こんにちは、ヤフーでエンジニアをしている大石純平です。
ソフトバンクイノベンチャー という新規事業提案制度を利用して事業化を目指して新規事業を1年半ほどやっていたのですが、残念ながらクローズすることになりました。その経験を後続の方に共有し、失敗した気持ちを供養するために筆を取っています。
以前私が書いたこちらの記事 ヤフーで働きながら新規事業に挑戦している話 - Yahoo! JAPAN Tech Blog の後日譚です。
今回の記事では「新規事業で扱った技術のこと」、「なぜうまくいかなかったのか」についてお話しします。
ソフトバンクイノベンチャーについて
ソフトバンクグループ社員なら誰でも新規事業を提案できます。アイデアの実現に向け、事業全般に関する相談から専任の担当者によるメンタリングなどといったさまざまな支援を受けられます。
その制度を利用して作ったのが BAKOON! です。
BAKOON! について
BAKOON! は端的にいうとオンラインフィットネスサービスです。
オンラインでフィットネスを行うサービスは他にもありますが、BAKOON!の特徴は以下です。
- 講師がアイドル
- 短時間でのフィットネス
- モーションキャプチャーを利用したコミュニケーションが行える
BAKOON! の流れ
- ユーザーはスケジュールを確認し、時刻になったら配信へ参加
- 配信中はアイドルと一緒に 20分程の HIIT (高強度インターバルトレーニング) を行う
- 配信が終わったら、ユーザーのアクティビティ(配信履歴)やランキングが更新される
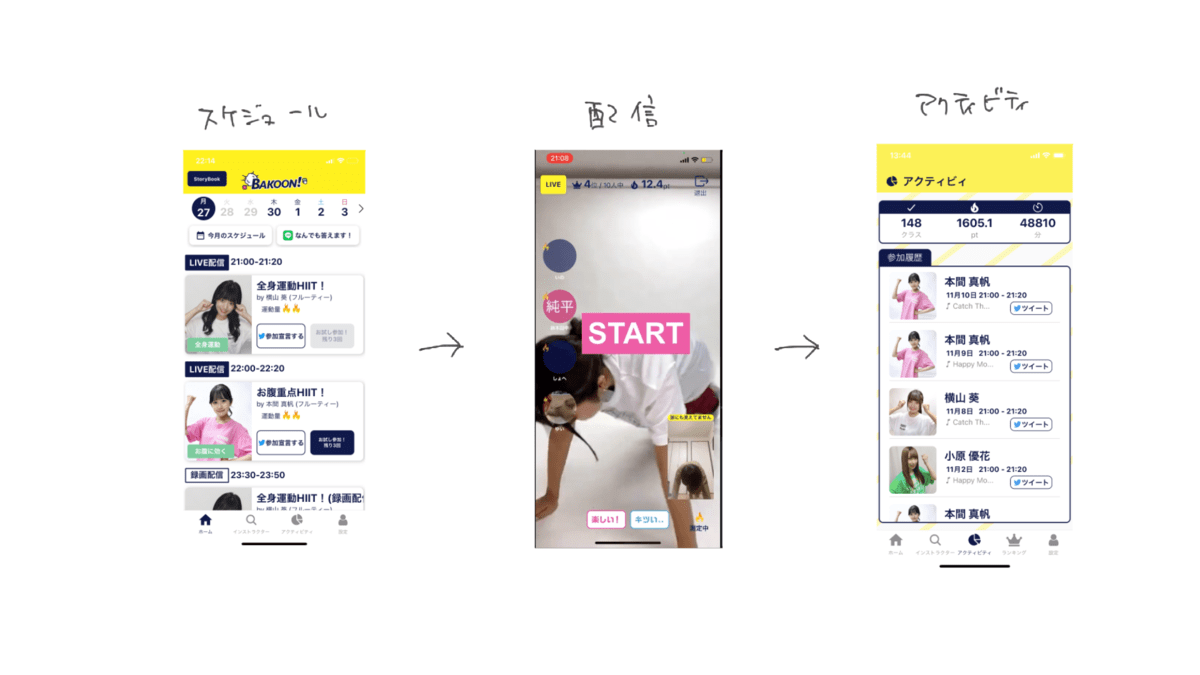
スケジュール画面
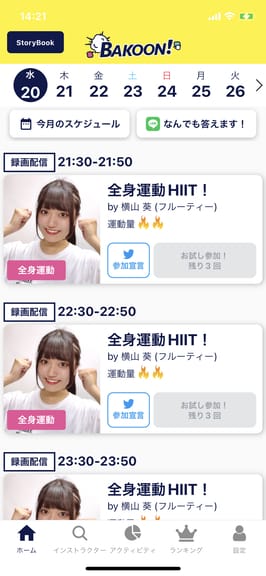
スケジュール画面には以下のような機能があります。
- ライブ配信と録画配信への参加
- 月額500円課金すると制限なしで配信に参加できる
- 配信5分前になると ユーザーへPush通知が飛ぶ
配信画面

配信画面では以下のような機能があります。
- タイマー機能(画面中央)
- HIIT では休憩と運動を交互にテンポよく行うのですが、画面上と音声でタイマーを動かすようにして運動の時間と休憩の時間を分かりやすくしています。
- モーションキャプチャーを使ったコミュニケーション、運動量の測定機能
- 頭の上で丸を作るとハートが画面上を飛んでいく機能と運動量を推定して測定する機能があります。
- スタンプ機能(画面下)
- スタンプを押すことでリアクションが画面上に反映されます。
- バーチャルステージ機能(画面左)
- 参加者がどの程度動いているかどうかを炎で可視化しリアクションの内容も可視化しています。
- テキストチャット機能
- アイドルが任意のタイミングで起動できるチャットです。
アクティビティ画面

アクティビティ画面では以下が確認できます。
- 参加クラス数、運動スコア、運動時間の合計
- 参加履歴
システム概観
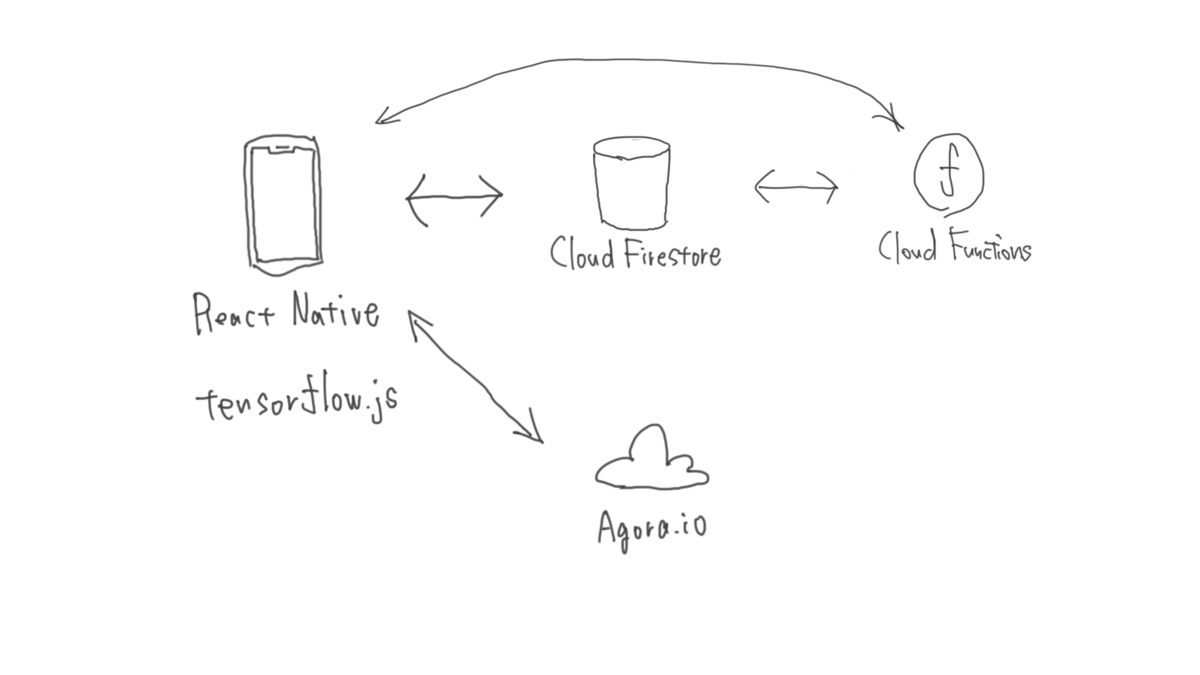
BAKOON! は React Native で作られた iOS アプリです。MVP(Minimum Viable Product)の段階では開発速度を優先して web サービスとして React で作っていました。その時作ったコンポーネントを生かすために、 React Native を採用しました。配信部分のバックエンドは Agora というリアルタイム配信のマネージドサービスを使用しています。React Native 用にもリアルタイム配信を実装できる SDK を提供しています。
BAKOON! では素早くサービスを作り出すために技術を選定しました。以下で BAKOON! で使用している技術について具体的にいくつか紹介します。
