
こんにちは。ヤフーで音声認識の研究開発を行っている桶作と申します。ヤフーで提供している全てのアプリには音声を使ったユーザーインターフェース(UI)が組み込まれているのをご存じでしょうか。音声UIには、ヤフー社内で独自に開発している「YJVOICE」と呼ばれる音声認識エンジンが使われています。
音声UIは手でアプリの操作をする必要がないため、「何か別のことをしながらアプリを操作したい」場面で非常に役に立ちます。例えばYahoo!カーナビでは、スマホに話しかけるだけで操作ができる機能が追加されており、運転中でもスマホを手で操作することなく、スマホに向かって話しかけるだけで操作できます。
雑音環境下でも高精度な音声認識を!
Yahoo!カーナビアプリを使う場面を想像してみましょう。カーナビなので車の中で使うことが多いですよね。音声認識のために車内で発せられた声をスマホで収録すると、声の中に車の走行音や音楽といった雑音に混ざってしまいます。私たち人間もうるさい場所で他の人の声が聞こえにくくなるように、YJVOICEも雑音が多い場面では正しく音声認識をすることが難しくなってしまいます。正しく音声認識ができないと、Yahoo!カーナビの音声操作がうまくできず、ユーザー体験を損ねてしまいます。雑音環境下でも精度よく音声認識をすることは非常に重要なのです。

写真:アフロ
ヤフーでは、雑音環境下での音声認識性能を出すために、「雑音重畳」とよばれる手法を用いてYJVOICEの音響モデルの学習を行っています。今回は、雑音重畳に加えて「SpecAugment」と呼ばれる手法を導入し、雑音環境下で性能向上の効果があるかどうかを検証してみました。
雑音重畳とは
雑音重畳とは、収録された音声データに対して、コンピューター上で雑音データを付与する方法です。雑音重畳によって、元の音声が雑音のある状況で収録されたかのようにできます。
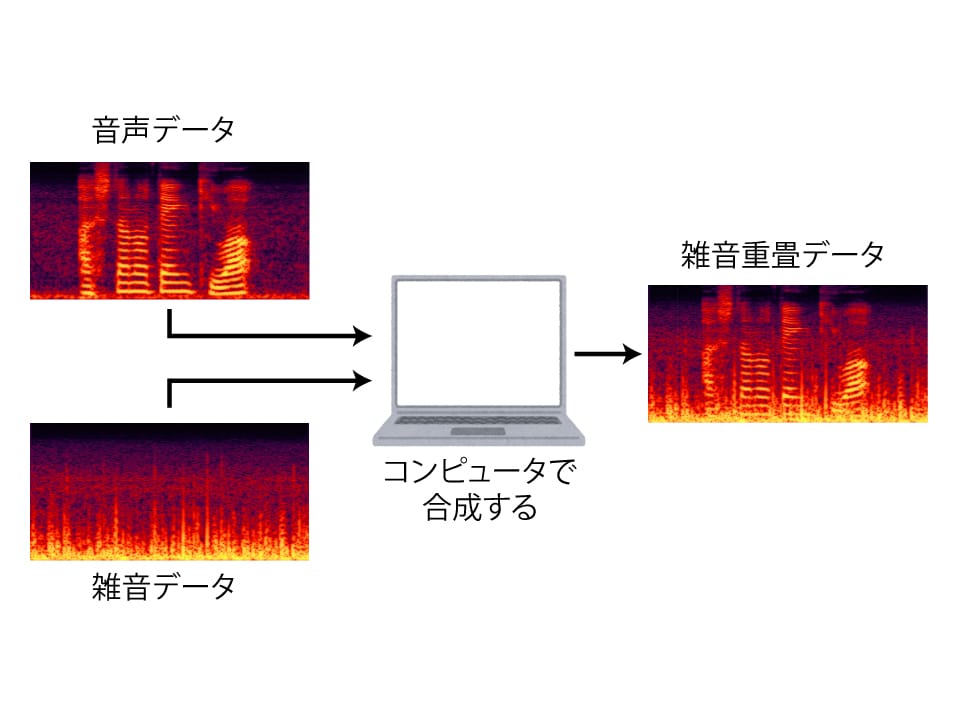
音声データにいろんな種類の雑音を重畳したデータを使って音響モデルの学習を行えば、雑音環境下での音声認識の精度向上が期待できます。またこのように学習データを水増しする手法のことをデータ増強などといいます。
SpecAugmentとは
