
こんにちは。寺田晃太朗 (@kotarotrd) です。 2018年4月に新卒でヤフーに入社し、データエンジニアとして働いています。 2019年10月に Apache NiFi Committer になりました。
私は昨年のAdvent Calendarで、注目するデータソリューション技術として「量子アニーリングがチョットワカルようになる記事」を書きました。 今年のAdvent Calendarの記事では、例えばそんなデータサイエンスを最大限に活用するために、データプラットフォームとしてデータ連携をどのように効率化できるかというテーマについて記事を書きます。
この記事では、Yahoo! JAPANのデータフロープラットフォームの役割とどのように活用されているかをご紹介します。
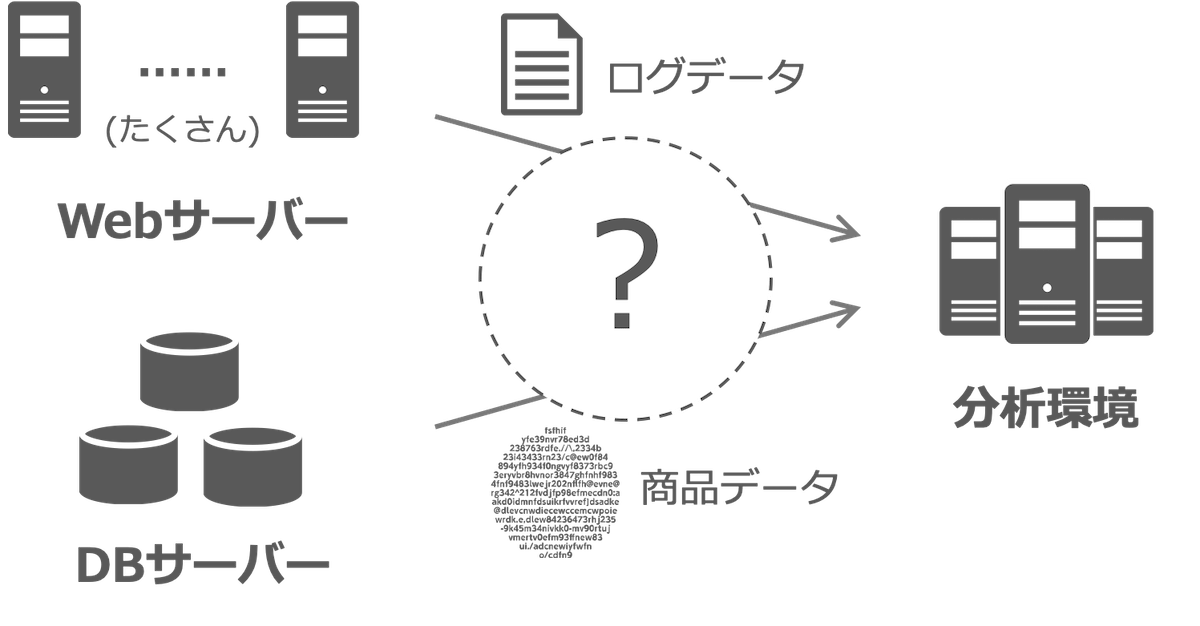
このような時どうやってデータを移動しますか?
以下のようなシナリオを考えてみましょう。
あなたはソフトウエアエンジニアで、とあるWebサービスを開発して運用しています。
サービスでは日々いろいろなデータが発生します。 ここでは、複数台のWebアプリケーションサーバーでユーザーがアクセスしたときに発生する「アクセスログデータ」と、データベース(DB)サーバーに保存されている「商品データ」を扱うことにします。
これらのデータを利用して、クリスマスの日に売上が最大化できるような施策を打つために、これまでのデータを分析すれば商品の見せ方を変えたり、新しい機械学習のモデルを作ることができるなと考えました。 しかし、サービスのデータは本番環境に存在しており、データ分析や機械学習モデル作成のためには分析環境にデータを移動する必要が出てきます。
さて、どうやってデータを移動するのがよいでしょうか?
