こんにちは! Yahoo! JAPAN研究所の坪内です!
2020年のトピックといえば、個人的には何といっても「新型コロナウイルス」です。
皆さんも、完全に新型コロナウイルスに振り回されっぱなしの2020年だったのではないでしょうか?
個人的な話ですが、新型コロナウイルスの影響で、楽しみにしていたオリンピックは延期!
コロナ禍で、学会なども軒並みオンラインに移行。
毎年欠かすことのなかった友人との集まりも、もちろん中止。
ニュースを見ても、新型コロナウイルスの影響で倒産、離婚、孤独など暗くなるものばかり。
仕方のないこととはいえ、暗い話ばかりです…
「新型コロナウイルス、いいかげんにしてーーー」と山のてっぺんから叫びたい気持ちでいっぱいです。
さて、こんな風に、新型コロナウイルスの影響で気分もパッとしないのは、僕だけではないと思います!
実際に新型コロナウイルスによってどのくらい、わが国がdepressedな状態(*1)になったのだろうか!? ふとそのような疑問が湧き起こりました。
そして、それを計測できないかなと考え、実際に試してみることにしました。
(*1 意気消沈した状態、不景気で暗い雰囲気)
「新型コロナウイルスが世の中のムードにどんな影響を与えたのか?」
これが、今回の記事のテーマです。
記事の最後に僕なりにヤフーのデータを解析し、推測した結果を掲載しています。結果を想像しつつ、どうぞ、最後までお付き合いいただければ幸いです!
イントロダクション
そもそもユーザーのムードってどのように計測できるのでしょうか?
機械を使って? それとも表情を調べる?

図1:EEGによる脳波計測と表情認識のイメージ
人のムードを計測すると言われると、ついこのような特殊な機器を頭につけた人が思い描かれます。あるいは、顔の特徴点を読み取り、ユーザーのムードを認識することを思い描く方もいらっしゃるかもしれません。
こういった脳波や他にも発汗量とか心拍数などの生体信号、あるいは顔認識等を計測し、被験者の感情やムードを推定しようという研究が数多くあります。医学的、生理学的な身体の反応から、正確にユーザーの感情状態を捉えるという、大変重要なテーマです。
ただ、今回のようなたくさんの人のムードを検証するにはその計測は適用できなさそうです。世の中のことを知りたいからといって、このような特殊な機器を何万人にも配る…なんてことはできないわけです!
(※さらに正確に言いますと、このような機器をつけてユーザーのムードを推定するには落ち着いた環境で、きちんと計測する技術も必要になります。ただ機器を配って、個々人が計測できるというものでもないそうです。)
新型コロナウイルスでどのくらいユーザーがdepressしたかという、新規性のある取り組みを実現したいわけですが、どういった手段で計測したら良いのだろうか… 何か別の手段で、ムードを計測できないか… と再度考えました。
そこで思いついたのがウェブ検索行動を使うことです!
ウェブ検索クエリには、ユーザーがその検索を行った“背景(=コンテキスト)”があります。その検索クエリを検索すること自体が何らかのヒントになっているものがあります。
つまり、(1)ユーザーのコンテキストが滲み出やすい検索クエリと、(2)コンテキストに関係なく検索される検索クエリがあるということです。
もし、ムードが明るい/暗いというコンテキストの軸で、それが滲みやすい検索クエリを見つけることができれば、そこから今日の日本全体のムードはどうだったのか? ということを推定することができるはず!!!
つまり、ウェブ検索行動を使って「新型コロナウイルスでどれくらい日本がdepressしたか?」に回答できるのではないか、という仮説を立てました。
そこで、
A)センサーデータ(つまり、加速度センサーとか、気圧センサーとかの値)
B)一部のモニターに対して行った「あなたの今のムードは?」と聞いたアンケートデータ
C)検索クエリ(*2)
(*2 プライバシーポリシーの範囲内で取得したデータを個人が特定できない状態に加工しています)
この3つの情報を使い、機械学習を駆使し、ユーザーの検索クエリから、ユーザーのその時のムードを推定するQMM(Query Mood Model)を作ったのです!
