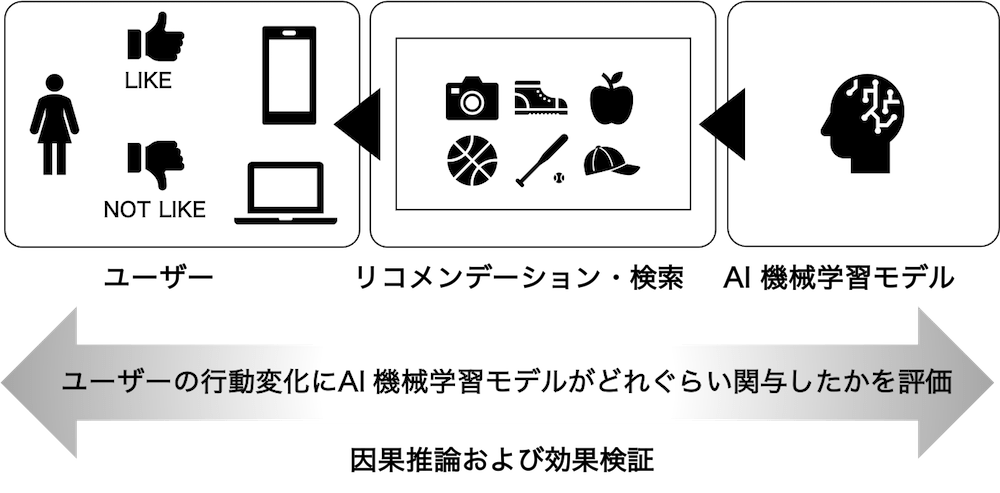
因果推論が重要であることを理解いただくために、ヤフーのサービスでどのようなことが行われているかを見てみましょう。私たちが手がけるAIや機械学習のモデルは、あるユーザーにとってそのアイテムが好ましいか・好ましくないかを、その他の外的要因を排除した独立した環境を想定して予測します。

しかし、実際にアイテムをユーザーに提案するとき、さまざまな外的要因の影響を受けます。以下の図は、Yahoo!ショッピングの検索結果画面の様子です。ご覧の通り、単に対象アイテムをユーザーが好むか・好まないかを決める場面に多くの外的要因が存在します。
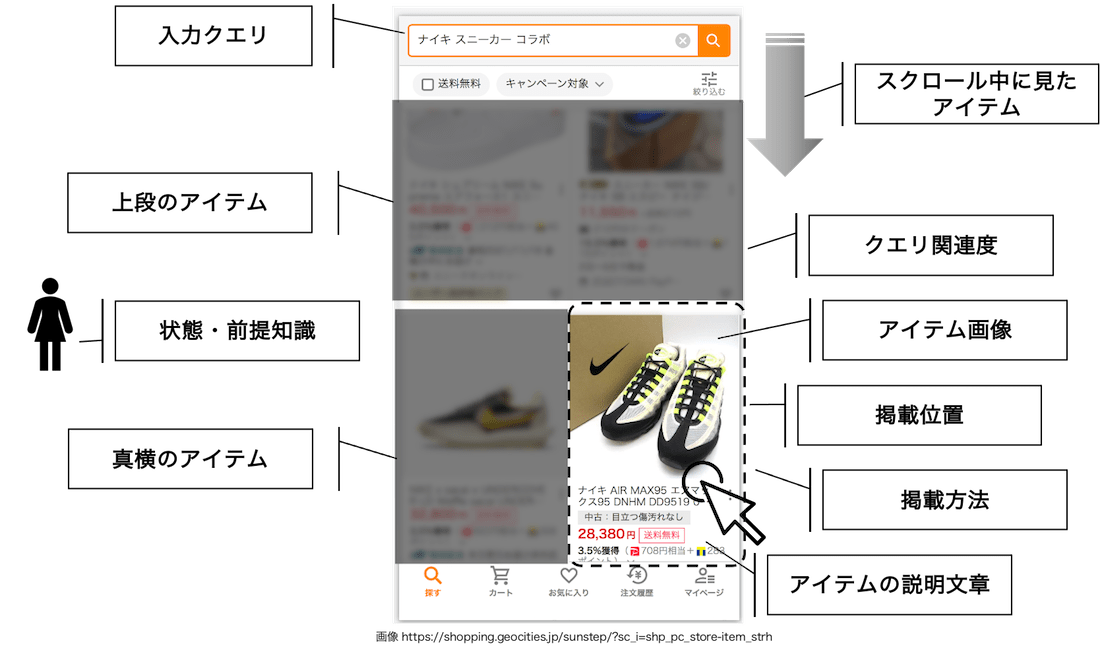
先にも述べましたが、これまでのAIや機械学習のモデルの評価は、さまざまな外的要因を受けないものと仮定し、評価されてきました。しかし、ユーザーがアイテムをクリックするとき、そのアイテムのことしか考えていないというのはやはり現実的ではありません。
本共同研究テーマである因果推論の領域では、実環境におけるこれらさまざまな外的要因の存在を考慮してモデルの正確な評価を試みます。
今回紹介する論文では因果推論手法の中でも「オフ方策評価(Off-Policy Evaluation; OPE)」という技術を用い、外的要因を考慮したモデルの評価を行います[1]。特に、複数のアイテムを同時に推薦した際にユーザーがアイテムを閲覧する順番に着目することで、これまでより正確な性能評価をより少量のデータを用いて行う方法を提案しています。
3.A/Bテストとオフ方策評価
新しくAIや機械学習のモデルを作成したとき、そのモデルの正確な性能評価をするには、前章のとおり、結果に影響を与えうる外的要因を考慮する必要があります。では、どうすればこれらの外的要因を考慮してモデルを評価できるのでしょうか?
