はじめに
メリークリスマス!
マーケティングソリューションズカンパニーのリサーチアナリシス部に所属している田中です。
今日はコンバージョン予測の紹介と考察を行っていきます。
まず、コンバージョン予測を選んだ理由について説明いたします。私は、ヤフーに広告を出稿していただいている広告主の課題を解決する部署に所属しているので、広告主の課題のひとつであるコンバージョン獲得をテーマにしました。
広告主の課題をコンバージョン獲得と仮定すると、そのためにヤフーとしてはユーザーがコンバージョンをするのかどうかを理解する必要があります。
コンバージョン予測はマーケティングへの適用範囲が広く、予測確率の高いユーザーに広告を配信したりそのユーザーの動きを観測したりすることに利用されています。
具体的な取り組みとしては、コンバージョンした/しないというユーザーごとの教師データから何らかの統計的手法、例えばロジスティック回帰などで二値分類のモデルを作成し、予測するのが一般的で、予測精度が重要になります。
予測精度を上げる際に、固定のデータセットつまり固定の特徴量・Label(説明変数・目的変数)に対してさまざまな統計的手法を試したり、そのパラメータを変化させたりするケースが多いです。
しかし、私たち直面する現実の問題は非常に複雑で、かつ今日ではテクノロジーの普及によって、取得できるデータも多種多様なものになりました。今後IoT(Internet of Things)が今よりも発展していくと、さらに取得できるデータ量は膨大になっていくと予想されます。
そのような中、固定のデータセットに対して、適用する統計的手法を変えていくだけでなく、どのようなデータを取得すればいいのか、利用するデータそのものについても考えていく必要がでてきたのではないでしょうか。
この記事では、統計的手法だけでなく、利用するデータそのものを変化させた時にコンバージョン予測の精度がどれだけ向上するのか、すなわちユーザー理解がどこまで深まるのかについて考えていきます。
利用するコンバージョンデータ
コンバージョンについてはヤフーの検索連動型広告「スポンサードサーチ」のデータを利用します。ヤフーのスポンサードサーチにはコンバージョン測定の機能があります。