ここで、「え?センサーデータが必要なの!?」と思った方は鋭いです!!
そうなんです、機械学習の常識からすれば、センサーデータなんて不要なはずなんです! C)検索クエリと、B)「あなたの今のムードは?」と聞いたground truthデータがセットで把握できるのであれば、それで学習ができます。もうこれだけで機械学習はできてしまうはずなのです!
なんで、A)センサーデータ(つまり、加速度センサーとか、気圧センサーとかの値)が必要なの? って思うわけです!
ここがこのQMM研究のポイントでもあります!!
QMMの手法の解説
(この章は手法の説明です。興味のある方のみお読みください。解析の方法ではなく、解析の結果に興味があるんだという方はこの章自体をスキップいただき、次の結果の章から読み始めても大丈夫です)
どうして、検索クエリとアンケート調査の結果だけではダメで、さらにセンサーデータも必要なのでしょうか? それは、「アンケートに回答いただいたタイミングと、検索をしたタイミングとが一致することが稀」であるからです。
つまり、C)検索クエリと、B)「あなたの今のムードは?」と聞いたground truthデータを元に機械学習することをイメージしてください。
例えば、こんなケースを考えてみましょう。
ユーザーが「今のムードは、最高に明るいぜ!」とアンケートで回答した10分“前”に「お笑い 動画」と検索していたらどうでしょうか? その「お笑い 動画」の検索の末にたどり着いた動画が作用して、ユーザーの気分を明るくしたことが考えられます。
では、次のケース。
ユーザーが「今のムードは、最高に明るいぜ!」とアンケートで回答した10分“後”に「お笑い 動画」と検索していたら? おそらく、気分が明るいから「お笑いの動画でも見よう!」つまり気分が明るいときに「お笑い 動画」を見るということが考えられます。
このようにアンケートの回答と、検索行動が時間的に近い場合は、これらのデータセットには意味が出てきます。
しかーし!
そんなアンケートの前後でユーザーがタイミングよく、何かを検索してくれるとは限らないのです!!
またこんなケースはいかがでしょうか?
ユーザーが「今のムードは、最高に明るいぜ!」とアンケートで回答した“半日前”に「お笑い 動画」と検索していたら? ひょっとすると、お笑い 動画を見て、それが面白すぎて、12時間後まで気分を上げ続けていることも考えられます。
しかし、普通に考えるなら、半日前のアンケートの回答は、おそらくはもはや遠すぎるデータで今のムードには関係ない方が多くなるのではないでしょうか。