SpecAugmentとは、2019年にGoogleによって発表された、音声認識でのデータ増強手法のことです。音声データの表現方法の1つにスペクトログラムと呼ばれるものがあります。スペクトログラムは、横軸に音声の時間、縦軸に音声の周波数を描いたものです。図で示したように、SpecAugmentはスペクトログラムの縦(周波数方向)と横(時間方向)のデータの一部を音声データを全て0に置き換えを行います。この操作をマスキングと呼びます。マスキングされた音声データを音響モデルの学習に用いるというわけです。
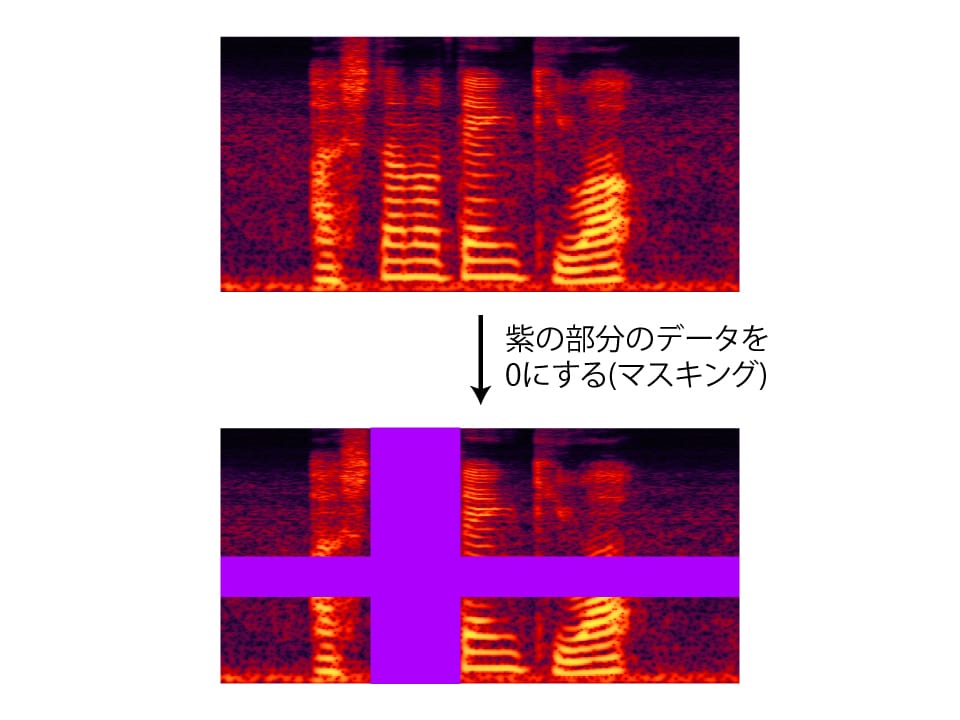
SpecAugmentでは、マスキングの仕方によって1つのスペクトログラムから複数の学習データを作り出すことができます。雑音重畳と同様にデータ増強を行っていることが分かります。
YJVOICEへの応用
さて、YJVOICE向けにSpecAugmentを使うため、2つの工夫を施しました。
- YJVOICEで使用している音響モデルであるLF-MMI用にSpecAugmentを改良した
- 雑音重畳とSpecAugmentの両方を学習データに対して適応した
元論文ではSpecAugmentはend-to-end音声認識向けの手法として発表されました。一方で、現在YJVOICEで用いているのは、Lattice-Free MMI(LF-MMI)と呼ばれる隠れマルコフモデル(HMM)ベースの音響モデルです。
LF-MMIでは、学習に使う音声データを1秒から2秒ほどに切ってから学習を行います。LF-MMIにSpecAugmentを適応するため、短く切られた音声の中で適切にマスクがかかるようにSpecAugmentを改良しました。これが1つ目の工夫です。
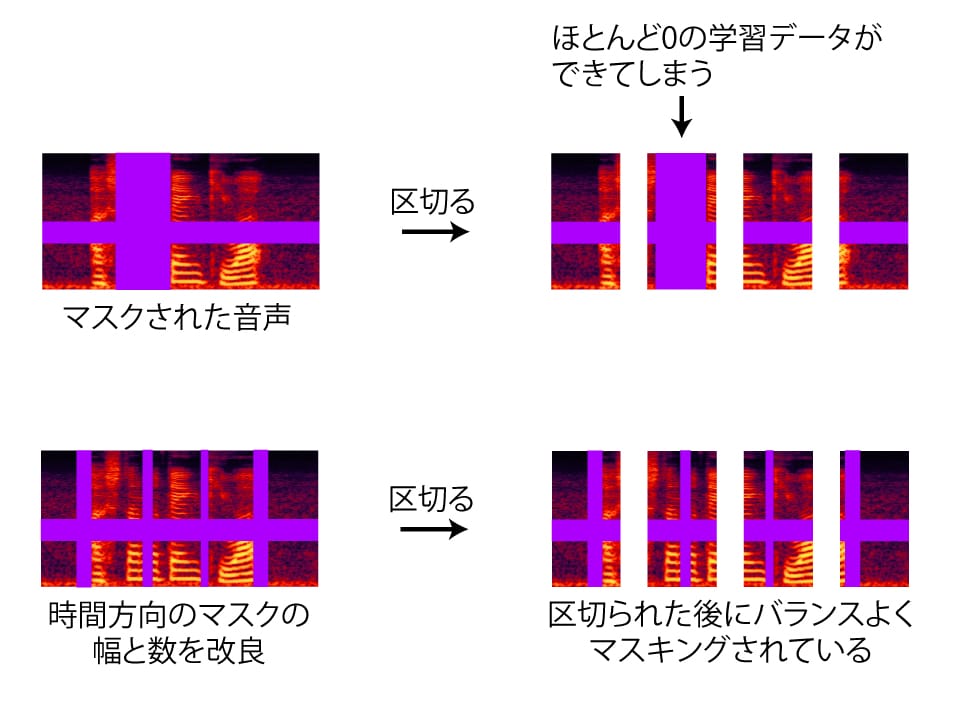
もう1つの工夫は、雑音重畳をした音声データに対してさらにSpecAugmentを行うということです。2つのデータ増強を併せて行うことで、さらなる雑音環境下での性能向上が期待できます。
実際にやってみた
雑音重畳のみで学習した場合と、雑音重畳+SpecAugmentで学習した場合で音声認識の性能を比較してみました。