複雑な実環境と同様の外的要因を人工的に再現することは多くの場合困難です。そこでリコメンデーション・検索では、モデルの評価のためにA/Bテストと呼ばれるオンライン実験を行います。A/Bテストでは、モデルaとモデルbの性能を評価したい場合、一定期間、実環境においてランダムに割り当てられたユーザーにモデルを適用し、そのフィードバック(クリックなど)を比較します。これにより、同じ外的要因が存在する状況でモデルaとモデルbの性能比較を実現します。

私たちヤフーを含む多くの企業が、そのサービスや商品を改善するためにA/Bテストをしています。しかし、A/Bテストは実際の環境下で実験をするわけですから、その準備や試したときの失敗が直接ユーザーに影響を与え、ひいてはビジネス毀損(きそん)も起こり得ます。すなわち、A/Bテストはコストが非常に大きい方法です。そこで、仮想的に実環境と同じ外的要因が発生する実環境を再現できる方法はないのだろうか? という要望が出ます。その要望に答える方法として注目を集めているのが、オフ方策評価です。
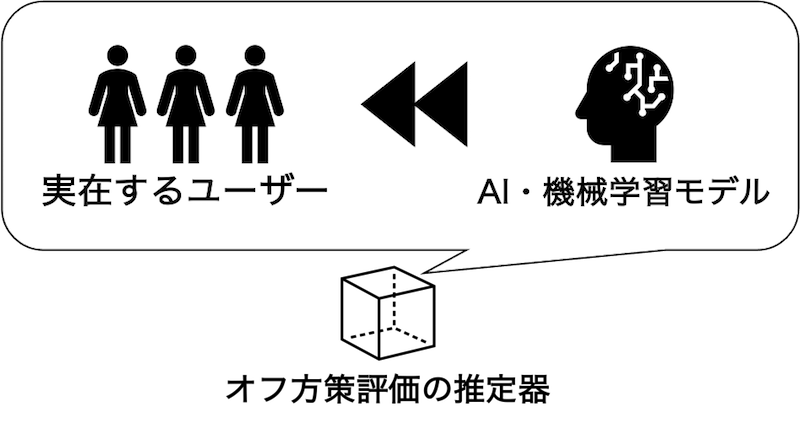
オフ方策評価では、これまでにリコメンデーション・検索に使われていた過去のモデルが集めたログデータを使って、まだ利用実績のないモデルを評価します。オフ方策評価は実環境でモデルを動かすことなくモデルの評価できます。そのため、オフ方策評価はA/Bテストと比べ、ユーザーへの影響をはじめとするコストを大幅に下げられます[2]。
一方で、オフ方策評価にも課題はあります。それは、A/Bテストに比べてモデルの性能推定の正確さ(精度)が劣ってしまうことです。これは、オフ方策評価では新たなモデルを評価するときに、過去に別のモデルが集めたデータしか使えないことに起因しています。この課題を軽減し、データからより正確なモデルの評価を行うため、多くの企業や研究者が新しい「推定器(estimator)」と呼ばれるものの開発に取り組んでいます。
4.Cascade-DR
