こんにちは。ヤフーの相良と言います。クラウドプラットフォーム本部で、ヤフーの次世代IaaS基盤を検討しています。
12月24日、クリスマスイブの本日の記事では、ヤフーの次世代IaaS基盤の取り組みをご紹介したいと思います。最初に次世代IaaS基盤の取り組み背景をご紹介し、検証・評価中のKubeVirtという技術について、IaaS基盤の代表的ソフトであるOpenStackと比較することで、その特徴を説明します。最後に、大規模環境を扱うヤフーならではの課題についても触れたいと思います。
なお、本記事では2020年12月時点の最新版(v0.36.0)のKubeVirtを前提にご説明します。
ヤフーの次世代IaaS基盤の取り組み
ヤフーではOpenStackで構築したIaaS基盤を長い間、大規模に運用してきました。過去にイベントなどでも紹介していますので、もしかしたらご存じの方もいらっしゃるかもしれません。クラスタ数が200以上、ハイパーバイザが20000台以上という非常に大きな規模のIaaS基盤を独自に構築、運用しています。
OpenStackで構築したIaaS基盤が活躍している一方、クラウド基盤の分野ではCaaS(Container as a Service)基盤であるKubernetesも大きな発展を遂げています。KubernetesはReconcile loopによるセルフヒーリングが強力で、クラスタを構成するノードの一部が故障した場合でも、その上で動作していたリソースは他のノードで自動で再作成されます。ヤフーでは大量のサービス・クラスタを管理する必要があるため、こういった運用自動化ができることは大変重要になります。またKubernetesをベースとすることで、コンテナ基盤と操作性・利用技術の点で親和性の高いIaaS基盤を実現できる可能性があります。
こういった背景から、ヤフーではKubernetesを軸に次世代IaaS基盤の検討を進めています。
KubeVirt
Kubernetesはコンテナを管理する基盤です。KubernetesでIaaSを実現するには、VMを操作するための追加の仕組みが必要になります。Kubernetesのコントロールプレーン(制御の仕組み)を活用し、VMを作成・管理する仕組みを提供するのがKubeVirtです。
KubeVirtはRed Hat社を中心にコミュニティ開発されています。既にライブマイグレーション、SR-IOV、NUMA、CPU Pinning、GPU対応などさまざまな機能を備えています。既存機能に加えて下記の点から、筆者は今後のKubeVirtの継続的な発展を期待できると考えています。
- NFV領域でのVNF・CNFの運用基盤としての期待
- oVirtからの移行
通信事業者がコアネットワークのネットワーク処理のため高価な専用機器を用意するのではなく、汎用的なサーバーを利用して低コストに処理を実現するNFV(Network Functions Virtualization)という取り組みが進んでいます。NFVでは、当初はVNF(Virtual Network Functions)というVM上でネットワーク処理を実施する方式が検討されていましたが、最近ではCNF(Cloud Native Network Functions)というコンテナ上でネットワーク処理を実施する方式の検討も進んでいます。KubeVirtはVMのみでなくコンテナも管理できることから、VNFとCNFの両方を対象にできる基盤として期待されています(Open Source Summit North America 2018: Cloud-native Network Functions (CNF) Seminarセッション)。市場規模の大きい通信事業者が必要とする細やかな管理機能に対応するため、企業の開発リソースがKubeVirtに継続的に投下されることが期待でき、今後の製品の発展につながるのではないかと筆者は考えています。
またKubeVirtのユーザーガイドを読むと、oVirtというソフトからの移行を想定した記載を見かけます。oVirtの開発者向けドキュメントにも、KubeVirtへの段階的な統合に関する記載(VM lifecycle in Kubevirt)が存在します。oVirtはRed Hat社が大規模仮想化環境向け管理製品として提供しているRed Hat Enterprise Virtualizationのコミュニティプロジェクトです。OpenStackのようなセルフサービス型のクラウド基盤は不要なものの、KVMとvirt-managerの組み合わせでは不足している細やかな管理機能を必要とする利用者向けの製品となっています。oVirtが提供している管理機能がKubeVirtでもサポートされていくことで、VMを管理する上で十分な機能を持つソフトになることが期待できます。
