
はじめまして、Yahoo!乗換案内(以下、路線サービス)でシステム開発を担当している丸山です。
路線サービスでは2月末に、主要路線における混雑時間帯を可視化したブログ記事を公開しました。
今回はこの背景について紹介いたします。
検索ログから混雑時間帯を分析
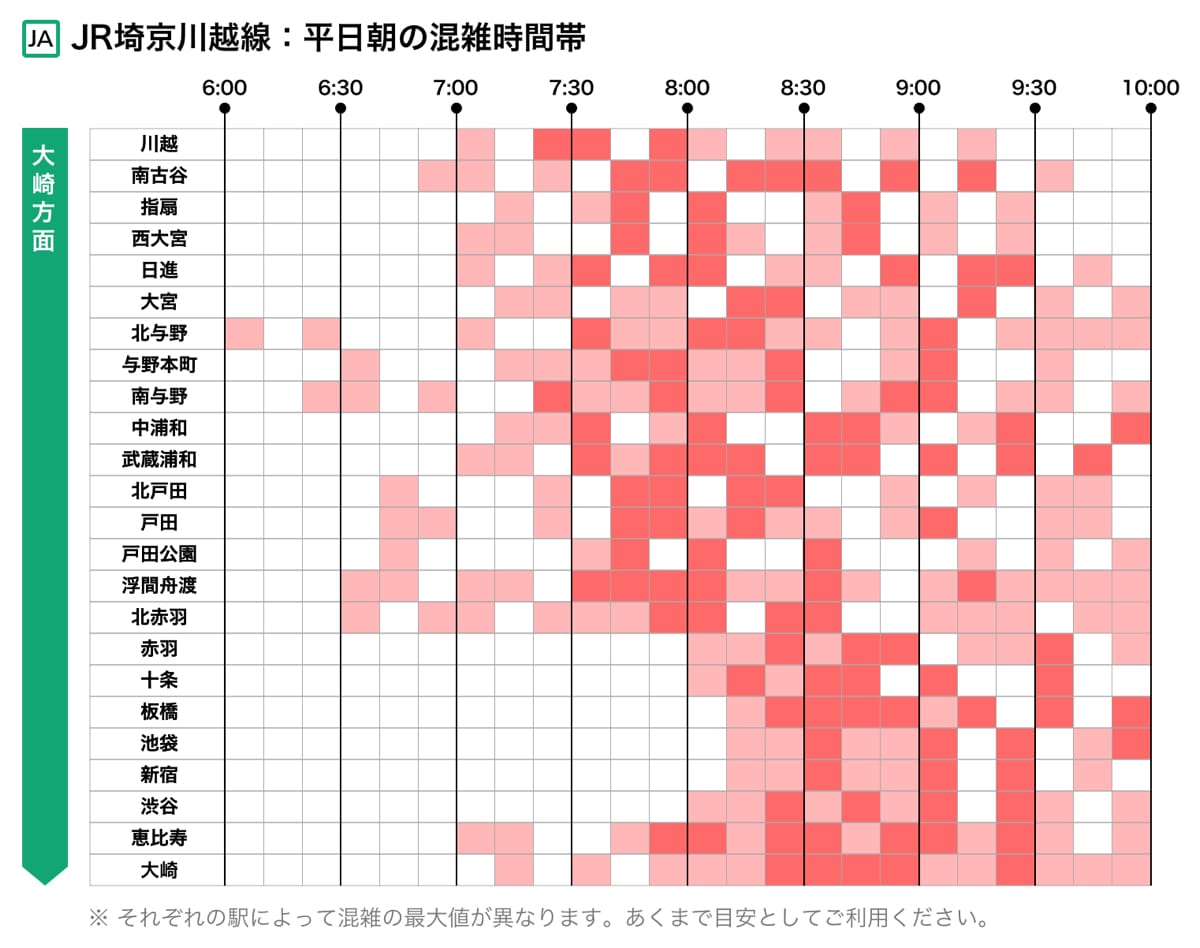
この記事では、関東・関西の8つの主要路線における平日朝の混雑状況をヒートマップで表現したものを掲載しています。混雑度は検索ログから算出しており、駅ごとに基準を変えています。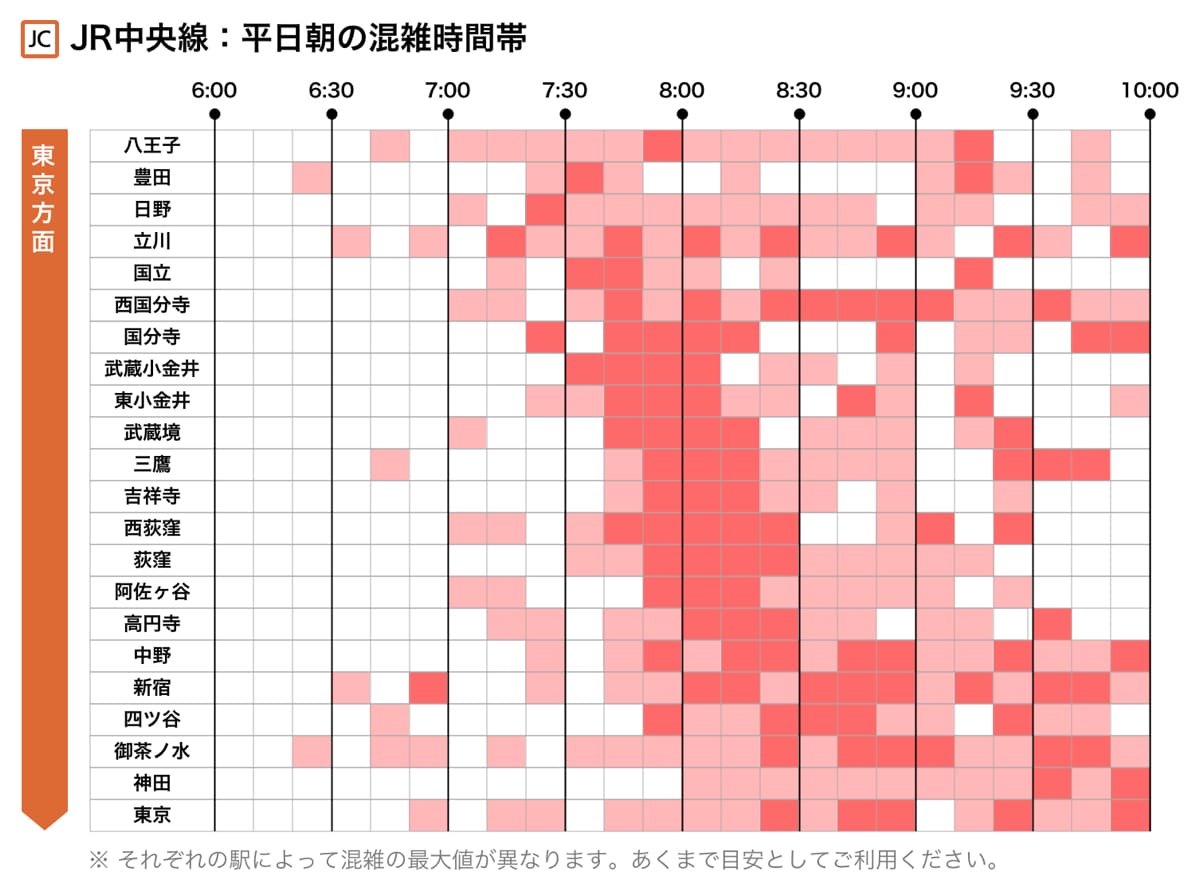
このデータ公開のきっかけは新型コロナウイルスの流行でした。イベントへの参加や外出することに対して敏感になってきており、移動に携わるサービスとしてどのような情報を提供すればユーザーのためになるかを検討し始めました。その中で、混雑を避けた通勤や移動がニーズとして高まっているという話が挙がり、通勤ラッシュ時間帯の混雑度が分かるとよいのではないかという話になり、このブログを書く運びとなりました。
先ほど混雑度は検索ログから算出していると書きましたが、もう少し正確に言うと、異常混雑予測という機能を実現する中で算出している平常時の検索数から出しています。ここで言う検索ログとは、ユーザー1人1人の経路検索結果に含まれる出発〜到着駅を出発/到着時間とのセットで蓄積したものです。以下に検索ログの一例を記載します。
{
"From": "東京",
"To": "大阪",
"AccessDate": "202004010700",
"InputDate": "202004010700",
"Route": [
{
"RouteNumber": 1,
"DepartureTime": "202004010700",
"ArrivalTime": "202004010930",
"RouteSection": [
{
"RailID": "27:0",
"Direction": "Down",
"StationList": [
{
"Name": "東京",
"Code": 22828,
"ArraivalTime": 700,
"DepartureTime": 702,
},
{
"Name": "新橋",
"Code": 22751,
"ArraivalTime": 705,
"DepartureTime": 707,
},
(中略)
]
}
]
}
]
}このデータを「路線」「方面」「駅」「時間帯」ごとに集計することで、いつ、どの路線のどの駅が何回検索されたか、ということが分かるようになります。異常混雑予測ではその集計データを利用して平常時や特定日の検索数を算出しているので、今回はそのデータを利用しました。
異常混雑予測は約2年前に乗換案内アプリで公開された機能なのでご存じの方もいるかと思いますが、最近リリースした駅混雑予測と合わせて紹介します。
異常混雑予測とは?