具体的なコードを交えての解説
TypeScript を用いて解説していきます。また、一部 React 特有の関数等が出てきます。
Teachable Machine と TensorFlow.js
BAKOON! では、モーションを使ったコミュニケーションを実現するために Teachable Machine を利用しています。Teachable Machine は Google が提供しているブラウザー上でモデル作成ができるサービスです。3種類(音声分類、画像分類、姿勢分類)の学習器が存在していて、それぞれの学習器に学習してほしいデータを放り込むとよしなにモデルを作ってくれます。今回は PoseNet を利用した姿勢分類の学習器を使用しました。

Teachable Machine で作ったモデルはこのように読み込めます。
tmPose.load関数で TensorFlow.js ライブラリで使用できるモデルのアーキテクチャを表すファイル checkpoint とライブラリのバージョン情報やラベル名が書いているファイル metadataURL を読み込みます。
import * as tmPose from '@teachablemachine/pose';
const loadModel = async (): Promise<tmPose.CustomPoseNet> => {
const modelURL = `https://teachablemachine.withgoogle.com/models/<modelID>`;
const checkpoint = `${modelURL}model.json`;
const metadataURL = `${modelURL}metadata.json`;
return await tmPose.load(checkpoint, metadataURL);
}そのモデルをこのように使用します。
model.estimatePose関数で推定したい画像や video などを読み込み、model.predict関数でその画像や video がどういったものなのか予測します
const getPrediction = async (model: tmPose.CustomPoseNet, images: tf.Tensor3D): Prediction => {
const { pose, posenetOutput } = await model.estimatePose(images);
const prediction = await model.predict(posenetOutput);
return prediction
}prediction の型は 分類名 と probability の object のリストになっています。
type Prediction = {
className: string;
probability: number;
}[];例えば、読み込んだモデルが頭の上に手で丸を作ると good という名前で分類をするモデルだとします。以下のような関数を書けば、 probability が 1以上で分類名が good のときに good を出力できます。
getReaction = (prediction: Prediction): `good` | 'normal' => {
const motion = prediction.find((motion) => motion.probability >= 1);
return motion?.className === `good` ? `good` : `normal`;
