
こんにちは。サイエンス統括本部でレコメンデーションエンジンの開発を担当している吉井と小出です。
今回は、レコメンデーションと横断データ活用の事例として、各種データからユーザーの意図を抽出し、レコメンデーションの性能改善につなげる取り組みについてご紹介します。
※レコメンデーションエンジンの開発はプライバシーポリシーの範囲内で取得したデータを用いて行っています
レコメンデーションとは
レコメンデーションは、サービスの利便性を向上させるために欠かせない技術となっています。
代表的なレコメンデーションの利用事例としては、
- 今閲覧しているアイテムに関連するアイテムを提示する
- あるアイテムと一緒に買われやすいアイテムを合わせ買いアイテムとして提示する
- ユーザーに関心のありそうなアイテムを提示する
などがあります。
今回はこのような一般的なレコメンデーションの事例とは異なり、過去にそのサービスを訪れたことがないユーザーに対して、ユーザーが求めているものと類似するアイテムをサービスが提供していた場合に、そのアイテムをレコメンドしたいというケースについてお話しします。
Yahoo! JAPANではトップページやニュースなどのメディア、ショッピングやオークションなどのコマース、クレジットカードやスマホ決済アプリなどの金融といった多種多様なサービスを運営しています。
特定のサービスを利用しているユーザーに、そのユーザーが求めているものがYahoo! JAPANの別サービスにある場合、その間を繋ぐことでユーザーが今まで以上の価値を得ることができるのではないかと考えています。
しかしこの取り組みを行うにあたって、解決しなければならない問題のひとつにコールドスタート問題があります。
コールドスタート問題
コールドスタート問題はレコメンデーションにおける代表的な問題の一つであり、レコメンデーションに関するトップ会議であるRecSysにおいてもセッションが組まれています。
例えば、新しく入荷したアイテムには、そのアイテムに関するユーザーの閲覧や購入といった行動が付与されない、あるいは非常に少量しかされないといったことが起こります。
その際、協調フィルタリングのようなユーザーの行動をベースとしたレコメンデーションを行っていると、新規のアイテムに対してレコメンドを提示できない、あるいは任意のアイテムに対して新規のアイテムをレコメンドできないといった事象が発生します。
この問題はアイテムだけでなく、ユーザーにも起こります。サービスの利用がほとんどないユーザーに対して、嗜好(しこう)にあったレコメンドを出すことはとても難しいです。
