
システム統括本部アーキテクト室 今野です。
先日、GoogleからBorg[1]なる論文が公開されました。Borgの関係者がKubernetes[2]の開発に携わっている経緯もあり、一般的にはコンテナ技術や仮想化を含めたPaaS(Platform as a Service)環境的な視点での注目が高い論文でしょう。
今回は、この論文を若干別の視点として、大規模分散システムの処理モデル的な観点から考察してみたいと思います。端的に言えば、Borgも含めた最近のクラウド環境の分散システムには重要なパラダイムシフト的な潮流があります。
大規模分散システムの処理モデル的な観点で、最初に近年のクラウド環境の分散システム動向を整理しつつ、最後にBorgから直近の分散システムの潮流を考察してみます。
分散アプリケーション処理モデルの動向
クラウド環境で実行される大規模な分散システムアプリケーションの処理モデルを大別すると、「オフライン処理」であるか「リアルタイム処理」であるかのいずれかとなります。
近年はリアルタイム処理志向の高まりを背景に、クラウド各社のアプリケーション処理モデルがオフライン処理からリアルタイム処理への移行する注目すべき動向があります。以下に、近年クラウド各社でリアルタイム処理への移行や導入が発表された、代表的なオフライン処理アプリケーション事例を示します。
| アプリケーション | 企業名 | オフライン処理システム名 | リアルタイム処理システム名 | 発表 |
|---|---|---|---|---|
| 検索インデックス更新 | MapReduce[3] | Caffein[11] | 2009年 | |
| 大規模データ分析 | MapReduce[3] | Storm[27] | 2012年 | |
| 大規模データ分析 | Hive[12](MapReduce[3]) | Presto[32] | 2013年 |
かつては検索エンジンのインデックス更新や大規模データの分析などはオフライン処理であるバッチ処理で定期的に実行されていました[3][12][27]。しかし、近年は利用者への即時性や更新遅延時間の向上を主な目的として、これらのシステムはリアルタイム処理に刷新されている動向があります[11][13][27][32]。
上記事例の通りMapReduce[3]は、オフラインの大規模データ処理における代表的なモデルです。まずは、このMapReduce近辺から近年の分散システムの動向を整理してみます。
MapReduceモデルの整理
MapReduce[3]は、2004年にGoogleから発表されたオフライン処理の代表的なモデルです。このMapReduceの処理モデルを、プログラミングモデル、データモデル、論理演算モデルの観点で区分して整理すると以下となります。
| 区分 | 機能 | 説明 |
|---|---|---|
| プログラミングモデル | MapReduce | MapReduceフェーズの処理の組み合わせ |
| データモデル | タプル(tuple) | キーバリュー型の単純なデータ構造に限定 |
| 論理演算モデル | 論理和型(disjunction) | Shuffleフェーズに相当 |
詳細については後述しますが、MapReduceの処理モデルは、上記の通り各区分ごとにそれぞれ単純化(限定)されたモデルであったと言えます。
また、MapReduceの関数プログラミングおよびグラフ的な特徴も合わせて以下に整理してみます。
関数プログラミング的な特徴
MapおよびReduceフェーズは、それぞれ関数型プログラミングのMapおよびReduce処理をモデル化したものです。MapReduceは、参照透過性がある純粋な関数処理と言えます。参照透過性とは入力により出力が一意に決まる性質のことです。言い換えればMapReduceの処理は、大域などの処理に影響する外部の環境は持たず、内部的にも静的な一時変数などの状態も持たないことを意味します。
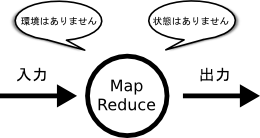
純粋な関数処理は複数の処理が同時に実行されても他の並列に動作している処理の状態には左右されないため、この参照透過性は並列化に向いている性質があります。その反面、この性質は、大域的な状態を必要とするアルゴリズムや、ジョブ異常停止時の再実行、リアルタイム処理性に向かないなどの要因ともなります[11][28][32]。
グラフ的な特徴
MapReduceは、実際にはMap,Combine,Shuffle,Reduceの4つのフェーズで構成されます[3]。ただし前処理的なフェーズを除けば、MapReduceは本質的には、入力データを変換するMapとで変換データをから結果を出力するReduceから成る2フェーズ構成になります[23]。
MapReduceをフローチャート(flowchart)の用語で説明すると、Map処理とReduce処理を一つの流れ線で結ぶ図となります。

