こんにちは。ヤフーで音声認識の研究開発をしている山口です。
私たちは、ヤフーの音声認識の性能を高めるため日々研究開発に取り組んでいます。
今回は、私が新卒1年目で取り組んだEnd-to-End音声認識のデモアプリ開発と、その技術検証結果を紹介したいと思います。
ヤフーの音声認識とは?
皆さんは、ヤフーの音声認識というものをご存じでしょうか?
「Yahoo! JAPAN」アプリを開くと検索欄の右側にマイクボタンがあり、そこを押すことで音声を使った検索ができます。この裏側で動いているのが自社開発の音声認識エンジン「YJVOICE」です。
このYJVOICEは、Yahoo!ニュースやYahoo!乗換案内など、ヤフーで開発されている多くのアプリに搭載されています。その性能がユーザーの満足度に直結するため、日々性能改善が行われています。
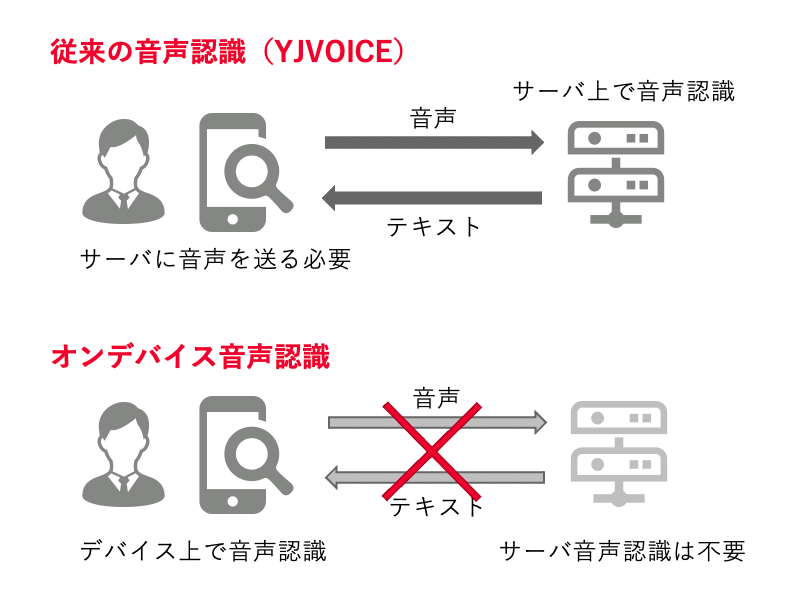
これらのアプリの音声認識は、サーバーサイドで処理が行われ、その結果がデバイス側に送られる仕組みとなっています。そのために、オフラインでの利用ができません。この問題を解決するためにヤフーでは、スマホ上(オンデバイス)で動作するEnd-to-End音声認識の実用化を目指し、現在研究開発を行っています。今回はその成果の一つとして、社内検証用のEnd-to-End音声認識技術を使ったデモアプリの開発と、その技術検証結果について詳しく説明します。
End-to-End音声認識とは?
ここでは、従来の音声認識とオンデバイスで動作可能なEnd-to-End音声認識の違いを説明します。
従来の音声認識の課題
YJVOICEで使われている従来の音声認識技術では、複数のモジュールを組み合わせて、音声認識が行われます。
YJVOICEでは、これらのモジュール一つ一つを丁寧にチューニングすることで非常に高い性能が得られています。
その一方で、そのままでは計算リソースの消費が大きく、オンデバイスで動かすことはできません。オンデバイスで動かすためには、モデルサイズの削減やデコードのパラメータチューニングなどが必要となり、大変な苦労を要します。
End-to-End音声認識の特徴とは?
