こんにちは、システム統括本部のPrivate PaaSチームで働いている水落 啓太(@keitam0)です。
近年、サービスの信頼性維持に関する方法論である「SRE(Site Reliability Engineering)」の取り組みが日本でも盛んになってきています。私たちPrivate PaaSチームでも積極的にSREに取り組み、Private PaaSの信頼性向上に努めています。
今日は、Private PaaSチームのSREの取り組みの中でも、SLI(Service Level Indicator)とSLO(Service Level Objective)に関して着目してご紹介したいと思います。
ヤフーのPrivate PaaSの紹介
ヤフーでは2017年より、VMware Tanzu Application Service (TAS)(旧Pivotal Cloud Foundry)という製品を社内向けにカスタマイズし、オンプレミスなPrivate PaaS環境を社内に構築しています。Private PaaS環境は、社内のエンジニアが、ソースコードをワンコマンドでアップロードするだけでアプリケーションを公開できるなど、ヤフーエンジニアの生産性向上に貢献しています。
2020年12月現在の規模は以下であり、プライベートなPaaS環境としては世界有数の規模ではないかと考えられます。
| 数値名 | 数値 |
|---|---|
| TASクラスタ数(※) | 25(本番環境)+ 3(開発環境)+ 2(性能試験環境) |
| 本番稼働アプリケーション数 | 約17,000 |
| 本番稼働アプリケーションコンテナ数 | 約80,000 |
| 処理リクエスト数(平均req/sec) | 約350,000 |
| 処理リクエスト数(ピークreq/sec) | 約600,000 |
以上のようなPrivate PaaSの信頼性・安定性維持、そしてそれを効率的に行うためにPrivate PaaSチームではSLI/Oを活用しています。
※TAS 1クラスタはおおよそ600のVMから構成され、1クラスタでメモリ換算合計10TB以上のアプリケーションを稼働させる能力があります
SLI/SLO
本記事では、Private PaaSチームでのSLI/Oを紹介していきますが、その前にSLI/Oについておさらいしたいと思います。
SLI/SLOは、Googleが提唱しているサービス保守に関する方法論であるSREに含まれるプラクティスのひとつです。
SLI(Service Level Indicator)
SLIとは、サービスの稼働状況を数値化したものです。一般的にはサービスのエラー率、レイテンシ、スループットなどがSLIとして扱われます。
SLO(Service Level Objective)
SLOとは、サービスの稼働状況についての目標値です。SLIとして数値化されたサービスの稼働状況はSLOに照らし合わせて、目標に達しているのか達していないのかが判断されます。SLIがSLOを下回り、目標未達となることをSLO違反といいます。
SLOは高すぎると過剰品質となり、また低すぎるとサービスの利用者へ不都合が発生することから、適切な値に設定する必要があります。
