
こんにちは、ナレッジベースの生成を担当している真壁です。
この記事では、ナレッジベースの概要、ヤフーにおけるナレッジベースの活用事例、ナレッジベース構築における主要な課題をご紹介します。
より具体的な内容は、先日行われたYahoo! JAPAN Tech Conference 2019 in Shibuyaでの山崎の発表内容をご参照ください。
ナレッジベースとは
ナレッジベースとは、世の中の物事や概念(エンティティと呼びます)とその関係を構造化して格納したデータベースです。
それぞれのエンティティはIDと自身に関する情報を持っており、関連のあるエンティティとはその関係の種類が区別できる形式でリンクされています。
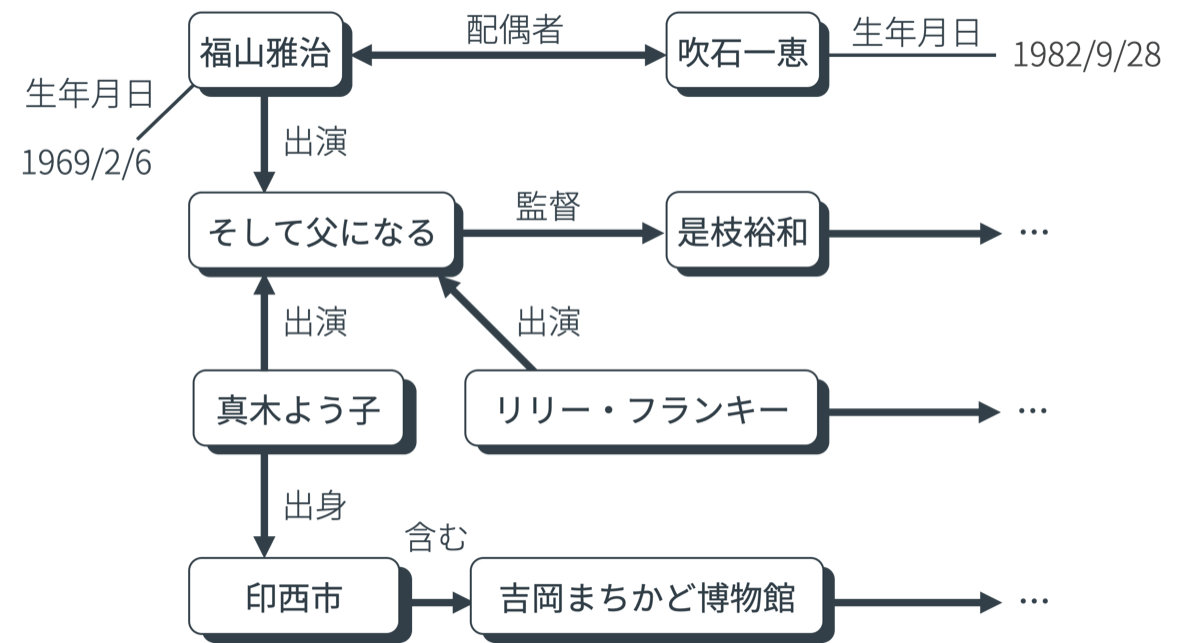
各エンティティが持つことができる情報はオントロジー(エンティティの分類やそれぞれの分類が持つ属性を体系的に整理したもの)により定義され、オントロジーに従って推論することによりナレッジベースを拡張していくことも可能です。
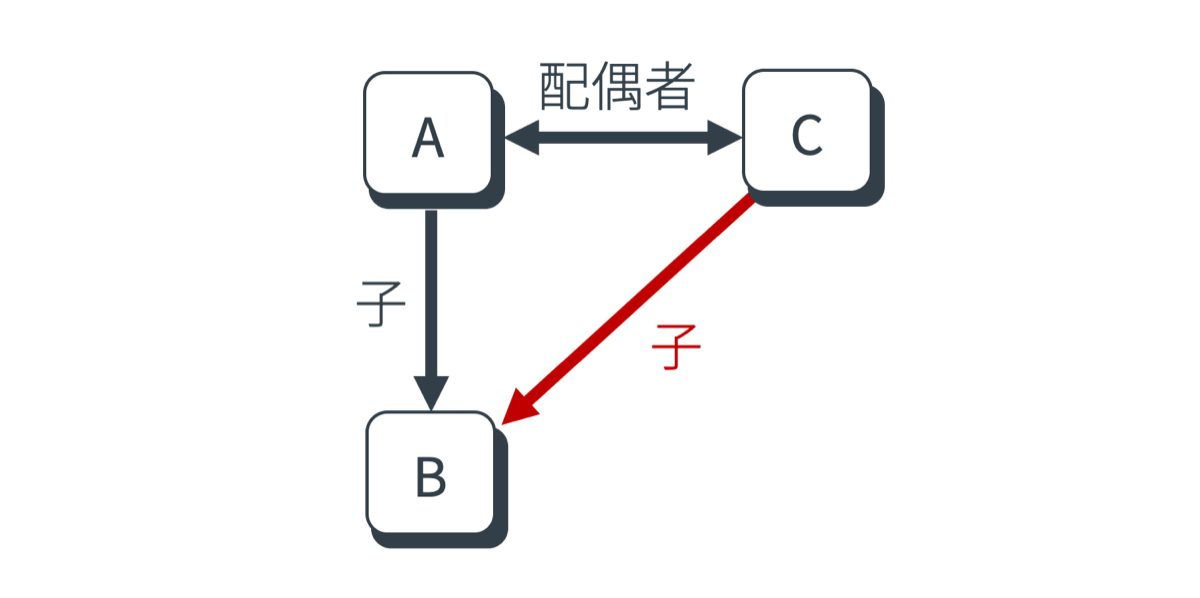
例えば下の図では、人物Aの子供が人物Bであることと人物Aの配偶者が人物Cであることが既知である時、BはCの子供でもあるという推論を行いBとCの間に親子関係のリンクを補完する様子を表しています。
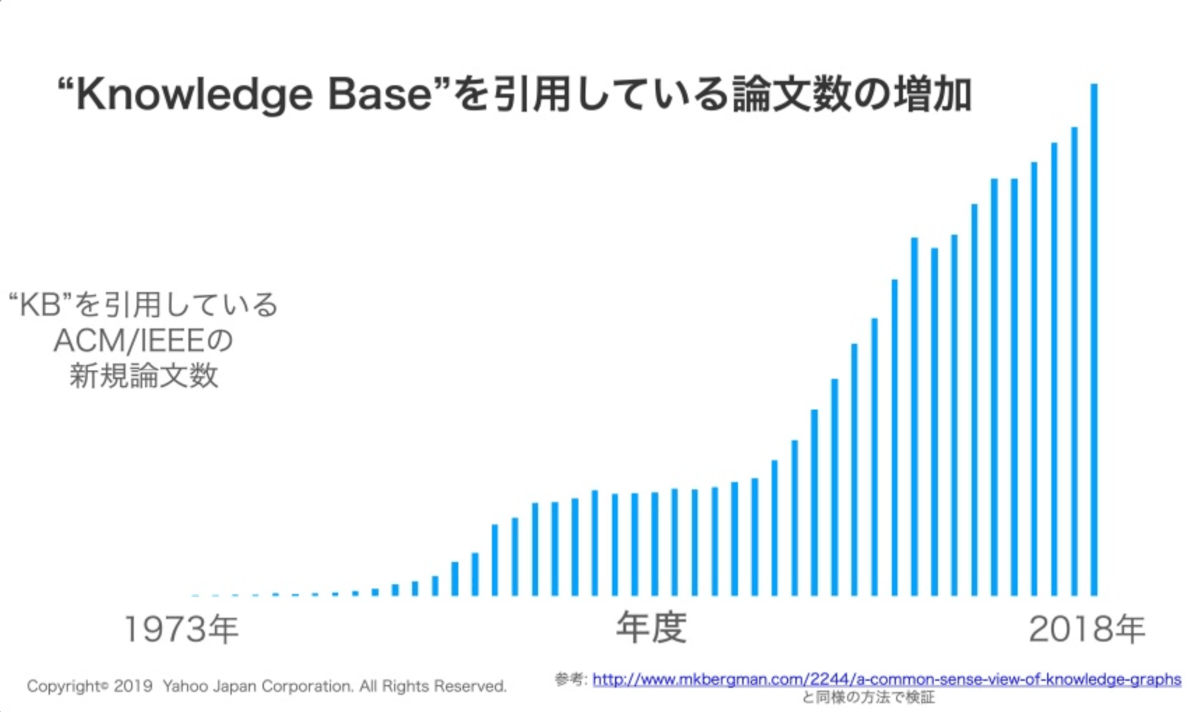
また、ナレッジベースは学術領域でも広く関心を集めており、多くの活用事例や拡充手法が世界中から幅広く報告されています。
