データソリューション本部の名嘉 真之介です。
現在は入社二年目で、レコメンデーションシステムの開発と運用周りを担当しています。
仕事内容に関しては期ごとに変化が多かったのですが、その中でRiakの運用を1年間続けています。
その結果、少しずつ運用のノウハウがたまってきており、今回のAdventCalendarがアウトプットの良い機会と考えて参加しています。
この記事の対象者
細かい説明を省くため、ある程度のRiakの知識があることを前提にしています。
主な対象者としては、Riakの運用に興味が有る方や実際に運用に携わっている方を想定しています。
Riak Meetup Tokyo #04 (2014/06/04)
まず、本題に入る前に紹介したい資料があります。
それはともにRiakの運用を行っている仁科が発表を行った「Riak Meetup Tokyo #04」です。
このときの発表は、以下のような内容でした。
- 導入しているサービスの紹介
- システム概要
- Riakの採用した理由
- サーバ構成
- チューニング方法
- パフォーマンステストの結果
- 監視
- 運用
このように、Riakを導入しているサービスの紹介がされており、この記事を読む前に一度ご覧いただけたらと思います。
今回の内容
構成としては以下の2部構成になります。
内容に一貫性はありませんので、興味に応じて必要な項目を見ていただけると幸いです。
Riakのメンテナンスについて
最初は、Riakのメンテナンスについてです。
内容としてはサーバダウン時の運用と、Linux向けのセキュリティアップデートの対応時の運用の2つの例を紹介します。
サーバダウン時の対応
“Riak Meetup Tokyo #04”でその概要について触れられていますが、深夜に一台のサーバがハードウェア障害によりダウンしたことがありました。
ここではその際に実際に行った作業手順を紹介します。
障害概要
平日の深夜、Riakクラスタ内の1台のサーバがrebootしました。
アラート検知後に、サービスに影響が出ていないか確認を取ったところ、サービスに影響は出ていませんでした。
障害状況としては、対象のサーバがreboot後にクラスタから外れているだけでした。
レプリケーション数を3に設定しているため、早急な対応は必要無いと判断し、翌日の出社後に以下の対応を行いました。
作業手順
1. 対象のサーバの状態を再確認
同じクラスタ内の別のサーバから、対象のサーバのRiakの状態を確認して停止していることを確認します。
ringreadyコマンドは“TRUE”or“FALSE”が返ってくるので、プロセスが停止しているサーバは以下のようにFALSEが返ってきます。
$ riak-admin ringready
FALSE ['riak@xxx.xx.xx.xxx'] down. All nodes need to be up to check.またmember-statusで確認後、もし停止しているサーバが“valid”になっている場合は、downコマンドでステータスを変更します。
$ riak-admin down riak@xxx.xx.xx.xxx
Success: "riak@xxx.xx.xx.xxx" marked as down2. 対象のサーバをクラスタから外す
cluster force-removeコマンドを使用して、ダウンしているサーバをクラスタから外します。
ここではまだ、設定は反映されません。