アイテムのコールドスタート問題に対しては、アイテムのタイトルや画像などのメタ情報を利用して関連商品をレコメンドするコンテンツベースのアプローチが考えられます。
また、ユーザーのコールドスタート問題についても、売れ筋の商品を提示するなど個別のユーザー、アイテムに依存しない方法でレコメンドするといった対策や、ユーザーの行動をできるだけ早くレコメンドに反映できるようシステムを強化することで影響を最低限に抑えるといったことが考えられます。
データ活用によるコールドスタート問題への対応
今回は、ユーザーのコールドスタート問題に対して、Yahoo! JAPANのさまざまなサービスのデータを活用して問題の解決をはかります。
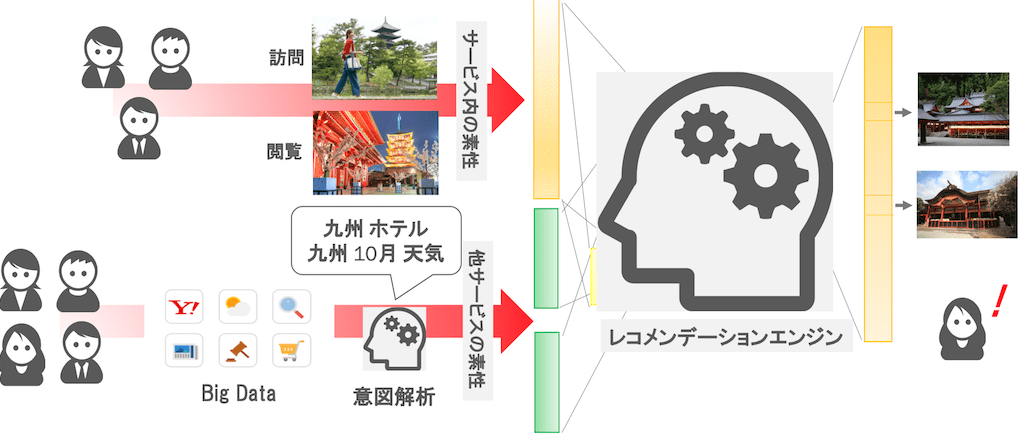
シンプルな例として、旅行を計画しているユーザーに対して国内ツアーをレコメンドすることを考えます。(ちなみにこのユーザーはYahoo!トラベルを利用したことがないユーザーとします)
あるユーザーが「九州 旅行」、「九州 お寺」といったキーワードで検索していたり、Yahoo!天気で来週末の九州地方の天気を確認したりしているといったデータが得られているとします。このようなデータから「このユーザーは来週末に九州のお寺へ参拝に行こうとしているかもしれない」という仮説が立てられます。
一方で、過去に同じような検索やサービス利用をしたユーザーのなかで、Yahoo!トラベルにて九州の国内ツアーを利用したというデータが一定量得られているとします。すると、Yahoo!トラベルでの国内ツアーの予約の情報と、ユーザーのYahoo!検索、Yahoo!天気といった他サービスでの利用傾向を紐づけることが可能です。
このようなビッグデータを用い、レコメンドモデルを作成することで、「来週末に九州のお寺へ参拝に行こうとしている」ユーザーに対して「九州の寺院巡りツアー」といったユーザーのニーズにある程度合致したレコメンドを提供できるのではないかと考えています。
問題設定
ここからは、実際にどのようなアプローチで問題を解いているかについて説明します。
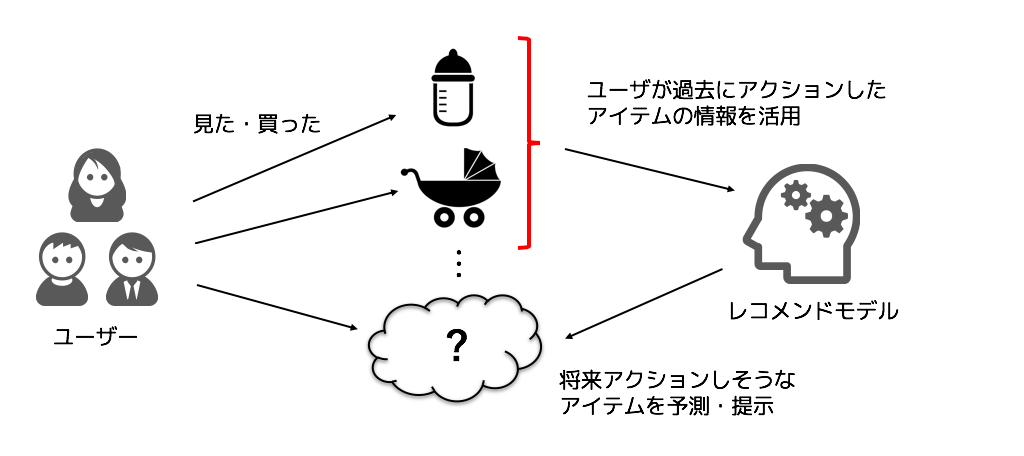
私たちのチームでは、レコメンドを「Next-Item Prediction」と呼ばれる問題設定として取り組んでいます。
Next-Item Prediction では、ユーザーが過去に行ったアクション(アイテムページの閲覧やアイテムの購入)の履歴やユーザーの属性情報などを基に、今後ユーザーがアクションしそうなアイテムを予測します。
モデルとしては、多クラス分類を行う Deep Neural Network を用いています。Googleが提供している機械学習の教材では、「Softmax DNN」と呼ばれているアプローチです。