「いつもは空いているのに今日はやたら混んでるな...」そんな経験をしたことはないでしょうか?
この機能はそうした突発的な混雑を事前に予測し、ユーザーに伝えることを目的に開発しました。
機能自体は2018年2月に路線サービスで公開したものです。また2016 年にはUbiComp というトップカンファレンスで本件に関する論文が採択されています。
CityProphet: City-scale irregularity prediction using transit app logs
※余談ですが、UbiComp の論文採択率は20%前後と非常に敷居の高いものとなっています。
どのように混雑を予測しているのか
混雑を予測する仕組みを簡単に説明すると、平常時の検索数と特定日の検索数の予測を比較し、「普段と比べて何倍検索されるか」を分析することで実現しています。
一般的に混雑といえば車両に対する乗車率をイメージされると思うのですが、この機能では平常時と比較することで、「いつもより混雑するかどうか」を予測しています。そのため機能名も「異常混雑予測」としており、普段は混んでいないけれど今日は混んでるといった「異常」な状態を予測するものとなっています。
とはいえ、あまりにも検索数が少ない駅ではすぐに倍率が上がってしまうため、検索数に対して一定の下限値を設けており、その数値を超えた上で平常時に比べ数倍の検索が予測される場合のみ混雑とみなし、情報を表示するようにしています。
検索数算出の仕組み
このように本機能では平常時と未来の特定日の検索予測値が必要になってきます。
この2つの検索数を算出するため、以下のモデルを使っています。
- bilinear モデル: 平常時の検索数を算出する
- ar モデル: 未来の特定日の検索数を算出する
どちらのモデルも経路探索ログを学習データとして使っており、10分単位で検索数の予測値を算出します。学習にはだいたい1-2カ月分の検索ログを用いており、非常に膨大な量のデータです。1日だけでも数千万レコードの経路探索ログが蓄積されるため、Hadoop のMapReduce を用いて日次でデータクレンジングを行っています。
