こんにちは。サイエンス統括本部でYahoo!ショッピングやPayPayモールのおすすめ機能(レコメンドシステム)の開発を担当している正沢です。
この記事では、別々に作られた複数の機械学習のバッチジョブ管理システムをApache Airflow(以降、Airflowと記載します)に集約して、運用負荷を低減した事例を簡単なシステム構成とともに紹介したいと思います。
※ レコメンドシステムの開発ではプライバシーポリシーの範囲内で取得したデータを用いて行っています
Yahoo!ショッピングのレコメンドとは?
Yahoo!ショッピングやPayPayモールには、ユーザーがなにか商品を見ている時に、他にも興味を持ってもらえそうな商品を推薦するレコメンドシステムがあります。
代表的な例としては
- 今見ている商品に関連する商品を提示する
- 今カートに入っている商品と一緒に買われやすいアイテムを提示する
- ユーザーが最近見ていた商品から関心のありそうな商品を提示する
などがあります。
Yahoo!ショッピングの成長とともにレコメンドは増え続けており、現在では表示するページやモジュールに合わせて100以上の掲載面で、60種類以上のモデルが稼働しています。
そして、100以上のレコメンドを支えるため、レコメンドシステムでは機械学習のバッチジョブが日夜回っています。
この記事では便宜上、今見ている商品に関連する商品を提示するレコメンドシステムを前提とした記述をしています。
機械学習バッチジョブとは?
機械学習のバッチジョブと聞いて皆さんはどのようなものを思い浮かべるでしょうか?
一般に機械学習、中でもラベルデータのある教師あり学習では、「学習フェーズ」と「推論フェーズ」があるという話はいろいろなところで紹介されていると思います。
そのため、機械学習のバッチジョブとして想像しやすいのは「学習フェーズ」だと思いますが、この記事におけるバッチジョブは「推論フェーズ」のことです。
推論フェーズをバッチジョブとして行うのは、入力データのバリエーションに対して推論結果の利用が非常に多い場合に適しています。
アクセスがあるたびにモデルで推論を行うよりも、事前に想定されるバリエーションの推論結果を保存しておいて参照する形の方がレスポンスが早くなりシステムの負荷も少なくなるためです。
今見ている商品に関連する商品を提示するレコメンドシステムでは入力データとなる「今見ている商品」の種類分だけレコメンドモデルで推論を行い、レコメンドするべき「関連する商品」のリストをKVSに保存しておくことでユーザーを待たせることなく関連する商品をおすすめできるようにしています。
