こんにちは。CTO直下のR&D組織であるテックラボにて、メディア処理系の研究開発に取り組んでいる志賀と三浦です。本記事ではYahoo! BEAUTYにおける「似ているヘアスタイル」表示機能の性能を改善した方法を紹介いたします。
Yahoo! BEAUTYと「似ているヘアスタイル」
Yahoo! BEAUTYは「好みのヘアスタイルからスタイリストを探せて出会えるサービス」として2019年12月にスタート。ヘアスタイルに関する検索、ヘアスタイル写真、スタイリスト情報、ヘアサロン情報などの機能やコンテンツを提供しています。
ユーザーが好みのヘアスタイルを見つけるための機能のひとつとして提供されているのが、ヘアスタイル詳細画面で表示された写真に対し、似ているヘアスタイルを掲出するモジュールです(表示例を以下に示します。モジュールを紫色の枠で囲んでいます)。このモジュールにより、似ているヘアスタイルを複数比較できるため、ユーザーの細かな好みやイメージに沿ってなりたい髪形を直感的に見つけることができます。
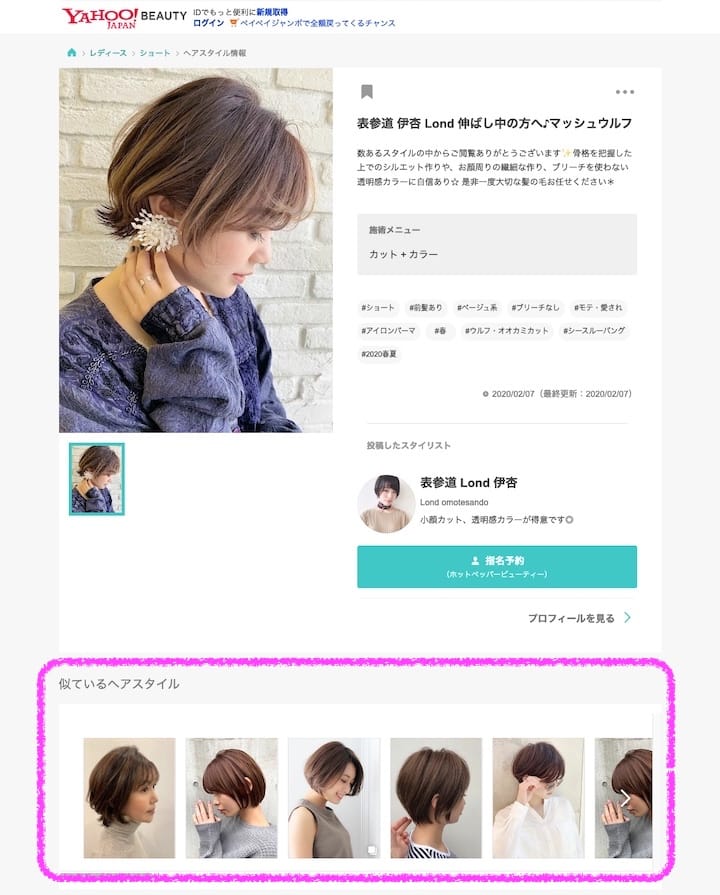
この仕組みをリニューアルすることで、以下の比較図のように、Beforeのように似ているとはいいがたい写真も表示されているところを、Afterのように近い雰囲気の髪形が表示できるようになりました。

これまでの精度の低いタグベースの手法
ヘアスタイル写真にはそれぞれ、投稿したスタイリストによって「ショート」「ベージュ系」「モテ・愛され」「2020春夏」のようなタグが付与されています。これまでは、これらタグの一致度をもとにした検索により似ているヘアスタイルを見つけていました。しかし、この手法には次のような点から、ユーザーが期待するヘアスタイルを見つけにくいという問題がありました。
1点目は、タグは抽象度が高いという点です。例えば、「ピンク系」というタグがついているヘアスタイルには暗めのピンクや明るめのピンクなどさまざまなピンクが含まれています。また、「ミディアム」というタグがついてるヘアスタイルは短めのミディアムや長めのミディアムなど、さまざまな長さが含まれています。
2点目は、「2020春夏」のような、関連性の低いタグが入力されることがあるという点です。これは入力されたタグが少ない場合に特に致命的であり、ヘアスタイルの特徴が似ているという観点からはバラバラな写真ばかり表示されてしまいます。
新たに採用した機械学習による画像ベースの手法
これらの問題を解決するために、新手法ではヘアスタイル写真を利用し、機械学習技術で似ているヘアスタイルを見つけます。似ているヘアスタイルを見つけるために、2つの特徴量を用います(抽出の概要を下図に示します)。
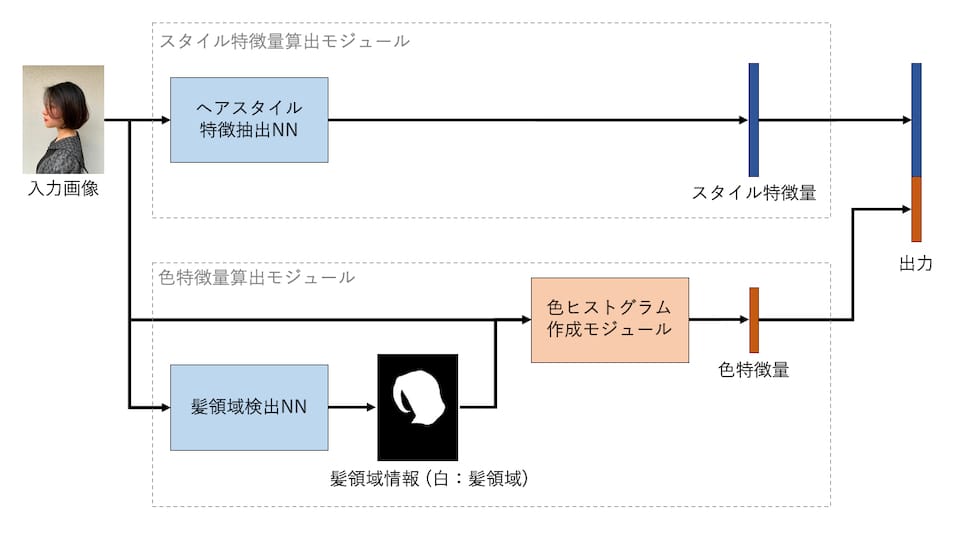
1つ目は、スタイル特徴量です。画像に対するタグ付けをマルチラベル分類問題とし、それを解くためのCNNを学習します。その中間層を特徴量とすることで、ヘアスタイルに特化した特徴量を算出します。この特徴量には、長さの微妙な違いを区別することや、学習により少数の誤ったタグの影響を排除することを期待しています。
2つ目は、色特徴量です。髪の領域を検出し、その領域内のカラーヒストグラムを特徴量として利用します。この特徴量には色の微妙な違いを区別することを期待しています。
スタイル特徴量