平常時の検索数は、過去の同じ曜日の検索数を元にしており、そこから平均的な数値を算出しています。ただし、過去のデータの中に公演やイベントなどで非常に検索数が増える日が含まれることもあります。そうした普段とは異なる検索傾向を持つ日を「外れ値」と自動的に判定し、除外した上で平均的な数値を算出しているのがbilinear モデルとなっています。
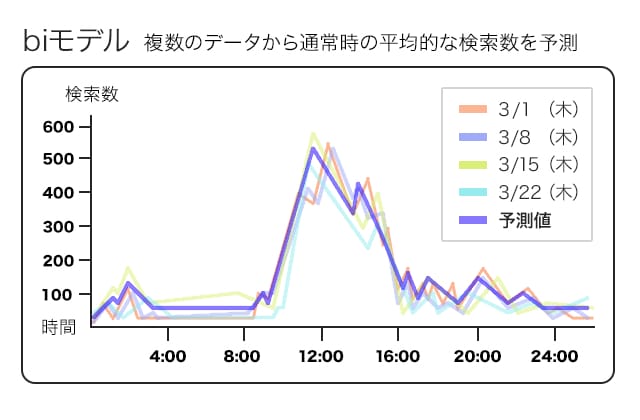
この平常時の検索数についてはなんとなくイメージいただけるのではないかと思います。
では未来の特定日の検索数は、過去の検索ログからどうやって算出しているのか。
これについてはまず検索ログの特徴から説明したいと思います。
路線サービスにはイベントやライブ会場等へのルートを、何日か前から検索するユーザーが一定数存在しています。そうした事前に検索されたログを蓄積していくと、当日の検索数に徐々に近づいていきます。以下は2015年にコミックマーケットが開催される日を指定した状態で、国際展示場駅までのルートが検索された数をグラフにしたものですが、その傾向がよく見て取れると思います。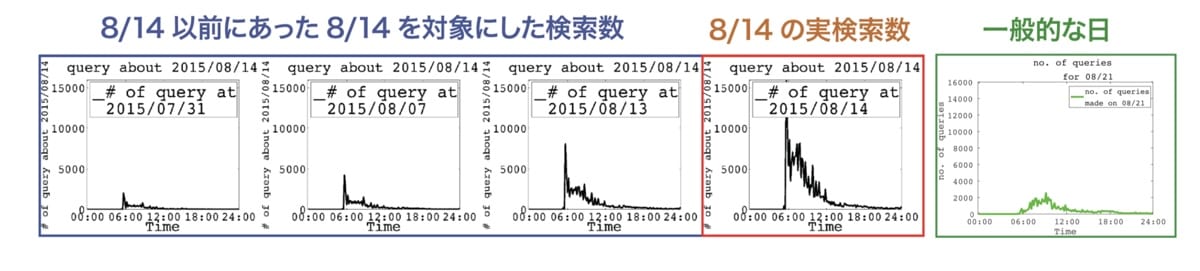
この検索数の推移を学習することで、「X日前の検索数をX倍し、足し合わせることで当日の検索数になる」というのが分かるようになり、未来の検索数が予測できるようになります。その役割を果たしているのがar モデルです。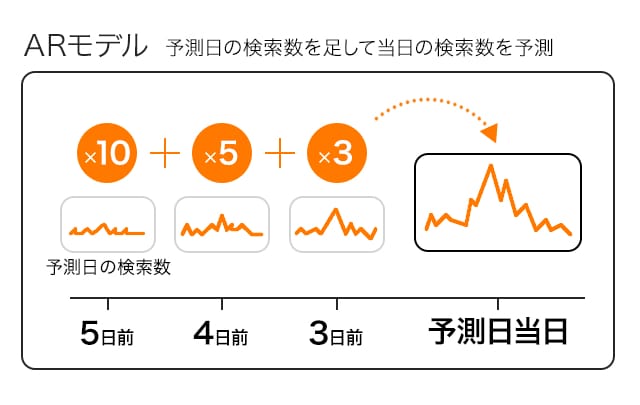
2種類のモデルについてはこちらのブログでも紹介しているのでよければ御覧ください。
【異常混雑予報】データの仕組みについてご紹介ー後編
異常混雑予測の抱える課題
上記の仕組みを利用することで、将来発生する混雑を検知できるようになりました。特に花火大会やコミックマーケット、アーティストのライブといったあらかじめ開催が決まっているイベントに対して、高い精度で混雑を予測できます。その一方で、ゲリラ豪雨や電車の運休/遅延といった、当日の急な変化は反映できないといった課題が見つかりました。
そこで路線サービスでは準リアルタイムに検索ログを集計し、駅の混雑を検知する機能を開発し、3月上旬にリリースしました。
駅混雑予測とは?