}前述の model.estimatePose() に渡している images は推定したい画像や video 等です。以下ではこの images をどのように持ってくるかの話をします。React Native でカメラを扱うにはいくつか方法があるのですが、BAKOON! では tensorflow.js 公式ドキュメントのサンプル にならって、 expo-camera を使う方法を取っています。
import { Camera } from 'expo-camera';
import { ExpoWebGLRenderingContext } from 'expo-gl';
import * as tf from '@tensorflow/tfjs';
import { cameraWithTensors } from '@tensorflow/tfjs-react-native';
const TensorCamera = cameraWithTensors(Camera);
// Component
...
const modelRef = useRef<tmPose.CustomPoseNet>();
useAsync(async () => {
modelRef.current = await loadModel();
}, []);
const handleCameraStream = (
images: IterableIterator<tf.Tensor3D>,
updateCameraPreview: () => void,
gl: ExpoWebGLRenderingContext,
cameraTexture: any,
): void => {
const loop = async (): Promise<void> => {
const imageTensor = images.next().value;
if (!imageTensor) return;
const model = motionCaptureRef.current;
if (!model) return;
const predction = getPrediction(model, imageTensor)
const getReaction = getReaction(prediction) // ここで取得した reaction をよしなに使用する
// メモリ解放
tf.dispose([imageTensor]);
// 500ms後に呼び出す
setTimeout(() => {
requestAnimationFrame(loop);
}, 500);
};
loop();
};
return (
<TensorCamera
type={Camera.Constants.Type.front}
style={styles.camera}
cameraTextureHeight={textureDims.height}
cameraTextureWidth={textureDims.width}
resizeHeight={200}
resizeWidth={152}
resizeDepth={3}
onReady={handleCameraStream}
autorender={true}
/>Firebase Cloud Firestore
モーションキャプチャの推定した結果やテキストチャットなどは Cloud Firestore を使ってやりとりしています。
Firestore とは
- Google が提供している serverless な NoSQL データベースサービス
- パスの概念がある独特なデータ構造
- リアルタイムリスナー という データベース のデータの更新を serverless でクライアントに通知する仕組みがあります
