はじめての○○特集2本目の記事です。
ヤフーのサイエンス部門に所属する山本康生です。主に広告やYahoo!ショッピングに対して機械学習の施策によるサービス改善を担当しています。今日は「機械学習をサービスに導入するノウハウ」というテーマで、機械学習をサービスに組み込みたいという動機から、それを実現するまでの背景をヤフー社内の事例を交えてご紹介します。
ヤフーでの深層学習を含む機械学習の適用範囲は多岐にわたり、中核事業である広告への適用[1][2]に始まり、Yahoo!ニュース[3]、Yahoo!ショッピング、ヤフオク![4]、GYAO!、その他多くのサービスに組み込まれています。
機械学習を適用したい「タスク」を決めましょう
皆さんの身の回りで深層学習を使いたいという意見が出たとします。では、深層学習を使って何を達成したいのでしょうか?
広告の入札価格を自動で決めたいのか、ECサイトでユーザーの好みに合わせた商品を推薦したいのか、自動音声対話システムを作りたいのか、または数時間後の気象状況からある場所の天候を予測したいのか。これらの目的を達成するために、深層学習を使うというのは間違った選択ではありません。ただ、現在の機械学習は私たち人間の思考をそのまま実現してくれる万能の技術ではありません。
例として、天候の予測を考えてみましょう。それは降雨量を予測するものでしょうか? 雨が降る・降らないを予測するものでしょうか? もしくは、雨が降った地域の天候と水害の危険性の関連度を予測するものでしょうか? これらを機械学習で扱うには、それらの予測作業を「タスク」と呼ばれる単位に定義する必要があります。降雨量のような実数で表すものは「回帰問題タスク」、雨が降る・降らないのように有無を表すものは「二値分類問題タスク」、そして水害の危険性の関連度を段階的に表すものは「多クラス分類問題タスク」と定義します。
このようなタスクを同時に扱うマルチタスク学習[5]という手法も近年研究が進んでいますが、その用途はまだ限定的です。また、マルチタスク学習が適用できる状況であっても、個々にどのようなタスクを行いたいのかは個別に定義する必要があります。

「ラベル付きデータ」があることを確認しましょう
取組んでいるビジネスや社会問題などの解決策として機械学習のタスクが定義できたとして、そこにラベル付きデータは存在するでしょうか? ラベル付きデータとは、機械学習が学習に使う正解データを意味します。降雨量を予想したいのであれば、過去に観測された降雨量の値です。
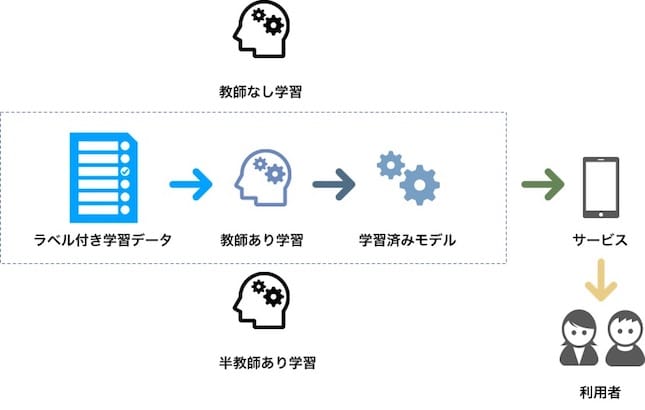
ここで正解データ、いわゆる教師あり学習を前提に話を進めることに違和感を感じる方がいるかもしれません。機械学習においては、教師あり学習・半教師あり学習・教師なし学習の3つの学習方法を学びます。しかし、サービスに適用する場合は教師あり学習におおむね限定します。
では、なぜ教師あり学習に限定するのでしょうか。それは、実際にサービスを利用するユーザーやそれに関わる利害関係者が存在する環境(ヤフーではこれをプロダクション環境と呼びます)では、一定の予測精度を担保する必要があるからです。半教師あり学習や教師なし学習の精度を否定するわけではありませんが、現時点での教師あり学習の精度と比べた場合、それらをしのぐ域には届きません。もちろん、学習済みモデルのFine-tuningにより少ないラベル付きデータで高い性能を引き出す手法もあります[6]。しかし、学習済みモデル種類やFine-tuningの適用範囲はまだ限定的です。このことから、ラベル付きデータがあること・教師あり学習が適用できること、を確認します。
今はラベル付きデータがなくても、なんらかの工夫や事業戦略で獲得することは可能です。しかし、それは非常にコストがかかる工程です。ヤフーでは、このような状況にならならないためにもデータに関する戦略が常に進められています[7]。そして、機械学習を適用する段階でラベル付きデータが十分にあることを目指しています。
データの「前処理」と「モデリング」を行いましょう