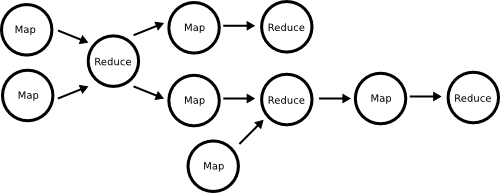
このフローチャートをグラフ的な表現で言い換えれば、各処理を点(vertex)、流れ線を有向辺(directed edge)とした2点が1つの有向辺で接続される、単純な有向非循環グラフ(DAG:Directed Acyclic Graph)となります。
MapReduceの有向非循環グラフは、各点の処理はmapまたはreduceに限定[23]され、各処理は単一の入力および出力の有向辺に限定[10]された非常に単純なものです。この単純化されたグラフは処理が限定され、処理の粒度的にも最適化しにくいなどの要因にもなります[9][10][13]。
逆に言えば、処理が汎用的な点と複数の入出力の有向辺から構成される有向非循環グラフは、MapReduceを一般化したプログラミングモデルと言えます。この一般的な有向非循環グラフは、後述するMapReduceの最適化や置換などに多用される重要な一般化です[10][12][19][27][23][28][30][32]。
MapReduceの普及と功罪
近年のMapReduceの普及は、この単純化(限定)された処理モデル故に「利用者である開発者や研究者の理解が容易であった」のが一番の要因でしょう。この単純化された処理モデルは大規模データの利用者に支持され、現在では数多くの企業のデータ処理基盤として普及するに至りました[7]。
多くのアプリケーションはMapReduceで表現可能です[22]。ただし現実のアプリケーションをMapReduceに変換するには、複数のMapReduceを用いたパイプラインやグラフを構成する必要があります[12][22][23]。この現実のアプリケーションからMapReduceへの変換は、利用者が変換する作業としては複雑なものでした[22]。
しかし、単純化されたMapReduceの処理モデルが普及した反面、近年では「利用者がアプリケーションを無理にMapReduceモデルに押し込んでしまう」「利用者が分散システム処理能力を超えたジョブを安易に投入してしまう」などの弊害が顕在化してきました[7][11]。

単純化されたMapReduceプログラミングモデルに対しては、以前から分散データベースの分野から批判もありました[8][9]。彼らの批判は、分散データベース分野の成果ではなく、なぜ新しく限定されたMapReduceの処理モデルを導入するのかという単純な疑問です[9]。
また、MapReduceの性能や実装面でも、前述のリアルタイム性への対応や実行時の最適化が難しいなどの批判や問題も同時に顕在化してきました[9][11][13][32]。
NextGen MapReduceとは
検索インデックスの更新処理は、かつてはMapReduceとして動作するGoogle社内最大のアプリケーションでした[36]。しかし、2009年頃からCaffein[11]で検索インデックス更新処理のMapReduceからの移行が公表され、ついには昨年開催されたGoogle I/O 2014では「MapReduce自体も1年前から利用していない」と公言されるまでに至ります[5]。
Facebookも、かつては社内の大規模データの分析にはMapReduceを利用していました[12]。しかし、2013年には大規模データのリアルタイム分析処理が必要になったとして、新しいシステムのPresto[32]の導入を公表しています。
また、MapReduceの主要なOSS実装であるApache Hadoop[6]も、従来のMapReduceをMR1(MapReduce Version1)として、現在ではYARN[7]をHadoop開発の中心に置いています。

このような昨今の新しいHadoopの動向を、HadoopではNextGen MapReduceや、MR2(MapReduce Version2)との用語を使っています[6]。今回の記事では、このNextGen MapReduceの用語を用いて、近年の新しい潮流を説明していきます。
NextGen MapReduce動向の整理
NextGen MapReduceの動向の主な背景としては、多様なアプリケーションへの対応と、前述のリアルタイム処理対応や最適化における問題があります。
今日までの、MapReduce関連の改善動向は、大まかにはMapReduceの枠組みの中で簡便化や高速化を目指す手法と、MapReduceを置換して新しい処理モデルを導入する手法に大別されます。
今回は、これらのMapReduceの改善動向を、前述のMapReduce処理モデルの区分に用いた、プログラミングモデル、データモデル、論理演算モデルの各軸に分解して整理してみます。
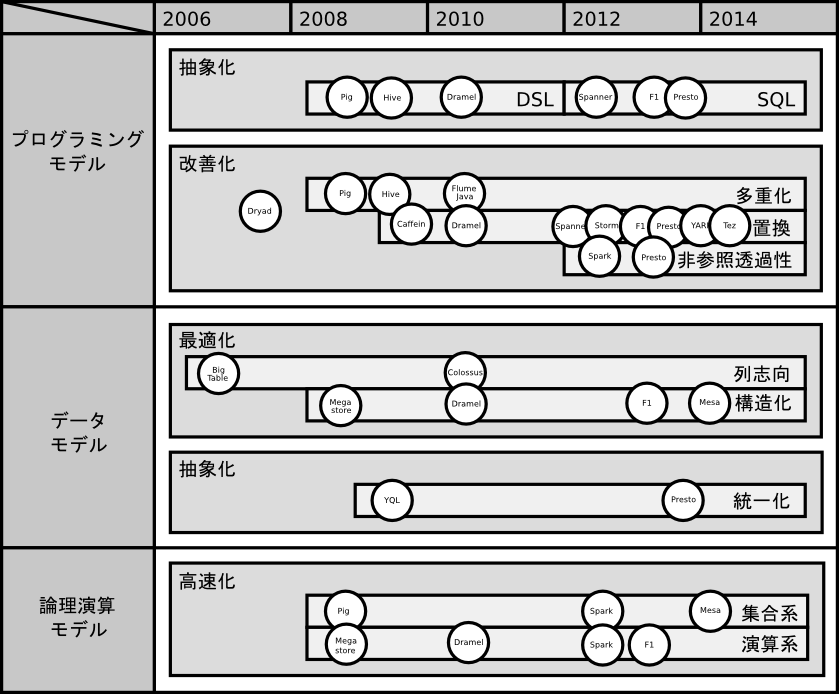