下の図はナレッジベースに言及する論文数の推移を示したものです。近年特にそのような論文の数が急増していることが分かります。
ヤフーにおけるナレッジベースの活用
ヤフーでは100以上のサービスを運用しており、どのサービスにも共通して言えるのは、それぞれのユーザーに対する最適なコンテンツ提供が重要であることです。
それぞれのサービスにおいて、ユーザーの行動ログを活用し最適なコンテンツの提供に役立てています。
しかし、それぞれのサービスのログが共通化されていない場合、他のサービスに活用することは容易ではありません。
例えば、ある人物Aが登場するコンテンツがあるとします。そのコンテンツを閲覧した人はAに興味があるとみなせば、Aが登場する別のコンテンツを優先的に提供できます。
しかし、この人物Aを表すIDが各サービスごとバラバラであるため、あるユーザーがAに興味があるという情報は他のサービスでは利用できません。
そこでナレッジベースを用いると、さまざまなサービスのさまざまなコンテンツに登場するエンティティをナレッジベース上のエンティティにひもづけることが可能になります。
このように共通のエンティティとして扱うことができれば、あるサービスでのデータを他のサービスで活用することが大きく容易になります。

また、関連するエンティティ同士がリンクされている特徴を活用し、より進んだ興味推定を行うこともできます。
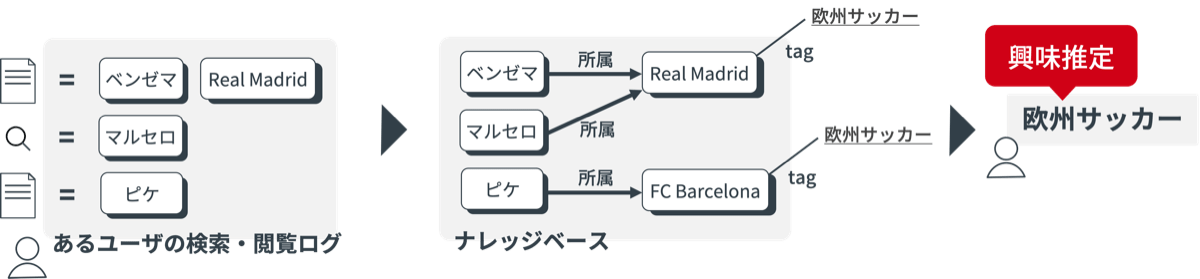
例えば、あるユーザーが一部のサッカー選手やサッカーチームの登場する記事をよく読んでいたとします。
ナレッジベース上のリンクをたどると、それらの選手やチームが共通して特定のリーグに属していることがわかります。