上記の2点からKubeVirtについて今後の発展が期待できると筆者は考えていますが、一方で本番環境での運用実績はまだ多く聞きません。KubeVirtのバージョンも(2020年12月時点で)v0.36.0とまだ新しいため、今後仕様変更が行われる可能性も高く、現時点でプロダクションレベルと言って良いかは難しいところです。以上の背景から、変更に柔軟に対応する覚悟で利用する必要があります。
KubeVirtの仕組み
KubeVirtはKubernetes上にクラスタアドオンとしてインストールします。VM作成先には、コンテナ起動のための通常のWorkerノードをそのまま利用できます。
KubeVirtをインストールすることで、下図のようにWorkerノードにはDaemonSetでvirt-handlerというPodが作成され、VMの起動が可能になります。VM作成時にはvirt-launcherというPodが作成され、このPod内のlibvirtを利用して、KVMでVMを作成します。
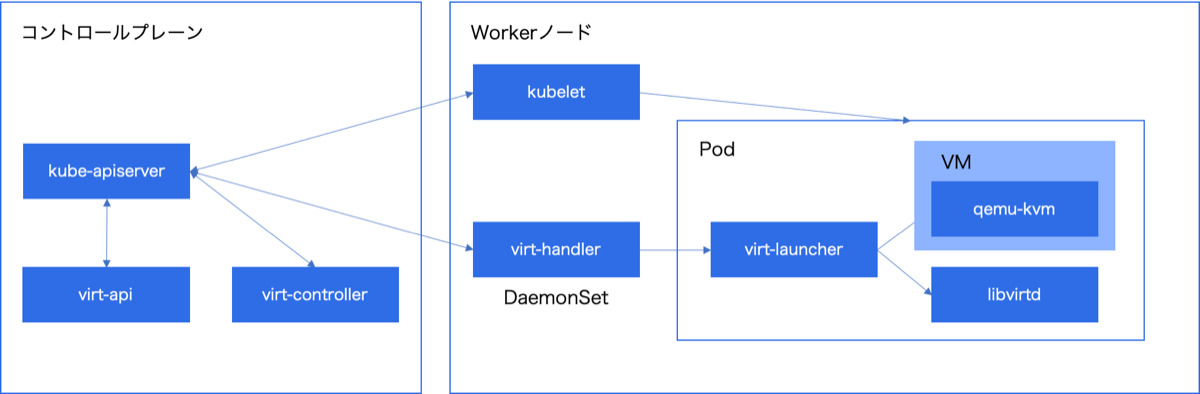
次にネットワークとストレージについて説明します。VMのネットワークはコンテナと同じくCNI、ストレージに関しても同様にCSIにインテグレーションされています。そのためVMとコンテナで共通のネットワーク・ストレージにアクセスが可能になっています。
以上のような仕組みから、VMを徐々にコンテナに移行する、VMとコンテナ双方が存在するハイブリッドなシステム(ユーザーアプリケーション)を運用するなどの用途に向いているといえます。
PodとKubeVirt VMの共通点と差異
前述の通りネットワークはCNI、ストレージはCSIとインテグレーションされているため、通常のPodと同じリソース(ServiceやIngress、PersistentVolumeなど)にアクセスできます。
一方で、現時点のKubeVirtには、PodのReplicaSet/StatefulSet相当のVirtualMachineInstanceReplicaSetリソースはあるものの、ローリングアップデートを実現するDeploymentに対応するリソースは用意されていません。またVMの高可用性を実現するLiveness Probeは、Podで利用できるprobe方法をすべてサポートできておらず、httpとtcpのprobeのみ対応し、任意のコマンドでのprobeは対応していません。
このように、PodとVirtualMachineのリソースは透過的に置き換え可能ではなく、VMに対してKubernetesのPodの使い勝手をそのまま提供できるわけではありません。そのため、Kubernetes OperatorでのVMの運用自動化を期待すると難しい点が出てくるかもしれません。このあたりは注意して利用を検討する必要があります。
OpenStackとKubeVirtのアーキテクチャ比較
本章ではさらに踏み込んで、IaaS分野を知る方にはなじみの深いOpenStackと「KubernetesとKubeVirtで実現するIaaS基盤(以下KubeVirt)」を比較することで、IaaS基盤設計者・管理者の視点でその違いを説明していきたいと思います。なお、KubeVirtの特徴ではなくKubernetes由来の特徴については、Kubernetesと明記して説明します。
コンピュート
VMの起動方法についてKubeVirtでは前述の通りの違いがありますが、スケジューリングについてもOpenStackとKubernetesでは違いがあります。
OpenStackはnova-scheduler(およびPlacementサービスで)VMのスケジューリングを行います。最も利用されるスケジューラフィルターはHostAggregate機能を利用したものだと思います。クラウド基盤管理者は、HostAggregateという単位でコンピュートノードを事前にグルーピングし、key-value情報を設定しておきます。またflavorにもkey-value情報を設定しておきます。利用者はVM起動の際にflavorを指定することで、HostAggregateとflavorのkey-value情報が照合され、適切なノードが選択されます。このような仕組みにより、クラウド基盤管理者の設計でVMが利用するノードを制限できます。