なお年代に関しては、主に論文で公表時のものを記載しています。論文で公表される内容については、各社で発表前の数年実稼働してきたシステムに関連したものが一般的に多い点に留意して下さい。特にGoogle関連の論文に関しては稼働してから4〜5年後に論文が発表される傾向がありますので、この記事の年代について差し引いて読んで下さい。
プログラミングモデルの拡張
MapReduceのプログラミングモデルの拡張については、利用者視点からはDSL(Domain Specific Language)による抽象化、特に近年は標準的なSQLを採用する傾向が主流となりつつあります。
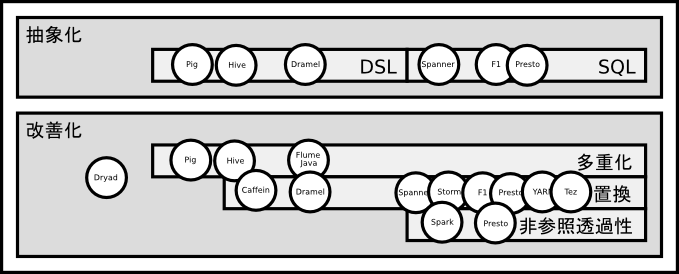
MapReduce改善動向は、MapReduceを基本とする多重化などの手法や、特に近年はMapReduceを刷新して置換する手法に大別されます。双方とも内部的な実行処理フローとしての有向非循環グラフ(DAG:Directed Acyclic Graph)を基本とした最適化も主流な特徴です。
また、関数プログラミング的な動向としては、近年はメモリ上に中間データを保持するなどの方法で、非参照透過型の高速化の傾向も見受けられます。
MapReduceの多重化および抽象化(2008〜)
2008年頃から、利用者に直接MapReduceでプログラミングするのではなく、DSLなどの上位層のプログラミングモデルの抽象化が始まります。
2008年のPig[23]では、プログラム開発経験者向けの操作言語としてデータベースのSQLとMapReduce処理との中間的な専用のDSLが提供されてます。Pigは、MapReduceのOSS実装であるHadoop[6]上に構築され、DSLによる記述は実行時にMapReduceに展開されます。プログラム開発経験者向けの性格もあり、DSLはMapReduceに対してある程度直接的な記述となります。
2009年のHive[12]では、操作言語としてSQLライクなHiveQLが提供されています。HiveもHadoop上に構築され、HiveQLによる操作は、Hiveコンパイラにより複数のMapReduce処理に展開されます。HiveQLはパース後に論理演算ツリーに変換され、最終的には物理的な処理モデルである複数のMapReduceから構成される有向非循環グラフとして展開されます。
2010年のFlumeJava[22]も、利用者に直接MapReduceでのプログラミングを強いるのではなく、抽象的なJavaフレームワークを提供します。FlumeJavaでのプログラミングは、内部的に有向グラフ(directed graph)であるデータフロー(data flow)に変換され実行されます。
MapReduceの置換および抽象化(2009〜)
最初のMapReduceを置換する動向として、Googleが2009年に刷新した検索エンジンCaffein[11]への移行があります。従来の検索インデックスの更新は、数100段レベルの連続したMapReduceのバッチ処理として構成されていましたが、Caffeinにより逐次更新可能なシステムに刷新されました。
刷新前は、この検索インデックス更新処理がGoogle社内における最大のMapReduceアプリケーションでした。ただし、Caffeinにより検索インデックス更新は基本的にはMapReduceを利用しなくなったものの、他のGoogleサービスではMapReduceは利用は継続していました[36]。
ツリー構造
2010年のDremel[13]では、操作言語としてSQLライクなDSLが提供されています。DSLによる抽象化の利点は、MapReduceのような直接的な操作ではないと同時に複雑な論理演算が表現でき、実装上も並列化の利点があります[13]。
Dramelでは、DSL操作は論理的なツリー構造に変換され、データベース分野で典型的な最適手法が取り入れられています。また、ツリー構造そのものはグラフ的には連結であり閉路を含まない無向グラフを指しますが、処理手順を考慮すれば有向非循環グラフとなります[10]。
また、このDremelの発表時点では(真偽は別としても)「DremelはMapReduceを補完するもので移行は想定していない」との前置きがあるのは興味深いところです[13]。
2012年のSpanner[14]からは、DSLとしてSQLが操作言語として採用されています。SQLの全面的な採用要因は、一般的なトランザクションに対応する目的と、前述のDremel[13]のGoogle社内での人気を受けての選択でした。なおこの当時のSQLにはGoogle独自の方言があり、近年では標準SQLへ準拠する改修が継続されています[24]。
有向非循環グラフ
2013年のF1[30]は、MapReduceフレームワークにも対応したSQLベースで抽象化されたシステムです。F1では、SQL操作は有向非循環グラフのパイプラインに展開され実行されます。