この情報を活用すると、単にそれぞれの選手やチームが登場するコンテンツを推薦するだけでなく、そのリーグ、またそのリーグに関連するコンテンツを含めたより幅広い推薦が可能になります。
ヤフーでのナレッジベース構築における主な課題
ヤフーのサービスの基盤となるようなナレッジベースを構築する際の主要な課題をいくつか紹介します。
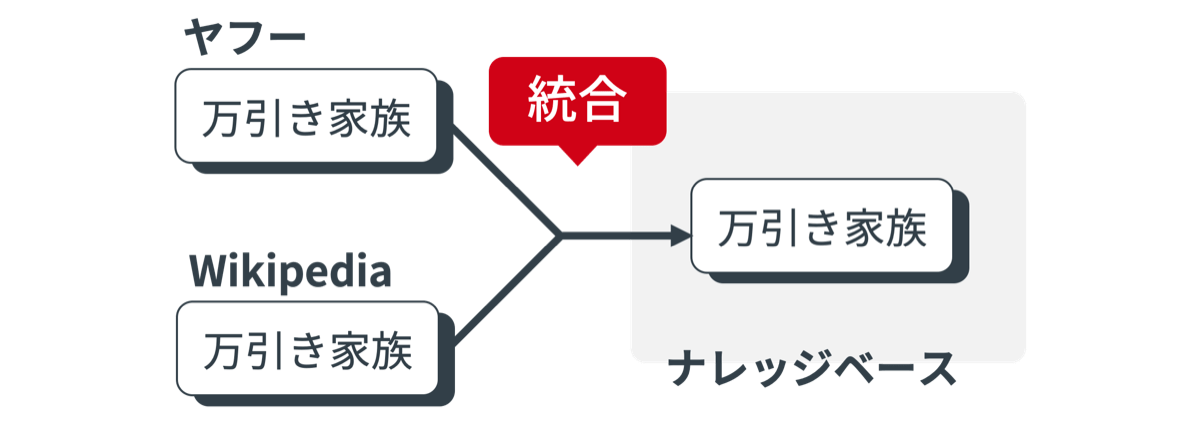
同一エンティティの統合
さまざまなデータソースを集約してナレッジベースを構築しているため、異なるデータソースから同一のエンティティを表すデータが複数得られます。
同じエンティティが複数存在するとエンティティの同定が困難になるので、一つのナレッジベースの中で同じエンティティは一つに統合しています。
基本的には、エンティティが持つ情報(名前、生年月日、緯度経度など)を手掛かりにして同一のエンティティ同士を統合するような仕組みを取り入れています。
情報の正確性の担保
ユーザーに対して掲出する情報には、高い正確性が必要です。ナレッジベースから正確性の高い情報だけを抜き出せるようにするため、ナレッジベースの中の情報にはその情報がどれだけ信頼に値するかを表す数値を割り当てています。
ナレッジベースを構成するデータソースはさまざまな種類があり、それぞれに特徴があります。
例えば、Wikipediaのようにさまざまな人が自由に編集できるデータソースは、幅広い種類のエンティティに関する情報が含まれる一方、詳しい人が少ない分野のエンティティなど、誤りが含まれる場合がどうしても避けられません。