近年盛んに研究の行われているEnd-to-End(E2E)の音声認識は、一つのニューラルネットワークからできており、シンプルな構成となっています。
これにより、モデルサイズや計算量の削減などのチューニングが従来型の音声認識と比較して容易に行えるようになりました。
このE2E音声認識を導入することで、サーバーに音声データを送信することなく、スマホだけで完結する音声認識が可能になります。
ヤフーの音声認識チームでは、従来型の音声認識の改善と並行して、E2E音声認識の研究開発を行っています。これらの成果をオンデバイスで動かして検証する目的から、音声認識チームでは2020年から社内検証用デモアプリの開発をスタートしました。2020年4月に新卒で入社した私は、社内検証用デモアプリの開発にアサインされ、主にモデル開発に携わることになりました。
スマホでの音声認識モデル
デモアプリ用モデルの条件
デモアプリ開発にあたって、研究開発中の高度なモデルではなく、まずは構造が簡単で軽量なモデルから検証していくことになりました。
この点から、デモアプリ用のモデル開発に求められていたこととしては、
- スマホで動かせるくらいに軽量であること
- 発話途中でもすばやく結果が表示されること(ストリーミング処理)
- 十分な精度が得られること
に加えて、短期間で開発ができることが求められました。
E2E音声認識のモデルの種類
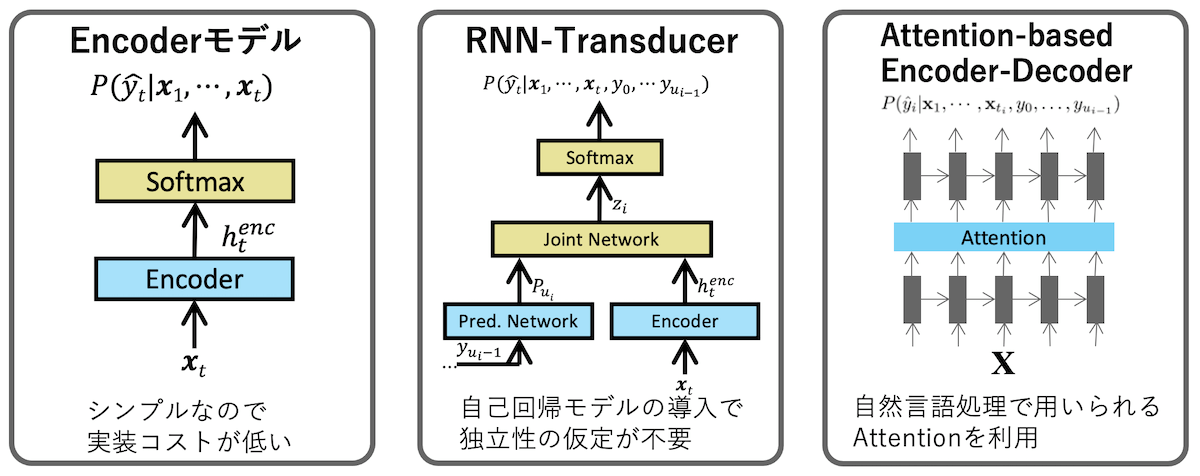
上図のように、E2Eのモデルには、
- CTC(Encoderのみのモデル)
- RNN-Transducer(RNN-T)
- Attention-based Encoder-Decoder
などがあります。
Encoderのみのモデルは、CNNやLSTMなどを使ったEncoderにより、音声の特徴量からテキストを直接予測するというモデルです。通常、音声の時系列長さと出力長さの系列長は異なっています。これを対応づけて学習するには、各出力シンボルがどの時刻の音声フレームと対応するのかを全てラベル付をする必要がありますが、音声認識の場合現実的ではありません。
それを解消する方法として、 CTC(Connectionist Temporal Classification)があります。これは、出力系列に対して、可能性のある全てのパスの出力確率から尤度が最大になるように学習する手法です。この手法では、ストリーミング処理ができ、RNN-TやAttention-based Encoder-Decoderと比較してデコードのアルゴリズムもシンプルになります。
自然言語処理の分野ではAttention-based Encoder-Decoderモデルを使って、系列長の違いを吸収する方法がよく使われます。この手法は音声認識でも用いられていますが、Encoderが音声を全て処理するまで結果が得られない、つまりストリーミング処理ができないというデメリットがあります。(MoChAなど、この問題を解決する手法もありますが、学習やデコード処理が複雑になったり、学習が不安定になる傾向があります)
RNN-TはCTCの改良版として登場したモデルです。CTCには、それぞれの出力間は条件付き独立であるという仮定を置いているために、言語的なつながりを明示的に学習できないという課題があります。
RNN-Tは、Encoderに自己回帰型のDecoderを組み合わせることで、この独立性の仮定をなくし、精度を向上させたモデルになっています。