以降の章では、前述のA/Bテストに比べてモデルの性能推定の正確さ(精度)が劣ってしまうという課題を解決するために私たちが提案した、「Cascade Doubly Robust(Cascade-DR)」という推定器についてご紹介します。今回は、幅広い読者の皆さんに研究を知っていただきたいので、数式や緻密な人工データ実験の結果を省いています。もし本研究の詳細に興味を持たれたがいらっしゃれば、論文をご参照ください。
4-1.オフ方策評価の目標
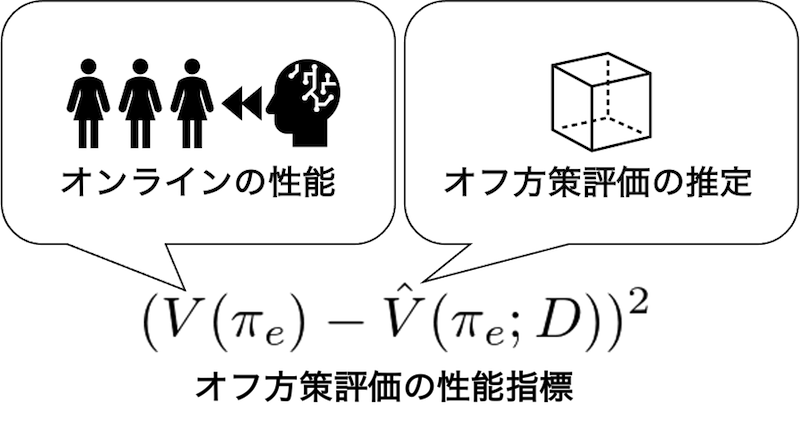
私たちの研究では、複数のアイテムを同時に推薦するときのオフ方策評価をあつかいます。ここでは、あるアイテムを評価するときに結果に影響を及ぼす外的要因は同時に推薦された他のアイテムです。精度の高い推定器を作るため、以下で定義される、オンラインで測ることのできる真の性能と、オフ方策評価の推定器の推定性能の差(二乗誤差)を小さくすることを試みます。
4-2.バイアスとバリアンス
真の性能と推定性能の間の二乗誤差を小さくするには、バイアスとバリアンスと呼ばれる二つの要素をバランスよく小さくすることが必要です。
「バイアス」は、外的要因をうまく考慮できていないことで発生する推定器の推定誤差のことをいいます。バイアスは外的要因(ここでは同時に推薦されたその他のアイテムの組み合わせ)ごとのデータの場合分けが不十分な場合、本当は異なるデータをひとまとめにしてしまうことで発生するので、たとえデータの数を増やしたとしても、解決はできません。
では、可能な限り他のアイテムの組み合わせを考慮してデータを分割して区別するようにすれば、推定器の推定誤差は小さくできるのでしょうか? この場合、確かにバイアスは下げられますが、一つ一つの分割で使えるデータの数が少なくなってしまうので、性能推定の安定さを欠きます。つまり、データの中で観測されるアイテムの組み合わせが少し変わっただけで、性能推定の結果が大きく変化してしまうのです。この現象は「バリアンス」といいます。
データ数を増やせばバリアンスの影響は小さくなります。しかし、膨大な数の組み合わせが発生する複数のアイテムを同時に推薦する場面においては、バリアンスを十分に小さくしうるのに必要なデータ数を集めることは、容易ではありません。
一般的にバイアスとバリアンスの間には、一方を下げれば一方が上がる「トレードオフの関係」が成り立ちます。そのため、良い推定器を作るには、このバイアス・バリアンスのちょうど良いバランスを達成することが必要です。