ラベル付きデータが準備できたら、そのデータを機械学習アルゴリズムが扱えるよう前処理を行います。そして、前処理済みのデータをアルゴリズムに適用するモデリングを行って学習済みモデルを生成します。
データの前処理やモデリングについては、数多くの出版物があり、アルゴリズムの詳細までを知ることができます。それらの方法に従ってデータの前処理やモデリングを行いましょう。ヤフー社内のデータの前処理やモデリングについても同様の手続きを行っています。
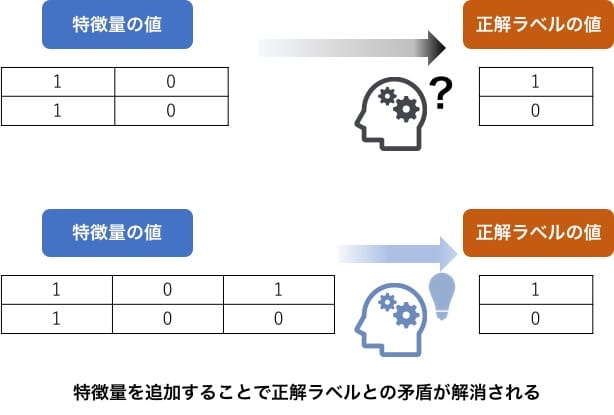
しかし、この手続きでも注意する点があります。データの前処理は、特殊な構造データ(自然言語・音声・画像・関係グラフ・位置情報やセンサーデータなど)の変換手法に時間を費やすのではなく、データから得られるインサイト(知見)を特徴量に組み込むことに注力することを推奨します。その理由は、特殊な構造データの変換方法は多くが確立されつつあることや、End-to-end学習[8]のようにデータの変換方法まで取込んだ学習アルゴリズムが登場しているからです。加えて、データから得られるインサイトによる特徴量は機械学習モデルの学習時の矛盾の解消を助け、精度改善に貢献します。
「学習済みモデルをサービスに適用」しましょう
モデリング作業時のオフライン検証で十分な予測精度が得られたら「学習済みモデルをサービスに適用」しましょう。ここでサービスに適用するというフレーズをあえて強調しました。なぜかというと、学習済みモデルはそれ自体が単独で存在するのではないことを認識してもらいたいからです。
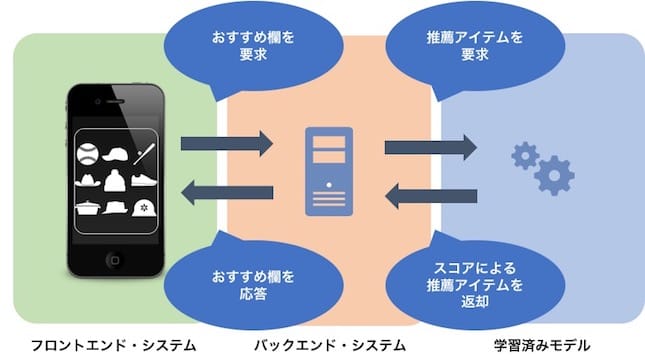
例えば、Yahoo!ショッピングのオススメ商品欄であれば、その画面を表示するタイミングでフロントエンド・システムがバックエンド・システムに表示アイテムを要求し、バックエンド・システムは学習済みモデルの予測値やスコアに従ってアイテムのリストを返します。機械学習では予測することを推論と呼びますが、この推論部分をどうサービス内に組み込むかというのは、サービスが定めた応答速度やモデルを配置するメモリ空間やディスク・スペースの制約を満たす必要があります。これは、非常に重要な項目です。ヤフーのような大量のトラフィックを処理するシステムでは特に推論部分の設計に十分注意を払います。
「効果測定」を行いましょう
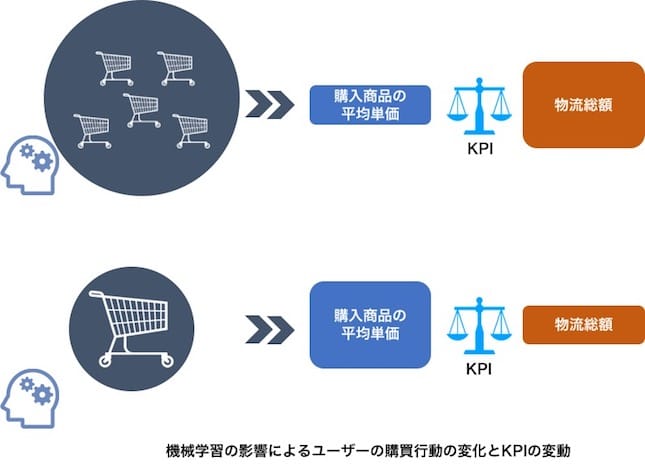
学習済みモデルがサービスに組み込まれたら効果測定を行いましょう。オフライン評価で得られたモデルの予測精度が非常に良いものであっても、それがサービスに良いインパクトを与えることを保証するものではありません。サービスごとに決められた効果測定基準、いわゆるKPI"Key Performance Indicator"[9]に基づいて効果測定を行いましょう。例えば、ECサイトが満たすべきKPIが「物流総額」「購入商品の平均単価」で、機械学習のモデルはユーザーの購買行動を予測するものであったとします。この状況下で、手頃な商品を頻繁に購入するユーザーが大半であった場合「物流総額」は上がり・「購入商品の平均単価」は下がります。逆に、高額な商品を低頻度で購入するユーザーが大半であった場合「物流総額」は下がり・「購入商品の平均単価」は上がります。このような傾向は、どちらが正しくてどちらが間違っているというものではなく、学習済みモデルをサービスに組み込んだ効果測定の結果として検討を行いましょう。サービスの利害関係者などが検討した結果、KPIのバランスを調整したいという要望があれば、新たなモデルを生成して適用するという場合もあります。
機械学習パイプラインやサービスを「安定稼働」させましょう
学習済みモデルを生成する機械学習パイプラインや、その学習済みモデルを組み込んだサービスは、言わずもがな情報システムです。ということは、常に要求仕様や外部インターフェース仕様の変更、定期的なアップデート、性能劣化の検知、障害発生時の緊急処置などに対応しながら管理維持しなければなりません。
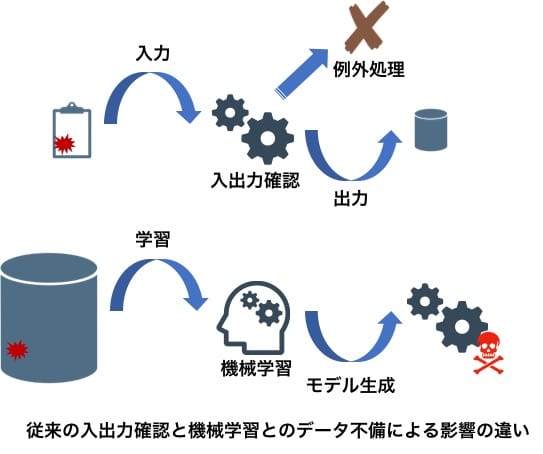