つまり、検索のタイミングと、アンケートのタイミングが近ければ、問題ないのですが、そんな都合よくいきません。ほとんどが学習には“使えない”データ(=時間的に離れすぎているデータ)になってしまうのです! そうすると、学習データが多く集まらず、うまくモデル化をすることができなくなってしまいます。図2に示した通りです。
本当だったら、点線のハートのタイミングで回答が欲しいのに、検索を行っているタイミング付近でのアンケート回答はなく、学習データになり得ません。
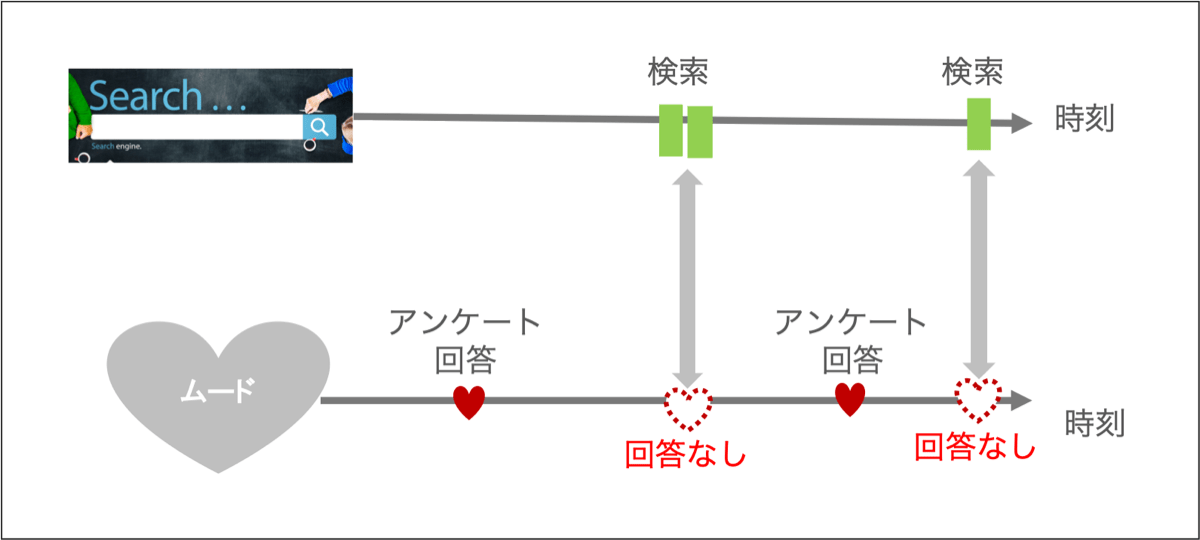
図2:検索行動とアンケート回答のタイミングがバラバラで学習データが集まりにくくなる
これが、C)検索クエリと、B)「あなたの今のムードは?」と聞いたground truthデータのみで、機械学習をしようとしたときの課題です! そして、その課題を打破するニューヒーローこそが、A)センサーデータなのです!!
課題自体は伝わったと思います。しかし、A)センサーデータがなぜそれを解決できるのか、まだベールに包まれていると思います。

どうしてA)センサーデータが加わると、学習データを増やすことができるのでしょうか? アンケート回答と検索との時間のズレを気にしなくてもよくなるのでしょうか?
そこで登場するのが、A)センサーデータとB)「あなたの今のムードは?」と聞いたground truthデータで作る、Sensor Mood Model(SMM)です。SMMのおかげで、QMMが実現できるようになるのです。では、SMMって何?
SMMはセンサーデータとアンケートの回答の関係をモデル化したものです。つまり、センサーデータ群をインプットとして、アンケートの回答(ムード)を予測するモデルです。実は、以下のような先行研究があり、スマホのセンサーデータだけで、ユーザーの気分を推定できる可能性は以前から指摘されていました。
https://dl.acm.org/doi/abs/10.1145/2462456.2464449
https://www.researchgate.net/publication/254034266_Daily_Mood_Assessment_Based_on_Mobile_Phone_Sensing
今回は、それらを踏襲して、モデルを作りました。
センサーデータというのは、スマートフォンから暗黙的に取得し続けることが可能です。アンケートを回答する瞬間、何かを検索する瞬間はもちろん、眠っている時や、スマートフォンをポケットに入れている時でもセンサーデータを取得できます。
今回はモニターの方に事前に説明し、同意いただいた上で、アンケートに回答していただいている期間は常にセンサーデータを取得し続けました。センサーデータとアンケートの回答をモデリングすることで、センサーデータを取得している期間、つまりスマートフォンの電源が入っている全時間においてアンケート回答、つまり今のムードを推定できるようになりました。