4-3.これまでの推定器
既存研究では、複数のアイテムを同時に推薦したときユーザーがどのようにアイテムを閲覧するか? というユーザー行動に仮定をおくことで、バイアス・バリアンスのトレードオフを調整します。
4-3-1.ユーザー行動に強い仮定をもつ推定器
Independent Inverse Propensity Scoring(IIPS)[3] は、クリックなどのユーザーのフィードバックが同時に推薦されたその他のアイテムの影響を受けず独立して得られるものと仮定します。すなわち、IIPSは以下図のように、ユーザーはそのアイテムのみしか考慮せず、近接するアイテムやより上位に表示されたアイテムの影響を全く受けないという非常強い仮定をおいています。この強い仮定により、IIPSはデータの分割が少ない分バイアスが大きくなります。一方で、アイテムごとにデータが集計できるのでバリアンスは小さくなります。
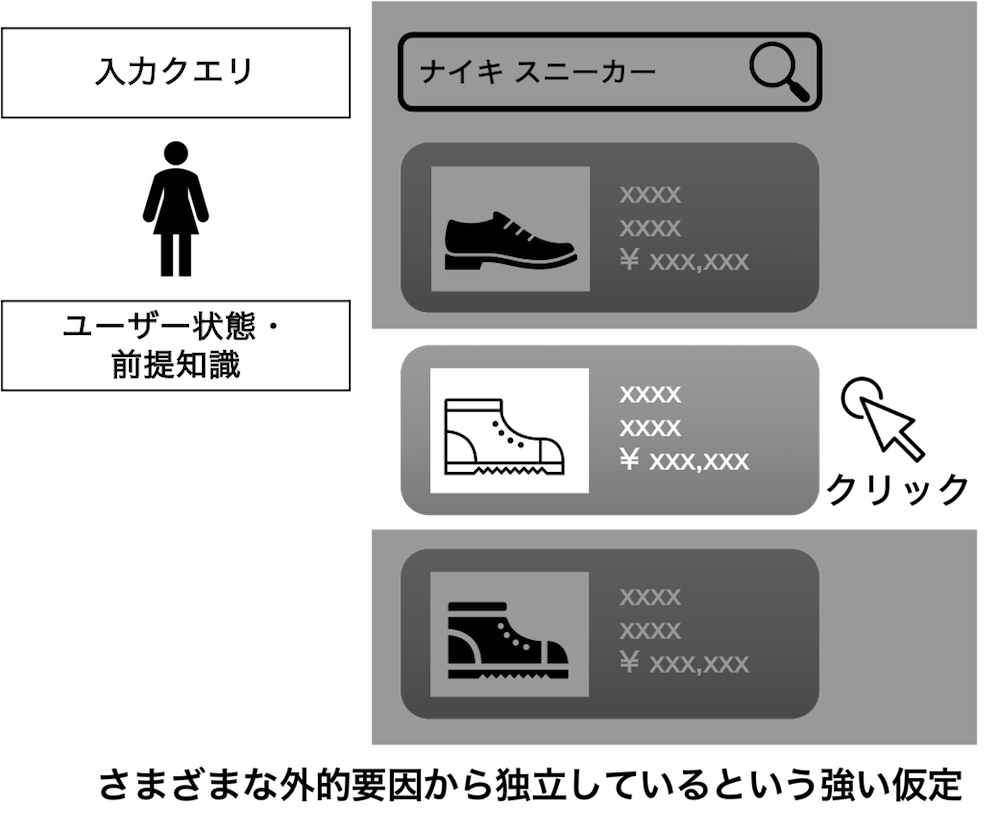
4-3-2.ユーザー行動の仮定をもたない推定器
Inverse Propensity Scoring(IPS)[4, 5] は、IIPSとは反対の発想で、クリックなどユーザーフィードバックが同時に推薦されたその他のアイテムの影響をすべて受けて得られるものと仮定します。これはユーザー行動のあらゆる可能性を受け入れるので、推定器は同時に推薦されるアイテムの組み合わせを完全に場合分けして考慮できます。そのため、IPSはIIPSで困っていたバイアスをなくすことができます。しかし、今度は場合分けした分割ごとに集められるデータが非常に小さくなってしまうため、バリアンスは大きくなります。
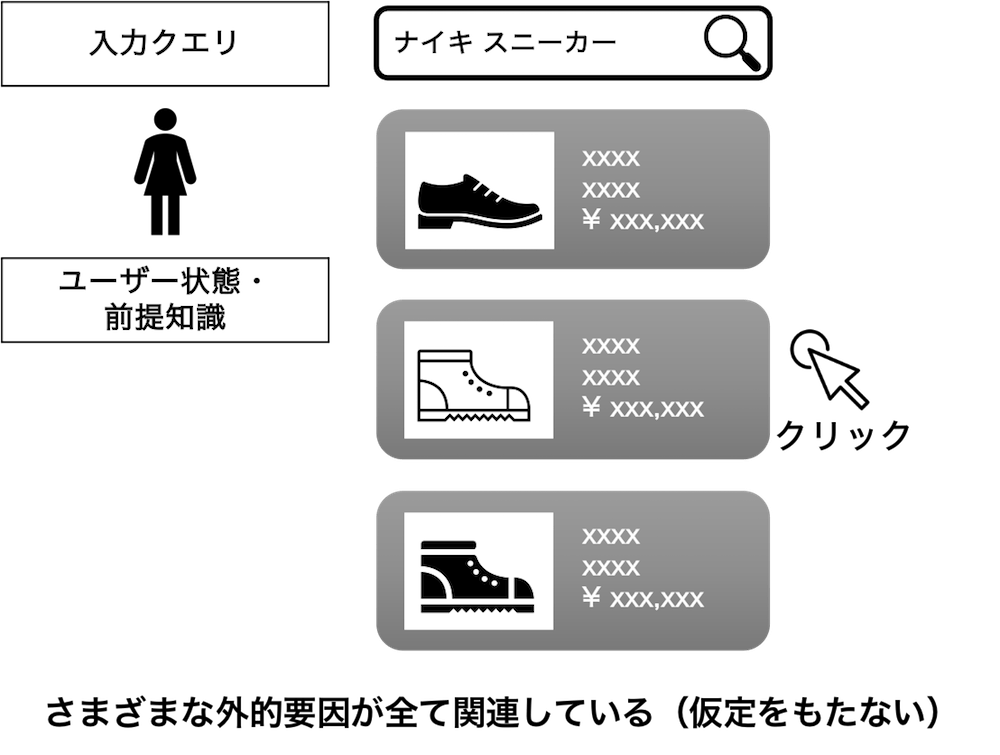
4-3-3.ユーザー行動に順序性の仮定をもつ推定器
Reward interaction Inverse Propensity Scoring(RIPS)[6] は、ユーザー行動が画面に表示されたアイテムを上から順番に閲覧するという仮定をおきます。これは「Cascade仮定」(*注釈)と呼ばれる仮定で、スマートフォンで検索結果を上から順番に閲覧していくことを思い浮かべると理解できるように、現実的な仮定です。RIPSはこの現実的なCascade仮定により、IIPSと比べて大幅にバイアスを減らすことができ、さらにIPSと比べるとバリアンスを減少させられます。しかし、とくに同時に推薦するアイテムの数が多いときには、バリアンスが大きくなってしまうのがRIPSの課題です。