(1) そもそも移動しない、(2) ジョブスクリプトを作成して移動させる、(3) システムに組み込む、といった方法が考えられますが、それぞれの手段を取ったときにどのような課題が発生しうるかを考えてみます。 もちろん稼働しているサービスの規模や種類にもよってどの方法が一番よいかは一概に判断できませんが、Webアプリケーションは複数台のサーバーで稼働していてデータ量も比較的多いとして考えてみます。
(1) そもそも移動しない
もっとも何もしない方法としては、そもそもデータの移動をせずに分析環境から本番環境のデータを触りにいくというのが思いつきます。 しかし、以下のような課題が考えられます。
- 分析の都合でサービスのデータにアクセスするために稼働中のサービスに大きな影響を与える (サービスが稼働しているサーバーのリソース消費など)
- データにアクセスする都度、サービス稼働環境と分析環境の間のネットワークに大量のデータが流れてしまい非効率
- 本番環境のログデータなどに分析環境からアクセスできるようなACLはセキュリティ的にもデータガバナンス的にもよくない可能性が高い
これは今回のケースには適していないでしょう。
(2) ジョブスクリプトを作成して移動させる
サービス稼働環境から分析環境へのデータ移動を実行するジョブスクリプトを作成し、それを手動やcronなどで実施する方法も考えられます。 しかし、以下のような課題が考えられます。
- そのようなスクリプトはフレームワーク化されていない限り最初から作らないといけない可能性が高く一大開発
- 複雑な処理を組み込むのが難しい
- 手動の場合は手順書を作成しても人手によるミスが発生する可能性があり、本番環境でやらかしてしまう可能性をはらんでいる
- ジョブを実行するシステムがダウンしてしまうと完了できない
- 基本的にバッチ処理となるためリアルタイム性は達成できず、また特定の時間にサーバーリソースやトラフィック増加を許容できない場合に不適
- システム障害(ハードウエア障害やネットワーク障害など)でジョブが失敗したときのリカバリー処理が大変
- データへのアクセス制御を組み込むことが難しい
これも今回のケースではあまり適していないと言えるでしょう。
(3) システムに組み込む
Webアプリケーション自体にデータを送り込む機能を実装する、もしくは分析環境のほうでデータを取ってくる処理を追加する方法も考えられます。 これによりいくつかの課題は解決しそうです。 しかしまだ以下のような課題が考えられます。
- (2) の方法と同様に開発に時間を要するケースが多い
- データの送信先やフォーマットが変更されたときに都度それに応じた開発とサービスへのリリースが必要となる(周囲のシステムやデータの変化に柔軟に対応しにくい)
- 処理能力を超えた流量のアウトプット・インプットが発生したときにうまく対応できない可能性がある
- 特定のシステム(例えばデータベースなど)にデータを送信する機能を組み込むことはときに困難
以上の理由によって、これにもまだ課題があるように感じます。
データ連携をとりまく課題
以上のようなシステム間のデータ連携に起こりうる課題は次のようにまとめることができます。
- システムのダウンに強くなければならない
- 処理能力を超えたインプットがきたときにうまくこなさないといけない
- いろんなデータやフォーマットに対応しなければならない
- システムや周囲システムの仕様変更に柔軟であり簡単に対応できなければならない
- セキュリティやデータガバナンスに強くなければならない
データフローに特化したツールを用いるのが効率的