Kubernetesもkube-schedulerというコンポーネントでスケジューリングを行います。Kubernetesはラベルセレクターという機能を利用します。クラウド基盤管理者が、Workerノードにkey-value情報を事前設定しておく点は同じです。利用者はマニフェストにkey-value情報を記載することで、ノードとマニフェスト中のkey-value情報が照合され、適切なノードが選択されます。
ここまでの仕組みは類似していますが、Kubernetesの場合、利用者は利用したいノードを直接指定することも可能です。またスケジューラーもクラスタのデフォルト以外のものを指定できます。Kubernetesではノード選択の自由が利用者に与えられている印象を受けます※1。この仕組みの違いは、当初からマルチテナントを想定して設計されているOpenStackと、シングルテナントを想定しNamespace機能によりマルチテナントを実現しているKubernetesとの設計思想の違いに見えます。
※1 OpenStackにもVMの起動先ノードを直接指定する機能は存在しますが、デフォルトの権限設定ではadmin権限を持つ利用者のみが利用可能となっています。
認証・認可
OpenStackはKeystoneで認証・認可を行います。KeystoneはOpenStack内の管理データベース、または外部の認証・認可基盤と連携してユーザー・プロジェクト・グループの情報を管理します。
Kubernetesではkube-apiserverの内部にプラグイン方式で認証・認可の仕組みが提供されています。Kubernetes内部にユーザーのデータベースを持つことは基本的になく、外部の認証基盤との連携が必要になります(ServiceAccountという仕組みもありますが、こちらはアプリケーション向けにトークンベースのアクセスを提供する機能となっており、利用者の通常の操作に利用するものではありません)。また認可についてはRole、RoleBinding、ClusterRole、ClusterRoleBindingなどのリソースで、対象リソースや操作単位に柔軟な指定が可能になっています。外部の認可基盤との連携も可能です。
イメージ管理
OpenStackはGlanceでイメージ管理されています。KubeVirtではVMイメージを利用可能にするため、下記の2つの方法を提供しています。
- a. (通常のKubernetesと同じく)コンテナレジストリの利用
- b. Containerized Data Importerの利用
前者は、VMイメージを /disk ディレクトリにファイルとして持つコンテナイメージとして作成します(VMイメージをコンテナイメージ用のフォーマットで軽く包む感じです)。このコンテナイメージをコンテナレジストリに登録しておくことで、KubeVirtがVM起動する際にコンテナイメージからVMイメージを取り出し、ボリュームに書き出します。コンテナと同じくコンテナレジストリを利用できるものの、コンテナイメージの特徴であるレイヤー構造を活用する仕組みは現時点では存在せず、大きなバイナリがイメージごとに保存されます。本来のコンテナレジストリの利用想定からは外れているため、コンテナレジストリのバックエンドのストレージ容量に注意が必要です。
後者は、KubeVirtとあわせて開発されているContainerized Data Importerというクラスタアドオンを利用します。ローカル端末のイメージファイルや、HTTPサーバー、オブジェクトストレージ、既存ボリュームなどからイメージを取り込み、VMが利用するボリュームに書き込むことができます。
ネットワーク
OpenStackではNeutronが管理しています※2。VMとブリッジのL2接続はML2 Mechanismドライバー、L3機能は仮想ルーター/分散仮想ルーター、ロードバランサ機能はLBaaS v2/Octaviaなど、構成要素に応じてNeutronプロジェクトでAPIやリファレンスドライバーを提供しています。リファレンスドライバーが用意された上で、必要に応じてその他ドライバーと柔軟に組み合わせることでネットワーク機能を実現します。
KubernetesではPod/VMのノード内・ノード間の接続はCNIという仕様に対応することで実現しています。Kubernetes自体がデファクトのCNIプラグインを提供するのではなく、外部の製品と連携してL2レイヤーのネットワーク機能を(製品によってはより上位のレイヤーも含めて)実現します。