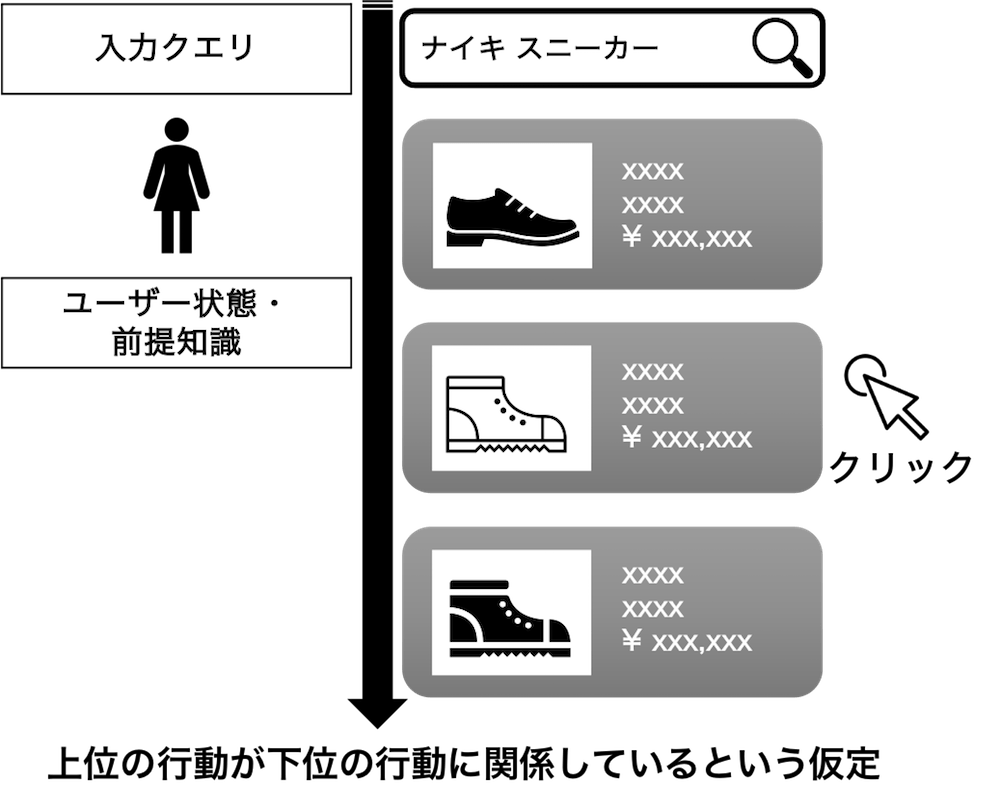
4-4.わたしたちのアイデア
本研究の提案手法は、既存手法と比べて、より良いバイアス・バリアンス・トレードオフを達成します。具体的には、RIPSと同じCascade仮定に基づくバイアスを実現するためIIPSよりもバイアスが小さく、同じCascade仮定や仮定を置かない場合のIPSやRIPSよりバリアンスを小さくします。どのようなアイデアなのか、私たちがどのようにそのアイデアを生み出したのかについてご紹介します。
Cascade仮定はユーザーがアイテムを上から順番に閲覧する仮定でした。RIPSはこの仮定にもとづき、各アイテムの報酬(クリック)がより上位に表示されたアイテムの影響をうける、として各アイテムのクリックをモデル化し、そのクリックを集計することで同時に推薦された複数のアイテム全体での報酬を推定していました。
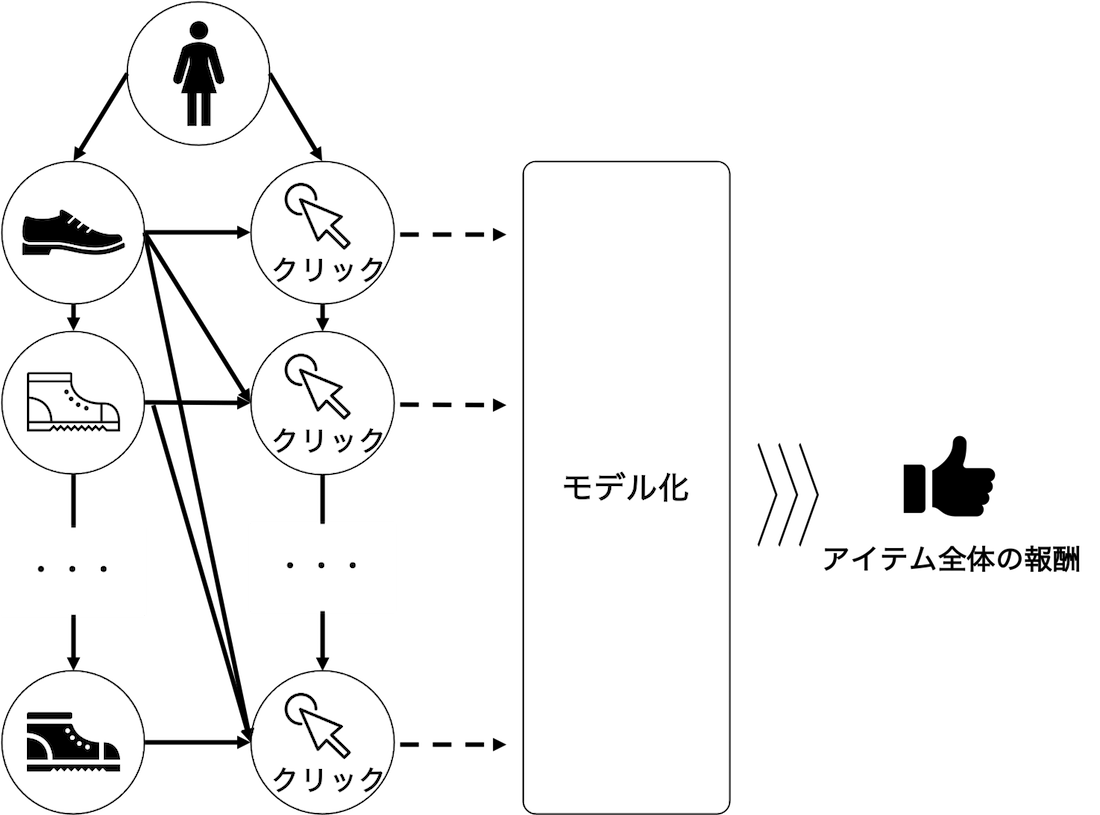
ここで少し見方を変えて、あるアイテムが他のアイテムから影響を受ける関係から、あるアイテムが他のアイテムに影響を与える関係に置き換えて関係性を再定義してみます。
すると、RIPSについてあるアイテムが他のアイテムに与える影響度をモデル化した上で、同時に推薦された複数のアイテムの影響度をもとに性能を推定していると少し違う角度から見ることができます。
たとえば、2つのアイテムを同時に推薦する状況を考えてみます。この場合、下のアイテムは上のアイテムの影響を受けた、ということもできるし、上のアイテムが下のアイテムに影響を与えた、とも言えるわけです。
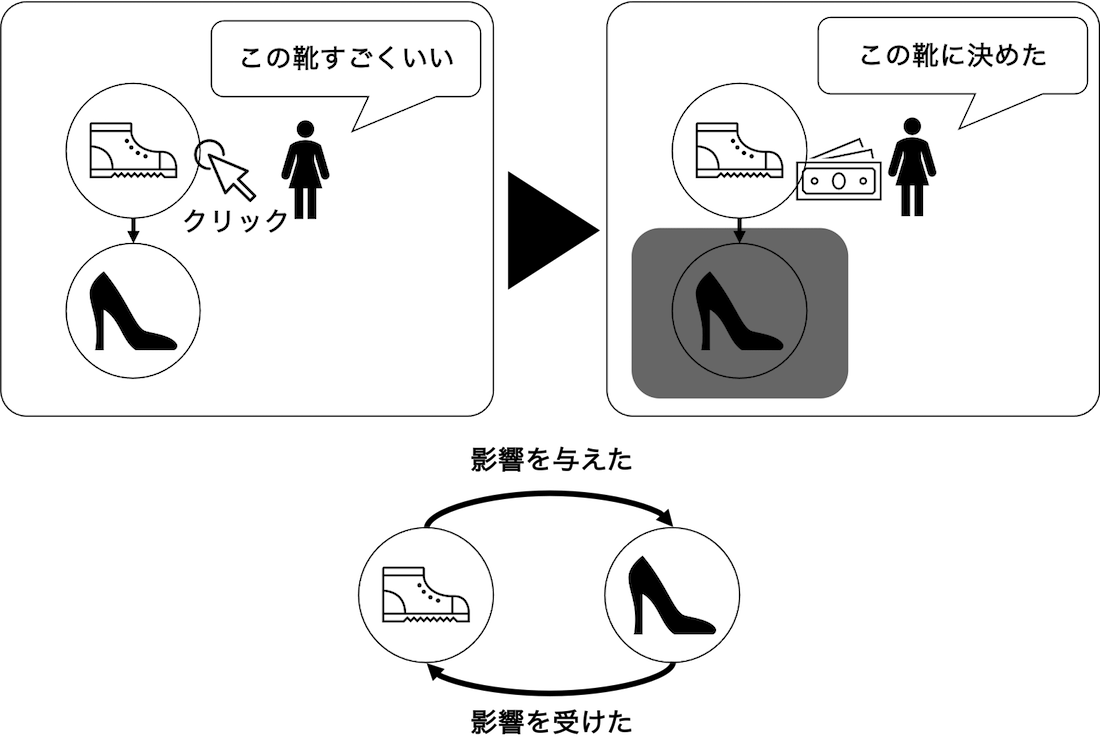