ただし、一般のクライアントはF1経由で前述のSpanner[14]と通信するものの、MapReduceフレームワークからは、性能上の問題からSpannerとは直接通信する必要があるとされています[30]。この時期から、Google社内的にもMapReduceベースの処理には性能上の問題があったことが示唆されています。
2013年のPresto[32]では、リアルタイムの大規模データ分析はMapReduceベースのHive[12]から刷新されました。Prestoは標準SQLへの準拠を目指して抽象化されたシステムで、F1と同様にSQLの最適化は有向非循環グラフのパイプラインに展開され実行されます。
MapReduceの置換および汎用化(2012〜)
前述の通り、有向非循環グラフはMapReduceの多重化や置換などの内部処理の最適化に用いられてきました。近年はMapReduce最適化の目的ではなく、有向グラフを直接的なプログラミングモデルとするものや、アプリケーション型の汎用的な処理モデルのものが登場してきています。
有向グラフによる汎用化
2012年のStorm[27]は、大規模データをリアルタイム処理する目的で開発されました。グラフ的には、入力(Spout)と処理(Bolt)を点とする処理フローの有向グラフを開発者が直接指定する形式をとります。またStormは有向グラフ的には循環(cycle)の定義も許容され再帰的な処理の指定も可能な点は特徴的なところです。
2013年のApache Tez[19]も、開発者が処理フローの有向非循環グラフを直接指定する形式をとります。グラフ的には、前述のStormと異なり各点(Vertex)の種別はなく、各点に入力(DataSource)と出力(DataSink)を指定する点が特徴的です。
アプリケーションによる汎用化
2013年のYARN[7]は、直接的にはクラスタのリソースを管理するためのフレームワークです。YARNでは、MapReduceのような特定の処理モデルは規定されず、任意のアプリケーション実行のリソース管理に注力する方式を取ります。プログラミング的には、アプリケーションがYARNにリソース要求しながら処理を進めていく方式をとります。
YARNの登場を受け、最新のApache Hadoop[6]では、従来のMapReduce(MR1)はYARNベースに再実装され、YARN上で動作する単なる処理モデルの一つという位置付けとなります。
2013年に公開されたAurora[37]も、任意のアプリケーションとリソース属性を設定して実行を依頼する形式をとります。Mesos[38]上に構築され、YARNのリソース管理に関する機能も提供します。通常の依頼形式のアプリケーションの他に、Cron形式の定期的に実行にも対応している点が特徴的です。
非参照透過性などによる高速化 (2012〜)
MapReduceは、参照透過性により大域的なデータや中間データをどのように保持するか(または可能か)が問題となります。解決策の一つとしては、大域的や中間データをインメモリで保持することによる高速化の動向があります。
2012年のSpark[28]、抽象データ構造であるRDD[29]は非参照透過性により中間演算データを保持できる構造で、後述する集計演算などの高速化やストリーム処理を実現しています。
2013年のPresto[32]の場合には、参照透過性は保ちつつも、従来はファイルに出力してた中間結果のデータをメモリ上に保持することにより、タスク間のデータの引き渡しをインメモリで実行することで処理の高速化を実現しています。
データモデルの拡張
前述の通り、MapReduceの参照透過性により大域的なデータや中間データの取り扱いが対応アプリケーションや高速化の面で必要となります。解決策の一つとしては、高速な入出力が可能な分散ストレージなどの分散データストアの活用があります。
分散データストアの改善として、今まで数々のデータモデルが提案されています。このデータモデルに関して、今回は主にMapReduce以降にGoogleから提案されたものを中心に整理していますが、近年は正規化やスキーマ定義などリレーショナルデータベースへの回帰的な傾向が特徴的です。
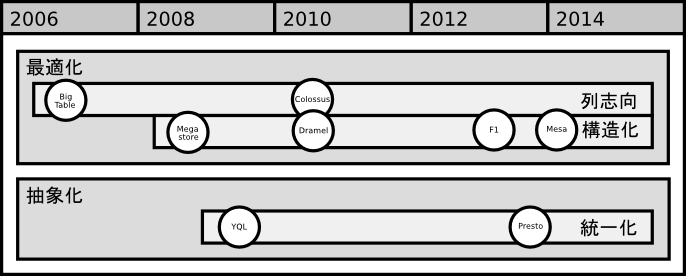
列指向(2006〜)
Bigtable[18]は、単純なキーバリューをハッシュタイプの行指向な構造として捉えれば、列指向のデータ構造であると言えます。列指向とは、1レコードのタプル(tuple)を横方向の行とした場合に、レコードの集合体であるテーブル全体をタプルの1要素で縦方向の列で操作できるデータモデルを指します。
なお、今日現在でも詳細は公表されていませんが、Google内部のファイルシステムであるGFS(Google File System)[21]の後継であるColossusは列志向のファイルシステムであるとされています[24]。
正規化構造(2008〜)