スタイル特徴量は、ヘアスタイル写真に写る髪形の特徴を表現します。ここで表現する特徴は、「ショート」「セミロング」といった長さをはじめとして、「マッシュ」「ひし形」などのシルエットや、「ワンカールパーマ」「外ハネ」のような毛先の動き、果ては「クール」「ガーリー」といったニュアンスや印象など、多岐にわたります。これらの特徴を抽出・表現するために、ひとつひとつに対してルールや画像特徴を設計するのは現実的ではありません。そこで、CNN (Convolutional Neural Network) を利用することを考えます。
まず、ヘアスタイル写真に付与されるタグの中から、付与される頻度が高いもの、および、似ているヘアスタイルを検索する基準として重要と思われるものを選定します(その結果、100程度のタグが選定されました)。次に、ヘアスタイル写真とそれに付与されたタグを学習データとして、マルチラベル分類を行うCNNを訓練します。ここで利用するCNNのアーキテクチャはXception [1] で、精度と速度のバランスの観点から適切であることを予備実験で確認しています。最後に、訓練されたCNNの中間層を取り出し、スタイル特徴とします。マルチラベル分類の訓練では入力画像に対して各タグが付与されるべきかどうかを学習しますが、訓練されたCNNの中間層は、それらタグを判別するための特徴を良く抽出できていると考えられます。
色特徴量
色特徴量は、髪領域における色の分布を表現します。色特徴量を算出する処理は以降に述べる2つのステップからなります。
まず、画像から髪の領域を検出します。この検出はニューラルネットワークを用いてセグメンテーションの問題として解くことができます。ここで利用するニューラルネットワークは、ResNet101 [2] をバックボーンにしたPSPNet [3] で、ヘアスタイル写真とそれに対応するマスク画像(髪領域とそれ以外の領域が塗り分けられている画像)の約1000ペアで訓練しています。
次に、検出された髪領域において、カラーヒストグラムを作成することで色の分布を表現します。ここでは画素値をL*, a*, b*色空間(CIE 1976色空間)に変換した上で量子化し、ヒストグラムを作成します。このヒストグラムを正規化したものを色特徴量としています。色を手がかりに画像の類似度を算出する手法にはさまざまなものがありますが、このようなシンプルなヒストグラムの作成でもある程度満足のいく検索精度が得られることを実験的に確認しています。
特徴量の結合
スタイル特徴量と色特徴量とを組み合わせることで、似ているヘアスタイルが検索できます。組み合わせ方はいくつかのパターンが考えられますが、開発段階での検討やABテストでの評価の結果、2つの特徴量を特定の重みを付けて連結 (concatenate) するのが良いという結論が得られました。
ABテストとその結果
ABテストの結果、従来のタグベースの手法と比べ、画像ベースの手法を用いた場合では「似ているヘアスタイル」モジュールに掲出された写真のクリック率 (CTR) が約113%に上昇しました。
あるヘアスタイル写真に対する掲出の比較例を以下に示します。本例は3列からなり、左から順に、クエリのヘアスタイル、タグベースで見つけた似ているヘアスタイル、画像ベースで見つけた似ているヘアスタイルです。

従来手法では、髪の長さやカラーがまちまちであるなど、検索が大ざっぱなことがわかります。前述したとおり、タグの一致度で検索するため、タグの持つ抽象度の高さや、タグを付けるスタイリストごとの基準のばらつきに影響されていると考えられます。
一方で、画像ベースの手法では、より似ているヘアスタイルが提示されています。画像から特徴を抽出することで、タグに比べて詳細な特徴を画一に抽出できているためだと考えられます。例えば色について、「アッシュ系」などのタグを手がかりにして似ている写真を検索するよりも、髪領域のカラーヒストグラムを用いて定量的に類似度を測る方が、より良い検索結果を得られることが想像できるでしょう。