ストリーミング処理が可能かつ精度が高いという点から、RNN-Tは近年盛んに研究開発が行われています。
モデルの選定
ここで、代表的なモデルの精度(データセットはLibrispeech test-clean)とパラメータ数を紹介します。
(ただし、言語モデル(LM)の有無やビーム幅等の実験条件はそろっていないため注意してください)

CTCベースのモデルであり、畳み込みニューラルネットワーク(CNN)からなるQuartzNet[1]は、モデルサイズが軽量でありながら高い精度で認識が可能なモデルです。また、CNNからなるためネットワーク構造もシンプルであり、CTCであるためにデコードも単純であるという利点があります。
論文のQuartzNetではストリーミング処理が可能であるものの、モデルの構造上レイテンシー(遅延)が非常に大きくなってしまいます。これについては、ある工夫により解決しました。その工夫については後の項で説明します。
Attention-based Encoder-DecoderベースのConformerは高い精度が得られていますが、通常Attention-based Encoder-Decoderモデルでのストリーミング処理は容易ではありません。
Conformer-Transducerは、精度とストリーミング処理可能な点で優れていますが、デコード処理が複雑になります。
今回は素早くデモアプリの作成と動作検証まで行う必要があり、なるべく早く開発を行う必要がありました。そこで今回は、構造・デコードがシンプルなQuartzNetをベースラインとして採用しました。
CNNを使った音声認識モデル QuartzNet
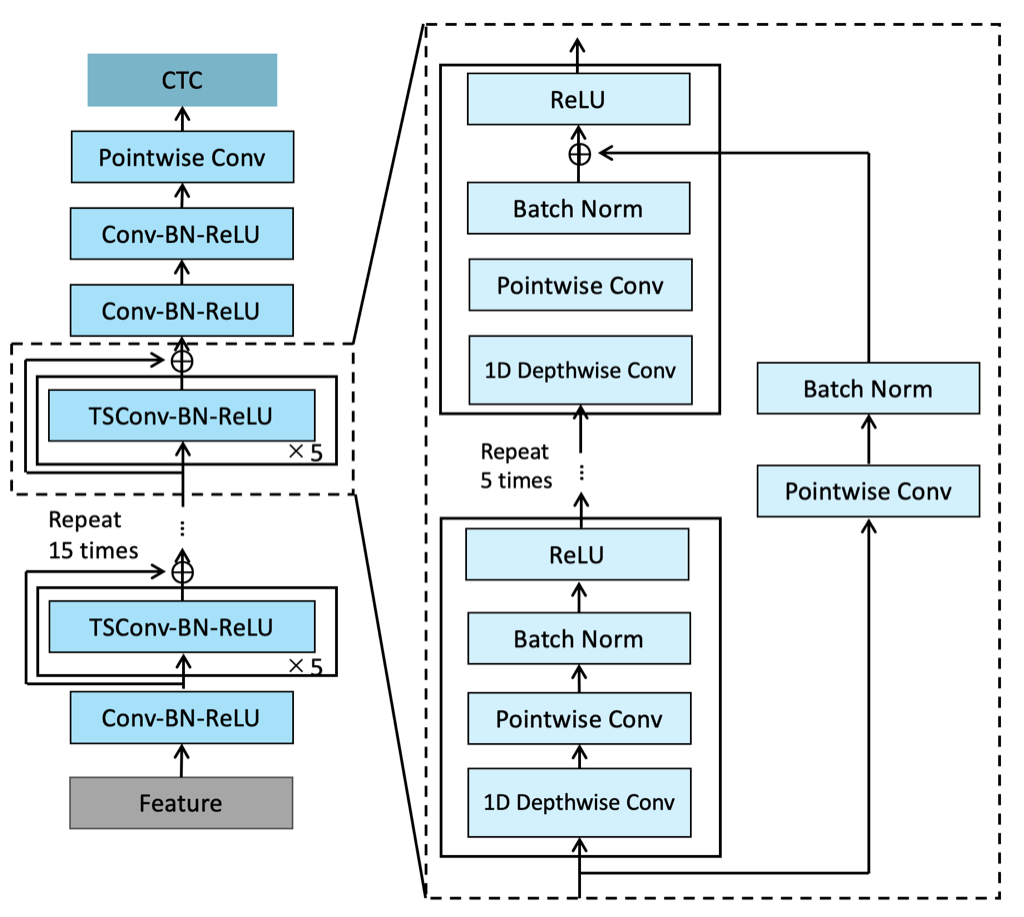
QuartzNetはNVIDIAが2020年に発表したモデルで、2019年に同じくNVIDIAが発表したモデルであるJasper[4]の改良版として発表されました。
QuartzNetとJasperの最大の特徴は、主に用いられているモジュールがCNNである点です。図のように、ResNetなどに特徴的な構造であるResidual Blockを多層化することで、単純な構造ながら、Transformerなどをベースとした最先端のモデルに近い精度が得られています。単純な構造であることで、実装が容易になり、それでいて高精度であるという点が今回のモデルの条件に適しています。
QuartzNetがJasperから進化したのは、Time-depth separable convolutionを採用したことで、軽量化を達成した点です。
通常、畳み込みでは大きなカーネルを、チャンネル数の二乗個用います。一方で、Time-depth separable convolutionでは、同様のカーネルをチャンネル数分だけ用いた畳み込みと、サイズの小さな1x1のカーネルをチャンネル数の二乗個用いた畳み込みの二つの畳み込みに分割することで、モデルの表現力を保ちながら、パラメータ数を削減しています。
QuartzNetではパラメータ数の削減により、Jasperより少ないパラメータ数で、カーネルを時間方向により長くできました。これにより、より長期の時間依存関係を学習可能にし、精度を改善しました。以上の点から、軽量でありながら高い精度を得られるため、スマホで動作する軽量なモデルを作成するのに適しています。
モデルの改良
レイテンシーを十数秒から120msに大幅削減