Private PaaS SLI/O
それでは早速、ヤフーのPrivate PaaSにおけるSLI/Oの現状を紹介します。
SLI/O設定ポリシー
Private PaaSチームでは、SLI/Oの計測・設定ポリシーを設けています。計測・設定ポリシーを設けた上で、各種SLI/Oを設定していくと、それぞれのSLI/Oに一貫性が生まれます。
PaaS利用者目線でSLI/Oを設定
SLIは、PaaS利用者の目線で設定するポリシーとしています。つまり、PaaSを内部的に構成する個々のコンポーネントではなく、PaaS利用者から見えるPaaSの機能(フィーチャー)に着目してSLIを設定します。例えば、Private PaaSにはアプリケーションをデプロイする機能がありますが、本機能に対してSLIを設定するとき、以下の2つのパターンが考えられます。
- アプリケーションデプロイジョブキューのエラー率
- アプリケーションのPaaSへのデプロイ成功率
Private PaaSチームでは必ず2のようなSLIのみを計測します。1はあくまでPaaS内部のコンポーネントの動作実績に着目している一方、2では利用者の目線である「アプリケーションをデプロイできるのか否か」に着目しています。
また、SLOについても「SLO = PaaS利用者が不都合のないSLI値」として90%〜99.99%の範囲で設定し、SLIがSLOを上回っているとき、PaaS利用者が不都合なくPaaSを利用できる状態を表すようにしています。
SLOを重要度別にカテゴリー分けする
同じSLOでもその違反時のインパクトは異なると考えられます。例えば、社内の開発者のみに影響するようなSLOと、Yahoo! JAPANを利用いただいているユーザーに影響するようなSLOがあるとすれば、後者のSLOの方がより強く達成が求められます。
そこで、Private PaaSチームでは以下のような基準を設けて4つのレベルにSLOを区分けし、SLOレベルごとにSLO未達時の行動ポリシーなどに活用しています。
| SLOレベル | 基準 |
|---|---|
| 0 | SLOを違反したとき、Yahoo! JAPANユーザーへ直ちに悪影響を及ぼす |
| 1 | SLOを違反したとき、Yahoo! JAPANユーザーへ悪影響が及ぼす可能性がある |
| 2 | SLOを違反したとき、社内のPaaS利用者(ヤフーの開発者)へ直ちに悪影響を及ぼす |
| 3 | SLOを違反したとき、社内のPaaS利用者(ヤフーの開発者)へ悪影響及ぼす及ぼす可能性がある |
全てのSLIをひとつのダッシュボードで可視化する
計測したSLIは全て1枚のダッシュボードにまとめます。複数のダッシュボードに分かれていると、Private PaaSの状況の全貌を一目で把握できないためです。また、1枚にまとめてそれをチームで見ることを習慣づけることで、どのあたりのSLIが不安定になりやすいかについてチームで共通認識を持ちやすくなる効果もあります。
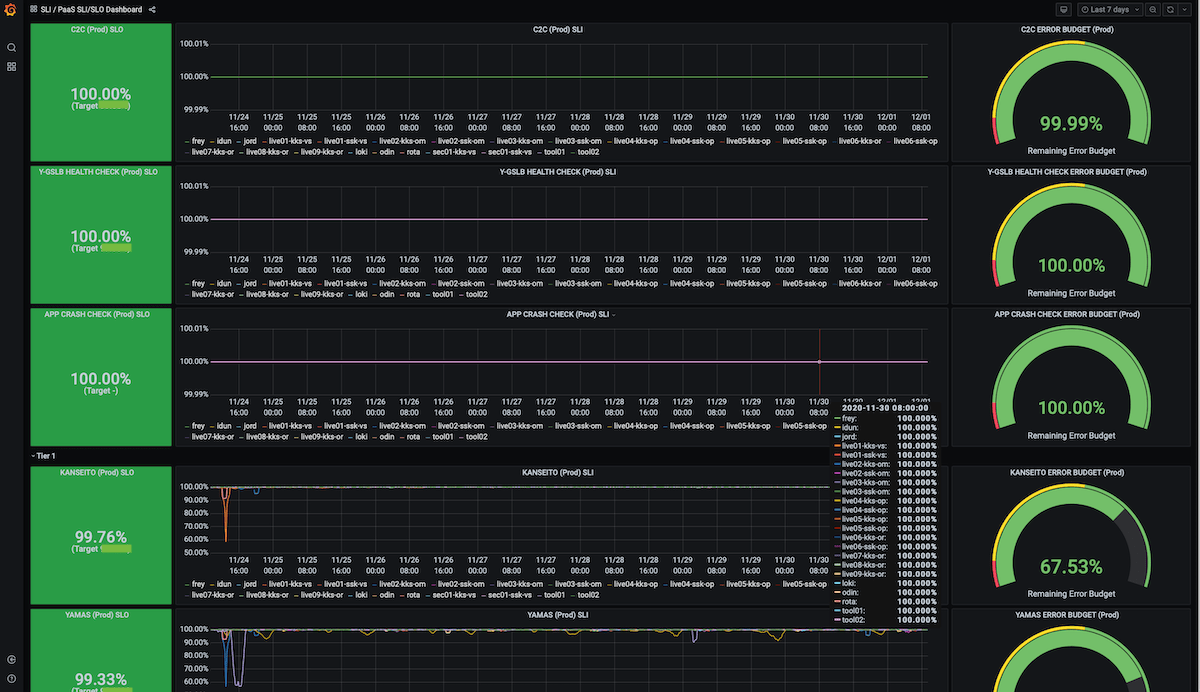
SLI一覧
Private PaaSの機能はいくつかの機能に分解できます。それぞれの機能について以下のようなSLIを設定しています。SLOについてはそれぞれのSLIごとに設定していますが、内部目標値のため本記事では割愛し、前述のSLOレベルのみを記載します。