異常混雑予測が過去の検索ログから未来の混雑を予測するものだったのに対して、駅混雑予測は当日の検索ログを準リアルタイムに集計し分析することで、突発的に発生する駅の混雑を予測・検知するものになっています。本機能には異常混雑予測の課題を解決する意味合いもありますが、天候の崩れやイベント、電車の遅延等で発生する混雑や入場規制を検知し、ユーザーに情報を届けるというのが一番の目的にあります。
電車の遅延や運休情報は鉄道会社からも公式情報として発表されるのですが、混雑や入場規制といった情報はSNSなどで調べないと分からない場合が多いです。そのため駅まで行って初めて規制されていることを知る、といった経験をされた方もいらっしゃるのではないでしょうか。
混雑や入場規制の情報を届けることで駅まで行かなくても駅の状況が分かるようになり、別の駅/路線を利用したり、周辺の施設で時間を潰すといった選択ができるようにすること目指し、この機能を開発しました。
どのように検知しているのか
混雑/入場規制の検知を実現するため、路線の検索ログとSNS への投稿内容を利用しています。
開発に着手する前に実現可能性を見極めるため、「入場規制が発生した場合に検索数が増える」という仮設を立て事前に調査を行いました。入場規制や混雑が発生した駅をピックアップし、他の日と比べて検索傾向にどのような違いがあるのかを見ました。すると、入場規制が発生した時間帯から、その駅を出発地とした検索が増えることが分かり、仮設が正しいことが分かりました。また入場規制とまでは行かないまでも混雑した状況が発生する場合に、徐々に検索数が増えてくるケースもありました。
見えにくいですが、こちらが調査時に検索ログを可視化したものの一部です。
- 品川: 12/6 入場規制

- 水道橋: 9/24 ライブ開催

- 片瀬江ノ島: 10/20 入場規制

上記の調査により検索ログを利用することで考えている機能が実現できると考え、開発を進めることになりました。このときの調査では箱ひげ図で外れ値を出して傾向を見ただけでしたが、最終的に3種類の閾値を事前に算出しておき、当日集計した検索数と突合することで検知するようにしました。
混雑度判定の判定
混雑度は以下3の閾値を用いて判定しています。
- 時間帯別
- 平常時よりも検索数が多いかどうかを判断するために利用
- 10分単位で算出しておく
- この数値を超えていない場合は混雑度Lv1,2 の閾値を超えていても混雑とは判定しない
- 混雑度Lv1
- 混雑度を判定するための閾値
- 各駅の検索数の平均に分散を考慮したもの
- 混雑度Lv2
- 混雑度を判定するための閾値
- 各駅の過去30日間の最大値の平均に分散を考慮したもの
混雑度Lv3 は入場規制を指すのですが、入場規制は検索ログだけでは判断ができませんでした。そこで混雑度Lv2 が発生している、かつSNS に当該駅の入場規制に関する情報が複数件投稿されているか否かでLv3 を判断するようにしました。
どこに表示される?
判定した結果は経路検索の結果画面と駅情報画面に表示されます。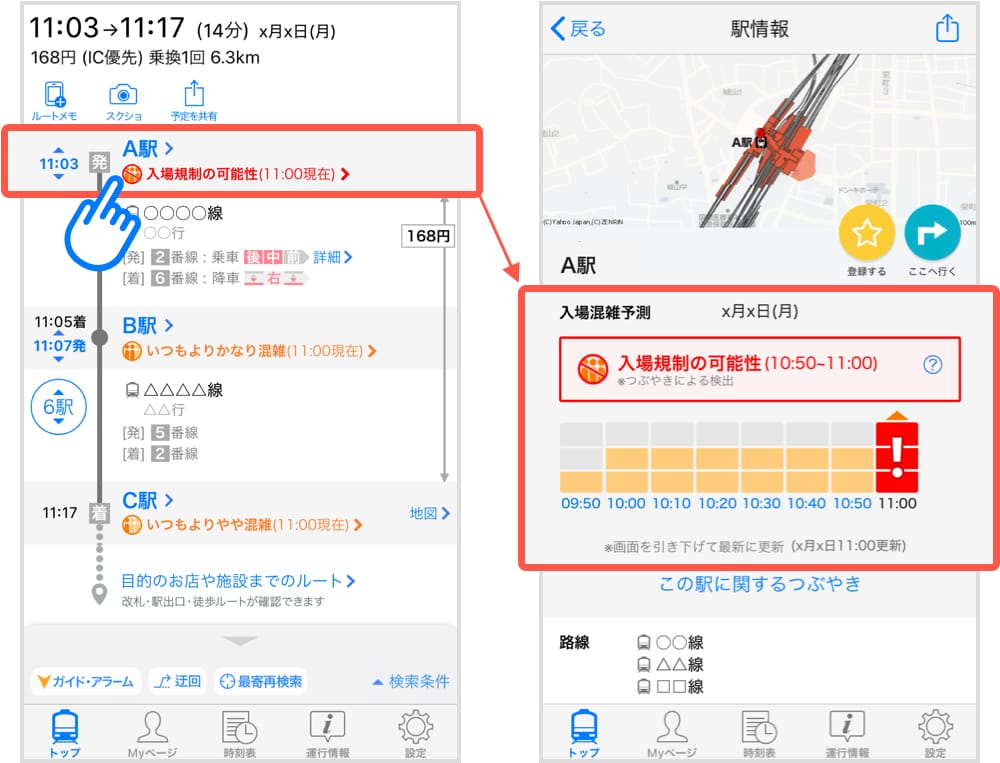
検索結果画面では現在検知しているもののみ表示されますが、駅情報画面では時系列で混雑度を見ることができ、混雑の増加/減少傾向を見ることができます。またこの画像には含まれていませんが、少し下にスクロールするとその駅周辺の別の駅や話題のお店、カフェなどを調べる機能もあります。
