こんにちは、R&D統括本部の吉田です。
前回と前々回の記事では、Hadoopのカスタマイズポイントを解説しました。
単純な問題に対しては、map関数とreduce関数の組み合わせだけでも、処理を行うことができますが、ある程度複雑な問題に対しては、今までに解説したカスタマイズポイントの活用が重要になるという話でした。
今回は実際のサービスの事例を紹介し、カスタマイズポイントがどう活用されているか紹介したいと思います。
ABYSS
ABYSSの事例を紹介しましょう。
ABYSSとは、検索サービスを簡単に構築できる社内プラットフォームのことで、詳しくは以下のTechBlog記事で紹介しています。先日無事に社内リリースされました。
新検索プラットフォーム「ABYSS」
これがABYSSのすべてだ!!
ABYSSでは、各種検索データのストレージにHadoopを使い、様々な処理を行っています。 Hadoopで行われているMapReduce処理の一つに「検索差分データのマージ処理」があります。今回は、この処理について解説したいと思います。
「検索差分データ」とは、例えばWEBページの検索インデックスに対して、後からこのURLのデータを更新したい、とか、このURLを削除したい、といった差分を記述したデータのことです。
例えば、以下のような形式になっています。
insert http://yahotter.yahoo.co.jp/ Yahotter! <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"...
remove http://cu.yahoo.co.jp/
1行目は、「http://latlonglab.yahoo.co.jp/」の内容の更新し、2行目は追加、3行目は削除する差分データです。
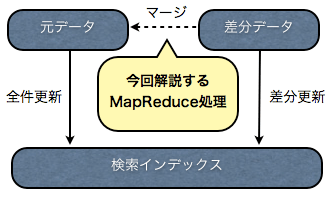
差分データは、検索インデックスに対して後からデータを追加したり削除したりします。 しかし、検索インデックスを新規に作成する場合などは、検索対象となる元データをまず作成し、そこから検索インデックスを生成します。
検索対象となる元データを作成し、新規に検索インデックスを生成する方法と、差分データを用意して、後から検索インデックスを更新する2通りの方法があるわけです。 それぞれ、全件更新、差分更新と呼んでいます。
差分更新は、検索インデックスに対して直接反映されるため、元データに対しては変更が反映されません。ABYSSでは、元データを後から解析処理などに使えるように、元データに対しても差分データをマージしています。そして、その部分が今回解説するMapReduce処理です。
「検索の元データ」とは、例えば以下のようなデータです。
https://developer.yahoo.co.jp/ Yahoo!デベロッパーネットワーク <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"...
また、元データがどういう形式で記述され、どのように検索ができるのかという情報は、スキーマファイルに記述されています。
<?xml version="1.0" encoding="UTF-8" ?>
<Schema>
<IndexFields>
<Field name="Url" type="URL" />
<Field name="Title" type="MA" />
<Field name="Body" type="MA" />
</IndexFields>
<IncIndex uniqueKey="Url" />
</Schema>元データは、Url、Title、Bodyの順に並んでいて、ユニークキーがUrlである、という情報を記述しています。
差分データをマージする処理は、一見単純な処理に思われるかもしれません。しかし、ABYSSでは、次のような制約があります。
- 検索インデックスは複数あり、数千規模まで増える可能性がある
- 検索インデックスごとに、別々のスキーマファイルがあり、元データの形式が異なる
- 検索インデックスごとにマージ処理の入力も出力先も異なる
多くの別々の検索サービスを統合するのがABYSSの役割なので、検索インデックスは複数あり、数千規模まで増える可能性があります。 検索インデックス1つに対して1回のMapReduceを行うと、数千回MapReduceを行う可能性があり、非常に効率が悪いです。 つまり、複数の検索インデックスの元データに対するマージ処理を、1回のMapReduceで行う必要があります。 しかし、検索インデックスごとにデータの形式が異なり、マージ処理の入力も出力先も異なります。
こういったある程度複雑な問題に対しては、単にmap関数、reduce関数だけでなく、以前の記事で紹介したカスタマイズポイントを上手く利用する必要があります。
処理の概要
まずは、処理の概要を説明します。
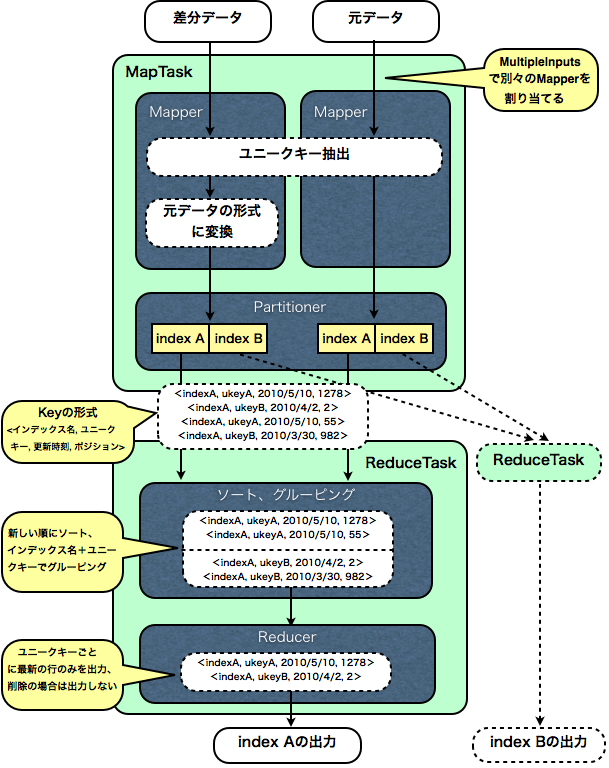
上図のように、差分データと、元データをMapReduceの入力ファイルとして読み込みます。 MultipleInputsを使い、差分データと、元データには別々のMapperを割り当てます。