つまり、先ほどはスカスカだった「C)検索クエリと、B)「あなたの今のムードは?」と聞いたground truthデータ」の回答セットですが、A)センサーデータを用いたSMMによってB)「あなたの今のムードは?」の推定結果が入ることで、以下のようにC)検索クエリとひもづけることのできるデータセットの拡充に成功しました。以下のような図のイメージです。
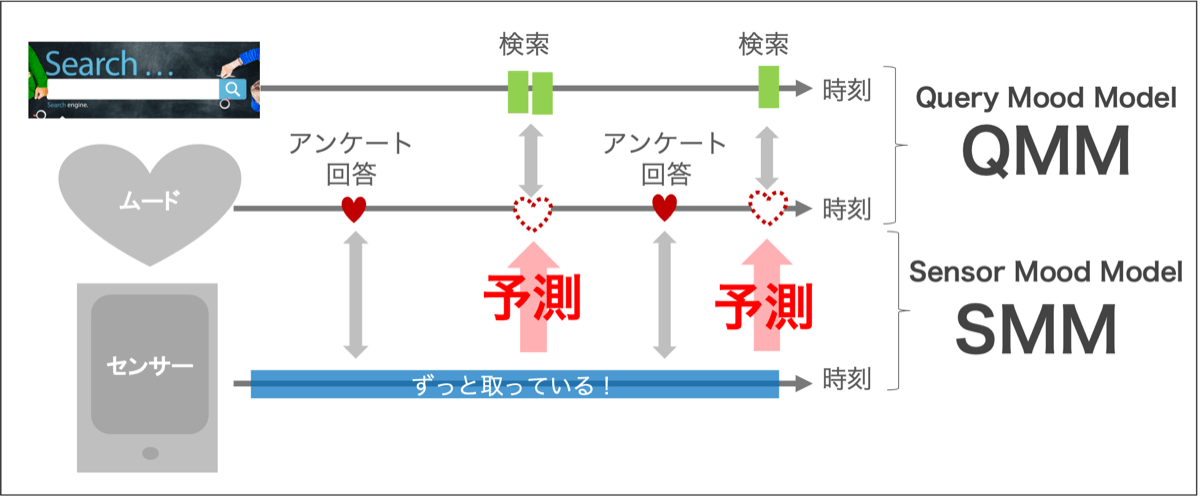
図3:センサーデータでアンケートでアクセスできるタイミングが増えた図
さあ、これでお膳立ては整いましたよ! 実際に400名を超えるモニターの方にご協力いただきまして、
A)センサーデータ(つまり、加速度センサーとか、気圧センサーとかの値)
B)一部のモニターに対して行った「あなたの今のムードは?」と聞いたアンケートデータ
C)検索クエリ(*2)
(*2 プライバシーポリシーの範囲内で取得したデータを個人が特定できない状態に加工しています)
を2019年11月から約90日間計測&提供いただきました。それらのデータを解析し、検索クエリの中から、ムードに関するコンテキストがにじみ出ている検索クエリを抽出しました。
このモニター400名の集団から作られたQMMは、別のもっと大きな集団にも当てはまるモデルである可能性が高いです。このモデルをもとに、ヤフーの検索ユーザー全体のムードスコアを求め、新型コロナウイルスの時の(日本全体の)浮き沈みを計測してみたいと思います!
検証
さて、前の章でご説明したモデルでヤフーの全検索クエリをスコア化し、新型コロナウイルスの時のヤフーの検索クエリから推定されるわが国のムードを調べていきたいと思います。
本題に入る前に、この指標が本当にうまく働いているか、気になる方が多いのではないでしょうか? このムードスコア、本当にムードがわかるか? とお思いの方も多いと思います。これを調べる事前調査として、このスコアで1週間の日本のムードの波を調べてみました。
みなさん、1週間のムードの浮き沈みって普段どのようなものでしょうか? 今週はいかがでしたか?
もちろん週によって大きく異なるのでしょうが、一般的には、
・月曜日(祝日の翌日)は気分が下がる(ブルーマンデーという言葉すらあるくらい!)
・土日祝日は気分が上がる
と言われています。
図4は、2019年7月に検索された検索クエリに対して、QMMによりスコアを出した値です。なんと、土日祝日が高くなり、休み明けにストンと気分が落ちる現象が再現されています!
お見事!