2008年頃からGoogleでMegastore[15][16]と呼ばれる正規化されたデータ構造が話題となります。Megastoreとは、リレーショナルデータベース(RDB)と行カラム型のNoSQLの中間的なデータモデルで、全てのテーブルがルートテーブルかその外部キーを持つ子テーブルのいずれかから構成されるものです[17]。
2012年のSpanner[14]では、Google内の数多くのアプリケーションがBigtableからMegastoreが移行し、標準的なデータモデルとして動作しています。
ネスト構造(2010〜)
2010年のDremel[13]では、Googleを含めたWeb系企業で多用されるデータモデルとして、階層データモデルの重要性が提起されています。
階層データモデルはネスト化されたツリー構造として表現され、保存時に階層コラムに分解(Split)、取得時に再構成(Assembly)されるなど、遅延評価的な設計も見受けられます。
階層構造 (2013〜)
2013年のF1[30]では、Megastore[16]とDremel[13]の中間的なデータモデルで、階層化された正規化データ構造が提示されています。論理的には階層化されたデータは、ルートテーブル以外の子テーブルは、その親を含む祖先テーブルの外部キーを必ず持つ構造をとります。
F1は、Spanner[14]上に構築されたシステムでもありますが、2013年の時点でSpanner自身のデータモデルは、Megastoreからこの階層構造データモデルに移行しています。
関係構造(2014〜)
2014年のMesa[31]は、データモデル的には一般的なリレーショナルデータベース(RDB)のようにスキーマ定義されたテーブル構造をもち、Megastore[17]やF1[30]にあったテーブル間の制約はありません。
データモデル以外のMesaの特徴としては、各スキーマに集計関数を定義でき、各テーブルデータは世代管理される点です。世代管理により一貫性の確保が容易になります。
抽象化(2009〜)
2009年のYQL(Yahoo Query Language)[20]は、SQLライクな指定でいろいろなサービスデータに統一的に取得できるインターフェースを提供するものです。YQLのインターフェースによりFlickrなどの既存サービスや、ユーザー独自のデータソースへ統一的なアクセスが可能となります。
2013年のPresto[32]では、Facebook社内の大規模データがHadoopの分散ファイルシステムであるHDFSだけではなく、その他の多くのデータストアに分散している背景からデータモデルが抽象化されました[33][34]。抽象化は、メタデータの取得やレコードの保存などのインターフェースにより規定されたものです[35]。
論理演算モデルの拡張
MapReduceのShuffleフェーズ処理は、論理演算的には単純な論理和(disjunction)に相当します。Shuffleフェーズのデータは、Reduceフェーズ処理で最終的な結果に変換されます。
論理演算モデルに関しては、前述のSQLによる抽象化の背景もあり、近年はリレーショナルデータベースの豊富な論理演算への対応の傾向が見受けられます。
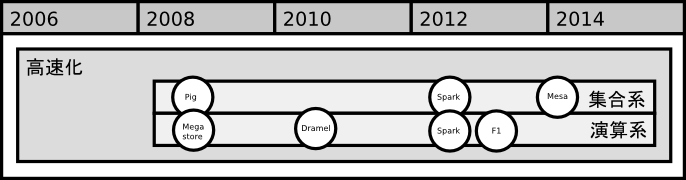
集合演算(2008〜)
2008年のPig[23]では、大規模データ分析でReduceフェーズの演算となる総数(count)や集計される合計(sum)などの集合演算用の組み込み関数が提供されています。ただし処理的には最終的には単純なMapReduceに展開される関係もあり、動作としては高速ではありませんでした。
2012年のSpark[28]も、抽象データ構造であるRDD[29]により総数や合計などの集合演算を高速に処理できるよう最適化されています。
2014年のMesa[31]は、前述したテーブルスキーマで型を定義し、スキーマ単位で集計用の関数を定義する手法で、集合演算を高速に処理できる構造になっています。
論理結合(2008〜)
Megastore[15][16]はデータ構造的に多くの論理結合である等価結合(equi-join)が発生します。2011年の時点での論理結合は、実行時にアプリケーションレベルで実装されていました[17]。
2013年のF1[30]でもデータ構造的に多くの論理結合が発生します。F1ではSQLで抽象化された要求が発行されますが、論理結合の対象がSpanner内部だけではなくBigtable[18]などの外部リソースも対象となるため、SQLは前述の有向非循環グラフベースに論理結合の最適化に力点が置かれています。
論理積(2010〜)
2010年のDremel[13]では、MapReduceの論理和型(disjunction)に加えて、論理演算モデルの拡張、特に論理積型(conjunction)を高速に処理する目的で設計されています。論理積型演算の目的は、MapReduce出力結果の分析や、リアルタイム処理における高速化です。