Apache NiFi は以上の課題をすべて解決しつつ、データを安全に移動するようなデータフローを設計できる1つの手段です。
「データフロー」という言葉は一般に幅広い分野で使用されていますが、ここでは NiFiのドキュメント にもあるように「自動化・管理化されたシステム間の情報の流れ」と定義します。 もう少し具体的には、データを処理したり取得したりするコンポーネント(NiFiではプロセッサーと呼ぶ)とそれらを接続する有向の接続(NiFiではコネクションと呼ぶ)のグラフ構造で表すことができます。
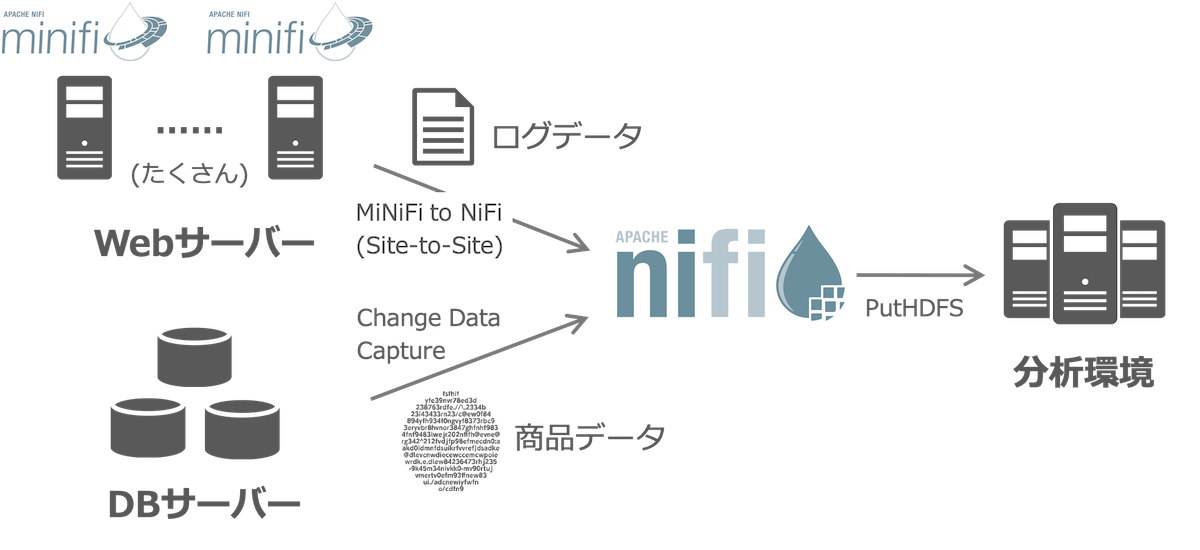
記事の冒頭で挙げたデータ移動のシナリオをNiFiで実現するには、次のようなアプローチでデータ移動を実現できます:
- データフロー実行用途にNiFiクラスタを立てる
- WebアプリケーションサーバーにNiFiを軽量化して組み込み用途に開発されている MiNiFi を導入し、発生するログデータをリアルタイムにNiFiクラスタへ送信する
- NiFiクラスタでは、MiNiFiから送信されるログデータを受信しつつ、並行してデータベースをChange Data CaptureしてDBの中身を追従する
- NiFiクラスタでは、取得したデータをORCなどのHDFSに書き込めるフォーマットに変換して、HDFSに書き込む
- NiFiクラスタでのデータフローの構築は、NiFiのWeb UIからコーディングレスかつスピーディーに構築・設定できる
より詳細な設計は今回の記事では省略しますが、以下のCloudera Communityで、サーバーのログをMiNiFiを用いてNiFiに送りNiFiでそれを集めてHDFSに保存するサンプルが掲載されています。
このようにアプローチすることで「データ連携をとりまく課題」を解決して、次のような利点を得ることができます。
- システム障害に強いデータフローを構築できる
- 送信されるログデータが急増してもNiFiで吸収できる
- データのフォーマットやデータ連携の送信先が仕様変更となっても柔軟に対応できる
- データの通信は暗号化され、指定されたユーザーのみがデータの閲覧やデータフローの編集が可能となる
具体的にどのような機能・特徴でこのように課題を解決できるかを次のセクションで説明します。
Apache NiFiとは
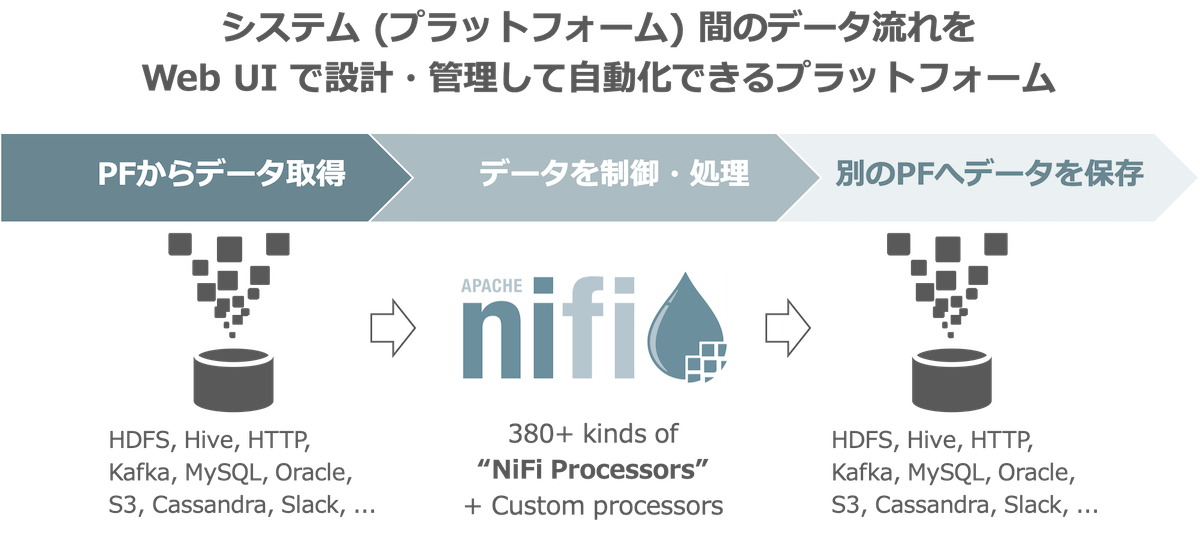
以上のようにデータフロー設計のツールとしてNiFiを利用する例をあげました。 Apache NiFiとはひとことでいうと「システム(プラットフォーム)間のデータの流れをWeb UIで設計・管理して自動化できるプラットフォーム」です。 NiFiは現在Apache Software FoundationのトッププロジェクトのOSSとして公開されています。
この例のパターンだけではなく、さまざまなより複雑なデータフローも設計できます。 データの流れのコントロールだけではなく、NiFiクラスタ上でデータの変換も処理でき、いろいろな用途で便利に使うことができます。 データフローを設計するのはシステムの一部なので基本的にはシステムエンジニア向けのツールですが、基本的にコーディングは不要です。
NiFiの特徴
もう少し細かく説明すると、NiFiは以下のような機能や特徴をもっています。 これらの機能や特徴が「データ連携をとりまく課題」で挙げた課題を解決します。
フロー管理に優れている
- 永続的 (persistent) なログ先行書き込み (write-ahead log) を利用することで、データの到達性を保証する(解決する課題: 1)