今回は広告主ごとのコンバージョンデータではなく、それを業種カテゴリー別(約100カテゴリー)にまとめたものを利用します。コンバージョンは「購入」、「契約」、「販促」、「ページ閲覧」などの種別があり、広告主によって異なります。今回は、コンバージョン種別が「契約」のデータのみを利用します。
コンバージョン予測モデル
コンバージョンする/しないを二値分類するモデルを作成します。
Label(目的変数)
正例:ある業種でコンバージョンしたユーザー(期間は1カ月間、正例数3,000以上のものを利用)
負例:ある業種でコンバージョンしていないユーザー(コンバージョンしていないユーザーは多いため、今回はサンプリングを行っています)特徴量(説明変数)
ユーザーごとに紐付いているユーザーの興味関心カテゴリー「インタレストカテゴリー」を利用します。インタレストカテゴリーはYahoo!プレミアム広告の行動ターゲティング広告に利用されているものです。約6,000カテゴリーがあり、ユーザーごとに最大225カテゴリーが紐付いています。今回はコンバージョンした日の前月の最終日のデータを利用しています。統計的手法
統計的手法は今回ロジスティック回帰とGBDT(Gradient Boosting Decision Tree)を利用します。(ライブラリはscikit-learnとxgboostを利用しています)
目的によって予測精度は変化していく
図1の結果は業種カテゴリーごとのコンバージョンの予測精度を表しています。(業種ごとにクロスバリデーションを行いました)予測精度はAUCという指標で計っています。AUCは0.5では予測精度は ランダム(ユーザーごとにランダムにコンバージョンするのかしないのかを予測すること)と同じ性能になり、1に近ければ近いほど予測精度が高いことを表しています。
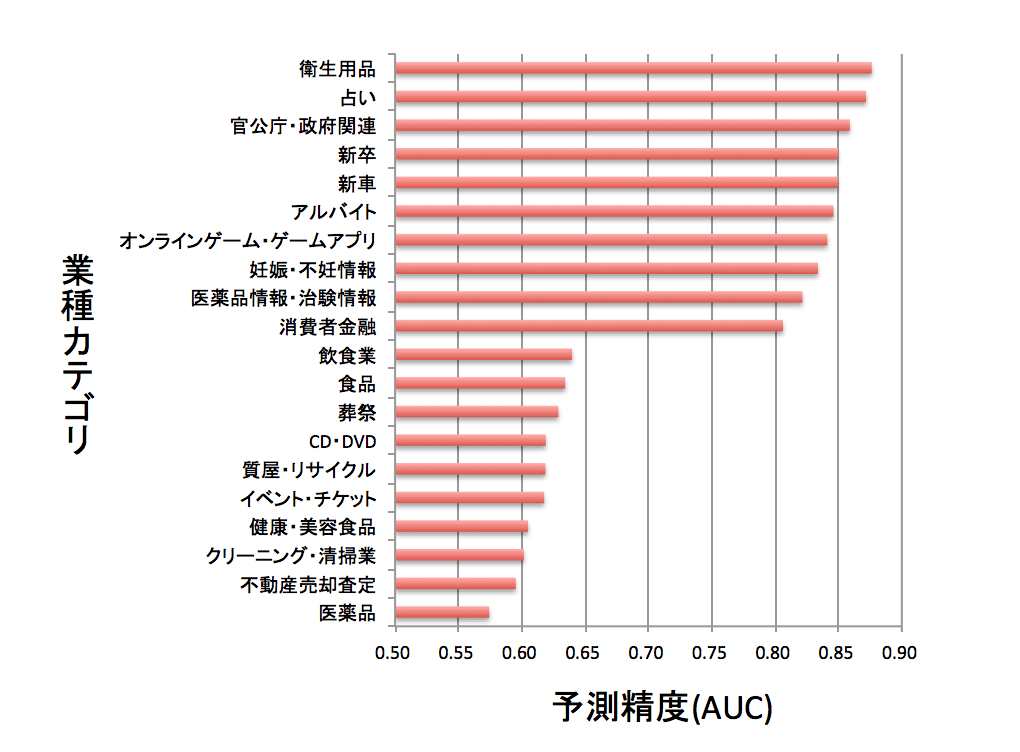
今回は、グラフの見やすさを考慮して約100種類ある業種カテゴリーの中から予測精度が高いTOP10と低いTOP10を選別しています。このように、単純にLabel(目的変数)を変えただけで、精度が大きく変化します。