一方、ヤフーが独自に用意している特定の分野のデータは、エンティティの種類こそ少ないですが、きちんとした情報源を用いて専門家により作られているため一つ一つの情報の正確性は非常に高いです。
これらさまざまな性格のデータソースから得られた情報を組み合わせて、最終的な情報の信頼度を算出しています。
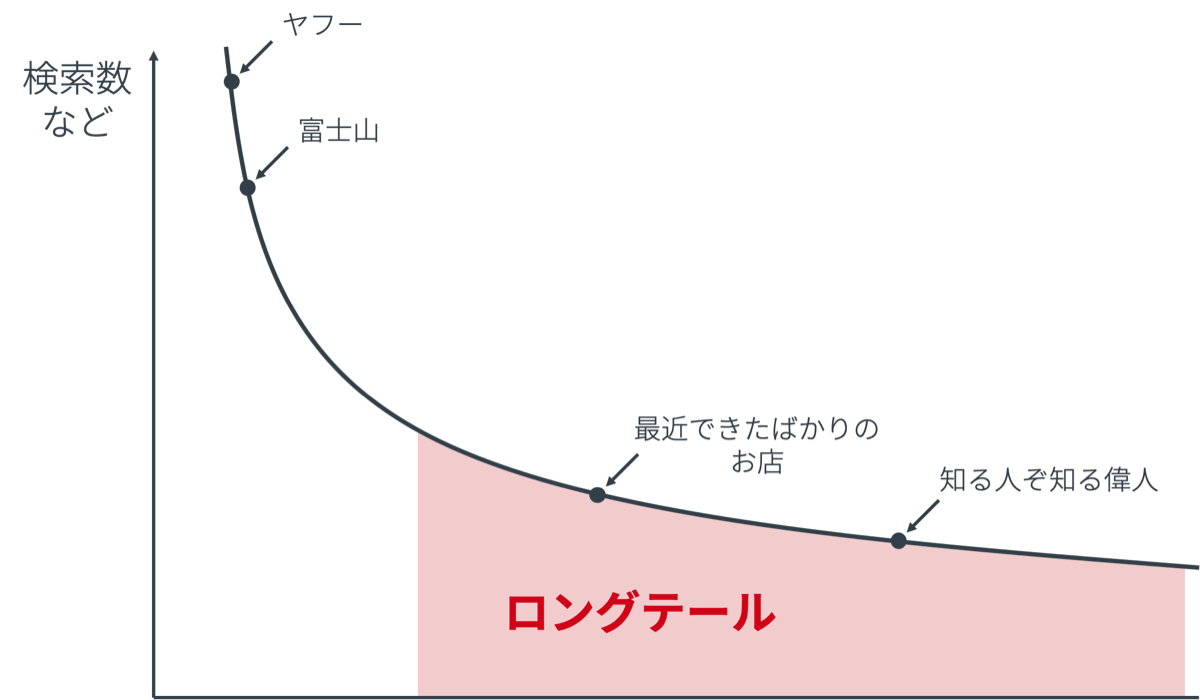
ロングテールエンティティの情報収集
ユーザーの検索するクエリやニュース記事に含まれるエンティティは多岐にわたり、主要なデータソースに情報がない場合も多いです。
このような登場する機会の少ないエンティティをロングテールエンティティと呼んでいます。
ロングテールエンティティと関連のある検索やコンテンツの数の合計はそれなりに多いため、ナレッジベースにはこのようなエンティティの情報もそろえておくことが必要です。
この他にも、最近急に流行り出したスポットやミュージシャンなども、既存のデータソースには含まれないこともあります。
このようなエンティティの情報を集めるための一つの手法として、ウェブ上のリソースからの情報抽出を行っています。
まとめ
ナレッジベースは世界中で活発に研究されており、ウェブサービスの質を高められるポテンシャルがあります。 ヤフーではさまざまなデータを統合して独自のナレッジベースを構築し、サービスに活用しています。 よりよく活用するため、さまざまな課題に対して知恵を絞って日々取り組んでおり、一緒に知恵を絞ってくれる仲間を常に募集しています。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