Mapperでは、スキーマファイルの情報に基づきユニークキーを抽出します。 差分データのMapperでは、それに加え、差分データを元データの形式に整形します。
そして、Mapperの出力Key/Valueを以下のように、いくつかの要素の複合形式にします。
Key: <インデックス名, ユニークキー, ファイルの更新時刻, ポジション>
Value: <処理の内容, 元データの行>
ポジションとは、InputSplit内で、その行がどの位置にあるかという数値です。 処理の内容とは、差分データの場合、その行を挿入するか(insert)、更新するか(update)、削除するか(insert)、元データの場合は無条件にallとします。
次にPartitionerを使い、同じインデックスのデータは、必ず同じReduceTaskで処理されるようにします。また、GroupingComparatorを使い、インデックス名+ユニークキーでグルーピングします。 さらに、Comparatorを使い、ファイルの更新時刻の逆順、更新時刻が同じだった場合はポジションの逆順でソートします。
結果として、Reducerには、同じインデックスで同じユニークキーのデータがグルーピングされて、新しい順に入力されます。
Reducerでは、最新の行のみを出力します。 ただし、最新の行の処理の内容がremoveだった場合には、出力しません。
差分データと元データの中で、同じユニークキーの最新の行を出力するというわけです。 もちろん、最新の行がremoveだった場合はそのユニークキーは削除し、出力しません。 結果として、元データに差分データがマージされるわけです。
また、Reducerと同じ処理をMapTask内のCombinerでも行い、転送量を削減しています。
MapReduceの出力は、MultipleTextOutputFormatを使い、各インデックスごと別々のフォルダ、ファイルに出力します。
では、処理の詳細を説明していきます。
処理の詳細
はじめに、解説するカスタムクラスのまとめを簡単に書きますので、わかりにくくなったら参照して下さい。
| MDPathFilter | 元データと差分データの両方ともそろっている入力ファイルのみ許可 |
|---|---|
| MDTextInputFormat | 小さいファイルをまとめて一つのInputSplitで扱えるように |
| MDLineRecordReader | ファイルの更新時刻とインデックス名をJobConfにセット |
| MDMapRunner | スキーマファイルから情報を抽出 |
| MDDiffMapper | 差分データのMapper |
| MDAllMapper | 元データのMapper |
| MDKeyWritable | Mapの出力Key。新しい順にソート |
| MDValueWritable | Mapの出力Value |
| MDHashPartitioner | インデックスのハッシュ値で分割 |
| MDGroupingComparator | インデックス名+ユニークキーでグルーピング |
| MDReducer | 最新の行のみを出力。削除の場合は出力しない |
| MDMultipleTextOutputFormat | インデックスごとにファイルに出力 |
PathFilter
PathFilterは、MapReduceの入力ファイルの中で、こういったパターンは除外したい、このパターンは許可したいといったフィルタリングを行い、 実際に処理するファイルを決定する仕組みです。
元データと差分データの両方ともそろっているインデックスのファイルに対してのみ、処理を行うためにPathFilterを活用しています。
元データだけしかなく、差分データが存在しないインデックスに対しても、マージ処理を行うことができてしまうので(元データがそのまま出力される)、 PathFilterでそうしたファイルのフィルタリングを行い、リソースを有効活用しています。
MultipleInputs
MultipleInputsは、ファイルごとに別々にMapperと、InputFormatを割り当てる仕組みです。
詳細は省きますが、InputSplit自体に、MapperとInputFormatの情報を含めてしまうことで実現しています。
以下のように、差分データには、MDDiffMapper、元データにはMDAllMapperを割り当てています。
// allInは元データの入力パス
MultipleInputs.addInputPath(conf, allIn, MDTextInputFormat.class, MDAllMapper.class);
// diffInは差分データの入力パス
MultipleInputs.addInputPath(conf, diffIn, MDTextInputFormat.class, MDDiffMapper.class);InputFormat
InputFormatは、CombineFileInputFormatを継承したクラスを使用しています。
通常は、少なくともファイル1つに1個のInputSplitが生成されるため、小さいファイルがたくさんあると、MapTaskが膨大な数になってしまい非効率です。 CombineFileInputFormatを使えば、小さなファイルをまとめて1つのInputSplitを生成することができます。