- NiFi内のデータのコネクション(キュー)にはサイズを設定できるのに加え、バックプレッシャー機構があり、入力でやってくるデータの流量がそれを処理するコンポーネントのデータ処理速度を超えてしまったときに、フローの上流に逆伝搬してコンポーネントの動作を抑制させる仕組みが備わっている(解決する課題: 2)
- フローのQoS(例えばレイテンシを優先させるのかスループットを優先させるのかなど)やコネクションへのデータの優先度設定などを細かくコントロールできる(解決する課題: 4)
ユーザーフレンドリーな使いやすさ
- NiFiの380以上の種類のプロセッサーが多様なデータプラットフォームとの接続を自分でコードを書くこと無しに可能とする(解決する課題: 3)
- データフローはビジュアルで設計でき、ほぼすべての機能がWeb UI内の操作で完結する(解決する課題: 4)
- Data provenanceというデータの流れた履歴をGUIから見ることができる(解決する課題: 4)
セキュリティ
- 各周辺システムとNiFi間の通信: SSLでセキュア化可能(解決する課題: 5)
- ユーザーとNiFiとの通信: SSL認証可能、ログインユーザーにアクセスレベルを設定可能(解決する課題: 5)
- 各コンポーネントに対してログインユーザーごとにアクセス制御が可能、すなわちマルチテナント構成が可能(解決する課題: 5)
拡張性
- 標準では存在しない独自機能をもつカスタムコンポーネントを開発するための開発環境が整っているので、ユーザーが比較的簡単にカスタムコンポーネントを作成できる(解決する課題: 3, 4)
スケーリング
- NiFi自体でクラスタを構築してパフォーマンスをスケールアウトしたり、スケールアップ・ダウンも容易に操作でき、可用性が向上する(解決する課題: 1)
技術的な詳細は Apache NiFi Documentation によくまとまっているので気になる方はぜひご参照ください。
直近のニュースとしては、約1カ月前(2019年11月4日)に最新バージョンの 1.10.0がリリース されました。 この最新のバージョンの紹介については別途 Hadoopソースコードリーディング で発表の機会をいただき紹介しました。 そのときの登壇資料を参考までにシェアしますので興味のある方がぜひご覧ください。
社内での活用方法を紹介
さて、私の所属しているチームでは、Apache NiFiをベースプロダクトとして使用した社内向けデータフロープラットフォームを社内に as a service として提供しています。
前提
前提として、Yahoo! JAPANでは100以上のサービスを開発・運用していて、それらを支えるさまざまなデータプラットフォームをオンプレミスで運用しているという背景があります。 いくつかを取り上げて紹介します。
Hadoop
データ処理基盤として大規模Hadoopを3クラスタ運用しています。 Hadoopクラスタが分析用の各種データの保存やデータ処理の中心として働いています。
関連記事・スライド:
- 大規模Hadoop運用に大切なこと / YJTC19 in Shibuya B-2 #yjtc (先日2019年12月13日に開催されたヤフーの技術カンファレンス「Yahoo! JAPAN Tech Conference 2019 in Shibuya」で発表)
- ヤフーにおけるHadoop Operations #tdtech
- Apache Hadoop Contributors Meetup出張報告(前編)
- Apache Hadoop Contributors Meetup出張報告(後編)
