こんにちは。サイエンス統括本部で機械学習エンジニアをしている芹沢です。ヤフー全社で使われているレコメンドプラットフォームを担当するプロジェクトに所属し、ログ収集・学習ジョブの開発/運用やMLOpsに関連する業務を行っています。
本記事ではそのMLOps業務の中からモデリング業務の効率化の取り組み事例を紹介します。新しいモデルを本番採用するまでにはA/Bテストの準備などをする必要がありますが、それにかかる工数が多いことが課題となっていました。そこで、検証段階からA/Bテスト実施までの実装の負担を軽減し、より早く安全にモデル改善の試行錯誤を行える仕組みを提供しました。
※ レコメンドシステムの開発はプライバシーポリシーの範囲内で取得したデータを用いて、個人を特定できない形で行っています。
全社共通レコメンドプラットフォームの紹介
レコメンドとは、サービスを利用するユーザーにおすすめのアイテムを推薦する機能です。われわれのプラットフォームは、ヤフー内の20を超えるさまざまなサービスに対し合計50以上のモデルを提供しており、リクエスト数は1日あたり最大5億ほどに達することもあります。専属のサイエンスチームを持たない小規模のサービスでも利用できるように、基本的なモデルであればロガーを実装するだけで利用可能な仕組みです。最近では大規模なサービス専属のサイエンスチームとも連携して、オーダーメードのモデルを開発・提供することも行っています。
現在、APIなどモデルの配信に関わる部分を担当するチーム、モデリング業務を行うチーム、そして私が所属するモデリング業務の改善およびログ収集・学習ジョブを担当するチーム、の3チームで運用しています。このモデリング業務で抱えていた課題とその改善策についてを、今回ご紹介いたします。(モデリングチームの取り組みについては以前こちらの記事で紹介いたしました。ご興味あればご覧ください)

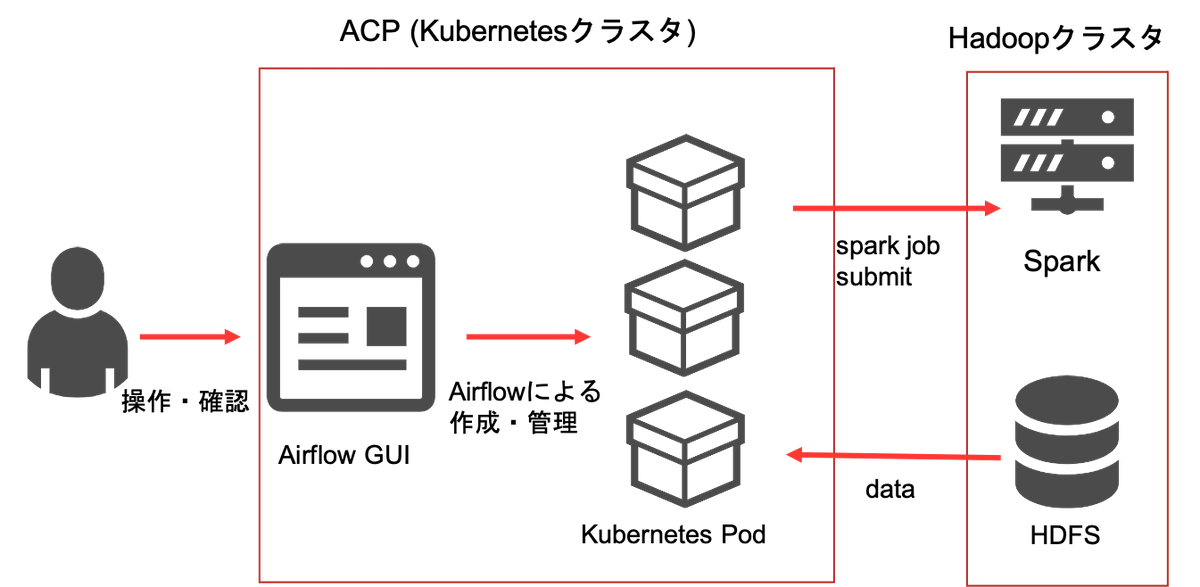
集計・学習システムの構成
本題に入る前に、ログ収集と集計・学習システムの構成について簡単に説明します。
ジョブはAIプラットフォームが提供するKubernetes基盤であるACP上に構築したAirflowで全て実行進捗(しんちょく)管理されています。ほとんどの処理はAirflowによってKubernetes上にPodが立てられて実行されます。データストレージとしてHDFS(Hadoop Distributed File System)を利用しており、Sparkを用いて集計・学習の中間データを保存します。Kubernetesによる動的なリソース管理とAirflowのGUIにより、多数のジョブの実行進捗管理がやりやすくなっています。
モデリング業務で抱えている課題
われわれのプラットフォームでは、多様なサービスからの多様な要望・ログ形式に対応し、時にはビジネスロジックを考慮したモデリングを行う必要があります。
しかし、厳しい時間的制約の中で性能の高いモデルを作ろうとすることに集中した結果、処理の構造化や単体テストなどの目先の実装の手間を避け、技術的負債や実装コストが次々に積み重なっていきました。
たとえば、
- 検証作業では: JupyterHub上で.ipynbファイルを実行
- A/Bテストでは: サーバー上でcronによって定期実行される.shから.pyファイル(.ipynbファイルを実装し直したもの)を実行
- 本番稼働では: ACP上のAirflow上のパイプラインからPodを立てて.pyファイルを実行
というように実行環境が各段階で異なり、非常に実装コストがかかりました。
A/Bテストの段階でAirflowを用いなかったのは、
- Airflowで動かすためのDocker imageを用意するのが大変
- パイプライン用のスクリプトを書くのが面倒