(ダウンしていない場合などでクラスタから外す際には通常、cluster leaveコマンドを使用します)
$ riak-admin cluster force-remove riak@xxx.xx.xxx.xxx
($ riak-admin cluster leave riak@xxx.xx.xxx.xxx)3. 予備サーバのRiakの追加
予備サーバのRiakを起動させ、クラスタに追加します。
$ riak start
ok
$ riak ping
pong
$ riak-admin cluster join riak@xxx.xx.xxx.xxxcluster planコマンドで設定の反映前後の状態を確認します。
もし、想定外の変更がある場合はcluster clearコマンドで変更点をリセットします。
$ riak-admin cluster plan
($ riak-admin cluster clear)問題なければ、設定を反映させます。
cluster commitコマンドを実行すると、設定が反映されます。
member-statusコマンドで設定が反映されたか確認してみると良いです。
$ riak-admin cluster commit
Cluster changes committed
($ riak-admin member-status)4. ネットワークトラフィックの確認
追加したクラスタにデータが流れ込むため、dstatコマンドなどで通信量を確認します。
もし想定以上の場合は、予備サーバにtransfer-limitコマンドで一時的な通信量の制限を設定します。
既存の設定値を確認する場合も、transfer-limitコマンドで取得できます。
取得した値より小さい値を設定すると、ノード間の最大接続数が制限され、通信量が減ります。
ただし、小さくしすぎると転送が失敗し、再送処理が大量に走るためご注意下さい。
# 設定の確認
$ riak-admin transfer-limit
# 設定
$ riak-admin transfer-limit riak@xxx.xx.xxx.xxx <limit>
Set transfer limit for 'riak@xxx.xx.xxx.xxx' to <limit>後はしばらく様子を見て、通信量などが落ち着いたら作業完了です。
5. 異常機の筐体調査
最後に今回異常を起こしたサーバの筐体調査を行います。
サーバダウン時の対応まとめ
サーバを問題無く予備機と交換することができました。
手順を見るとわかるのですが、やったことは以下の3点です。
- サーバをクラスタから外す
- 予備サーバをクラスタに追加する
- しばらく様子を見る
Linux向けのセキュリティアップデート対応
今年は多くのLinux向けのセキュリティ脆弱性が発表された年でした。(kernel:0771 ,0924, 0981, openssl, bashなど)
多くの方が対応に追われ苦労したと思いますが、ヤフーも例外ではなくアップデート対応を行ったので、その際の作業手順を紹介します。
またその後、自動化に向けてPython 製のデプロイ・システム管理ツールであるFabricの導入を行ったところまで触れていきたいと思います。
作業手順
1. サーバへのデータのReadとWriteを停止
作業対象のサーバへのデータのReadとWriteを止めます。
2. サーバの停止
作業対象サーバのRiakを停止させます。
この作業前に、pingコマンドやステータス確認系のriak-adminコマンドで状態を確認しておくと丁寧だと思います。