QuartzNetはストリーミング処理が可能であるものの、モデルの構造上レイテンシーが非常に大きくなってしまうという問題があります。ここでは、この問題を解決するための工夫について説明します。
QuartzNetでは、畳み込みに大きなサイズのカーネルが使われています。畳み込みを用いる場合、ある時点の情報を計算するために、その時刻以降の情報である未来のコンテキストが使われてしまいます。これによりQuartzNetでは、十数秒先までの未来のコンテキストをあらかじめ与えておく必要があり、レイテンシーが非常に大きくなってしまいます。(下図左側)
これを解決するために、非対称パディング(Asymmetric padding)[5]という手法を用いました。
通常の畳み込みでは、左右に同じ数だけパディングを施します。一方で、非対称パディングの場合には、左右非対称にパディングを行います。これにより下図右側のように、未来のコンテキストを使わずに畳み込みの結果を得られます。
ただし、完全に未来のコンテキストを無視するのではなく、少しだけ未来のコンテキストを使うことで精度が向上します。そのため本モデルでは、一部のパディングにおいて右側にもパディングを1フレーム分行い、120ms分だけ未来のコンテキストを利用するようにしました。
以上の工夫により、モデルの構造上生じるレイテンシーを十数秒から120msと大幅に削減することに成功しました。
| 通常のパディング | 非対称パディング |
|---|---|
 |
 |
Transformer decoder との joint training で23%の精度向上
今回のモデルでは、QuartzNetによるEncoderのみを用いて推論を行いましたが、学習時のみにTransformerを使ったDecoderを用いました。これにより学習が安定化し、23%の相対的な精度の向上が確認できました。
学習データの短さに対処し長時間の音声も予測可能に
今回用いた学習データは5秒以下の短い音声がほとんどでした。
その一方で今回用いたモデルのカーネルサイズは大きく、あるフレームの予測に18秒前の音声を使うようなモデルになっていました。
このようなミスマッチにより、5秒より先の部分のカーネルの学習が進まず、長時間の音声を推論した場合に正しい認識結果が得られないという問題がありました。
この問題を解決するために、今回はカーネルサイズと層の数を減らすことで、あるフレームの予測に2秒前までの音声を使うようにしました。これにより、カーネルから未学習の部分がなくなり、長時間の音声に対しても同じ精度で予測ができるようになりました。
iOSデモアプリの実装
続いてiPhoneで動作検証するためにデモアプリ作成を行いました。
iOSにはCore MLと呼ばれる、デバイス上でモデルの推論を行うためのライブラリがあります。Core MLを利用することで効率的かつ容易に推論を行えます。
PyTorchからCore MLへモデルの変換
今回学習した音声認識モデルはPyTorchを使って作成しました。
そのため、Core MLにモデルを変換する必要があります。
Core MLへは以下の手順で変換できます。
- PyTorchのモデルをTorchScriptに変換
- coremltoolsによりTorchScriptからCore MLへ変換
TorchScriptは、C++上でPyTorchを動作させるために作られたライブラリですが、TorchScriptを介することで、Core MLへの変換ができます。