翌月に新車を購入する、就職活動を開始するといったユーザーの行動はデータから手に取るように分かってしまうのです。また、医薬品、食品、葬祭などあらかじめニーズを予測することが難しい、急に必要に駆られてコンバージョンにいたるカテゴリーについては予測精度が低いのは納得できる結果だと思います。そもそも、これらのカテゴリーに対して翌月にコンバージョンするかしないかをウェブの行動データから予測すること自体が無理があるのかもしれません。
データの変化
次に、図2のように「データの変化」には2つの種類があると考えています。1つはFeature(説明変数)が増えていく、つまりレコードごとに観測できる変数が増えていく場合です。もう一つは単純にレコードが増えていく場合です。私は、この2つの組み合わせが、「データサイズが増えていく」ということだと考えています。
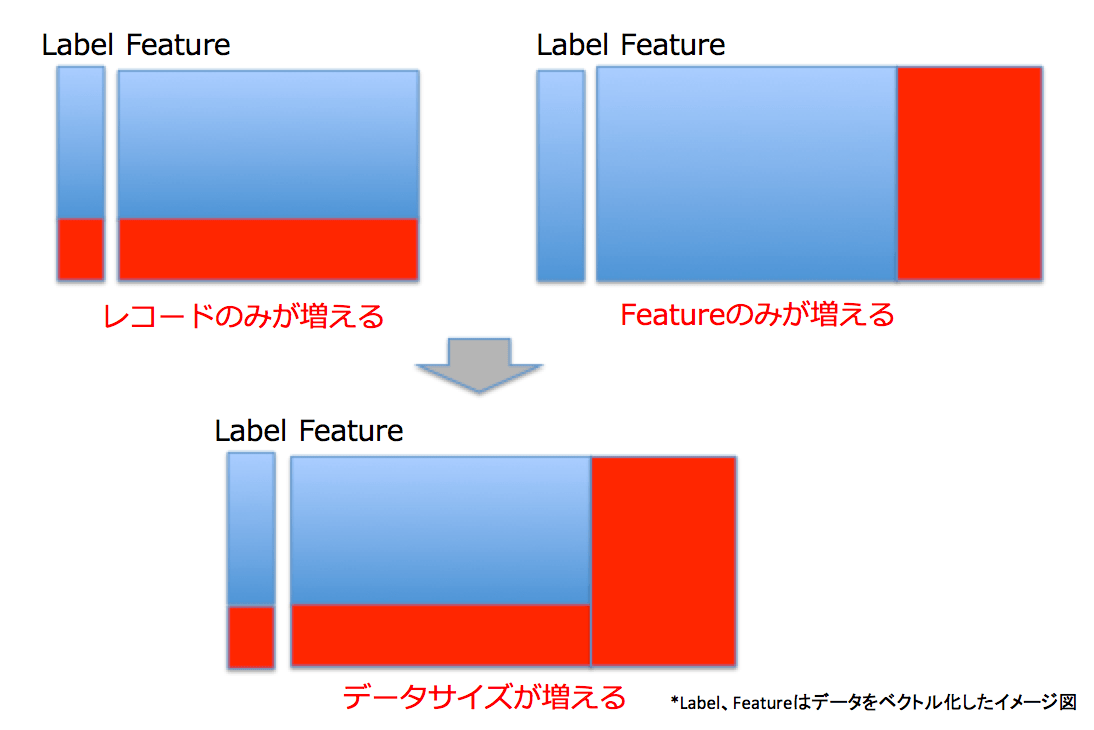
では、実際にデータの変化によって予測精度がどう変化していくか見ていきます。今回は仮に新しいデータが取得できた場合という仮想状態を作り、予測精度を見ていきます。具体的には、データのレコード数とFeature数をそれぞれ変化させて、予測精度の変化を見ます。
データの変化による予測精度の変化
表1はそれぞれの統計的手法におけるデータサイズごとの予測精度です。表の縦はデータの正例のレコード数(負例も同数にサンプリング)を、表の横はFeature数のサンプリング率を表しています。今回は新車のカテゴリーのコンバージョンデータを利用し、予測の評価データは正例、負例が1,000レコードとしています。
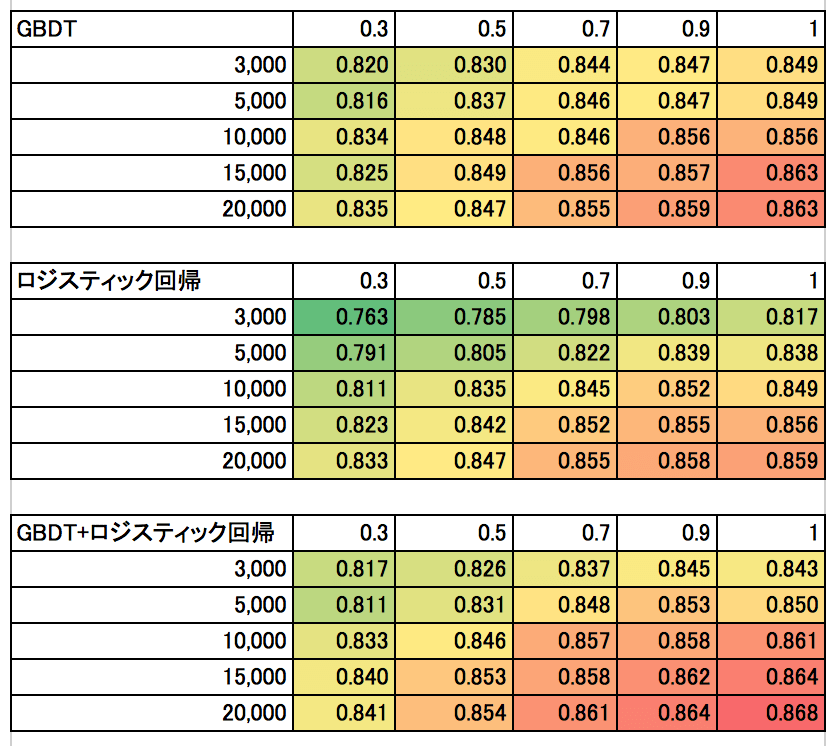
データサイズ(レコード数、Feature数)が大きくなるにつれて、予測精度が高くなっていることがわかります。ここで、ロジスティック回帰という単純な手法であっても、データサイズが大きければ、データサイズが小さなGBDTの予測精度に勝っている点に注目してください。(一般的に同条件であればGBDTの方がロジスティック回帰よりも精度が高い)このように、予測精度には統計的手法だけでなく、データサイズも大きな影響を及ぼしているのです。
以下の図3は少しわかりやすいように、上記の統計的手法ごとの予測精度を降順にしたものです。
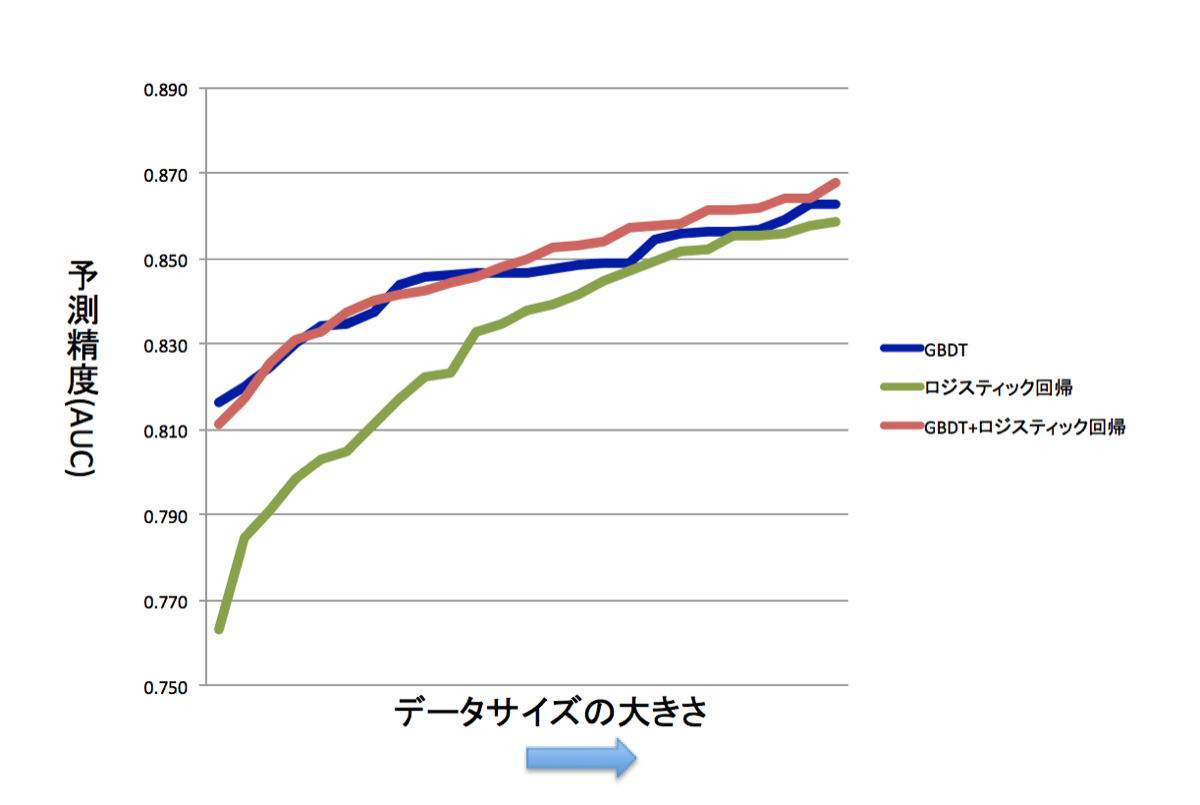