| SLOレベル | SLI | 説明 |
|---|---|---|
| 0(本番)/ 2(開発) | HTTPSアクセス成功率 | PaaSにデプロイしたアプリケーションへHTTPSアクセスが成功する率 |
| 0(本番)/ 2(開発) | コンテナ通信成功率 | PaaSネットワーク内部でのコンテナ間通信に成功する率 |
| 0(本番)/ 2(開発) | アプリケーション正常動作率 | デプロイ済みのアプリケーションがクラッシュせずに動作する率 |
| 0 | GSLB(広域負荷分散)ヘルスチェック成功率 | PaaSにGSLBサービスイン設定されているAppがGSLBへ正常応答する率 |
| 1 | GSLB(広域負荷分散)コントローラー操作成功率 | PaaSにデプロイしたアプリケーションをGSLBによるサービスイン/アウトに成功する率 |
| 1(本番)/ 2(開発) | アプリケーションデプロイ成功率 | PaaSへのアプリケーションデプロイ操作に成功する率 |
| 1(本番)/ 2(開発) | PaaS/アプリケーションログ転送率 | PaaS本体および、アプリケーションの関連PFへのログ転送成功率 |
| 1(本番)/ 2(開発) | PaaS/アプリケーションメトリクス転送率 | PaaS本体および、アプリケーションの関連PFへのメトリクス転送成功率 |
| 2 | PaaSコンソール表示・操作成功率 | PaaSを操作するコンソールの表示・及び操作に正常応答する率 |
| 3 | PaaS機能一覧ページ表示成功率 | PaaSクラスタごとに利用可能な機能一覧を表示するページの表示成功率 |
上記を見ると、特に本番環境に公開したアプリケーションが適切に「サービスインできるか」、「リクエストをさばけるか」、「正しく通信できるか」といった最重要な項目について、SLOレベル0として、特別に注意して扱っていることがわかるかと思います。これらのSLOが違反した状態は、PaaS上で稼働するAppが無視できないレベルでダウンしている状態を意味しており、Yahoo! JAPANサービス自体のダウンに直結してしまうのです。
実装方法
上記のSLI一覧は、以下のように実装しています。
SLIの回収・可視化
Private PaaSのSLI/OはPrometheus/GrafanaによりSLIメトリクスを回収、可視化しています。
Private PaaSは複数のクラスタにより構成されるため、クラスタごとにPrometheusを配置し、PrometheusのFederation機能を活用し、中央のPrometheusにメトリクスを集めています。
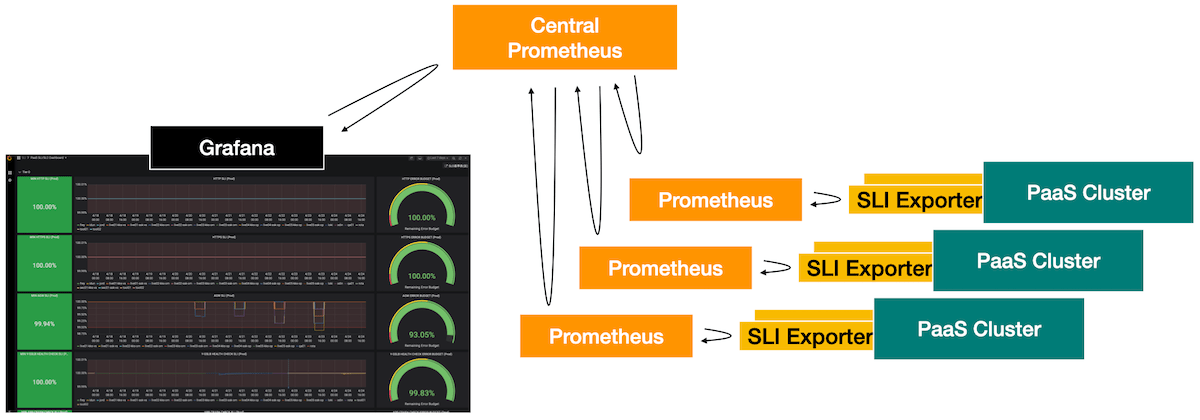
このとき、各クラスタのPrometheusはSLI以外にもさまざまなメトリクスを集計しているため、全てのメトリクスを中央へ集めると、中央のPrometheusが高負荷となってしまいます。そこで、SLIに関するメトリクスについては、sli:... というメトリクス名として、中央のPrometheusでは sli:... という名称のメトリクスのみを回収します。