ただし、メモリの領域を新たに確保するようなメソッドや未対応のメソッドがあると、Core MLへの変換ができません。そのため、それらのメソッドを避けるため、PyTorchのモデルの実装は一部書き換えを行いました。(単純なCNNのモデルでは起きない問題です。今回は非対称パディングの際にpadメソッドを使っていましたが、それがメモリのアロケーションを行うためにエラーを出していました)
Core MLへの変換は以下のようなコードにより実現できます。
import torch
import coremltools as ct
# PyTorchのモデルを読み込む
model = pytorch_model_create()
# モデルへの入力の定義
inp = torch.rand(128, 128)
# TorchScriptの形式に変換する
traced_torch_model = torch.jit.trace(model, inp)
# Core MLへの変換
mlmodel = ct.convert(
traced_torch_model,
inputs=[ct.TensorType(name="x", shape=inp.shape)]
)
# model.mlmodelという名前で保存される
mlmodel.save("model.mlmodel")Swift上での推論の実装
続いて、Core MLに変換したモデルをiPhone上で動かすために、Swiftでの実装を行いました。
実装が必要なのは
- マイクの音声を取り込む部分
- 特徴量抽出
- モデルの推論
- 推論結果を表示するUI
などがありますが、今回はモデルの推論部分にフォーカスして説明します。
Core MLによる推論は容易に実装できます。
モデルの推論部はMLModelによりモデルの読み込みを行えば、predictionメソッドにより推論が行えます。
特徴量については、特徴量をモデルに引き渡すためのクラス(MLFeatureProvider)を実装することで、モデルの入力として与えられます。
疑似的には以下のように実装できます。
import CoreML
// Feature Provider を定義 (featureを渡すためのクラス)
class FeatureProvider : MLFeatureProvider {
var featureNames: Set<String> {
get {
return ["x"]
}
}
let feature: MLMultiArray
init(feature: MLMultiArray) {
self.feature = feature
}
func featureValue(for featureName: String) -> MLFeatureValue? {
if featureName == "x" {
return MLFeatureValue(multiArray: self.feature)
}
return nil
}
}
// 推論を行う関数
func inference(input: MLMultiArray){
// modelの読み込み
let url = Bundle.main.url(forResource: "model", withExtension: "mlmodelc")
let model = try! MLModel(contentsOf: url!)