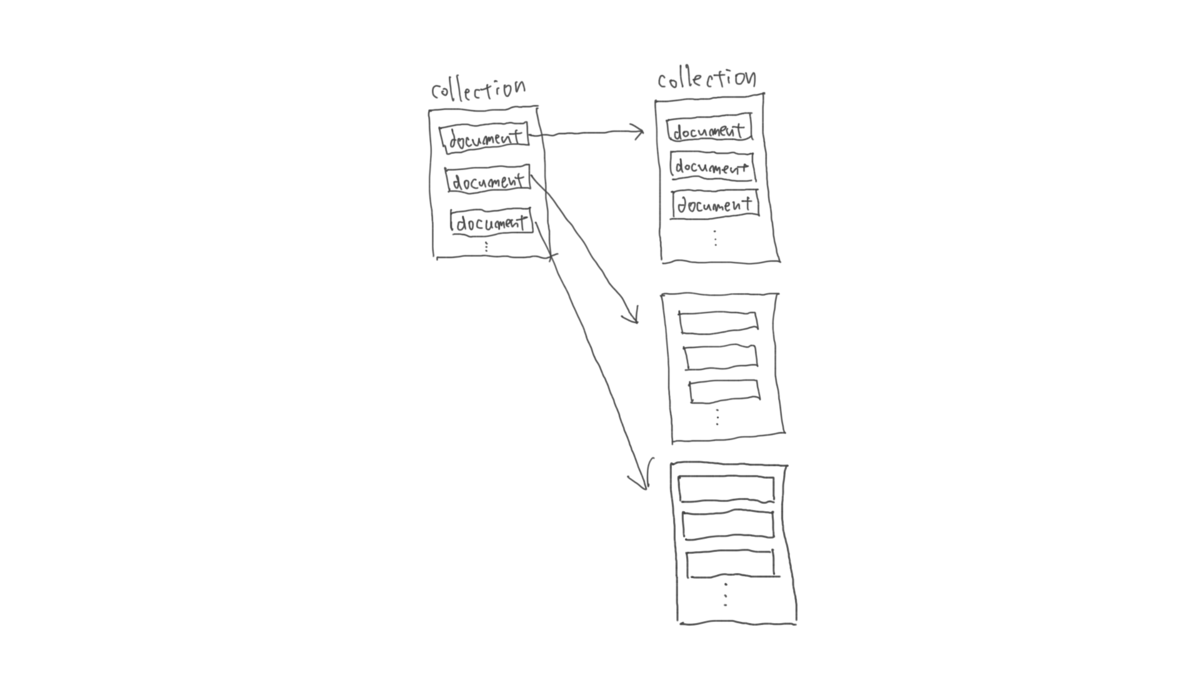
Firestore では以下のようなデータ構造があります。
- ドキュメント: データの単位です。 json object に近いです。ドキュメントは必ずいずれかのコレクションに含まれます。
- コレクション: ドキュメントをまとめるものです。
- ネストしたコレクションのことをサブコレクションと呼びます。トップレベル以外の位置にあるコレクションはサブコレクションです。
Firestore ではパスの概念をうまく使うことで、データのリレーションを表現できます。例えば、 以下のようなデータモデリングをしてみましょう。
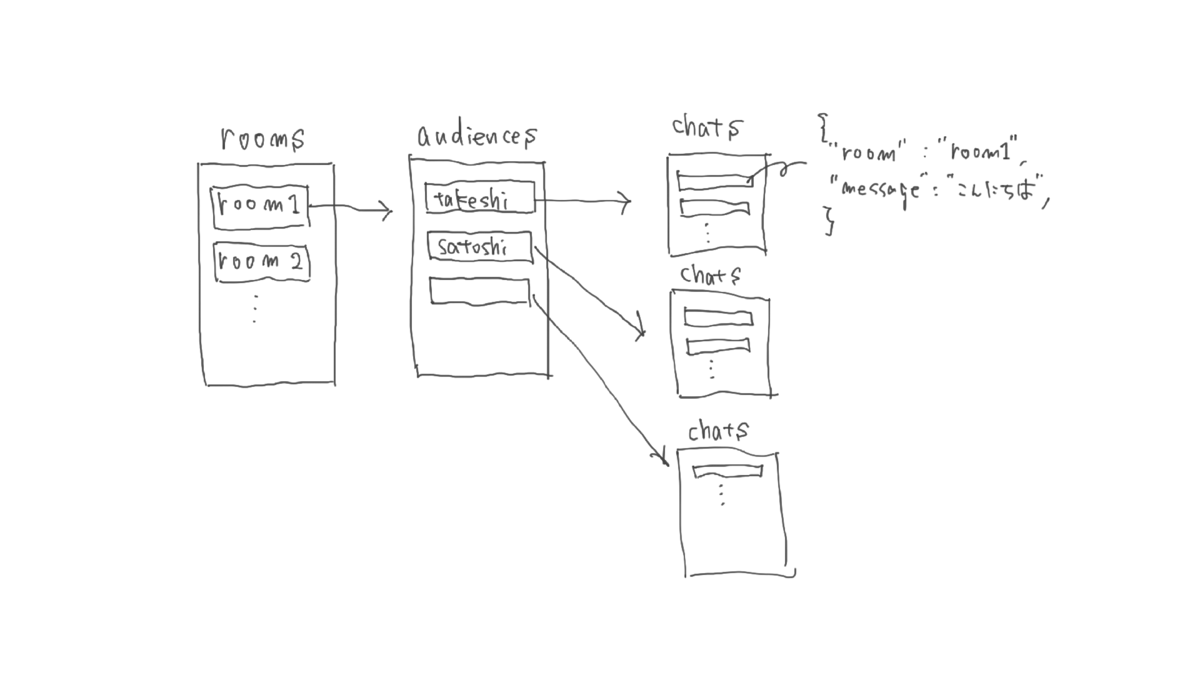
配信部屋 rooms コレクションに room ドキュメントがあり、 room ドキュメント配下に audiences コレクションがあります。その audidence コレクションには audience ドキュメントがあり、それぞれの audience は chats コレクションを持っています。
room1 配下にある chats 一覧を取得することを考えます。単純にやろうとすると、一度 audience を全て取得したあとで、 audience ごとに chats をそれぞれ取得することになり、 N+1 問題が起きてしまいます。
このような問題に対しての解決策が Firestore には用意されています。コレクショングループという機能を利用することで room1 以下にあるサブコレクション chats を1回の処理で全て取得できます。
import firestore from '@react-native-firebase/firestore';
firestore().collectionGroup(`chats`).where(`roomId`, `==`, `room1`).get()このように非正規化されているデータであっても RDBMS での JOIN みたいなことを実現できます。
注意点としては、Firestore は基本的にはインデックスを自動で作成してくれるのですが、コレクショングループで where を使った絞り込みをしたい場合はインデックスを手動で作成する必要があります。
また、異なるコレクション配下のサブコレクションが同じ名前だとそれらも取得することになるので、そこは注意が必要です。prefix や suffix を付けることで別の名前にする必要があります。また、ドキュメントのフィールドに対して where で絞り込みを行っても良いでしょう。
firestore を使う上での工夫
BAKOON! ではデータの性質ごとに Firestore の使い方を分けています。その性質とは主に以下のものです。
- リアルタイム性が要求されるデータ
- リアルタイム性が要求されないデータ
Firestore にはリアルタイムリスナーという便利な機能があります。データベース のデータに変更があったタイミングで、クライアントにデータを送ってくれるので、クライアント上でポーリングのような実装をする必要がなくなります。リアルタイム性が要求されるデータについては、その機能を使います。
リアルタイム性が要求されるデータの取扱い
onSnapshot という関数はデータの変更を監視し、変更された場合はそのデータを通知してくれます。
以下のコードでは chats というコレクションを監視しています。そのコレクションに変更があったら onSnapshot 関数内の snapshot が送られてくるので、それをハンドリングします。