$ riak stop
ok停止したかどうかはpingコマンドで調べます。
$ riak ping
Node 'riak@xxx.xx.xx.xxx' not responding to pings.また、同じクラスタ内の別サーバからringreadyコマンドで停止したかどうか調べます。
$ riak-admin ringready
FALSE ['riak@xxx.xx.xx.xxx'] down. All nodes need to be up to check.無事に停止が確認できたら、次に進みます。
3. セキュリティアップデート
ここで必要なセキュリティのアップデートを行います。
必要があれば、サーバを再起動させます。
4. Riakの起動
作業対象サーバのRiakを起動させます。
$ riak start
ok起動後に確認としてpingやtestコマンド、ステータス確認系のriak-adminコマンドなどで動作を確認すると丁寧だと思います。
$ riak ping
ok
$ riak-admin test
Successfully completed 1 read/write cycle to 'riak@xxx.xx.xx.xxx'
# 確認
($ riak-admin ring-status)
($ riak-admin member-status)
($ riak-admin transfer-limit)5. サーバへのReadとWriteの再開
サーバへのデータのReadとWriteを再開させます。
問題なくReadとWriteが行われていることが確認できたら、作業終了になります。
自動化に向けたFabricの導入
上記で紹介した手順は、数台なら業務の隙間時間で対応できるかと思います。
ただ、対応する台数が数十台におよぶ場合は、しっかり時間をとって作業をおこなわなければなりません。
Riakの性質上マスターレスであるため柔軟な対応が可能ですが、こういったプロセスの停止を含む作業はRiakのレプリケーション数に依存します。私たちのRiakの設定はレプリケーション数を3に設定していたため、サービスを停止させずに安全面を考慮した場合は1台ずつの対応しかできません。
そこで、Python 製のデプロイ・システム管理ツールであるFabricを導入して作業の自動化を行い、作業負荷の軽減を行いました。
また、作業のグルーピングを行い、他の運用作業でも汎用的に使用できるようにしました。
作業のグルーピング
Fabricは実行コマンドを好きな粒度にまとめて管理できるため、メンテナンス作業のグルーピングを行いました。
私の場合は紹介したセキュリティ脆弱性の対応は、大きく分けて以下の4つに分けました。
これらを一つのタスクとして考え、そのタスク内に必要な処理をまとめます。
- Riakプロセスの停止
- セキュリティアップデート
- Riakプロセスの起動
- Riakのステータス確認
このように作業をグルーピングすることで、作業手順を他のメンテナンスにも使いまわせる粒度にまとめました。
処理をまとめたタスクを用意することで、セキュリティ脆弱性対応の作業以外にも使用できるはずなので、幸せになれそうです。
今回はRiakについての話のため、Fabricについてはここまでにしようと思います。
Linux向けのセキュリティアップデート対応まとめ
今後も多くのLinux向けのセキュリティ脆弱性が発表されていくと思います。
あまり運用負荷の高くないRiakではありますが、Riakプロセスを再起動が必要な作業の場合だとわりと大変です。