レコメンドの仕組み
レコメンドのための機械学習バッチジョブは大きく3つのバッチジョブで構成されています。
- マッチング
- 今見ている商品に関連する商品の集合を抽出する
- リランク
- 商品の集合をユーザーが最も興味をもつと考えられる順序に並び替える
- フィーダ
- レコメンドデータをKVSにフィードする
マッチングとリランクによって生成されたレコメンドデータはフィーダでKVSにフィードされ、レコメンドAPIでフロントエンド(FE)に対して配信しています。
- KVS(Key-Value Store)
- リランクが完了したレコメンド元商品と、レコメンド商品の組み合わせを保存しておくCassandraクラスタ
- レコメンドAPI
- フロントエンドからのリクエストに応じてレコメンド商品を返却するAPI
これらの仕組みが安定的に稼働すると、サービスを訪れたユーザーに興味のありそうな商品をおすすめできます。
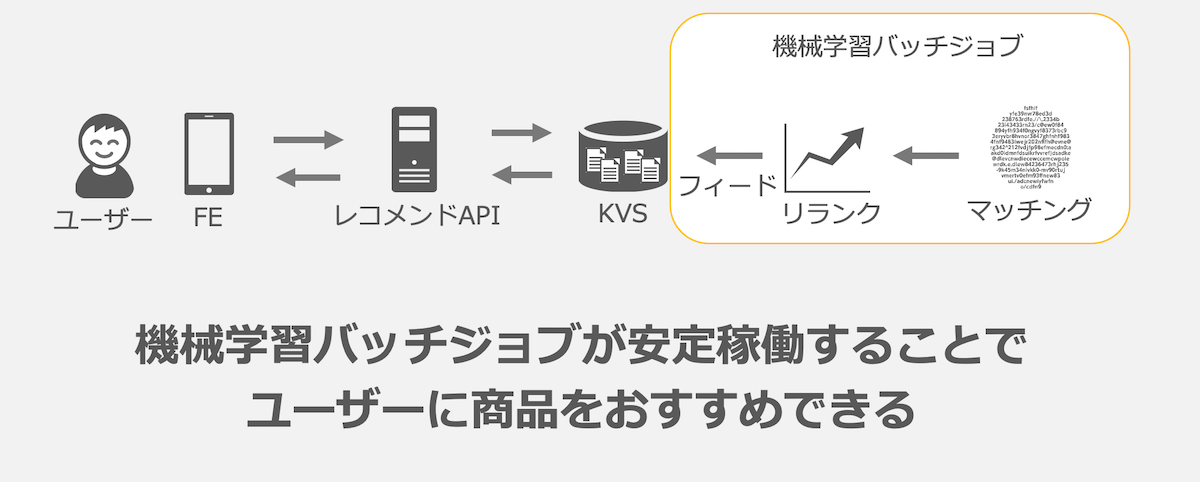
ただ、これらのバッチジョブは依存する社内システムや開発時期の違いなどによって別々に開発・運用されていました。
課題:夜中にアラートが鳴り原因究明に時間がかかる
もともとは別々のシステムでもそれぞれうまく回っていました。ただ、嬉しい悲鳴ですがYahoo!ショッピングの成長とともに各バッチジョブが重くなり長時間回るようになるにつれて、問題が起き始めます。
さまざまな要因はあるのですが、代表的なものとしてはマッチングジョブで利用するアクセスログなどの集計に遅れが発生した場合や、重いフィードジョブが複数同時に実行されKVSに負荷が集中する事象が発生した場合にレコメンドAPIでアラートが鳴り響きます。また、後ほど紹介するCaaSで動作していたフィーダには実行時間の制限があり、フィードするデータが大規模になるにつれてフィードを打ち切られてしまうことがありました。
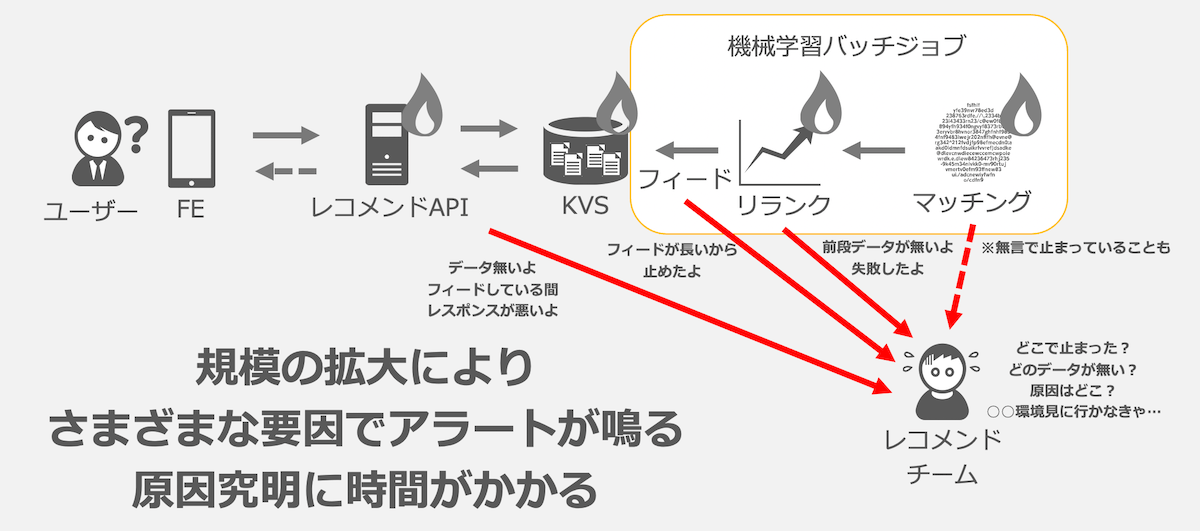
就業時間中に発生する分にはバッチジョブの再実行や走りっぱなしになってしまっているバッチジョブの強制停止など対応をしていましたが、集中して業務に取り組んでいる際にアラートが発生すると業務効率の低下につながります。
また、バッチジョブは24時間回っていますので、夜間にアラートが鳴ることもありました。夜間対応を行った翌日は業務時間の調整を行うのですが、どうしても安心して眠れる時間が短くなるため運用を担当した時は業務のパフォーマンスに影響が出てしまいます。