しかし、機械学習パイプラインや学習済みモデルを組み込んだサービスは変化に脆弱であると指摘されています[10]。例えば、機械学習を組み込んでいないサービスであれば、逐次入出力に対して厳密な検証が行われ予期せぬ問題発生時は例外処理がなされます。しかし、機械学習は大規模データを一括して処理する仕組みなので、データの不備がないことを仮定する傾向があります。その結果、データに問題が混入する危険性が高く、その問題が発生した場合はモデリングが失敗したり非常に誤った予測値を算出する可能性が生まれます。このような課題に対し"Rules of Machine Learning:Best Practices for ML Engineering"[11]の提唱のようにプロダクション環境で機械学習を安定して維持する施策を推奨します。ヤフー社内でも学習済みモデルの予測精度のモニタリングなどは積極的に行われています。
まとめ
機械学習を使う動機をタスクとして定義することから始まり、最後はサービスにモデルを組み込んでシステムを安定稼働させるまでをご紹介しました。ここまでお話した流れは、私が担当するYahoo!ショッピングでも同様です。例えば、ビジネス側の要望として「ユーザーが商品を目にした際、詳細情報を確認したくなるような施策をして欲しい」という要望があれば、私たちサイエンス部門はユーザーの商品に対するCTR"Click Through Rate"予測モデルを考案してサービスに組み込んでその要望にこたえます。
皆さんの普段の関心がアルゴリズムやモデリングまでであったり、サービスに学習済みモデルを組み込んでみたいが具体的に何に気をつけなければよいか分からない、というものでしたら本記事は何らかの気付きがあったのではないでしょうか。もしそうであれば幸いです。
参考
[1]: コンテキスト広告におけるクリックログを用いた効率的な広告引き当て手法, https://randd.yahoo.co.jp/jp/papers/244
[2]: Distributed Representations of Web Browsing Sequences for Ad Targeting
https://randd.yahoo.co.jp/jp/papers/125
[3]:Embedding-based News Recommendation for Millions of Users
https://randd.yahoo.co.jp/jp/papers/233
[4]:ヤフオク!、偽物出品対策を強化 従来の機械学習に加えて、スパコン・ディープラーニングを活用開始
https://about.yahoo.co.jp/pr/release/2018/11/30a/
[5]: A Survey on Multi-Task Learning
https://arxiv.org/pdf/1707.08114.pdf
[6]: Residual Squeeze VGG16
https://arxiv.org/pdf/1705.03004.pdf
[7]: データフォレスト構想
https://dataforest.yahoo.co.jp
[8]: Limits of End-to-End Learning, ACML 2017, https://arxiv.org/abs/1704.08305
[9]: KPI, https://ja.wikipedia.org/wiki/重要業績評価指標
[10]: Hidden Technical Debt in Machine Learning Systems, NIPS 2015
https://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf
[11]: "Rules of Machine Learning:Best Practices for ML Engineering"
http://martin.zinkevich.org/rules_of_ml/rules_of_ml.pdf
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