という理由があったからです。本番稼働の際にはそれらを行うことになるとはいえ、A/Bテスト段階では実装に時間をかけたくありません。(なぜなら、A/Bテストの結果次第でモデルの導入が却下される可能性があるからです。特にレコメンド分野においては、オフラインの指標とオンラインKPIは必ずしも相関しない上に、他の指標に悪影響を与えることもあるので、その可能性は高まります)
とはいえ、このように本来きちんとやった方がいいことを省略したとしても、それほど準備が早くなるわけではありませんでした。
そして、実装の時間的コストは、サービスや施策の分析やモデリング作業にかける余裕を奪いました。また、バグ検証の余裕もないのに、環境に合わせるための規模の大きな実装を繰り返すことでバグの混入リスクも高まるという危険な状態でした。
ゴールは「仮説を立てて検証」を素早く何度も反復できる環境
こういった実装のコストはデータサイエンティストに負担させるべきではなく、機械学習エンジニアが担当して、データサイエンティストは分析・モデリング業務に集中すべきという考え方もあると思います。
しかし、
- 人的リソースが限られている(プロジェクトの規模に対し、対応モデルの数が多いため)
- モデルの担当者が実装を行わないと、仕様の勘違いからトラブルにつながる可能性がある(多様なサービスごとに最先端のモデルを導入するため)
- モデリングチーム自身が、実装含めエンジニアリング部分にも興味を持っている
といった背景から、モデリングチームが実装も担当しつつ、機械学習エンジニアがその負担を軽減するという方針をとることにしました。
さて、ここまで書いてきた通り、構造上の問題が多く、小手先の工夫ではどうにもなりません。そこで、A/Bテストを高速かつ安全に準備できる仕組みを用意することにしました。
サイエンス業務である以上、「仮説を立てて検証する」ということを素早く何度も反復できる必要があります。試してみないとわからないことは多いからです。それでいて、数を打つだけでは不十分で、なるべく信頼できる施策であることが重要です。よって、言葉にすると当たり前ですが、「開発工数を削減しつつ、安全性を担保する」のを目的としました。それを実現するために以下のような仕組みを用意しました。
A/Bテスト準備フローの改善
基本的なコンセプトは
「JupyterHubでの検証時の.ipynbファイルを(なるべく)そのまま使いまわしてA/Bテストをする」
というものです。それを実現するために.ipynbファイルをshellで実行できるpapermillというツールを使います。さらに、Argo Workflowsというワークフローツールでpapermillのコマンドを実行し、その実行進捗管理をAirflowで行います。
詳しい方は、「なぜAirflowとArgo Workflowsという2つのワークフローツールを使うんだ?」と疑問に思うかもしれません。AirflowとArgo Workflowsともに優れたワークフローツールなのですが、それには2つのツールの特長の違いと社内の事情が関連しています。
Airflowは高機能かつ優れたUIにより一覧してジョブの状況がわかりやすいという点に分があります。また、現在のログ収集・学習の定常稼働ジョブはAirflowで一元管理されており、A/BテストでもAirflowで実行進捗管理をしたいというモチベーションがあります。
一方で、Argoは優れたテンプレートエンジンがあるという特長があります。AIプラットフォームはこのテンプレートをいくつも提供しており、その中にはpapermillの実行が簡単に行えるものも含まれます。このテンプレートをそのまま利用することで、開発・管理コストを抑えながらこの仕組みを運用していくことが可能になります。(そもそもの目的として開発コストの削減があるので、独自の実装ではなく、社内で知見を横展開しやすいというのもメリットでしょう)