解決策:AirflowとKubernetesの導入
最初にバッチジョブ管理の構成とありたい姿を紹介します。
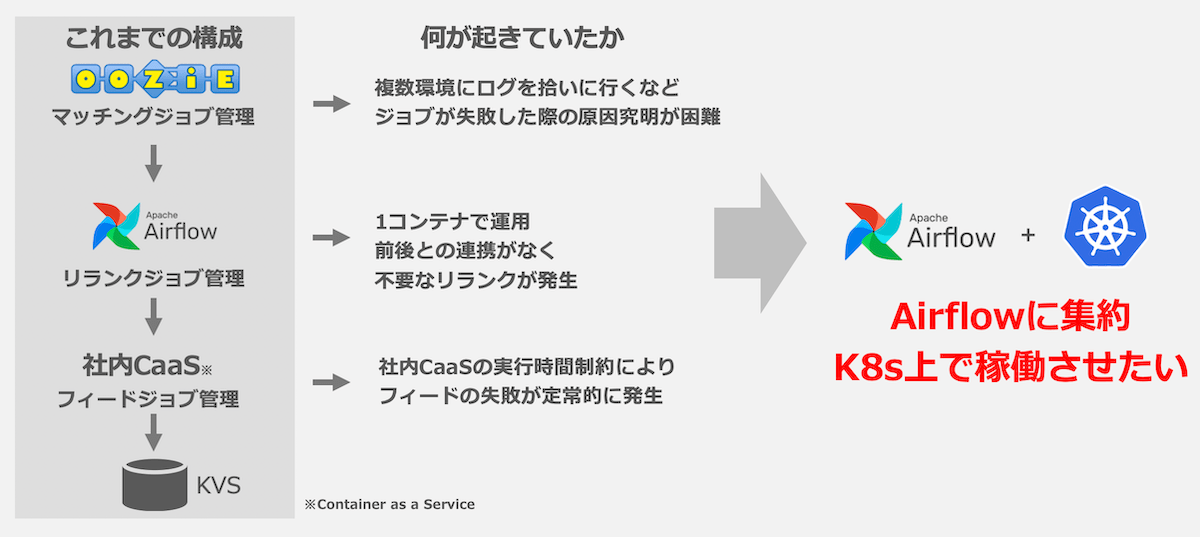
これまでマッチングジョブ、リランクジョブ、フィードジョブはそれぞれApache Oozie(以降、Oozieと記載します)、Airflow、社内CaaSの上で動いていました。
それぞれ自分のチームでマネージしなくて良い、Hadoop等の学習リソースとの相性が良いなどのメリットもあったのですが、規模が大きくなるにつれてデメリットが目立つようになってきました。個別の問題以外にも、バラバラに運用していることで、1つの原因でもアラートが複数飛んでしまう問題もありました。
Kubernetes上でAirflowを運用すれば、全体を1つのバッチジョブ管理システム上で動かすことができます。私たちのチームではこの構成することでこれまでの構成のメリットを上回るメリットを得られると判断しました。
Airflowを選んだ理由
Airflowを選択した理由は大きく3つです。
- DAG(Directed acyclic graph※)をPythonで記述することができる
- OozieはXMLでの記述で見通しが悪く管理が煩雑だった
- Poolによる負荷の集中を避けられる
- フィードジョブが集中するとKVSのReadのレイテンシに悪影響があった
- UI上から一元的に実行状況の制御とログの確認ができる
- 各ジョブ管理システムをそれぞれ確認していた
※ DAGはAirflowで実行されるバッチジョブ(Airflow内ではタスクと呼ばれます)の定義や実行順序などを記載するものです。
これ以外にもAirflowは私たちのチームに適した特徴を有していました。
- Kubernetes pod operatorを利用することで社内CaaSからの移行が容易である
- 社内CaaSではDocker Imageを定期的に実行していた
- チームに運用経験がある
- リランクではすでにAirflowを使っていた
これらは会社やチームによって異なるとは思いますが、Airflowの学習コストをかけても最初の3点が得られるのは大きなメリットになると思います。
Kubernetesを選んだ理由
Kubernetesを選択した理由は大きく3つです。
- 社内で利用できるリソースの中でも制約が少ない
