
こんにちは、Yahoo! JAPAN研究所の小林です。
ヤフーでは主に自然言語処理に関する研究開発を行っています。最近ではテキストの自動要約・生成の分野に興味があり、ボトムアップに有志で研究開発グループを立ち上げて最新論文の勉強会やモデル改善コンテストを開いたり、新しい技術をサービスに提案して実際にリリースしたりと、いろいろなプロジェクトを進めています。
サービス応用の実例としては、Yahoo!ニュース・トピックスの見出し候補生成、Yahoo!ニュース・コメントの建設的順ランキング、Yahoo!知恵袋のプッシュ通知生成などがあります。それぞれ、サービス担当のエンジニアやニュース編集者と密に連携しながら、定性評価やA/Bテストを繰り返してリリースを行っています。公開できる範囲の内容については下記のように国際会議でも発表していますので、興味のある方はチェックしてみてください。
- Yahoo!ニュース・トピックスの見出し候補生成
- Yahoo!ニュース・コメントの建設的順ランキング
- Yahoo!知恵袋のプッシュ通知生成
今回は上記のサービス応用事例の中から、昨年開催された国際会議NAACL 2019で発表した「トピックス見出し候補生成による編集者支援」の取り組みを紹介します。
人間によるYahoo!ニュース・トピックスの編集プロセス
Yahoo!ニュース・トピックスは、日々配信される大量のニュース記事の中から重要なニュース(トピックス)を厳選して紹介するサービスで、Yahoo!ニュースのトップページに掲載されている短い見出しのリスト(下図右)がそれにあたります。それぞれのトピックス記事は短い見出しと詳細記事・関連記事へのリンクなどから成っており、十数名の編集者が24時間体制で作成しています。
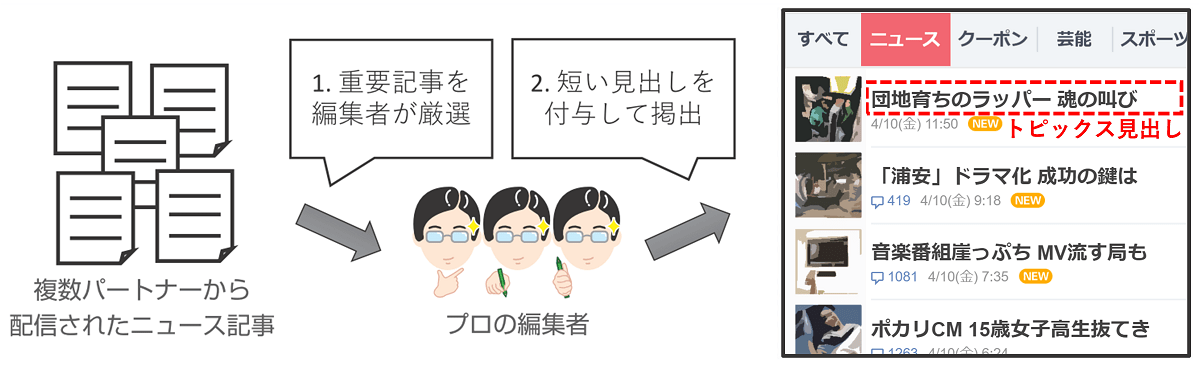
この編集プロセスの中で最も重要な要素の一つが、ニュース内容を分かりやすく短い表現で伝えるための「トピックス見出し」の作成です。トピックス見出しの長さは、表示領域や視認性などの影響を考慮して基本的に13.5文字(半角文字は0.5文字換算)と決まっており、熟練した編集者でもどう表現するかの判断を迷うことが多いそうです。例えば、こちらの「ダルビッシュ論争」に関する記事では、長い人名「ダルビッシュ」を「ダル」などに省略すべきか否かについての議論が紹介されています。
このような編集時の難しさを解決するために、Yahoo!ニュース編集部では熟練した編集者が持つ暗黙知に加えてA/Bテストなどのテクノロジーの活用を進めています。その一環として、当時(2015年)注目を集めていたニューラル見出し生成技術を用いて編集者支援ができないかという話になり、有志によるプロジェクトが立ち上がりました。
ニューラルネットワークでトピックス見出し候補を生成
トピックス見出しの編集を支援するために、与えられた記事に対して複数の見出し候補を自動生成するためのモデルを設計します。大まかな流れはニューラル翻訳モデルと同じで、Encoder-Decoderモデルという2つの再帰型ニューラルネットワークを組み合わせたモデルを用います。より具体的には、記事に付与された長い記事見出しから短いトピックス見出しへの"翻訳"タスクとしてモデルを定式化することで、見出し候補を生成するモデルを過去の事例から学習します。