import firestore from '@react-native-firebase/firestore';
export const onSnapshot = (
setChats: (chats: Chat[]) => void,
): UnSubscribeFunction => {
return firestore()
.collectionGroup(`chats`)
.where(`roomId`, `==`, `room1`)
.onSnapshot((snapshot) => {
// onSnapshot 関数を使うと変化があったら snapshot が送られます。
// いわゆるオブザーバーパターンで snapshot のデータをクライアントは扱います。
if (!snapshot) return;
const chats: Chat[] = [];
snapshot.docs.forEach((doc) => {
const chatCommand = doc.data() as Chat
const chat: Chat = {
roomId: chatCommand.roomId,
message: chatCommand.message,
};
chats.push({ chat: chat });
});
setChats(chats);
});
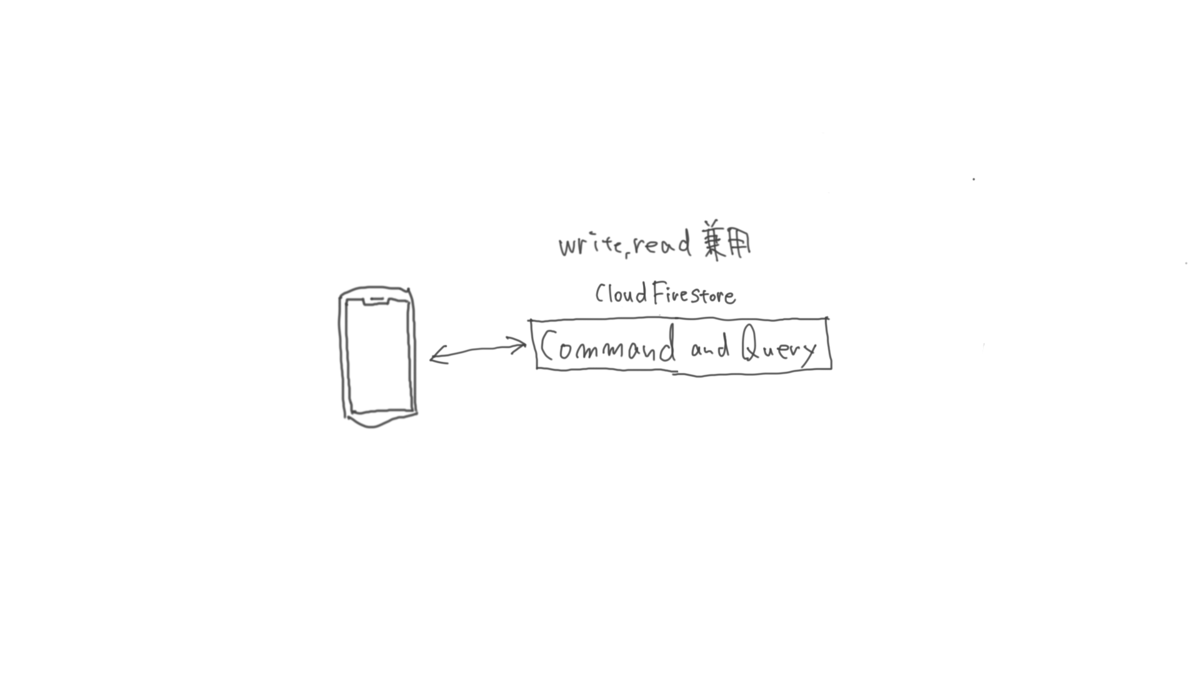
};リアルタイム性が要求されないデータの取扱い
リアルタイム性が要求されないデータに関しては、 CQRS というパターンで扱っています。
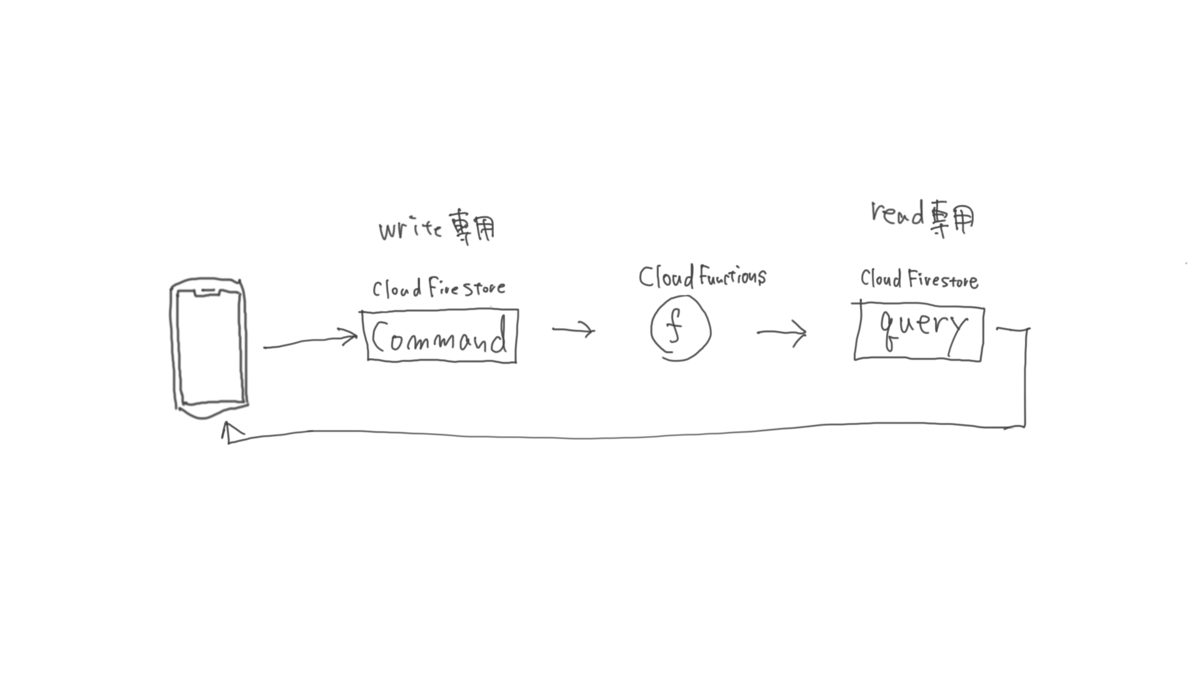
CQRS について
データモデルを書き込み専用モデルと読み込み専用モデルに分けます。それぞれ command, query と呼びます。
- command: いわゆる RDBMS で使われるようなモデリングを行います。必要に応じて正規化も行います。
- query: view に合わせて作成します。なので、基本的に正規化は行わず、冗長なモデルが必要に応じて作成されます。
Firestore で CQRS を実現する場合、 Cloud Functions を使うのがおすすめです。command のデータが追加されたら、 Cloud Functions が動き出し、 query へデータを書き出します。
メリットは以下があります。
- view 用にモデルを作成するので必要なデータを取得するクエリが簡単になります。 where 等で絞り込む必要がなく、基本的には get するだけになります。
- command の変更が query に及ばないので、変更と保守に強くなります。
- 副次的なメリットとして、 command は update には使わず create でデータを扱うので、時系列データとして command のデータが残ります。その時系列データを参照することで、変更履歴の確認ができます。
Agora.io
Agora での配信は React Native 用の SDK を使えば簡単に行えます。実装内容としては以下のコードのようにあらかじめ用意されている機能を呼び出すだけで良いです。
基本的な流れは以下です。
- クライアントを初期化 → チャンネルに参加 → 動画の再生
初期化時の Option や 動画の再生方法などは host 側、 audience 側で異なります。
クライアントの初期化
host 1 : audience 多 で配信する場合を考えます。
- host は Broadcaster という Role を指定します。また、 host の声を配信に乗せたい場合は