- 社内CaaSや仮想機上のCronJob等に比べてリソースの制約が少なかった
- Airflowの運用で複数コンテナを使いたい
- Airflowを単一コンテナで実行するとスケールさせにくい問題があった
- リソースの監視をPrometheusとGrafanaで行うことができる
- ヤフーのKubernetesはPrometheusとGrafanaに連携されており、リソースの不足などをすぐに確認できる
導入後の仕組み
導入後の監視/運用の仕組みは下図のような形になりました。
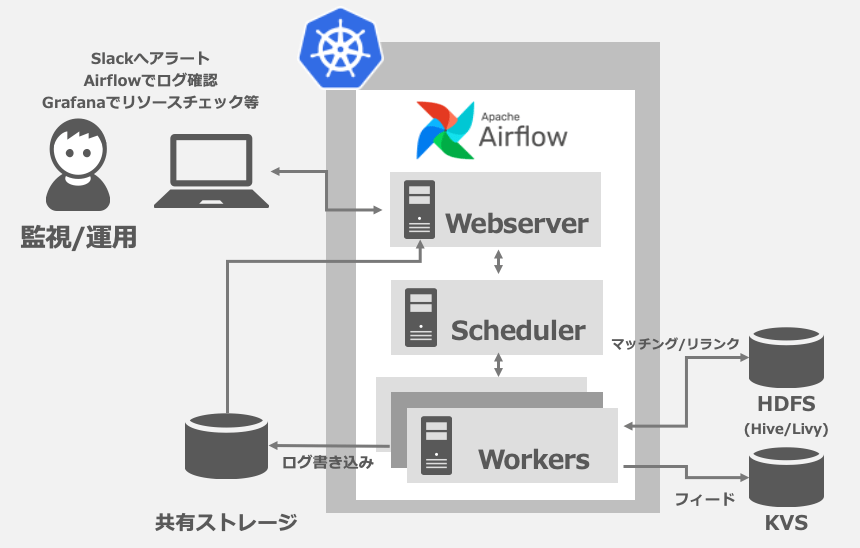
監視はGrafanaを用いてKubernetesクラスタの負荷状況を監視できるようになっています。これは社内のKubernetesクラスタに備わっている機能で、別々のシステムになっていた頃よりも一覧性が上がりました。
エラー発生時はただエラーが発生したDAG名を記載した通知を飛ばすのみだったのですが、実際に運用してみると初動はログの確認であるパターンが多くなっていました。そこで以下のようなSlackの通知がチーム宛に飛び、通知からスムーズに初動の対応が行えるようになっています。

頻繁に更新するDAGはパッケージとして管理しており、開発は下図のような形で実施しています。
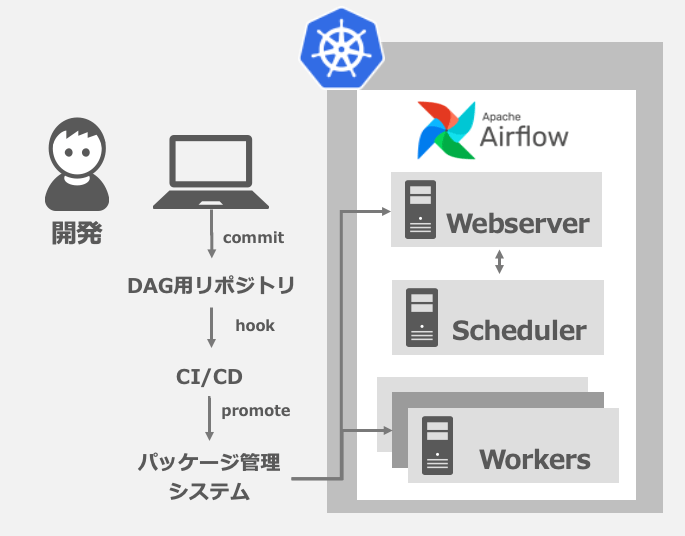
KubernetesのConfigMapを利用した方法でDAGをデプロイすることも検討できるのですが、管理するDAGが多く、よりスケーラビリティの高いパッケージとして管理しています。
この仕組みを実現する上で一番私が悩んだのはリポジトリをいくつに分けるかでした。全て1つのリポジトリに入れることも可能ではありますが、管理のしやすさやCI/CDとして扱いたい単位を考慮して試行錯誤を行い、以下のような形に落ち着きました。
- 各DockerImage用リポジトリ
- Airflow用DockerImageを管理
- 社内の認証システムのためのサイドカーコンテナ用DockerImageを管理
- DAGの更新サービスをもつサイドカーコンテナ用DockerImageを管理
- Kubernetes用リポジトリ
- Kustomizeを利用してCI/CDツール内でyamlを更新して開発環境や本番環境向けにリリースし分けられる
- DAG用リポジトリ
- DAGやAirflowのPluginをパッケージ化してリリースできる