「レコメンデーションの問題設定だとクラス数が多すぎるので、多クラス分類はハードウェア的な理由で難しいのでは?」と思われる方もいらっしゃるかもしれませんが、私たちがレコメンドモデルを作成するサービスのアイテム数は多くが1万~3万程度であり、実際に検証した結果十分にリアルタイム推論が可能だったため、このアプローチを採用しています。非常にシンプルなアプローチであり、実用的に使いやすいのもメリットです。
データの組み合わせによる改善の事例
今回の事例では、ユーザーのサービスでの行動履歴の他にユーザーの検索履歴の情報を組み合わせることで、レコメンドモデルの性能を改善させることができるかを検証しました。
ユーザーの検索履歴の情報をレコメンドモデルに活用するために、ユーザーの検索履歴の情報をベクトル化しました(これをユーザーの検索ベクトルと呼ぶことにします)。このベクトルは、ユーザーが過去に使用した検索クエリの情報を集約して作成しました。
検索クエリを直接利用せず、ベクトルという形に変換して利用するのはシステム的な理由があります。検索クエリの種類数は膨大であり、直接モデルの入力として利用しようとするとモデルのサイズが大きくなりすぎてしまい、予測に時間がかかるようになり十分な推論性能を発揮することができなくなってしまいます。Feature Hashing など、この問題に対するアプローチも存在していますが、モデルの推論性能以外にも、ユーザーごとに検索クエリを管理しておくコストが大きい問題があると判断したため、今回はユーザーの検索履歴の情報をベクトルに集約しておくアプローチを取ることにしました。
ユーザーの検索ベクトルは、検索クエリをベクトル化しその平均ベクトルとすることにしました。
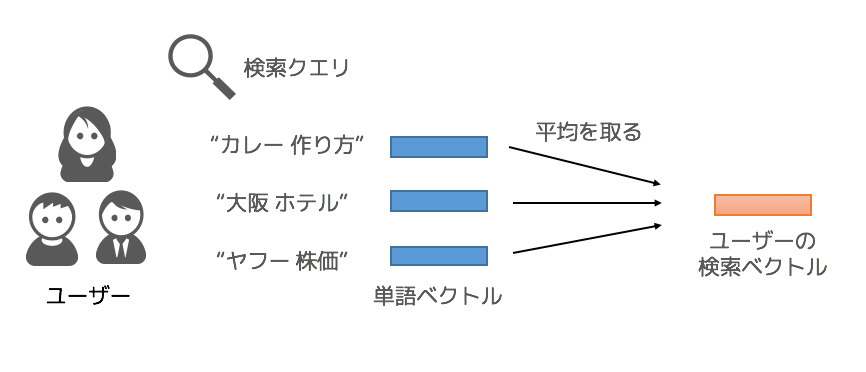
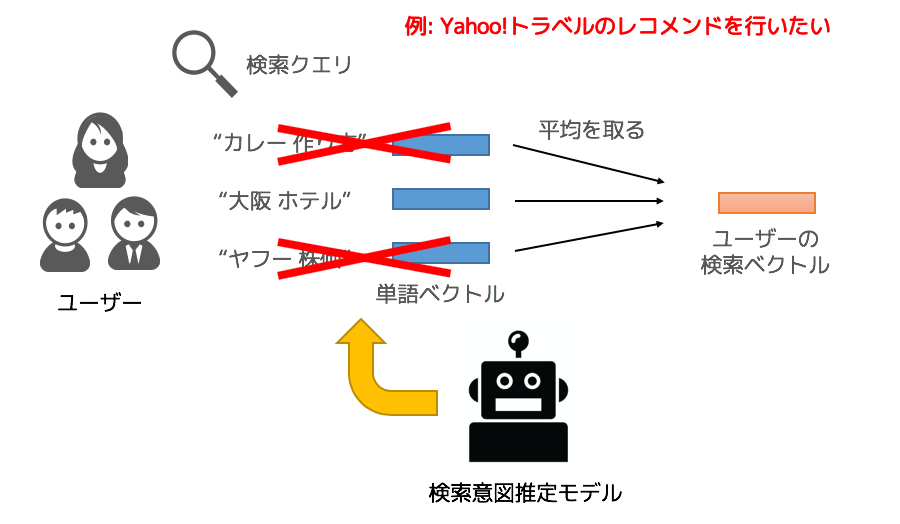
検索クエリのベクトル化には、社内で作った「検索クエリの情報を基に学習したword2vecモデル」を利用しています。
ここで工夫として、ユーザーの検索ベクトル作成に用いる検索クエリのフィルタリングを行います。典型的な頻度によるフィルタリングの他に、検索意図を考慮したフィルタリングを行っています。社内で作った検索クエリの意図推定モデルを活用し、レコメンドを実施したいサービスと関係がなさそうと判断された検索クエリをフィルタリングすることにしました。
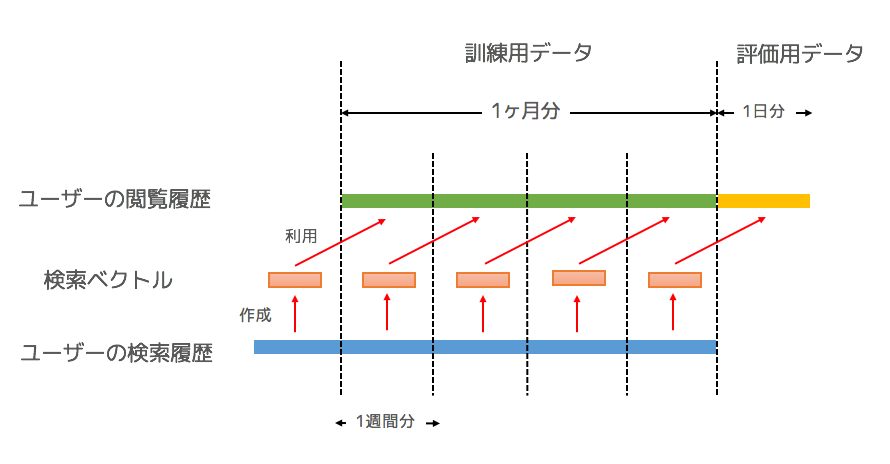