- Hadoopのバージョン混用は可能? HDP 2.6.4 とコミュニティ版 Hadoop 3.2.1 におけるHDFSの互換性調査結果
分散オブジェクトストレージ
Amazon S3互換のWeb APIを実装した分散オブジェクトストレージシステムを開発しています。 主にサービスの画像・動画データや各種データを格納する幅広い用途で用いられています。
関連記事:
Pulsar
社内のサービス・コンポーネント間のメッセージキューを汎用的に使えるように、Yahoo Inc. (現 Oath) とYahoo! JAPANで開発しOSSとなったPub-SubメッセージングシステムPulsarを使用しています。
関連記事・スライド:
- ヤフー発のメッセージキュー「Pulsar」のご紹介
- ハイパフォーマンスでスケーラブルなメッセージングシステム:Pulsarの紹介
- Message Queueを社内プラットフォームとして提供してみた 〜 Apache Pulsar活用事例 〜
データベース
MySQLやOracleといったリレーショナルデータベースや、Apache Cassandraのような分散データベースを運用しています。
関連記事・スライド:
NiFiの活用
Yahoo! JAPANはこれらの多種多様なデータプラットフォームを抱えているため、それらのシステム間でデータをやりとりするためのデータフロー設計も複雑となりがちです。 NiFiはこれを簡単にしてくれます。
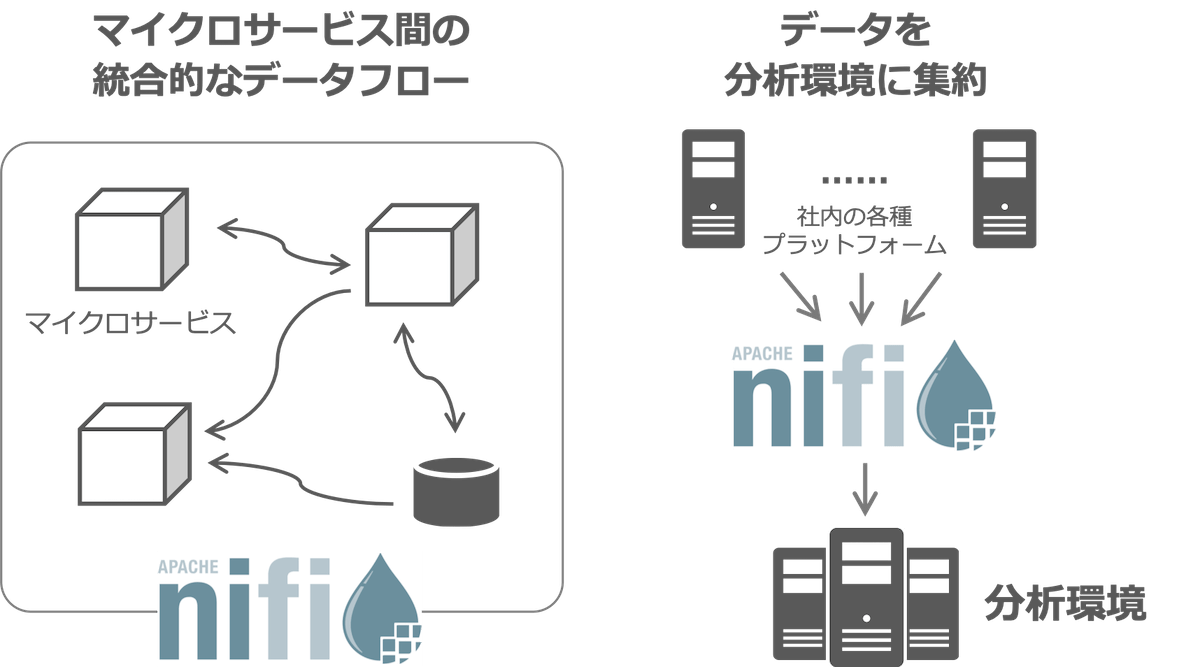
NiFiの活用方法は、主に以下の2つの用途に分類できます。
- マイクロサービス間のデータフロー設計・実行
- サービスの稼働環境・分析環境をまたぐデータフロー設計・実行
それぞれを説明します。
マイクロサービス間のデータフロー設計・実行
もともとNiFiが開発された用途に素直に従った活用方法に近いと思います。 サービスがもつマイクロサービス化された各コンポーネントのAPIやデータをNiFiで取得・連携し合うことで、システムの統合的なデータフローをNiFiで設計・実行できます。 また、サービスがもつ各種ストレージに保存されているデータを取得、集約、加工して、再びサービスで活用できるように戻すというフローも考えられます。
以前ヤフーでNiFiを紹介したときの以下のスライドで詳細を説明しています。
サービスの稼働環境・分析環境をまたぐデータフロー設計・実行
サービスのログデータや各種ストレージに保存されているデータを取得、集約して分析環境に連携する用途でもNiFiを活用できます。 これは本記事の冒頭で説明した例に近い用途です。 このようなプラットフォーム間を横断的にデータ連携させるためにもNiFiを活用できます。
いずれにしても、NiFiという統合的なデータフローの設計・実行環境を提供することで、Web UIによるスピーディーなデータ連携の設計が可能となりました。
NiFiの利用規模
ヤフーでは2019年12月時点で20弱のサービスでNiFiを導入しています。 この中にはWebでサービスを提供しているプロダクトはもちろんのこと、社内向けサービスや、データ分析システム、コーポレート系の部署も含んでいて、多種多様な場所でNiFiが使用されています。 パフォーマンスを担保するために、各サービスごとに専用のNiFiクラスタを払い出す形で提供しています。 クラスタを構成するノード数はサービスごとに求めるパフォーマンスによって異なっていますが、最大のノード数で構成されるクラスタは30ノードあります。
運用上の工夫を紹介
NiFiをベースとしたプラットフォームをヤフー社内で運用するにあたり工夫している点をいくつか紹介します。