さらに画像ベースの手法では、タグで示されていない特徴をもとに似ているヘアスタイルが表示されていることも特筆すべきでしょう。例えば、タグでは髪の詳細な長さ(あごくらいまでの長さ)や丸めなシルエットには触れられていませんが、画像ベースではこれらの観点で似ているものが掲出できています。以上のように、画像ベースの手法がより詳細な特徴を正確に捉えてヘアスタイルを検索できており、そのためにCTRが向上したと考えられます。
まとめと今後の課題
似ているヘアスタイルを検索・掲出する機能について、ヘアスタイル写真を活用して精度を改善する取り組みを紹介しました。抽象度が高くばらつきの大きいタグをベースにした従来手法に対し、写真から髪形や色の特徴を取り出すことで、より詳細にヘアスタイル間の類似度を測る手法を開発しました。
今回採用した特徴量の抽出手法は比較的シンプルなものですが、まだまだ改善の余地があります。例えば、スタイル特徴量を抽出するCNNの学習において、ArcFace [4] のような分類性能を高めるための損失関数を導入することが考えられます。また、色特徴の抽出についても、照明など撮影環境の違いに頑健な手法や、インナーカラーやメッシュなどのワンポイントカラーを良く表現できるような手法が考えられそうです。これらの改善を通して、ユーザーが理想のヘアスタイルを見つける体験をより良いものにしていくことを目指します。
「似ているヘアスタイル」機能はYahoo! BEAUTYでお試しいただけます。ぜひ触ってみてください。
関連リンク
- Yahoo! BEAUTY、独自AI技術を活用した、類似ヘアスタイル写真表示機能を提供開始(プレスリリース)
- サービス紹介ページ(Yahoo! BEAUTY)
参考文献
- F. Chollet, “Xception: Deep Learning with Depthwise Separable Convolutions,” IEEE Conf. Computer Vision and Pattern Recognition (CVPR), pp. 1800-1807, 2017.
- K. He et al., “Deep Residual Learning For Image Recognition,” IEEE Conf. Computer Vision and Pattern Recognition (CVPR), pp. 770-778, 2016.
- H. Zhao et al., “Pyramid Scene Parsing Network,” IEEE Conf. Computer Vision and Pattern Recognition (CVPR), pp. 6230-6239, 2017.
- J. Deng et al., “ArcFace: Additive Angular Margin Loss for Deep Face Recognition,” IEEE Conf. Computer Vision and Pattern Recognition (CVPR), pp. 4685-4694, 2019.
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 志賀 優毅
- CTOテックラボ 機械学習エンジニア
- 三浦 衛
- CTOテックラボ 機械学習エンジニア