上記のアプローチについてオフライン検証を行いました。1カ月分のサービス閲覧履歴と検索履歴を用いてレコメンドモデルの学習を行い、その期間より先の1日分のサービス閲覧履歴を用いて評価を行いました。ここで、ユーザーの検索ベクトルは対象とする日時より以前の1週間分の検索履歴を用いて作成しました。これは以下の理由によります。
- leakage(予測に使用してはいけないデータを利用してしまい、モデルが不当な学習をしてしまう現象)を防ぐため
- 実際のデータ更新頻度をある程度シミュレートするため。検証当時はユーザーの検索ベクトル更新をどのように実現するか未検討であったため、最低でも実現できそうな更新頻度で検証を行った
実験結果は、以下の表の通りとなりました。全ユーザーに対する結果(左2列)と、閲覧履歴が存在しないユーザー(コールドユーザー)のみに対する結果(右2列)を示します。
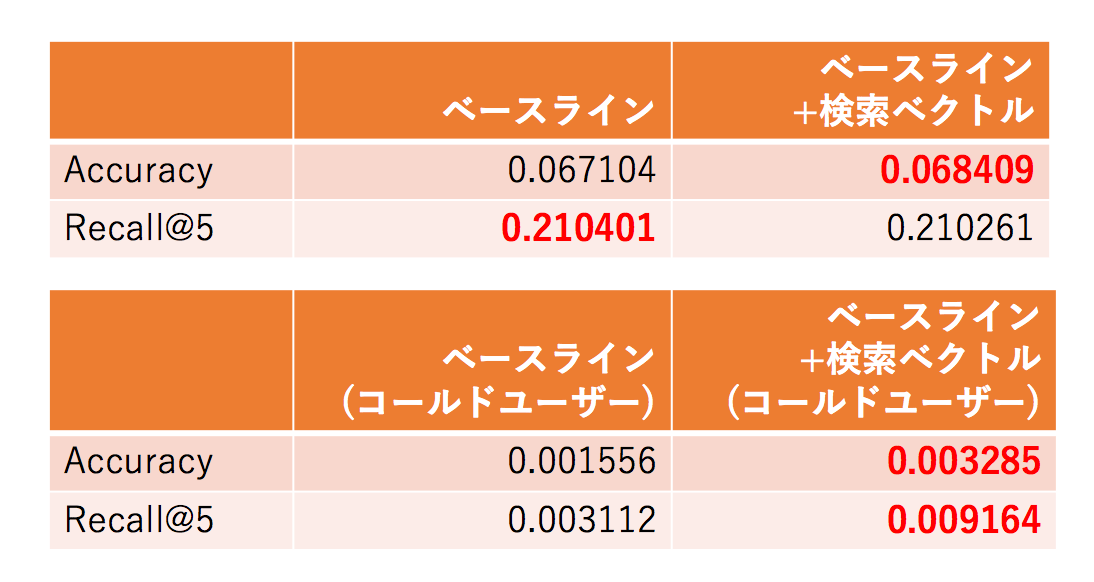
ベースライン手法は、ユーザーの検索ベクトルを特徴量に用いなかったモデルです。ユーザーの検索ベクトルを用いることで、全体のレコメンド性能を大きく劣化させることなく、コールドユーザーに対するレコメンドの性能を大きく向上させることができました。
終わりに
レコメンデーションと横断データ活用の事例として、検索データからユーザーの意図を抽出し、レコメンデーションの性能改善につなげる取り組みについて紹介しました。
今回はわかりやすい例として検索データを利用した結果を載せていますが、他にもさまざまなデータを用いた検証を進めています。また、今後利用するデータを増やしていった際には、推論の性能がサービスの要求レベルを満たせるようにモデルの改善を行ったり、システムの改善を行ったりすることが必要になってくると思います。
モデルの性能と推論のスピードをどちらも担保することは簡単なことではありませんが、そのためのモデル改善やシステム改善に今後もチャレンジし続けていきます。
ヤフーでは今回ご紹介したレコメンデーション技術を始めとする、大規模なデータと機械学習等の技術を活用したソリューションの開発分野で活躍したいエンジニアを募集しています!
写真:GYRO_PHOTOGRAPHY/イメージマート
写真:アフロ
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 吉井 和輝
- 機械学習エンジニア
- レコメンデーションエンジンの開発・運用に日々取り組んでいます!
-
- 小出 明弘
- サイエンス領域のマネージャー
- レコメンデーションの改善を中心に、データサイエンスの活用に必要なデータマネジメントやセキュリティなどを合わせて担当しています。