これまでの構成とこれからの構成を下図にまとめました。
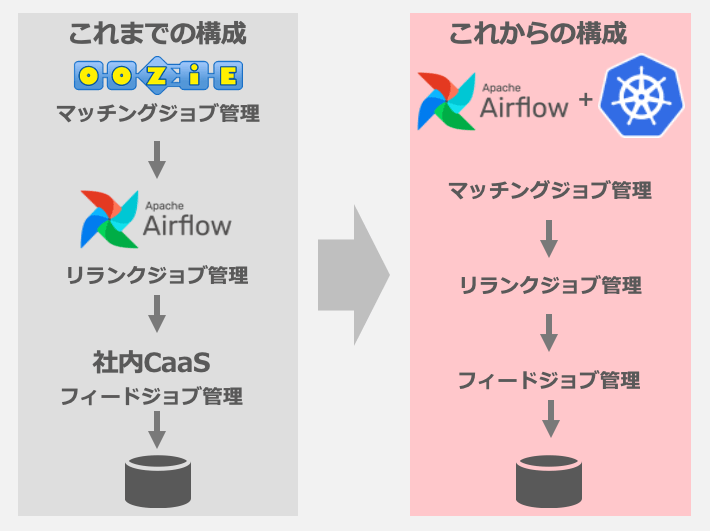
スケジューリングを一元的に管理することで、HDFSやKVSへの負荷をハンドルしやすくなりました。これによりリクエストの増加が見込まれる大規模イベント時に各バッチジョブをUIから手軽に負荷低減や停止・再開のオペレーションをすることができるようになっています。
結果:バッチジョブ起因の夜間対応がほぼ0に
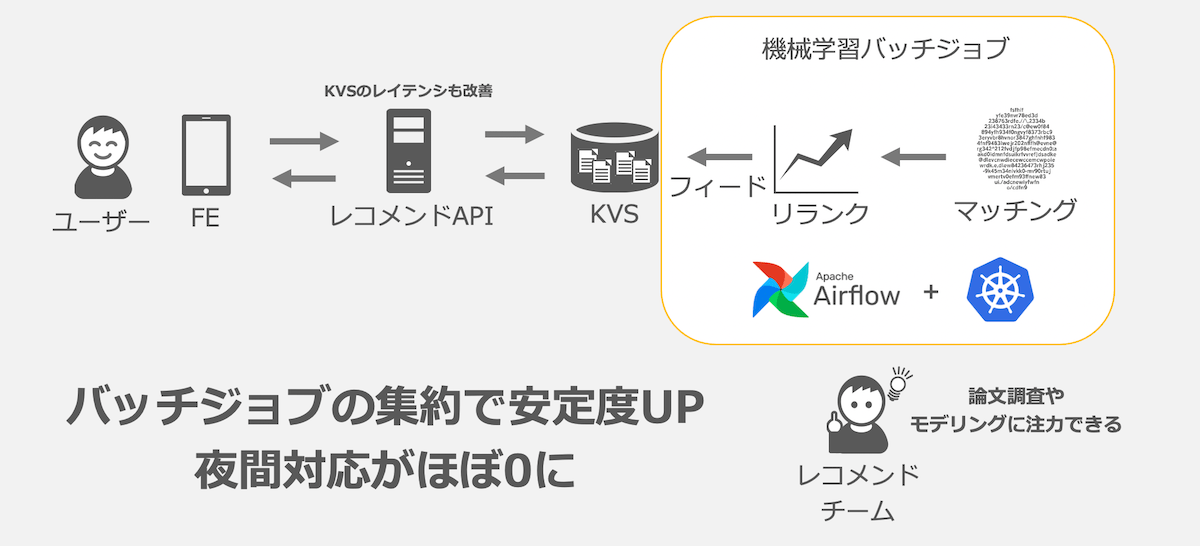
全体を通してスケジューリングされたことや、AirflowのPool機能などを用いて過負荷を防ぐことで、夜に手動での対応が必要なアラートが鳴ることはほぼなくなりました。仮にアラートが発生した場合にも一元管理されたログから即時対応を行うことで、サービスへ影響が及ぶ可能性をより小さくすることができるようになりました。
今回はレコメンドシステムの機械学習バッチジョブを支えるシステムについて紹介しましたが、私たちは運用だけでなくモデル改善やシステム開発がメインのミッションです。
Yahoo!ショッピングやPayPayモールを訪れた際にユーザーが使いやすく興味を持ってもらえるレコメンドシステムを目指して、今後も大規模なデータや機械学習などの技術を活用して改善を続けていきたいと思っています。
Apache®, Apache Airflow™, Airflow™, Apache Oozie™, Oozie™及びAirflowのロゴ, Oozieのロゴは、米国および/またはその他の国におけるApache Software Foundationの商標または登録商標です。
Kubernetes®及びKubernetesのロゴは、米国および/またはその他の国におけるLinux Foundationの商標または登録商標です。
The Kubernetes logo files are licensed under a choice of either Apache-2.0 or CC-BY-4.0 (Creative Commons Attribution 4.0 International).
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 正沢 道太郎
- 機械学習エンジニア
- 主にYahoo!ショッピングやPayPayモールに対して機械学習の施策によるサービス改善を担当しています。
-