setDefaultAudioRoutetoSpeakerphoneを true にします。 - audience は Audience という Role を指定します。
host
import RtcEngine, { ClientRole } from 'react-native-agora';
const rtcEngine = await RtcEngine.create(appId);
await rtcEngine.enableVideo();
await rtcEngine.setChannelProfile(ChannelProfile.LiveBroadcasting);
await rtcEngine.setClientRole(ClientRole.Broadcaster);
await rtcEngine.setDefaultAudioRoutetoSpeakerphone(true);audience
import RtcEngine, { ClientRole } from 'react-native-agora';
const rtcEngine = await RtcEngine.create(appId);
await rtcEngine.enableVideo();
await rtcEngine.setChannelProfile(ChannelProfile.LiveBroadcasting);
await rtcEngine.setClientRole(ClientRole.Audience);チャンネル参加
host が joinChanel したときに指定した channelId へ audience が joinChannel すると host の配信を視聴できます。
await engine.current.joinChannel(token, channelId, null, uid);動画の再生
- host は
channelIdのみ、 - audience は host が
joinChannelしたときのchannelIdとuidを view component で指定することで配信時の動画をリアルタイムで再生できます。
host
<RtcRemoteView.SurfaceView
channelId={channelId}
renderMode={VideoRenderMode.Hidden}
mirrorMode={VideoMirrorMode.Enabled}
/>audience
<RtcRemoteView.SurfaceView
channelId={channelId}
renderMode={VideoRenderMode.Hidden}
mirrorMode={VideoMirrorMode.Enabled}
uid={HostUid}
/>Agora のクイックスタートガイド を参考に実装するとわかりやすいと思います。
捨てやすさを考える
ここからは、プロダクトやサービス全体の話をしていきます。
われわれのアイデアが市場に受け入れられるかを確認するためには、すばやく MVPを作り検証を回していく必要があります。そのためにわれわれは捨てやすいコードを書くことを念頭に置いて開発していました。捨てやすいのは重要なことです。
捨てやすいと聞いて何を想像しますか? 今まで書いてきたコードを消して、新しいコードを0から書き直すことを想像しますか? モノリシックなシステムをまるごと置き換えるということを想像しますか? ここではそういった意味ではありません。捨てやすさを意識するということにはいろいろな含意があります。
開発の初期ではプロダクトのドメインというものは不確かです。他にも設計、技術、機能等不確かな要因がたくさんあります。その不確かさを受け入れ、現時点で良いと思える設計で実装を行う必要があります。あくまでも「現時点で」です。