標準SQL論理演算への対応(2012〜)
2012年のSpark[28]は、基本的にはMapReduceのプログラミングモデルおよびデータ構造をそのままに、論理演算モデルを拡張したものです。Sparkの抽象データ構造の中心となるRDD[29]では通常の論理和型(disjunction)や論理積型(conjunction)に加えて、差分型(substract)や直積型(cartesian)などの多種多様な論理演算に対応しています。
2013年のPresto[33]は標準的なSQL(ANSI SQL)への準拠を目的として外部結合(outer-join)など幅広い論理演算への対応を目指しています。また、Dremel[13]のSQLは過去にはGoogle独自の方言がありましたが、現在では標準的なSQLへ修正する作業が継続されています[24]。
分散システム処理モデルとしてのBorg
上記のMapReduceを中心とした動向を踏まえて、最後に分散処理モデルとしてBorgを整理してみます。
分散システムの分類的には、Borgはメッセージパッシング(message passing)モデルのマスターワーカー(master worker)タイプで、YARN[7]のようなアプリケーション実行管理型の分散処理プラットフォームです。残念ながら今回の論文では、その詳細が公開されている訳ではありませんので、一部推察を交えながら考察してみます。
Borgシステム構成
Borgは利用者から見れば、ProtocolBufferをインターフェースとするRPC(Remote Procedure Call)システムとなります。Borgを構成するGoogle社内の関連システムの構成図は以下となります。
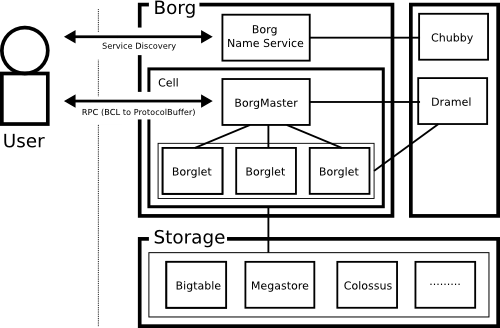
Google社内では、Borgはセル(Cell)と呼ばれる単位で目的ごとにクラスタリングされたものが複数存在します。各セルの規模は平均(中央値)は1万台のコンピューターで構成され、さらに大規模なものも存在します。
Borg利用者は、一般的には専用のコマンドラインツールやWeb画面を用いてジョブを投入します。Borgへのジョブ投入までの手順は以下となります。
- 対象ジョブが動作可能なセルをBNSに問い合わせ
- 対象セルのBorgMasterへジョブを投入
- BorgMasterがBogletへジョブを分割して投入
BNS(Borg Name Service)はChubby[41]ベースに実装され、基本的な対象となるサービス発見機能の他にも、実行しているジョブの動作状況などの監視の役割も持ちます。ジョブ実行のより詳細なリソース使用状況などはDremel[13]に保存され、障害原因やジョブのデバッグなどに活用されます。
RPC経由のアプリケーション実行は、多くのものがGCL(General Configuration Language)[39]ベースに拡張したBCL(Borg Configuration Language)で記述されています。BCLは実行時に、ProtocolBufferに変換されてBorgにジョブ投入されます。Googleでは、既に全体で数百万行のBCLの蓄積があり、数千行規模のBCLが数万程度存在しています。
Borg処理モデル
Borgは前述の通りYARN[7]と同じくアプリケーション実行を管理するものであり、MapReduceのように処理モデルを限定したものではありません。Borgも前述の処理モデルの区分に沿った形で整理すると、以下のようになります。
| 区分 | 機能 | 説明 |
|---|---|---|
| プログラミングモデル | アプリケーション型 | リアルタイムとバッチ処理の融合 |
| データモデル | - | Bigtable[18]やMegastore[15]などが利用可能 |
| 論理演算モデル | - | - |
また、論理演算モデルについては、アプリケーション型のプログラミングモデルでは範囲外となりますので、本章では割愛しています。
プログラミングモデル
BorgもYARN[7]と同じく、MapReduceはBorg上に再構築されて動作する処理モデルの一つという位置付けとなります。MapReduceの他にも、FlumeJava[22]やMillWheel[25]などの多くの既存のアプリケーションフレームワークが、Borg上で動作しているとの事ですが、ジョブ投入に関するBCLの説明はあるもののアプリケーションの再構築方法についての詳細は残念ながらありません。
ただし、MapReduceは2008年頃から当時のBorgで動作しており、YARNと同様にアプリケーションがリソース要求しながら処理を進めていく形態であったようです。現行でもYARNのようなインターフェースかもしれませんし、MPI(Message Passing Interface)のように抽象化されたプログラミングモデル層が存在するかは推察の域を出ません。