例えば、kaggleなどのコンペティションでは、この一時点を切り取って予測精度を競い合う事が多いですが、実問題では、際限なくデータサイズが大きくなっていきます。果たしてどこまで予測精度が上がるのか、私には想像がつきません。
統計手法の変化だけでなく、Feature, Label含めどのようなデータサンプルを取得すれば、予測精度を上げるのに効くのかという議論も必要だと私は考えています。この人工知能がトレンドになってきた昨今、良い教師データを与えられる人が評価される(お金をもらえる)という時代がくるのかもしれません。
一方、画像・音楽はレコード数が変化するのみでFeatureは固定されている事が多く、データサイズの変化は限定的です。画像・音楽においてディープラーニングなどのアルゴリズムが適用されているのがトレンドですが、これは、上記のような制約があるデータで優位な結果を出そうと統計的手法の研究が進化した結果ではないかと私は考えています。
おわりに
掲題として挙げているユーザー理解とは、データを利用してどこまでユーザー理解ができるのかといった意味で書きました。コンバージョン予測は一例に過ぎず(予測した期間も含め)、クリックなどさまざまな予測、セグメント推定、デモグラ推定などもユーザー理解といえます。
今回はデータサイズの大きさに着目していますが、IoTなどのテクノロジーの進化によって落ちるデータ、それを解く統計的手法があって初めてユーザー理解ができるのです。
ユーザー理解を達成するには、データだけでも、テクノロジーだけでも難しくデータとテクノロジーの両方を組み合わせることで初めて達成するものだと私は考えています。
「ユーザー理解はどこまでできるのか」という問いに対して、想像がつかないという答えとなってしまいましたが、データとテクノロジーの両方を活用して限界までいければと考えています。
以上、ここまで読んでいただきありがとうございました。
Yahoo! JAPAN Tech Advent Calendar 2017を最後まで読んでいただきありがとうございました。それではみなさん良いお年をお過ごしください。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