SLI Exporter
SLI計測のためのSLI計測器は、Prometheus Exporterとして実装します。ほとんどをGo言語で実装しています。先ほどSLI/O設定ポリシーで述べたように、PaaSの利用者目線でのメトリクスをとる必要があるため、Exporterは原則として、PaaS利用者によるPaaS操作や、アプリケーションクライアントによるPaaS上へのアプリケーションアクセスを模倣するような動きをします。
例として、SLI「アプリケーションデプロイ成功率」を計測するExporterでは以下のようなPaaSへのアプリケーションデプロイに関する操作を行い、全て成功した場合に限り、成功した旨をメトリクスとしてカウントします。
- ソースコードをPaaSへプッシュする(アプリケーションをビルド・作成できるか?)
- 1のアプリケーションのルーティング設定を行う(アプリケーションを公開できるか?)
- 1のアプリケーションのスケール数を変更する(緊急時に増強対応ができるか?)
- 1のアプリケーションを削除する(不要なアプリケーションを削除できるか?)
実際には、PaaSの1から4の操作は、PaaS内部のさまざまなコンポーネントが連動して実現されます。しかし、SLIの計測としては、個々のコンポーネントは扱わず、利用者の視点でブラックボックス的に計測することで「PaaSのデプロイ関連機能」そのものの信頼性を計測するわけです。
SLI/Oの運用と改善
前節までで、Private PaaSチームでのSLI/Oにどのようなものがあり、どのように実装したのかを説明しました。しかし、これだけではSLIを計測しただけで終わってしまいます。どのようにSLI/Oを運用しているのか、またどのようにSLI/Oを改善しているのかを説明します。
SLO違反時の対応
SLOは、PaaS利用者が不都合のない閾値を見定めて設定しています。すなわち、SLOを下回ったときはPaaS利用者が何らかの不都合な状態となることを意味します。Private PaaSチームではSLOを機能障害と扱うか否かの基準としても活用しており、SLO違反時は、対象の機能が障害したと判断します。SLOレベルによって以下のような対応ポリシーを定めています。
| SLOレベル | 違反時の対応 |
|---|---|
| 0, 1 | 24/365のシフト体制で障害対応を行い、最速で復旧を目指す |
| 2, 3 | 営業時間内で障害対応を行い、優先的に復旧を目指す |
SLO違反後には、今後のSLO違反を防止し、安定的なSLO維持に向けた対策を話し合います。特にSLOレベル0, 1でのSLO違反は重大なため、ポストモーテム形式でより本格的な議論を行います。
SLO違反時のトラブルシュート
Private PaaS SLI/Oの欠点
Private PaaSチームでは、利用者目線でSLI/Oを計測・設定するポリシーと述べましたが、このポリシーは良くも悪くもあります。PaaS利用者目線での信頼性をSLIから把握できる利点がある一方、PaaS内部の各種コンポーネントの状況はSLIから把握できないのです。SLO違反時に分かることは「PaaSの機能を安定提供できていない」ということだけであり、その原因までは私たちのSLIでは分かりません。