独自パッチを当てた社内ディストリビューションを作成
OSS版NiFiに対して独自パッチを当てた社内ディストリビューションをビルドし、それを用いています。 独自パッチの内容としては以下のようなものがあります:
- Hadoop、Pulsar、Dragonは上で述べたようにオンプレミスで独自環境を提供しているためその対応が必要
- 社内のプラットフォームに接続するために既存で用意されていない新規プロセッサー (NiFiのコンポーネント) を新規開発
NiFi Registry の活用
開発環境と本番環境の2種類のNiFi環境を提供しています。 そのため、開発環境のNiFiで設計したフローをスムーズに本番環境のNiFiにデプロイできるように、NiFi Registryを経由したリリースフローを推奨しています。 その中では、Yahoo! Inc. (現 Oath) が開発してOSSとなった Screwdriver.cd を利用して本番環境にシームレスにデプロイできるようにしています。
汎用テンプレートの配布
NiFiを利用するにあたり、よく利用されるようなフローをテンプレートとして標準で配布しています。 例をあげると、NiFiでの処理結果などを通知するために、社内で開発している MYM や Slack へ通知できるようなテンプレートを作成して配布しています。
Prometheusの併用活用
Prometheusを使用してサーバー監視をしています。 その上、最新の1.10.0からはNiFi上の各コンポーネントも詳細に監視できるようになったため、これらのメトリクスを詳細にユーザーに提示することが可能となりました。
以上のような工夫を施していますが、まだまだ改善の余地はあるのでアップデートを続けています。
NiFiのプロダクトとしての課題
さまざまな場面で便利に活用できるNiFiですが、プロダクトとしての課題やデメリットもまだ存在しているのでここで現在把握している範囲で説明します。
NiFiのパッケージサイズ
NiFiではあらゆるプラットフォームと接続するために、標準で多様なプロセッサーが導入されています。 現に最新のNiFi 1.10.0では380を超える種類のプロセッサーが導入済みです。 そのため依存しているライブラリが非常の多く、NiFiをビルドしたパッケージサイズはバージョンを増すごとに拡大中です。 NiFi 1.10.0 のバイナリtarballのサイズは1.2 GBのサイズになっています。
これに対してはサブプロジェクトの NiFi Registry を利用することで解決が見込まれています。 当初はデータフローをバージョン管理する用途で開発されたNiFi Registryに、加えてnar (NiFi内で用いられるクラスローダーに特化したwar/jarアーカイブのこと) を管理できる仕組みの開発が進められていて、それを活用することで解決できる見込みです。
スケールの限界
NiFiはクラスタリングすることでスケールアウトできると特徴で述べましたが、パフォーマンスはマシンのスペックにも依存しますが、どこかで限界を迎えそうであることがすでにMeetupなどでも共有されていて、自分たちもそのように体感しています。 そもそもメインはデータフローの制御に目的をおいたシステムなので、そのようなデータ処理をスケールアウトする用途は重要視されていないという見方もできると思います。