開発を進めていく中で、だんだんとビジネスロジックの理解が深まり、当初の設計や選定技術、機能よりも良いものがわかってきます。しかし、良いものがわかったからと言ってすぐそれらを既存のシステムに導入できるわけではありません。ですが、パーツの交換や変更、破棄がしやすければ、より良いものへ変更が可能です。先ほど述べたように捨てやすいコードであれば、このようにより良いものがわかった際に変更することができます。
捨てやすいコードで大事なことは適切なモジュール性です。コードの依存を考えて、どこからどこまでがこのモジュールの領域なのかを適切に見極めることが重要です。繰り返しますが、現時点で最良であると思えることも、時がたてば最良ではなくなります。常に捨てやすくする方向にかじを切っておくことが、より良いシステムを目指す上で大事だと考えます。
DDD のようなアーキテクチャは端的にいうと捨てやすいコードを書くための方法論だと私は思っています。ドメイン以外のコードを置き換え可能にするため、インターフェースでレイヤーを分離し、外部に依存した実装をなるべくドメインから剥がす方法です。DDD を完璧に実現することは私の力量ではできません。しかし、「A は B に依存するのはコスパの関係上仕方ないが、 C は捨てやすくしておこう」という議論をメンバーとできたのは 「捨てやすさ」を念頭に置いておいたからだと思います。
捨てやすさを意識することはコード以外にも応用が効きます。
例えば、われわれは時間をかければ PoseNet のモデルの学習器を作ることはできます。しかし、時間をかけて作ったのだからどうせなら生かしたいというサンクコストバイアスを背負う危険があります。
そういう状態はビジネスを停滞させます。外部のサービスを使うことですばやく価値を提供できるのならそちらを使うべきです。
サービスとして何に価値を置いているかを考えることが重要です。例えば、モデルの学習器自体がサービスのコアであれば自分たちで作る意味があります。しかし、われわれの場合はあくまでもコミュニケーションを運動中に簡単に行うためのアイデアを実現させる手段として、学習器が必要だったのです。
技術選定やコードの書き方に対して迷うこともあったのですが、迷ったときは捨てやすい開発をするという指針に立ち返って開発できました。
一見、技術の話だけをしている用に感じるかもしれないですが、ビジネスと技術は不可分です。ビジネスの進め方に合わせて技術もかじ取りをうまくする必要があるからです。
以前、 Martin Fowler の犠牲的アーキテクチャ を読んだことがあったのですが、読んだ当初は自分の中ではしっくり来ていませんでした。0 からビジネスを考え徐々にプロダクトを育てていく中で、捨てやすさを意識して開発することがより良いプロダクト作りにつながるということを体感することができました。これらの経験を踏まえることでようやく自分なりに犠牲的アーキテクチャを解釈し直せたと感じています。
なぜうまくいかなかったのか
前述したとおり、われわれのプロジェクトは事業化にはいたりませんでした。
事業化できなかった直接の原因は、見込みよりも集客ができなかったからです。ここでは、失敗した理由を深掘りして話していきます。
主に以下の2点が挙げられます。
- アイドルありきの進め方になっていたこと
- マネタイズやビジネスモデルについて深掘りできていなかったこと
アイドルありきの進め方になっていたこと
ユーザーのモチベーションを保つのがアイドル頼みだけになっていました。