詳細ダッシュボード
前述のPrivate PaaS SLI/Oの問題の解決策として、Private PaaSチームではSLI/Oダッシュボードの他に、PaaSの各種機能に関する詳細メトリクスを把握するためのダッシュボードを作成しています。
以下は、ログ・メトリクス転送に関する詳細情報をまとめたダッシュボード例です。ログ・メトリクス転送に関するトラブルシュート時に運用者が知りたい情報がまとめられています。
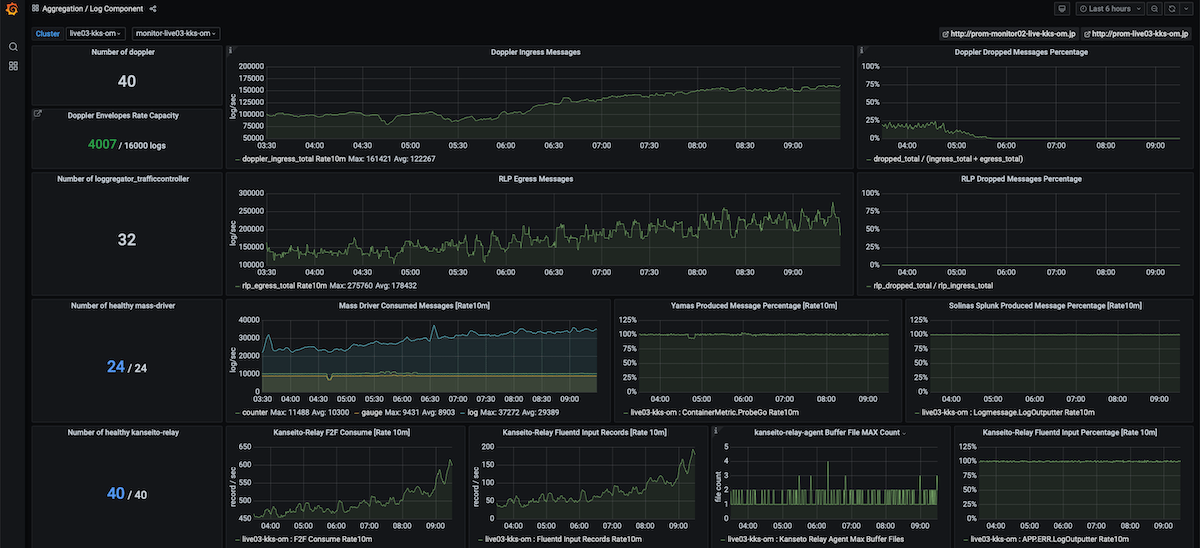
ログ・メトリクスに転送には複数の中継コンポーネントを経由するのですが、それぞれのコンポーネントに関するメトリクスが表示しています。例えば、上部中央のグラフは、PaaS内部のログバッファを通過するログ数の推移を表しています。本ダッシュボードは主に障害などによるSLO違反時や、ログ・メトリクス転送の信頼性向上に関する議論の際の情報源として活躍します。
SLOとリリースポリシー
PaaSソフトウエアの各種リリース・アップデートは障害の発生要因になりやすく、SLIを悪化させる原因になりやすいため警戒しています。原則としてエラーバジェット(SLO違反までの残可能停止時間)が残っていればリリースするのですが、そのリリースによるSLO違反時の影響の大きさや、SLO違反時の対応体制を考慮し、設定しているSLOレベルごとにリリースポリシーを設けています。
なお、PaaSは、それ自体がマイクロサービスとして多数のコンポーネントから成り立つため、さまざまなリリースが存在します。それぞれのリリースがどのSLOに影響しうるのかはチーム内で早見表を作って対応しています。
| SLOレベル | リリースポリシー |
|---|---|
| 0 | ペアオペレーション必須、複数クラスタの同時リリース禁止 |
| 1 ≧ | カナリアリリースによる本番環境での事前検証必須 |
| 2 ≧ | 営業時間内のみリリース、開発環境での事前検証必須 |
| 3 ≧ | 規程なし(エラーバジェットが残っていればOK) |
特に、SLOレベル0及び1に関わるリリースに関しては、Yahoo! JAPANユーザーに直接影響を与える可能性があることから、必ずカナリアリリースを挟むなど厳格なリリースフローとなっています。
SLOとアラーティング改善
SLOを根拠にアラート整理
Private PaaSチームでは、SLI/Oの計測とは別に、各種アラーティングを行っています。アラートの数は多岐にわたりますが、いずれのアラートについても、このアラートはどのSLO維持に関わるか? という観点で設定・見直しを行います。
また、SLO違反時には、最優先度で対応が必要なCriticalレベルのアラートを発行します。
バーンレートアラーティングの導入
Private PaaSチームでは長らく実現できていなかったのですが、最近エラーバジェットの消費速度を計測し、消費速度が超過した場合にアラートを発行するバーンレートアラーティングの運用も開始しました。バーンレートアラーティングでは、SLO違反に到達する前に、Warningレベルのアラートとして事前に気づくことができることから、Yahoo! JAPANのユーザーやPaaS利用者へ実害が発生する前に対応行動が開始できると期待しています(幸いまだ発動したことはありません)。