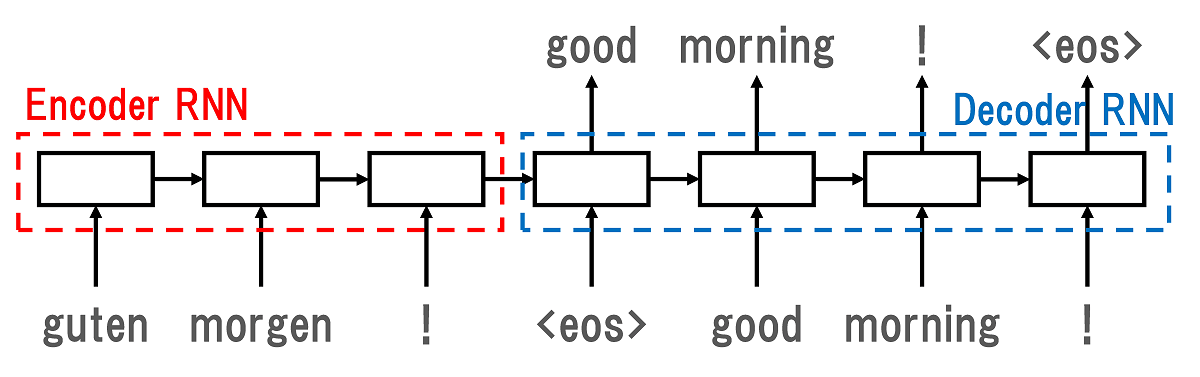
Encoder-Decoderモデルの最もシンプルな構造は下記のようなものです。Encoderは入力をある表現(例えば実数ベクトル)にエンコード(圧縮)し、Decoderがその表現を別の出力へとデコード(解凍)します。下記の例は、Encoderが「guten morgen !」を1単語ずつ入力してエンコードした後、Decoderが「good morning !」を1単語ずつデコードしています。このように対応する入出力のペアを大量に用意しておけば、モデルの尤もらしさ(全体的な出力の正確性)を計算できるので、これを最適化するようパラメータを調整することでモデルの学習を実現できます。
論文では上記より少し複雑なモデル、具体的には複数エンコーダを用いたアテンション機構付きのEncoder-Decoderモデルを用いて文字単位で学習していますので、詳細については論文(NAACL 2019)を参照ください。ちなみに、現在の編集支援ツールでは、より新しいモデル構造であるTransformerモデルを複数結合したアンサンブルモデル(EMNLP 2018)が利用されています。
見出し候補生成モデルの編集支援ツールへの導入
学習後の見出し候補生成モデルを下記のように編集支援ツールに導入しました。このツールは編集者がトピックス見出しを編集・入稿する際に実際に利用するもので、ここに複数の見出し候補を表示することで編集者に見出し表現の気づきを与える効果が期待できます。ツールの挙動はシンプルで、下記の通りです。まず、編集者がトピックス記事に用いる記事詳細ページのURLをツールに入力します。このとき、記事の見出しやリード文といった情報を自動取得し、同時に見出し候補生成モデルが返却した見出し候補のリストを表示します(右上グレー背景の表示領域)。

見出し候補の見せ方については、編集者のフィードバックを元に3つの細かい工夫を入れています。1つ目は「見込みのない候補の切り捨て」で、候補リストの質を担保するためにモデルの出力スコア(見出し候補が生成される確率)に基づいて質の悪い見出し候補を表示しないようにしました。2つ目は「重複する候補の除外」で、限られた表示領域で多様な候補を提示するために文字列類似度に基づいて表現の似通った候補を表示しないようにしました。3つ目は「未知語のハイライト」で、生成された候補のファクトチェックを促すために記事詳細に含まれない文字をハイライトするようにしました。
見出し候補表示機能のリリース前後の効果
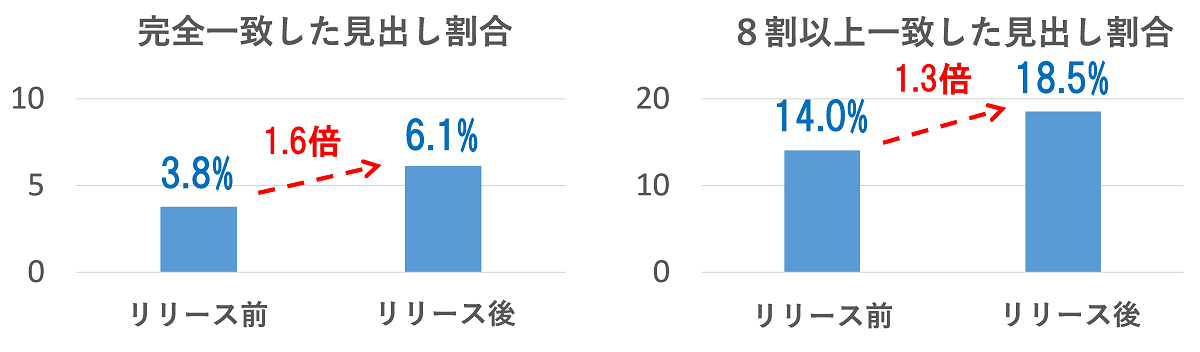
提案された見出し候補は、どの程度が編集者に採用してもらえる品質だったのでしょうか? この疑問に答えるために、見出し候補表示機能のリリース前後における編集者見出しと(自動生成)見出し候補の文字列一致度を比較しました。文字列一致度は、表示されている複数の見出し候補それぞれに対して、実際に掲出された編集者見出しとのROUGE-L指標(最長共通部分列の割合)を計算し、その最大値で算出しました。