アイドルとフィットネスを融合させれば、運動をライトに行いたい層も集客できるのではないかという仮説からアイドルを起用したのですが、実際のところ、参加する方のほとんどはファンの方でした。仮説の段階で理想を奇麗にまとめすぎてしまい、うまくいきそうだという想像だけで進めていました。実際に最初に MVP で検証したときも滑り出しがよかったことで、このまま進めれば大丈夫という安心感を持ってしまっていたこともあると思います。どういった層が使ってくれているかはきちんと集計すればわかったことなのですが、まずはサービスを作らなければと開発優先になり、ユーザーの検証などが後回しになってしまいました。アイドルとフィットネスという結論ありきにならず、最初に市場の課題を精査しそれに合わせて、プロダクトを作るべきだったと今は感じています。
また、検証サイクルをすばやく回せるようなプロダクトにするべきでした。アイドルを BAKOON! の一番の成功要因に置いていたことで、いろいろなアイドルの方の動画で検証するのにも営業、調整などの段取りが多く、検証サイクルを回すのに時間がかかってしまいました。もっと素早く検証サイクルを回し、自分たちの事業について見直す必要があったと感じています。
それに加え、アイドルとフィットネスそれぞれのコンテンツに詳しくない状態で作っていたことも良くなかったと思います。もちろん、基本的なことの調査は行っていましたが、それぞれのコンテンツを深掘りしたり、詳細な市場調査などはできていませんでした。BAKOON! はコンテンツが一番重要なものなのに、自分たちの知識や想像だけでプロダクトを作っていました。コンテンツに重きを置くのならば、そういったことに詳しい人をチームメンバーへ引き入れるべきでした。
実際に事業を開発してみると、チームメンバーの構成がプロダクトの性質に大きく影響することがよくわかりました。メンバーそれぞれの武器を把握し、その中から成功要因を見つけ出すことで、検証サイクルをすばやく回せるプロダクトになると思います。
マネタイズやビジネスモデルについて深掘りできていなかったこと
オンラインサービスでマネタイズといえばサブスクリプション型のものであるという固定観念があり、今回のサービスも安直にサブスクリプション型で良いと考えていました。また、 われわれは toC のサービスとして BAKOON! を作ったのですが、それはビジネス的な観点の理由ではなく toB のサービスをあまり知らないことが主な要因でした。
今改めて考えるならば toB 向けのサービスとして BAKOON! を作ることも念頭に置きます。
例えば、健康意識を芽生えさせるためのプログラムを企業に売り込み、 BAKOON! のシステムを使ってもらうことや、 Zoom などを使用してオンラインフィットネスを行っている企業に BAKOON! のシステムを売り込むことを考えても良いでしょう。そうすれば、ユーザーへ提供する価値やどの部分の開発に力を入れるべきなのかなど判断することが変わってきたと思います。このように事業を行う上で、どうやって利益を得るのかをしっかり考えておく必要があったと感じています。
おわりに
BAKOON! は終わってしまいましたが、 0 から事業を作り出すことに挑戦できたのは良い経験でした。企業の中にいるとすでに出来上がっているサービスの中で能力を発揮することを求められることが多いかと思います。0 からの事業ではサービスの方向性を見定め何をやるべきなのか、やるべきじゃないのかを選択する能力が求められます。エンジニアという立場を超えて、サービスを発展させていくのは難しいことでしたが、やりがいはとてもありました。
この文章が新しい挑戦をする人の役に立てばうれしいです。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 大石 純平
- エンジニア
- 巨大な広告システムの一部を作っています。最近は捨てやすさについて考えています。