このとき、RIPSはあるアイテムより後に表示されたアイテムの組み合わせを細かく分割することで、そのアイテムの影響度をデータから推定しています。そのため、同時に推薦されたアイテムの個数が多いときには、一つの分割あたりのデータ数が少なくなってしまう傾向があり、これがRIPSのもつバリアンスが大きい原因になっていました。
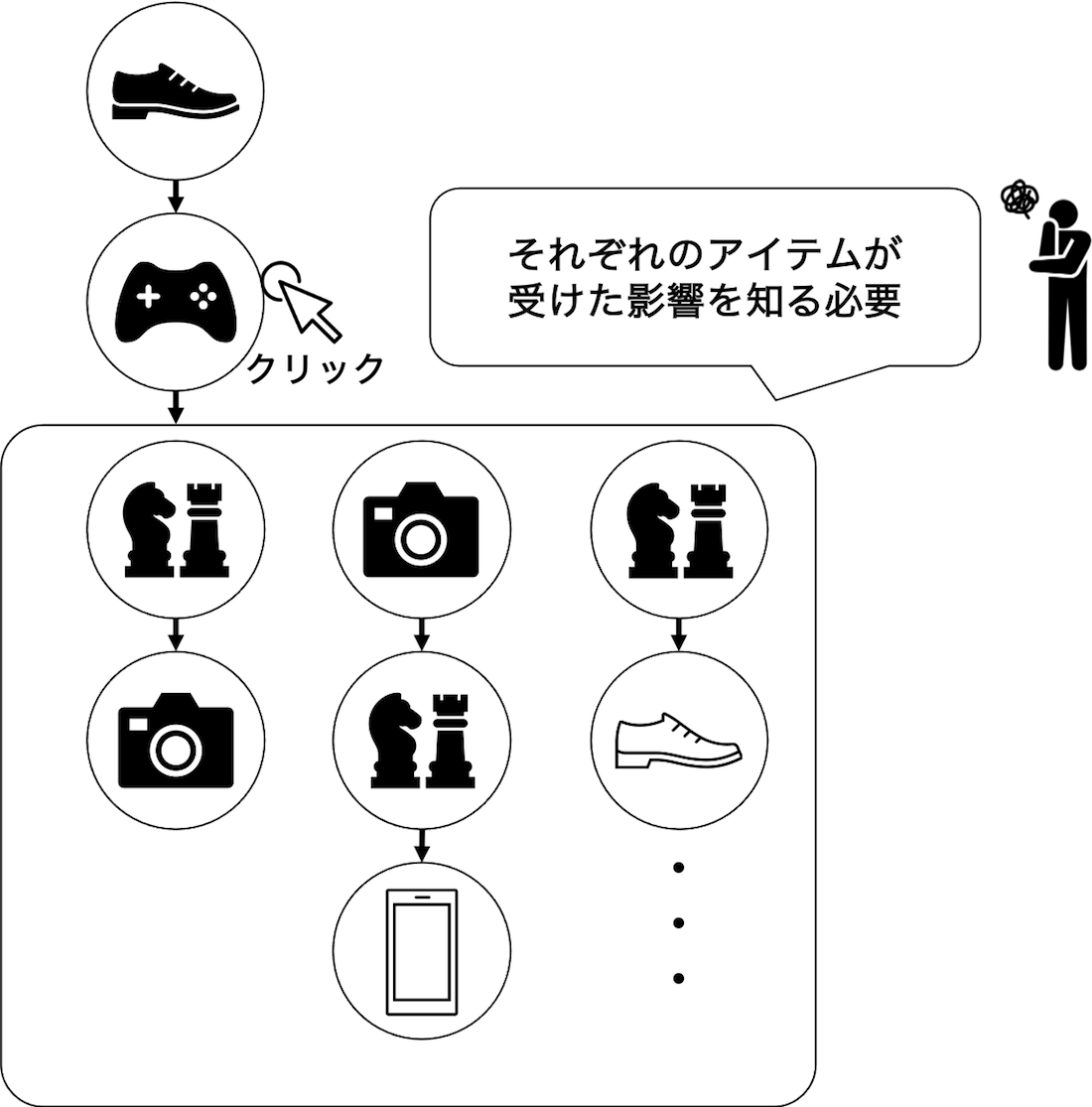
Cascade-DRでは、あるアイテムの影響力を機械学習の予測器で予測しデータ拡張を行います。これにより、擬似的に性能推定に使えるデータを増やせるので、RIPSのバリアンスの問題を軽減できます。
さらに、私たちの提案手法では単に機械学習モデルの予測を使うだけでなく、観測されたデータを用いて機械学習で予測したデータの予測誤差の補正も行っています。この予測誤差の補正を入れることで、Cascade-DRはRIPSと同じCascade仮定に基づくバイアスを実現できます。
結果として、Cascade-DRはRIPSと同じバイアスを実現しつつ、RIPSよりさらにバリアンスを小さくできるというわけです。

5.ヤフーのデータを用いた実験
最後に、私たちの提案したCascade-DRが本当に既存研究より良いバイアス・バリアンス・トレードオフを実現し、性能推定の精度を向上できているかを紹介します。今回の実験では、以下のようなヤフーの検索結果に表示される関連モジュールのランキング推薦のデータで評価を行いました。
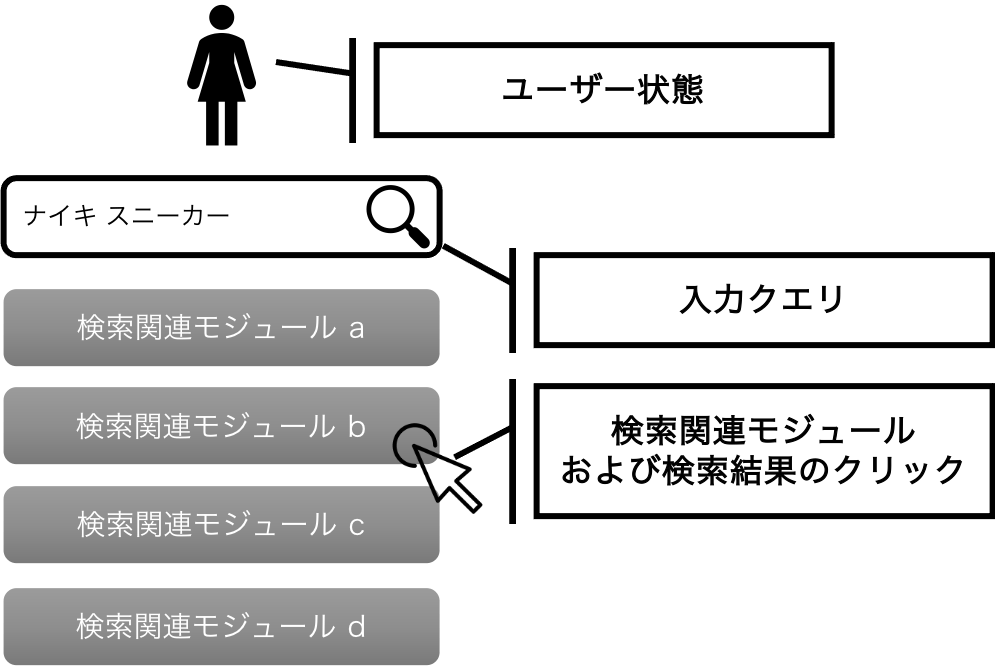
結果を表す図は少しずつデータの構成を変えた20回分の実験結果をもとに、その分布を「箱ひげ図」で表現しています。ここでは評価指標を二乗誤差としているため、数値が小さければ小さいほど精度が良いことを表しています。これを見ると、Cascade-DRが既存手法と比較し全体的に高性能であることが見て取れます。

先にも触れましたが、論文では人工データを用いた実験も行い、広範な問題設定の元でCascade-DRが非常に高性能であることを確認しています。
特に、複数の異なるユーザー行動をシミュレーションしたデータ上において、「データサイズ」「同時に推薦するアイテムの個数」「評価対象となる機械学習モデル」の3点を変化させ実験を行い、Cascade-DRの有効性を確認しています。