SLI/Oの改善
SLO値の見直し
前述の通り、PaaSチームではSLOはPaaS利用者に不都合のないSLI値を設定するポリシーとしています。PaaSを運用していく中で、「PaaS利用者に不都合のない値」が変動してくる、また従来のSLOが適切でなかったと気づくケースがあります。
例えば、SLOを満たしているのにPaaS利用者から、PaaSのエラーに関する問い合わせが来る、また障害対応が求められる場合などがそれに当てはまります。このような場合が散見されるときには、SLOが利用者の期待を満たしておらず、低すぎるということなので、SLO値の引き上げを検討します。SLO引き上げの前に自分たちがそれを守れるかの確認をしますが、基本的には利用者ファーストの観点からどうすれば引き上げられるのかを考えるべきと捉えています。
直近では、とあるSLOを99%として運用していましたが、上記のようなケースで明らかに不足していると分かったため、99.9%へ引き上げました。
不足しているSLI/Oの追加
SLI/Oは策定の検討や、実装自体に工数を要するため、現実的には優先度をつけて開発していくしかありません。このためPrivate PaaSのあらゆる機能をSLI計測し、SLOにより安定提供を目指せているかというと、そうではないのが実情です。
例えば、Private PaaS SLIのひとつである「コンテナ間通信成功率」は当初、コンテナ間通信機能の利用者が少なかったことから、SLIとして計測していませんでした。しかし、あるとき本機能の障害時に、PaaS運用者が気づくことができず、発見が遅れ、PaaS上で稼働するアプリケーションの障害要因となってしまうことがありました。コンテナ間通信機能は、利用者はまだ少ないとはいえ、それを利用するPaaS利用者にとってはアプリケーション稼働率に直結する重大な指標となります。このような反省を活かして追加したSLI/Oです。
既存SLI計測方法の改善
すでにSLI計測しており、SLO値にも問題がないけれども、その計測方法が適切でなかったという場合もあります。このようなときは発覚次第、改善に取り組んでいます。
例として以下のようなケースがありました。
「アプリケーションデプロイ成功率」のSLIがSLOを満たしており、十分高いにも関わらず、PaaS利用者よりアプリケーションのデプロイに失敗するという報告を複数受けました。SLOを満たしているのにPaaS利用者がアプリケーションをデプロイできないとはおかしな状況です。調査したところ、原因は「アプリケーションデプロイ成功率」SLI計測に用いていたデプロイ対象のサンプルアプリケーションのメモリ設定値が小さすぎることにありました。
従来はサンプルアプリケーションのメモリを256MBと設定してデプロイしていましたが、実はこのときPaaSクラスタのメモリリソースが不足しており「小さなメモリなアプリケーションはデプロイできても、大きなメモリのアプリケーションはデプロイできない」という状況だったのです。
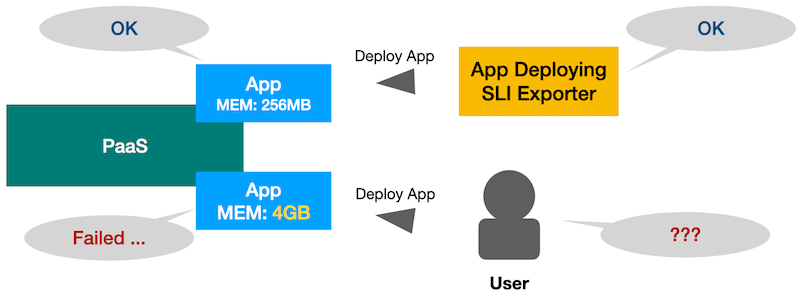