// featureを渡すためのインスタンスを定義
let provider = FeatureProvider(feature: input)
// 推論
let result = try! model.prediction(from: provider)
}デコードの実装
音声認識の場合には、モデルから得られた各文字の出力確率から、もっともらしい文字列に変換するためのデコードという処理が必要になります。
一般的には、幅優先探索の一つであるビームサーチにより、もっともらしい文字列を探索します。
ただし今回はデバイス上で動かすという点から、より軽量な探索手法として、Greedy decode と呼ばれる、出力確率最大のラベルを認識結果として用いる手法を用いました。Greedy decodeの実装は、Swiftを用いてモデルによる推論の後処理として実装しました。
実機検証の結果:速度は十分、モデルサイズも50MB以下に
以上のように実装したデモアプリで、実際に音声認識を行ってみました。
なお、アプリは「iPhone 11 Pro」上で動作検証を行いました。
その結果、認識精度については現行のYJVOICEには届いていませんが、「今日の天気」や「東京から渋谷までの行き方を教えて」などの基本的な音声検索の発話については正しく認識できていることが確認できました。
推論時間を音声の長さで割ることで算出される Real Time Factor(RTF)については0.2以下となり、音声認識における処理速度としては十分な速度を達成しました。
また、モデルサイズについては50MB以下となり、iPhone上にモデルをダウンロードして動かしても問題ないサイズであることが確認できました。
なお、今回は重みの量子化などのモデルサイズの削減手法は適用していません。それらを適用することで、さらなるモデルサイズの削減が期待できます。(例えば、モデルのパラメータを8bitにすれば、1/4までモデルサイズを削減できます)
おわりに
以上のように、QuartzNetと非対称パディングを組み合わせることで、低遅延かつ軽量なモデルを開発できました。さらに、作成したモデルを使ってiOS用のデモアプリを実装し、実機での検証まで行えました。
ただし、精度の面については現行のYJVOICEよりも劣るため、今後の研究開発で改善していきたいと思います。
音声認識分野で最も盛り上がっているE2E音声認識に取り組み、モデル選定から実装・学習までひととおり行えたのは学びが大きかったです。
また検証用であるため、実際にリリースはしなかったものの、iOS開発というユーザーの直接触れる部分まで携われたのは、非常によい経験になりました。
このように新卒であっても最先端の研究内容に携われるというのは、ヤフーのデータサイエンスチームの魅力だと思います。
ヤフー音声認識チームでは他にもさまざまな取組を行っているので、今後の続報をご期待ください。
(この記事に関連する採用情報「音声認識エンジニア・研究員」もぜひご覧ください)
参考文献
[1] Samuel Kriman, Stanislav Beliaev, Boris Ginsburg, Jocelyn Huang, Oleksii Kuchaiev, Vitaly Lavrukhin, Ryan Leary, Jason Li, Yang Zhang, “QuartzNet: Deep Automatic Speech Recognition with 1D Time-Channel Separable Convolutions”, ICASSP 2020
[2] Shinji Watanabe et al., ESPNet, https://github.com/espnet/espnet, (2021)
[3] Anmol Gulati, James Qin, Chung-Cheng Chiu, Niki Parmar, Yu Zhang, Jiahui Yu, Wei Han, Shibo Wang, Zhengdong Zhang, Yonghui Wu, Ruoming Pang, “Conformer: Convolution-augmented Transformer for Speech Recognition”, INTERSPEECH 2020
[4] Jason Li, Vitaly Lavrukhin, Boris Ginsburg, Ryan Leary, Oleksii Kuchaiev, Jonathan M. Cohen, Huyen Nguyen, Ravi Teja Gadde, “Jasper: An End-to-End Convolutional Neural Acoustic Model”, INTERSPEECH 2019
[5] Vineel Pratap, Qiantong Xu, Jacob Kahn, Gilad Avidov, Tatiana Likhomanenko, Awni Hannun, “Scaling Up Online Speech Recognition Using ConvNets”, INTERSPEECH 2020
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 山口 僚平
- 音声認識エンジニア
- End-to-End音声認識の研究開発を担当しています。データの力で日本をUPDATEしてきます。
-