音声認識モデルにはLF-MMIを用いました。LF-MMIにはノード数4096で5層の隠れ層を持つDeep Neural Networkを使用しています。学習はヤフーが持つGPUスーパーコンピューターであるkukaiを使用しました。元論文で述べられているように、SpecAugmentに関連したハイパーパラメータにはマスキングの数や幅の最大値があります。これらの探索もkukaiを用いて行いました。1つのモデルを学習するのに約1週間ほどかかります。手当たり次第にパラメータ探索を行うのは時間がかかりすぎるため、事前にどのパラメータが性能改善に効果的かを調査しておき、そのパラメータを中心に探索を行うなどの工夫をしました。
学習済みのモデル精度評価のために、2種類の音声データを用意しています。1つは静音環境で収録された音声データセット(クリーンセット)、もう1つは雑音の多い場所で収録された音声が多く含まれるデータ(ノイジーセット)です。2種類の評価データセットに対して誤り削減率(SpecAugmentを導入したことで、どれだけ認識精度がよくなったかを表す数値)を求めました。最も性能が良かったモデルの結果を次の表に示します。
| 誤り削減率 | |
|---|---|
| クリーンセット | 0.0% |
| ノイジーセット | 5.5% |
クリーンセットではSpecAugmentを導入しても認識精度はほとんど向上しませんでした。しかし、ノイジーセットではSpecAugmentを導入したことで誤り削減率5%を達成することができました。雑音重畳のみで学習を行うよりも、雑音重畳+SpecAugmentで学習した方が雑音環境下での音声認識性能が向上する傾向が見られました。
まとめ
今回は、雑音環境下での音声認識精度を向上させるための取り組みを紹介しました。SpecAugmentを使うことで、ヤフーの音声認識エンジンであるYJVOICEでも、雑音環境下での性能向上する傾向が見られました。しかし、性能改善の可能性があるとは言っても、SpecAugmentを使った性能改善率はまだまだ小さいです。SpecAugmentを使ったより大幅な性能改善の達成は今後の課題として取り組んでいこうと思います。
音声UIは、今後もいろいろな場面で使われることが考えられます。音声UIのユーザー体験を向上させるべく、これからもYJVOICEの性能改善に取り組んでいきます。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 桶作 愛嬉
- 音声認識エンジニア