ネットワークのそれぞれのレイヤーに対して、機能の対応を整理したものが次の表です。
| レイヤー | 機能 | OpenStack | Kubernetes |
|---|---|---|---|
| L2 | Pod/VMのノード内・ノード間の接続 | L2エージェント(ML2 Mechanismドライバー) | CNIプラグイン |
| L2 | IPアドレス割り当て | internalドライバー | CNIプラグイン |
| L2/L3 | ネットワークインターフェイスへのIPアドレス設定 | DHCPエージェント | CNIプラグイン |
| L3 | Privateネットワーク/PodネットワークのIP固定・外部広告(BGP) | Fixed IP、BGPスピーカードライバー | (特定CNIプラグインで独自対応) |
| L3/L4 | セキュリティグループ | Firewallドライバー | NetworkPolicy |
| L3/L4 | ルーター(SNAT) | 仮想ルーター・分散仮想ルーター | kubelet・kube-proxy※3 |
| L3/L4 | ルーター(DNAT) | 仮想ルーター・分散仮想ルーター | kube-proxy: Service type NodePort |
| L4 | L4ロードバランサ(クラスタ内) | LBaaS v2・Octavia | kube-proxy: Service type ClusterIP |
| L4 | L4ロードバランサ(クラスタ外) | LBaaS v2・Octavia | Service type LoadBalancer |
| L7 | L7ロードバランサ | LBaaS v2・Octavia | Ingress |
CNIプラグインの役割は基本的にはPod/VMのノード内・ノード間の接続、およびIPアドレス割り当てですが、プラグインによってはkube-proxyで対応するiptables処理をeBPFの機能で高速化したり、SmartNICにオフロードできます。ネットワークに関してはOpenStack、Kubernetesともさまざまな要素があり、既存のネットワークとのインテグレーションも考えると、かなりの検討が必要になります(Kubernetesでは標準のプラグインが定まっていなく選択肢は多数あるため、クラウド基盤設計時の検討はより大変に思います)。
またKubeVirtでは、VMとノード内のブリッジとの接続方式にbridge、masquerade、sriovなどの方式が存在します(KubeVirtユーザーガイドでFrontendと記載されている部分)。bridgeではIstioなど一部の通信が行えず、masqueradeではブリッジまでの接続にNATを使用することのオーバーヘッドが存在し、sriovではライブマイグレーションが困難など、基盤設計時に注意が必要です。
※2 QueensリリースでNeutron LBaaSはdeprecatedとなっています。https://wiki.openstack.org/wiki/Neutron/LBaaS/Deprecation
※3 非常に細かい点ですが、現時点のKubernetesではSNATルールの設定は、kubeletとkube-proxyで重複して実施しているようです。次のissueで整理について議論されています。https://github.com/kubernetes/kubernetes/issues/82125
ストレージ
OpenStackではCinderでブロックストレージ、Manilaでファイルストレージが提供されています。
Kubernetesでもブロックストレージとファイルストレージを提供していて、基本的な仕組みは変わりません。Kubernetesでは利用者のボリューム要求(PersistentVolumeClaim)に対して、事前に確保していたボリューム(PersistentVolume)を割り当てるstaticプロビジョニングと、ボリューム要求が発生した時点でボリュームを自動的に作成するdynamicプロビジョニングに分かれている点が異なります。なお、dynamicプロビジョニングをサポートしていないドライバーも多いため、この点は運用する上で注意が必要です。
Kubernetesはブロックストレージを提供する外部ストレージを利用できますが、従来はファイルシステムフォーマット済みの領域をPodに提供する形でした。Kubernetes 1.18からはRaw Block Volumeという機能もstableとなり、必要であればPod・VMから直接ブロックデバイスを扱いたいケースにも対応可能になりました。