(脚注※ ユーザー全員の頭に脳波計をつけているわけではないですし、本当はどうだったのか? などというデータはありません。しかし、より自分の体験やイメージに近い結果となっていることに着目していただければと思います)
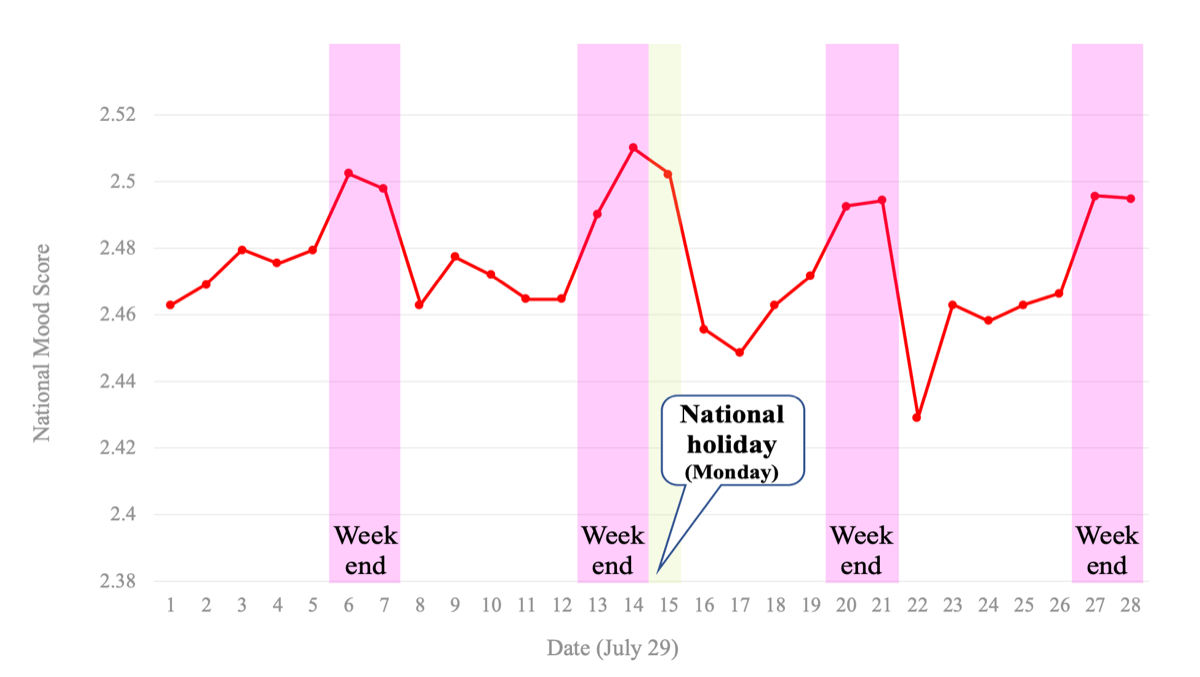
図4:2019年7月のムードスコア
このようにみると、1週間のムード動きはそれなりに把握できていそうですね。この指標、それなりに使えるということです!
さて、締めくくりです! 「新型コロナウイルスでどれくらい日本がdepressしたか?」いよいよ!! 図5が、ヤフーの検索クエリから算出した新型コロナウイルス時のムードスコアの推移です!