また、Borgはリアルタイム処理とバッチ処理の双方を処理するプラットフォームとして設計されています。概念的に前者はProduction(prod)と後者はNon-Production(non-prod)として区別されています。背景としては、YARNと同様に多種多様なアプリケーションを同一ホストで動作させることによる利用率の最大化があります。
データモデル
BorgはYARN[7]と同様にアプリケーション管理のフレームワークであり、基本的にはデータモデル自体定義は対象ではありません。
Borgでは前述のBigtable[18]やMegastore[15]などGoogleで社内で動作している既存ストレージは全て利用できるとされています。ただし、Borgでは前述のYQL[20]やPresto[33]のようなデータソースの抽象化に関する記載はなく、Borgの各アプリケーションが各ストレージに直接アクセスする方式のようです。
分散処理モデルの今後について
従来、MapReduceは大規模分散システムのオフライン処理モデルとして代表的なものでした。ただ、今回整理した観点から見れば、アプリケーション分野によっては既にその役割を終えたものであると言えるのではないでしょうか。
MapReduceは、その処理モデルを単純化することで理解しやすく成功したモデルであったと言えます。その反面、単純化されたモデルが故の弊害がいろいろと顕在化してきていました。モデルを単純化し弊害が顕在化したと言う面では、前回の分散システムの一貫性に関する動向[42]とも共通する事例です。
冒頭にも述べた通り、この単純化したモデルへの反動は、近年のNextGen MapReduceのようなパラダイムシフト的な潮流を生み出す要因ともなりました。
以下に、今回整理した分散処理モデルの区分ごとに、今後のNextGen MapReduceの潮流での予想される事項を整理して、記事のまとめとしたいと思います。
プログラミングモデル
プログラミングモデル的な観点では、多種多様なアプリケーションへの対応やクラスタ効率化の背景から、今後はBorg[1]やYARN[7]のような汎用的なアプリケーション管理型の分散システムが主流になると予想されます。
かつての専用的な処理モデルについては、ソフトウエア資産的な価値はもちろん、クラスタ効率面からも汎用的な分散システムへの再構築も予想されます。
データモデル
データモデル的な観点では、データ構造はアルゴリズムの基本であり、今後も各アプリケーションごとに最適なデータ構造の模索は継続するでしょう。
特にWeb企業などのクラウド環境のアプリケーションについては階層モデルが適しており[13]、正規化やスキーマ定義などのリレーショナルデータベースへの回帰的な傾向は、今後も継続するものと予想されます。
論理演算モデル
論理演算モデルの観点では、標準SQLは利用者に対する学習コストも低く、ソフトウエア資産価値の視点からも独自方言のない標準SQL準拠への取り組みは、ますます重要度が増すでしょう。
単純に標準SQLに準拠するだけではなく、多種多様なアプリケーションへの対応する目的で、Dremel[13]やPresto[33]のように幅広い標準SQL論理演算への対応も継続するものと予想されます。
最後に
最後に、分散システムの構成的な観点からは、Borg[1]やYARN[7]などは、各ノードがより等しい役割(Role)をもつ、より対称的な構成へ移行している傾向があります。
より対称型な分散システム構成へ移行する背景としては、前述のアプリケーションの多様性への対応やシステム利用効率性の問題の他に、分散システムとしての単一障害点の存在や処理性能上のボトルネックへの対応の要因があります[1][6][7]。
筆者自身、今回まで説明した分散システムの関連動向や、プログラムの複雑さへの対応などを背景として、新しい対称型の分散システムフレームワークの開発に取り組み始めています[40]。
次回は、近年の分散システムの基本フレームワークであるコンセンサスサービス(Consensus Service)[41][43]関連の動向と合わせて、新しい分散システムフレームワークのあり方などについて説明できればと思います。
参考資料
- [1] Large-scale cluster management at Google with Borg, 2015
- [2] Kubernetes
- [3] MapReduce: Simplified Data Processing on Large Clusters, 2004
- [4] Google Cloud Dataflow
- [5] Google、大規模データをリアルタイムに分析できるクラウドサービス「Google Cloud Dataflow」を発表。「1年前からMapReduceは使っていない」, Google I/O 2014