混雑や入場規制に巻き込まれた際にはこちらの機能もぜひご利用ください。
ブログ公開までの流れ
少し話が逸れましたが、このように路線サービスでは検索ログを分析し機能開発に利用しています。今回のブログではその中の一部データを利用して可視化を行った次第です。
ブログ公開までの流れは以下の通りです。
- 2/25
- 企画検討
- データ抽出
- グラフ作成
- 記事作成
- 2/26
- グラフ、記事の内容チェック
- 2/27
- 記事公開
企画検討からブログの公開までわずか2日と、非常にスピード感を持って取り組めた事案でした。振り返ってみると、このように短期間でできたのは以下のような要因があったからだと思います。
密接なコミュニケーション(Slack&Zoom)
コロナの影響もあり、ほぼ全員が自宅にて勤務していたのですが、Slack やZoom を使って常に連絡が取れる状態になっています。この日も企画を検討する際、Slack にて関係者に呼びかけを行いZoom で打ち合わせを行いました。全社員が当然のものとして利用していますが、リモートワークをしていても円滑にコミュニケーションが取れる環境が整っていることは非常に重要だと感じました。
高速な意思決定
意思決定に携わる人数が必要最小限だったため、方向性を合わせてやると決めるまで短時間だったことも要因の1つだと思います。このときはSlack 上でサービスメンバー全員にどういったことをすればよいかの案を募りましたが、最終的にサービスマネージャー、企画、デザイナー、エンジニアが1名ずつZoom 会議に参加し(計4人)、内容を決定しました。
混雑情報の間接利用
先ほど紹介したように、今回既に存在するデータを利用して可視化を行いました。平常時の検索数はデータベースにも登録されているので、対象路線に絞り込んで取り出すだけで済み、データ抽出の作業時間を大幅に短縮できました。データの分析から取り掛かっていた場合、これほど早く公開することはできなかったと思います。
デザイナーの迅速対応
抽出したデータを元にデザイナー陣がグラフを作成してくれたのですが、駅ごとに検索母数が異なっていたり駅を順番に並べたりする必要があったため、1つのグラフを作成するのに40分〜1時間程度必要でした。今回は8路線を対象に作成したので8時間ほどかかる想定でしたが、この地道なグラフ作成作業をデザイナーチームが各自のタスクを追えた後に行い、1日で終わらせてくれたことが大きかったです。
まとめ
以上が主要路線における混雑時間帯集計の裏側でした。
路線サービスでは今後もこうしたデータ活用を積極的に行い、新たな機能開発を行ったりサービスのグロースを行っていく予定です。ユーザー数が非常に多く、大量のデータを抱えているヤフーだからこそできることがまだまだあると思います。また他サービスのデータを組み合わせることでよりユーザーの利便性を高める機能開発に繋げられると考えています。
データ分析やデータドリブンなサービスのグロースに興味・関心のある方は、ぜひ一度弊社の採用ページをご覧ください。
写真:アフロ
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 丸山 三喜也
- Yahoo!乗換案内エンジニア
- Yahoo!乗換案内のシステム開発をしています。