さらに楽をするために作業の自動化のような対応を取り入れてみるのも悪くないはずです。
Read 時におけるSSL 有無のスループットの比較
最後は、httpとhttpsのRead性能の比較調査を行った結果を紹介します。
ここでいうスループットは、1秒あたりに何件Readできるか(QueriesPerSecond)になります。
調査目的
新規でRiakを使ったサービスを導入する際に、Read処理をhttpsで実装する案が出ていました。
しかしhttpsのRead処理の検証では、十分なパフォーマンス(1万qps以上)を得ることができませんでした。
そのため、SSLが通信の際にネックになっていると考え、http経由で十分なパフォーマンスが出るかを目的とした調査を行いました。
諸注意
今回の調査では、社内の閉じたネットワーク内で行っているため、外部からアクセスはできません。
検証環境
大規模なサービスで使用するために用意されていたサーバを一時的に借り、検証環境を整えました。
| 項目 | 詳細 |
|---|---|
| サーバ台数 | 36台 |
| RAM | 48GB |
| Storage | SSD 300GB * 2発 |
| RAID | RAID 0*1vol |
| filesystem | xfs |
| Backend | Bitcask |
一件当たり、平均4KBのデータをWrite/Readします。
検証方法
検証用に構築したRiakに、1万qps以上でデータを書き込みます。
その最中に、http経由でReadを行った場合とhttps経由でReadを行った場合のスループットを調べます。
その作業を3回行なって平均を取り、Readのデータとして集計しました。
結果の比較
以下がhttpとhttpsのスループットの比較になります。
縦軸がqpsになり、横軸がRead時の並列数になります。
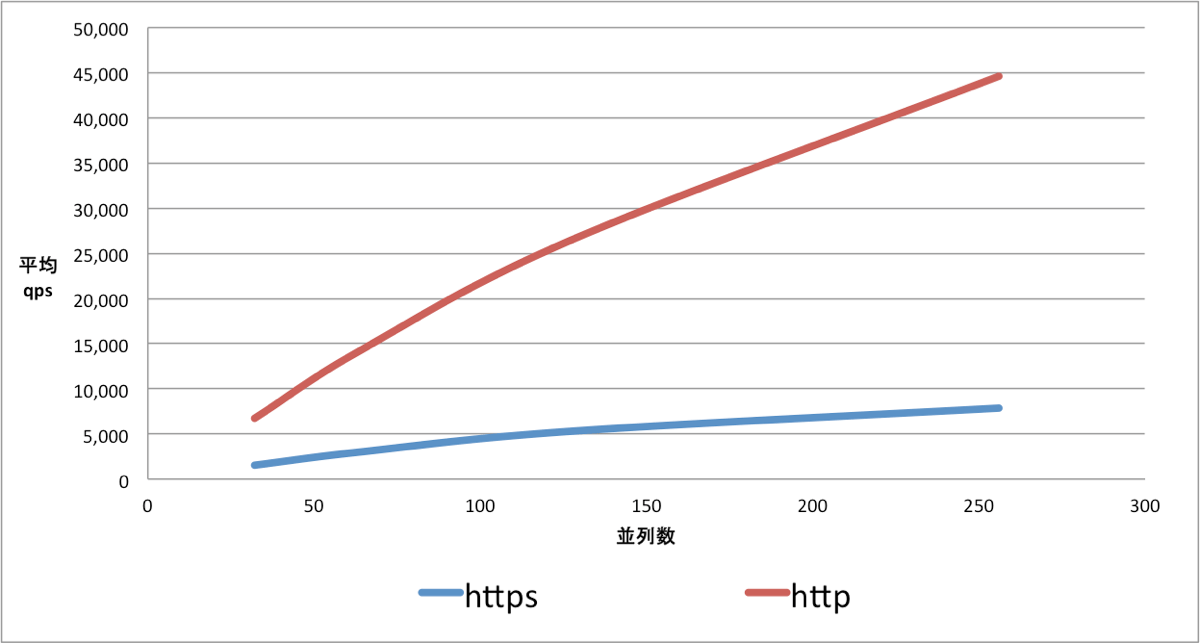
この結果から、256並列においては6倍以上の差でhttpの方がスループット性能は高いということがわかりました。
また、平均レイテンシ(ms)は以下のようになります。
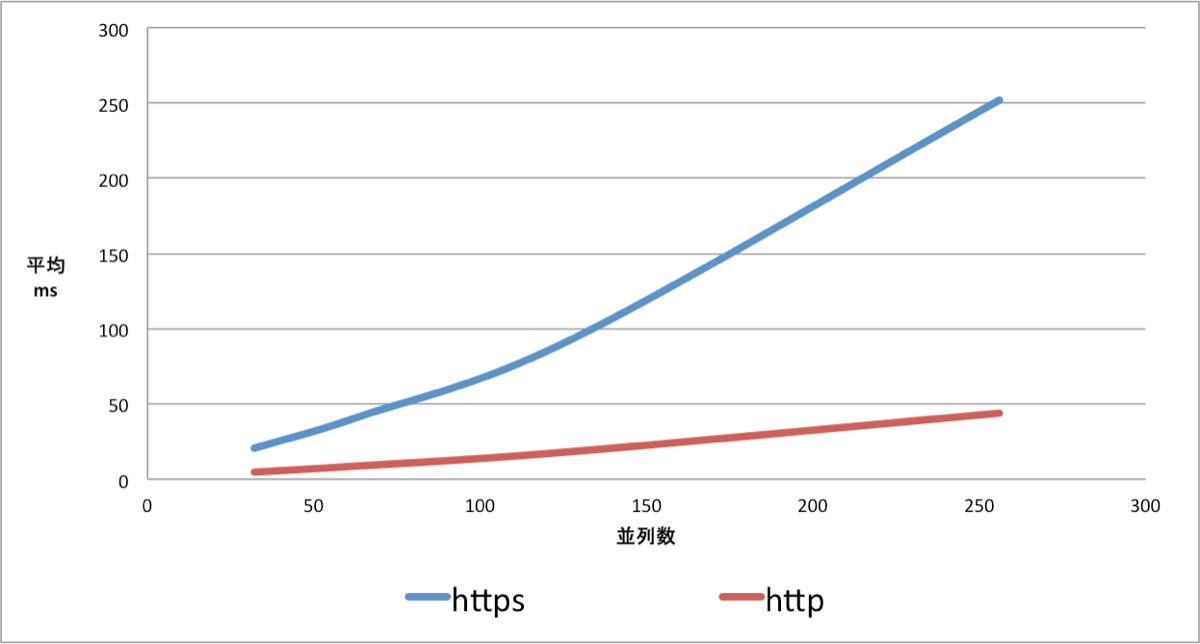
Read 時におけるSSL 有無のスループットの比較まとめ
以上の検証から、httpで十分なパフォーマンスを得ることができました。
またその結果からhttpとhttpsのRead処理の差を知ることができました。
もしRead処理において十分なパフォーマンスが出ていない場合は、この数値を参考にしていただけたらと思います。
終わりに
Riak Meetup Tokyo #4での仁科の行った発表から、約半年が経過しました。
以前もチューニング後は安定稼働していましたが、発表後も大きなトラブルはなくRiakは稼働しています。
あえていえば、多発したLinux向けのセキュリティの脆弱性へアップデート対応がネックだったと言えます。
ただ、その件に関してもFabricを導入することで運用負荷が軽減しました。
またSSL有無の比較検証についても、実際に数値として出すことでその差を把握できたことは良かったと思います。
拙い内容でしたが、Riakを運用している方やこれから運用に携わる方の少しでもお力になれたらと思います。
最後まで読んでいただき、ありがとうございます。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