- [6] Apache Hadoop
- [7] Apache Hadoop YARN: Yet Another Resource Negotiator, 2013
- [8] MapReduceとパラレルRDBでベンチマーク対決、勝者はなんとRDB, 2009
- [9] A Comparison of Approaches to Large-Scale Data Analysis, 2009
- [10] Dryad: Distributed Data-Parallel Programs from Sequential Building Blocks, 2007
- [11] Large-scale Incremental Processing Using Distributed Transactions and Notifications, 2010
- [12] Hive - A Warehousing Solution Over a Map-Reduce Framework, 2009
- [13] Dremel: Interactive Analysis of Web-Scale Datasets, 2010
- [14] Spanner: Google’s Globally-Distributed Database, 2012
- [15] Google Megastore, 2008
- [16] Migration to a Better Datastore, 2009
- [17] Megastore: Providing Scalable, Highly Available Storage for Interactive Services, 2011
- [18] Bigtable: A Distributed Storage System for Structured Data, 2006
- [19] Apache Tez
- [20] Yahoo Query Language (YQL)
- [21] The Google File System, 2003
- [22] FlumeJava: Easy, Efficient Data-Parallel Pipelines, 2010
- [23] Pig Latin: A Not-So-Foreign Language for Data Processing, 2008
- [24] Jordan Tigani, Siddartha Naidu, Google BigQuery Analytics, Wiley, 2014
- [25] MillWheel: fault-tolerant stream processing at internet scale, 2013
- [26] Apache Storm
- [27] Storm @ Twitter, 2014
- [28] Apache Spark
- [29] Resilient Distributed Datasets: A Fault-Tolerant Abstraction for
In-Memory Cluster Computing, 2012 - [30] F1: A Distributed SQL Database That Scales
- [31] Mesa: Geo-Replicated, Near Real-Time, Scalable Data Warehousing, 2014
- [32] Presto
- [33] Facebook、分散SQLエンジン「Presto」公開。大規模データをMapReduce/Hiveの10倍効率よく処理すると
- [34] Presto: Interacting with petabytes of data at Facebook
- [35] Presto: Developer Guide - SPI Overview
- [36] Google search index splits with MapReduce, 2010
- [37] Apache Aurora
- [38] Apache Mesos
- [39] GCL Viewer: a study in improving the understanding of GCL programs, 2008
- [40] Round
- [41] Chubby Distributed Lock Service, OSDI’06, 2006
- [42] 分散システムの一貫性に関する動向について
- [43] Zab: High-performance broadcast for primary-backup systems, 2012
提供:Paylessimages/イメージマート
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