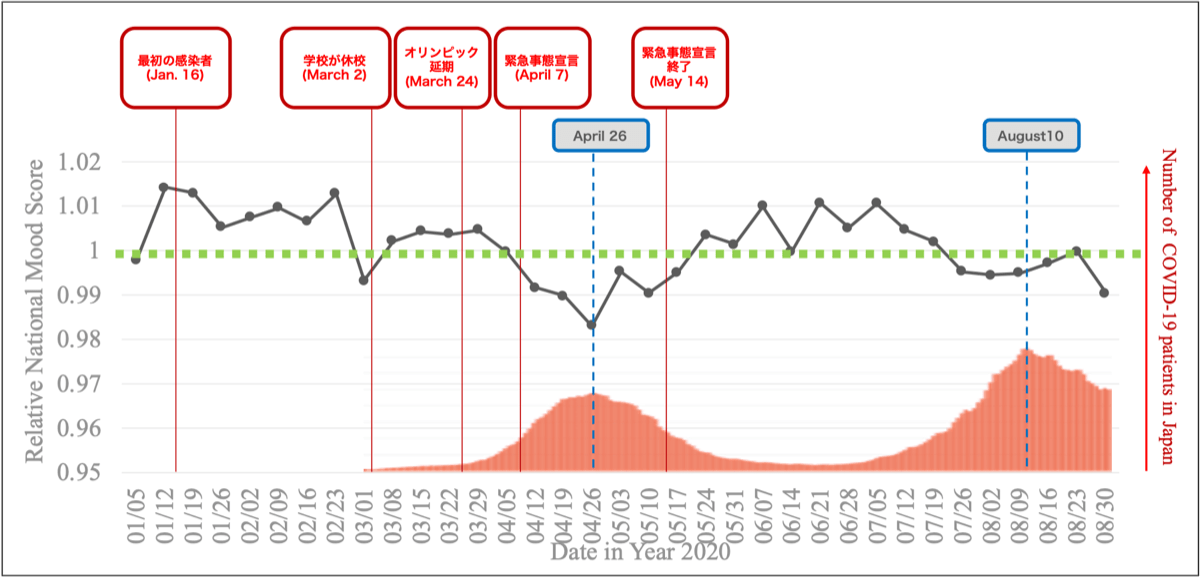
図5:2020年コロナ禍でのムードスコア(対2018年比)
週のばらつきをなくすために、まずは日曜日だけのムードスコアを計算しました。さらに、例えば2月は「気分が落ち込む」といった季節性も考慮し、計算しています。グラフの数字は、2018年の同じ時期の日曜日を1とした時に2020年の感情スコアがどの程度になるかを示しています。図中のオレンジ色の棒グラフは、新型コロナウイルスの現在感染者数を示したものです。
新型コロナウイルスが話題になる前、日本はオリンピックムードでムードスコアは2018年に比べて高い状態にありました。それがコロナ禍が話題になるにつれて、徐々にムードが下がっていきます、
興味深いのは、ヤフーの感情と感染者の数が逆転していることがわかります! 第1波の時は、もっとも感染者の多かった4月26日にヤフーのムードスコアはもっとも低くなり、そこから感染者が減るにつれてムードは上がっていきました。また第2波の時に下がりますが、第1波ほどの落ち込みはなく、まあ例年通りというような結果となりました。
「新型コロナウイルスでどれくらい日本がdepressしたか?」
・第一波の時は大きく落ちた。
・第二波でも落ちたが、第一波ほどではなかった。
このような結果になりました!
場所がどのくらい混んでいる! などの混雑の解析やステイホームの状況の解析など、人の動きに着目し、新型コロナウイルスの解析をした事例は多く見かけたと思います! しかし、このように“ムード”を軸に解析した結果は、なかなか珍しいのではないでしょうか?
終わりに
今年は本当に新型コロナウイルスに振り回された一年でした。こういった新しい災害に対しても、データ解析は有用な手段となり得ます。
これからも、ヤフーが抱えるデータの総力をあげて、日本の課題を1つでも多く解決していきたいと思っています。引き続き、ヤフーを応援してくださいますよう、よろしくお願いします!
最後まで読んでいただき、ありがとうございました!
ちなみに、この記事の内容は論文として発表したものです。興味ある方は以下の論文もご覧ください!
https://arxiv.org/abs/2011.00665
写真:アフロ
GYRO_PHOTOGRAPHY/イメージマート
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 坪内 孝太
- Yahoo! JAPAN研究所
- 人の行動ログに着目したデータ解析の研究に従事しています。
-