VM起動時の初期化
OpenStackはVMイメージにDHCPエージェントとcloud-initサービスを事前に導入しておき、VM起動時に両者で初期化します。この仕組みに関してはKubeVirtも同じです。
KubeVirtの場合、DHCPサーバーはVMが動作するノード内(Pod内)で動作します。DHCPサーバーが動作するネットワークとVMが動作するネットワークが異なるためDHCPリレーが必要になる、という問題は起きなくなっています。またメタデータサーバーは存在せず、OpenStackのConfig Driveと同様の仕組みでメタデータを提供します。
ヤフーの次世代IaaS基盤の課題
これまでの説明でKubeVirtがどのようにIaaS基盤を提供するかイメージいただけたでしょうか。ここからはKubeVirtを利用してヤフーでIaaS基盤を検討する際に、注目しているポイント・課題をご紹介します。
クラスタで管理するノード数
最初にご説明した通り、ヤフーではOpenStackクラスタを200以上運用しています。クラスタ数が多くなる一因に、1クラスタあたりのノード数の制約があります。OpenStackの1クラスタあたりの限界ノード数は(メッセージキュー・管理データベースなどの処理能力から)おおよそ200台と考えられています。クラスタを分割し運用する設計(筆者は「ミニクラウド」と呼んでいます)は、障害範囲を狭くできる一方、運用負荷は必然的に高まります。
次世代IaaSでは1クラスタあたりのノード数を増やし、運用負荷を下げたいと検討しています。Kubernetesの1クラスタあたりの限界ノード数は、KubeCon + CloudNativeCon North America 2018: Kubernetes Scalability: A Multi-Dimensional Analysisセッションでは、(1ノードあたり110 Pod動作させた場合)1300台、(1ノードあたり30 Pod動作させた場合)5000台と報告されており、OpenStackよりも多くのノードを扱えそうです。
一方でetcdへの負荷集中は注意が必要と考えています(筆者の経験したトラブルで、FaaSなどのアプリケーションで異常が起きた際に短期間に大量のPod再起動が繰り返し発生し、Kubernetesのevent情報が膨れ上がり、Kubernetesクラスタ全体が不安定になるということがありました)。Namespace機能でマルチテナントを実現する場合はetcdを共有するため、こういった負荷集中には気をつけなければいけません。
クラスタ外ノードとの通信のためのIP固定
ヤフーの社内には、送信元IPを事前登録することで利用が可能になるサービスが複数あります。
Service type LoadBalancerを利用すればクラスタ外ノードとの通信のためのIPを固定できますが、Service type LoadBalancerを大量に使用することになるのと、間に一つコンポーネントを挟むため、低レイテンシ・高スループットを必要とするサービスの利用が難しくなります。
CalicoのようなCNIプラグインを利用し、BGPを利用してIPの経路をクラスタ外へ広告することで、PodネットワークのIPアドレスでクラスタ外のノードと直接通信することが可能になります。一方でKubernetesのネットワークやサービスディスカバリのモデル(クラスタ内であればClusterIP、クラスタ外であればNodePortやService type LoadBalancerを利用するモデル)からは逸脱していきます。
最適な設計は何か、利用者にどのような利用を促すかは、今後検討が必要だと思っています。
まとめ
本記事では、ヤフーの次世代IaaS基盤の取り組み背景をご紹介し、KubeVirtについてOpenStackと比較することで仕組みを説明いたしました。
今回ご紹介したKubeVirtを利用した次世代IaaS基盤については、これから設計を本格化し、パイロット運用を開始していく予定です。これからさまざまな問題に直面すると思いますが、そこで得るノウハウは今後もコミュニティにフィードバックしていきたいと思っています。
本記事が皆様のIaaS基盤ソフトの理解の一助となれば幸いです。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 相良 幸範
- Kubernetesエンジニア
- ヤフーでクラウド基盤を開発しています。