下記2つのグラフはリリース前後の文字列一致度について、完全一致(ROUGE-L=1.0)の見出し割合と8割以上一致(ROUGE-L≧0.8)の見出し割合を表しています。グラフの見方としては、例えば8割以上一致のリリース後の割合18.5%は、実際に掲出された編集見出しのうち18.5%が(最良の)見出し候補と(文字列として)8割以上一致していることを意味しています。各グラフのリリース前後を比較すると、完全一致の割合が1.6倍、8割以上一致の割合が1.3倍向上していることが見て取れます。これらの結果は、見出し候補表示機能が編集者に一定の気づきを与えていることを示唆しています。
国際会議NAACL 2019での発表
これまで説明してきた内容をまとめて、自然言語処理のトップ会議NAACL 2019の産業トラック(Industry Track)で発表を行いました。産業トラックは実世界応用に特化した企業向けの発表トラックで、査読時に実用化を重視した評価が行われるという特徴があります。2019年の採択率は24.5%(114投稿中28本採択)と、メイントラック(採択率24.4%)と同程度に設定されていますが、"良い査読者"に当たる確率が高いので企業研究者の方にはオススメです。
採択された28本の論文を見ると、Alibaba、Amazon、Apple、Facebook、Google、IBM(五十音順、略称)など、国際会議の常連企業が並んでおり産業トラックの注目度の高さが伺えます。その中でもAmazonは9本の論文が採択されており、ひときわ目立っていました。私たちの論文については、当時としては見出し生成の実用化論文として珍しかったこともあり、ありがたいことに口頭発表10本の中に選んでもらいました。久しぶりの口頭発表で緊張しましたが、発表後にも質問をしに来てくれる人がいてとても励みになりました。今後も機会があれば実用化研究を発表していこうと決意した次第です。

おわりに
今回は国際会議NAACL 2019で発表した「トピックス見出し候補生成による編集者支援」について紹介しました。現在もさまざまなサービス改善に関する研究開発を進めており、直近では下記2つの会議で発表します。もし興味を持たれた方は各会議の公式ページをチェックしてみてください。
- The 42nd European Conference on Information Retrieval (ECIR 2020)
- Distant Supervision for Extractive Question Summarization
- Semi-Supervised Extractive Question Summarization Using Question-Answer Pairs
- Unsupervised Ensemble of Ranking Models for News Comments Using Pseudo Answers
- 2020年度人工知能学会全国大会(JSAI 2020)
- 人手評価を考慮した強化学習に基づくニュース見出し生成
- 自然勾配ブースティングを用いたニュース見出しの信頼度付きクリック率予測
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 小林 隼人
- Yahoo! JAPAN研究所