public class MDTextInputFormat extends CombineFileInputFormat<MDInputKeyWritable, Text> implements JobConfigurable {
public RecordReader<MDInputKeyWritable, Text> getRecordReader(InputSplit genericSplit, JobConf job, Reporter reporter) throws IOException {
return new CombineFileRecordReader(job, (CombineFileSplit) genericSplit, reporter, MDLineRecordReader.class);
}
}getRecordReader関数では、CombineFileRecordReaderを返します。
CombineFileRecordReaderは、ファイルをまとめたInputSplit(CombineFileSplit)を扱うことができ、
ファイルごとにオリジナルのRecordReader(MDLineRecordReader)がインスタンス化され、呼び出されます。
RecordReader
Mapperでは、ファイルの更新時刻と、インデックス名をファイルのパスから取得する必要があります。 しかし、CombineFileInputFormatでいくつかのファイルがまとめてMapperに渡される可能性があるため、 Mapperの初期化処理だけでそれらの情報を取得することはできません。
CombineFileRecordReaderでは、InputSplitに含まれるファイルごとに、オリジナルのRecordReaderがインスタンス化され、初期化処理が呼ばれるようになっています。
そこで、オリジナルのRecordReaderをカスタマイズし、RecordReaderの初期化処理で、ファイルの更新時刻とインデックス名をJobConfにセットし、 Mapperから読み出せるようにしています。
JobConfに文字列などをセットする方法や、RecordReaderとは何かについては、前の記事を参照して下さい。
MapRunner
Mapperでは、ユニークキーがどこにあるかという情報や、差分データを元データの形式に変換するための情報を、スキーマファイルから読み出す必要があります。 スキーマファイルは、インデックス一つに対して、1回読み出せば十分です。
そこで、カスタマイズしたMapRunnerで、RecordReaderで読み出したインデックス名が変わるたびに、スキーマファイルから情報を呼び出し、 Mapperのインスタンス変数にセットしています。
MapRunnerについては前回の記事を参照して下さい。
Mapper
Mapperは、差分データを処理するためのMDDiffMapperクラスと、元データを処理するためのMDAllMapperクラスに分けられます。
MDDiffMapper、MDAllMapper共に、MapRunnerでスキーマファイルから読み出した情報を元に、ユニークキーを抽出します。 MDDiffMapperでは、さらに、差分データを元データの形式に変換します。
Mapperの出力Key/Valueは以下の通りです。
Key: <インデックス名, ユニークキー, ファイルの更新時刻, ポジション>
Value: <処理の内容, 元データの行>
KeyとValueはそれぞれ、MDKeyWritable、MDValueWritableという独自のWritableクラスを使用しています。
Writableクラスのカスタマイズ方法は前回の記事を参照して下さい。
Partitioner
インデックス名のハッシュ値で、Partitionに分割し、ReduceTaskに割り当てます。 つまり、同じインデックスのファイルは同じReduceTaskで処理されるというわけです。
同じインデックスの同じユニークキーのデータをまとめてReducerで処理できるだけでなく、 同じインデックスのデータは同じReduceTaskで処理されるので、MapReduceの結果のマージされたファイルは、一つにまとまって出力されるという効果があります。
public class MDHashPartitioner implements Partitioner<MDKeyWritable, MDValueWritable> {
public int getPartition(MDKeyWritable key, MDValueWritable value, int numReduceTasks) {
//インデックス名(key.index)のハッシュ値で分散
return (key.index.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}Partitionerについては、前回の記事を参照して下さい。
ソート
Comparatorをカスタマイズし、ファイルの更新時刻の逆順、更新時刻が同じだった場合はポジションの逆順でソートするようにしています。 これで、新しい順にデータがReducerに渡されることになります。