軸となる仕組みはこれだけの単純なものです。次はこれを活用した新しいA/Bテストの準備のフローを紹介します。大まかな流れは以下です。
- オフライン検証で良さそうな結果が出る(JupyterHub)
- notebookの修整
- Docker imageの用意
- notebookの動作確認・レビュー
- Airflow用スクリプトの作成
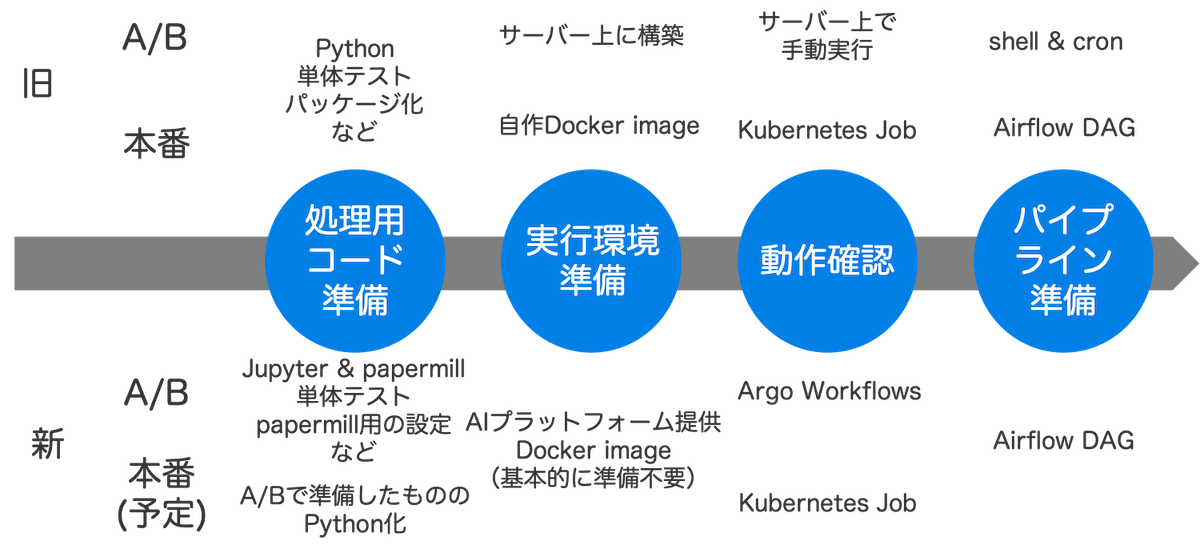
notebookの修整
papermill用の設定が必要になるのと、安全で楽な運用のために、notebookの修整をします。「そのまま使い回す」というコンセプトとはトレードオフなのですが、よりよい運用のためにある程度コストを払うことにしました。
papermillの大きな特長として、shellのコマンドからパラメータとして内部の処理に値を渡せるというものがあります(例えば、ログの集計対象の日時などです)。これにより同じようなnotebookをいくつも作ることなく、パラメータだけ変えて使い回すことができます。このパラメータ指定用のセルを用意する必要があります。
また、安全な運用のためには関数化・モジュール化やそれに対する単体テストがかかせません。しかし、.ipynbファイルに対するテストはそのままではやりにくいです。そこでtestbookというツールを導入し、notebook内の処理のテストができるようにしました。ただし、testbookはpysparkkernel(Jupyterでpysparkを動かすために用いているsparkmagicのkernel)に対応していなかったので、その部分の処理は.pyファイルにモジュールとして書き出して単体テストをすることにしました。
さらに、楽な運用のためにnotebookをある程度分割するようにもしています。papermillはnotebookの途中から再実行することには対応していません。例えば、長い時間のかかる学習後の処理で失敗した場合に、最初から学習し直すのは好ましくありません。そうならないように、notebookは分割して、それぞれを実行するようAirflowのtaskに割り当てます。
他には、必要な認証情報などの設定のセルも適宜追加して完了です。
Docker imageの用意
Docker imageは基本的にはチームごとで作るのをやめて、AIプラットフォームが提供しているものを使います。検証に使っているJupyterHubも、AIプラットフォームが提供しているACP上に構築されたものを利用します。これでほぼ環境の一貫性が担保されます。必要に応じてArgo Workflowsのtemplateの処理としてpip installでライブラリを追加します。
場合によってはpipに対応しておらずソースビルドが必要になるライブラリも考えられますが、その場合はAIプラットフォームが提供しているものimageをベースとしてそのライブラリを新しく追加したimageを作成します。
Airflow用スクリプトの作成
必要な設定をAirflowのパイプライン用のスクリプトに書きます。AIプラットフォームの提供するArgo Workflowsのtemplateのおかげで、面倒な認証設定などをする必要はありません。ここで、papermillの出力するnotebookの実行履歴をPersistentVolume上に置くようにすることで、問題が起こったときなどに後からさかのぼって確認できます。
目的とアプローチのまとめ
今回提案する仕組みの目的は「工数削減」と「安全性の担保」でした。それらがこの仕組みによってどう達成されたかをまとめました。
| 目的 | アプローチ・具体的手段 |