Private PaaSの利用者は、1GBから4GB程度のアプリケーションをデプロイすることが多いことから、そのユースケースに合わせて、SLI計測系も4GBのアプリケーションデプロイの成功率を計測するように変更しました。
SLI/Oを導入して良かった点・今後の課題
ここまでで、Private PaaSチームでのSREの取り組み、特にSLI/SLOに関する取り組みを紹介しました。取り組みの結果より、SLI/Oを導入して良かったこと、また今後の課題を述べたいと思います。
良かった点
最も良かった点は、Private PaaSチーム全員でPrivate PaaSの稼働状況がどのようになっているのかを把握できるようになったことです。短期的には、リリース判断の他、障害の判断や緊急対応の判断にSLI/Oを用いて素早く回復へ向けた作業に取り組めるようになりました。長期的には、どのような点についての安定性を追求すべきなのかの共通認識を持ち、そこに向けた改善に取り組みをしやすくなりました。
Private PaaSは多くのコンポーネントによって成り立つシステムであることから、個々のコンポーネントに着目しすぎると、議論が狭く深くなりすぎてしまい、いま自分たちが何をすべきなのかが分からなくなりがちです。特定コンポーネントに対して、過剰な安定性を追求してしまったり、反対に安定性向上の取り組みが必要な箇所を見逃してしまったりといったようにです。
PaaS利用者の視点に基づいたSLI/Oを計測・設定することで、利用者の視点から逆算して、Private PaaSチームに足りないもの、また反対に足りているものが見えるようになり、SLI/Oという共通言語を活用して、Private PaaS開発・運用に関する議論ができるようになりました。
今後の課題
一方、課題も多くあります。
最近目立っているものでは、SLI計測値としては異常がなく、大半のPaaS利用者には問題がないが、一部のPaaS利用者に重大な障害が発生するケースです。
特定VMのみで異常が見られ、そのVM上で稼働するアプリケーションのみが障害するような状況です。このような状況では、SLIが例え99.9%のように高値を示していても、その利用者にとっては重大な問題ですから、SLIと利用者の感覚が一致しません。このような利用者を救うには、より厳格にコンテナやVMのオートヒーリングをかけられるようにしたり、もしくはSLIをより個別の利用者のアプリケーションの稼働状況を考慮するなどの改善があり得ますが、現状十分にできておらず課題となっています。今後、課題解消に向けて、Private PaaSチームとして取り組んでいきたいところです。
最後に
ここまで、ヤフーのPrivate PaaSチームでのSREおよびSLI/Oに関する取り組みを紹介しました。
今後もYahoo! JAPANのサービス安定稼働に向けて、Private PaaSチーム一同頑張っていきたいと思います。
最後までお読みいただきありがとうございました。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 水落 啓太
- エンジニア
- Private PaaSチームでSREエンジニアをしています。
-