これの解決策としては、負荷の高いデータ処理はNiFi上で実行せずにApache FlinkやApache Stormなどにオフロードして実行することがが考えられます。 例えば、Event-Driven Messaging and Actions using Apache Flink and Apache NiFi では、イベントのデータ処理に対して高スループットが求められる部分にFlink、データのエンリッチメント部分にNiFi、とそれぞれの長所を組み合わせて利用している事例が発表されています。 その他にも、NiFi 1.10.0から導入されたStateless NiFiを用いてNiFiフローをYARNやKubernetesクラスタ上で動作させることもできるようになったため、このようなデータ処理のオフロードの方策も考えられると思います。
参考記事・スライド:
- Exploring Apache NiFi 1.10: Parameters and Stateless Engine - Cloudera Community
- Introduction to Apache NiFi 1.10
- Apache NiFi 1.10.0 でなにができるようになったのか? #hadoopreading
データフローのコード化
データフローのコード化には向いていません。 これはNiFiはコードを書いてそれをジョブとして動かすという使い方ではなく、データフローをGUIで直接設計するためにそもそもコードとして落ちないからです。 データフローをXMLファイルとしてエクスポートできますが、人間が見てもわかりにくいです。 これにより、データフローを変更したときに差分のレビューがやりにくいという弊害が生じます。 なお、NiFi Registryを用いると簡易的に差分を確認できますが、まだレビュー向けではないです。
UI/UX
NiFiの根幹であるUI/UXもまだ改善の余地があると個人的には思っています。 例えば、Undo/Redoがまだできないなどです。 (これはNiFi公式ツイッターの 今年のエイプリルフールのネタ になっています。)
アップデートとコントリビュート
開発の方針として、NiFiに対して社内で改善した修正のうち、OSSに貢献できる内容のものは積極的に OSS版NiFi に貢献しています。 これにより、ヤフーで見つけて直したバグ修正や機能改善はOSSに貢献してコミュニティに還元できますし、また他社での修正や改善はNiFiのバージョンアップデートで社内に取り込むことができます。 これはOSSの良い活動サイクルだと考えています。
現時点 (2019年12月) まででApache NiFi (github) とNiFiのサブプロジェクトである NiFi Registry (github)、 その他関連するプロジェクトにはYahoo! JAPANから合計23件のバグ報告や修正・改善コントリビューションを実施しています。 この活動は継続していき、よりプロダクトの完成度を上げていけるように取り組みたいと思っています。
おわりに
ヤフーのシステム間のデータ連携の一部にはApache NiFiが取り入れられていて、スピーディーなデータフロー設計が可能となっています。
Apache NiFiはなにかといろんな用途で使えて便利なツールです。 Javaの実行環境さえあればMacやノートPCなどにも気軽にインストールできるので、まだ触ったことのない方はぜひ試してみてください。
- Apache NiFi, Apache Hadoop, Apache Pulsar, Apache Cassandra, Apache Flink, Apache Stormは、The Apache Software Foundationの米国およびその他の国における登録商標または商標です。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