最後に、私たちが開発したCascade-DRは現在OpenBanditPipelineというオープンソースソフトウェア上で公開されており、世界中の研究者や実務家が誰でも気軽に使えるようになっています。これらの研究結果および実装を公開したことにより、ヤフーだけでなく多くのリコメンデーション・検索を行う企業で、ランキング推薦のより正確なオフライン評価ができるようになると期待できます。私たち研究チームは、多くの企業が複数のアイテムを同時に推薦する際に抱えていた実務的な課題の解決に貢献できたことを、とても嬉しく思います。
6.おわりに
今回は、普段から皆さんが利用しているリコメンデーション・検索の改善に役立つ最先端の技術を紹介しました。登場したオフ方策評価は、今後も発展が期待される技術です。より便利で正確なオフ方策評価が可能となると、AIや機械学習の試行錯誤を非常に高速にできます。その結果、皆さんがまだ触れたことのない新しいAIや機械学習が誕生するかもしれません。本記事を含め、私たちはヤフーはインターネットにまつわるさまざまな技術領域で、これまで解決できていない課題に取り組んでいます。皆さんが、本記事を通してその取り組みに興味を持っていただけたのであれば幸いです。
*注釈
Cascade仮定の「Cascade」は「滝」を意味します。リコメンデーション・検索では、ユーザーが上から順番にアイテムを閲覧する目線の動きと、滝が上から下に流れていく様子が似ていることから、比喩表現として「Cascade仮定」という名称を使います。
7.紹介論文
8.参考文献
[1] Yuta Saito, Shunsuke Aihara, Megumi Matsutani, and Yusuke Narita. “Open Bandit Dataset and Pipeline: Towards Realistic and Reproducible Off-Policy Evaluation”. NeurIPS, 2021. https://arxiv.org/abs/2008.07146
[2] Alexandre Gilotte, Clément Calauzènes, Thomas Nedelec, Alexandre Abraham, and Simon Dollé. “Offline A/B testing for Recommender Systems”. WSDM, 2018. https://arxiv.org/abs/1801.07030
[3] Shuai Li, Yasin Abbasi-Yadkori, Branislav Kveton, S. Muthukrishnan, Vishwa Vinay, and Zheng Wen. “Offline Evaluation of Ranking Policies with Click Models”. KDD, 2018. https://arxiv.org/abs/1804.10488
[4] Doina Precup, Richard S. Sutton, and Satinder Singh. “Eligibility Traces for Off-Policy Policy Evaluation”. ICML, 2000. https://dl.acm.org/doi/10.5555/645529.658134
[5] Alex Strehl, John Langford, Sham Kakade, and Lihong Li. “Learning from Logged Implicit Exploration Data”. NeurIPS, 2010. https://arxiv.org/abs/1003.0120
[6] James McInerney, Brian Brost, Praveen Chandar, Rishabh Mehrotra, and Ben Carterette. “Counterfactual Evaluation of Slate Recommendations with Sequential Reward Interactions”. KDD, 2020. https://arxiv.org/abs/2007.12986
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 山本 康生
- データサイエンス部門レコメンデーション・システム研究開発
- ヤフーのレコメンデーション・システムの研究開発を担当しています。多腕バンディット問題、因果推論も合わせて研究しています。
-