Comparatorは、MDKeyWritableのデフォルトのComparatorとしてMDKeyWritableのインナークラスで定義されていて、 バイト列でそのまま比較する最適化を行っています。
Comparatorについては、前回の記事を参照して下さい。
グルーピング
Comparatorをカスタマイズし、同じインデックス名かつ同じユニークキーをグルーピングして、Reducerに渡すようにしています。 MapReduceの実行の前処理で、独自のComparatorクラスをGroupingComparatorとして登録します。
job.setOutputValueGroupingComparator(MDGroupingComparator.class);ソートの時と同様にバイト列でそのまま比較する最適化を行っています。
Reducer (Combiner)
Reducerには、同じインデックスで同じユニークキーのデータがグルーピングされて、新しい順に入力されます。
概要で述べた通り、Reducerでは、最新の行のみを出力します。 ただし、最新の行の処理の内容がremoveだった場合には、出力しません。
差分データと元データの中で、同じユニークキーの最新の行を出力することで、元データに差分データがマージされるわけです。
出力のKey/Valueは以下の通りです。
Key: <インデックス名, 出力する行>
Value: null
Keyに実際に出力する行に加えて、インデックス名を指定し、後のOutputFormatでの出力先を決定します。
CombinerもReducerと同じ処理を行い、転送量を削減しています。 Combinerについては、前回の記事を参照して下さい。
OutputFormat
OutputFormatには、MultipleTextOutputFormatを継承したクラスを使用することで、インデックスごとに別々のファイルに出力します。
public class MDMultipleTextOutputFormat extends MultipleTextOutputFormat<TextPair, NullWritable> {
protected TextPair generateActualKey(TextPair key, NullWritable value) {
// 実際にファイルに出力するKeyを決定する
Text actualKey = key.second;
return new TextPair(actualKey, null);
}
protected String generateFileNameForKeyValue(TextPair key, NullWritable value, String name) {
// ReducerのOutputKeyから、インデックス名を抽出し、ファイルの出力先を決定する
String prop = key.first.toString();
return "tmp/" + prop;
}
}generateFileNameForKeyValue関数で、Reducerの出力Keyから、インデックス名を抽出し、どのファイルに書き出すかを決定します。 そして、generateActualKey関数で、実際にファイルに書き出すKeyを決定します。
まとめ
こうして、差分データが元データにマージされて、インデックスごとにファイルが出力されました。
サービスの仕組みに密接した内容のため、わかりにくい部分があったかもしれませんが、 カスタマイズポイントが活用されている雰囲気を感じていただければ幸いです。
なお、実際には、もう少し複雑になっていて、説明のために単純化して書いた部分があります。 例えば、詳細は省きますが、差分データに単純な追加/更新/削除以外の処理があり、それに対応するためにファイルをキャッシュする仕組みを導入したりしています。
また、ABYSSでは、HDFSのファイルをRESTで操作できるようにするなど、Hadoop自体のカスタマイズも行っています。
おわりに
3回に渡り、Hadoopのカスタマイズポイントを解説し、それらが実際の業務でどう活用されているかを紹介しました。
最近では、PigやHive、HadoopStreamingなど、Hadoopでの分散処理を記述する労力を減らす方法がたくさんあります。 map関数とreduce関数の組み合わせでできるような処理は、Javaで記述するより、それらの手段を活用した方が効率的です。
しかし、map関数とreduce関数の組み合わせだけではできないような複雑な処理、 また定常的に実行されるような処理でHadoopの能力を最大限に引き出すためには、 Hadoopの内部の仕組みを理解し、解説したようなカスタマイズポイントをいじる必要が出てきます。
より詳しく知りたい場合は、オライリーから出ている象本を読んでみることをおすすめします。
P.S.
以前、GoogleがMapReduceの特許を取得したことをお伝えしましたが、
Hadoopに特許の利用を許可したそうです。よかったです。
(R&D統括本部 吉田一星)
追記Hadoopを使いこなす(1)
Hadoopを使いこなす(2)
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