|---|---|
| 工数削減 | 【アプローチ】 検証時に近いコードを動かせるように 【具体的手段】 papermillでnotebookを実行 |
| 工数削減 | 【アプローチ】 実現を手軽に 【具体的手段】 Argo Workflowsのテンプレートをはじめ、AIPFチームの提供するツールを使う |
| 工数削減 ・安全性の担保 | 【アプローチ】 実行環境の一貫性を保つ 【具体的手段】 基本的に提供されたDocker imageを利用 |
| 安全性の担保 | 【アプローチ】 コードをテストしやすく 【具体的手段】 notebook上の処理の関数・モジュール化 |
この仕組みを導入した効果
現在2つの新規案件について、この仕組みを試したところです。
1つ目の案件では、初の試みだったこともありドキュメントが不足していてArgoの利用方法で詰まる場面もありましたが、それ以外の部分ではスムーズに進められ、こちらは二週間ほどで準備を終えられました。
2つ目の案件では15営業日かかる見込みのところを12営業日で終えられました。見かけ上は3営業日、2割程度の工数削減ですが、実際にはそれ以上の効果があったと考えています。このフローにモデリング担当が慣れればさらなる高速化が期待できます。
また、モデリング担当者からは以下のようなポジティブなフィードバックがありました。
全体的な印象について
- 楽になっている実感があった
- テストやレビューを時間に余裕を持って行えた(かかった営業日が長く見えるのは、急ぐ必要がないのでリリースを週明けにしたから)
具体的な作業について
- 新しい環境用にモジュールを作り直さなくていいのが楽
- Docker imageを作る必要がなく、動作確認の手間がなかった
目的とした工数削減・安全性の担保以外について
- notebookから処理の失敗原因がわかりやすいのが助かる
一方、挙げられた課題点としては、「Pull requestのレビューをGitHubで行う際、.ipynbファイルというメタデータを含んだJSON形式だと該当箇所を探すのが難しくてコメントをつけづらい」というものがありました。GitHubの機能としてJupyter上と同様に表示することは可能ですし、nbdimeを使えばdiffを見ることもできます。しかし、拡張を入れていないGitHubではnotebookとして表示した状態からコメントを入れられないようです。また、PySparkの処理のテストがやりにくいのも課題です。
さらに、今回の記事の範囲外ですが、A/Bテストで良い結果が得られてから本番稼働を行うまでのフローをどうするかを考える必要があります。ある程度ならA/Bテストと同様の構成で動かし続けることは可能ですが、年単位で動かし続けることになった場合、このままの構成で管理できるのかという懸念はあります。とはいえ、.pyの形で処理を書き直した場合でも、従来とは違ってACP上で同じDocker imageを使って動かすことで環境の一貫性が担保されるので、以前よりもスムーズに開発できるのではないかと期待しています。
おわりに
この記事では、全社共通レコメンドプラットフォームにおけるモデリング業務改善の取り組みについて紹介しました。
MLOpsは「なんらかのツールを導入して良くなったから完成」というようなものではありません。業務を進めていく中で課題を洗い出し、日々改善していくものです。日々進化していくヤフーのMLOpsを今後もお伝えできればと思います。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 芹沢 信也
- 機械学習エンジニア
- 全社共通レコメンドプラットフォームで、ログ収集・学習ジョブの開発/運用やMLOpsに関連する業務を行っています。



