こんにちは、 前回のHadoopの記事 に引き続き、MapReduceのカスタマイズポイントを解説していきます。
前回の記事の図や、表などを参照しながら読み進めていただければと思います。
MapperやReducerの流れの制御
Mapperの実行の流れは、デフォルトでは、初期化処理を行った後、map関数を繰り返し実行し、終了処理を行うようになっていますが、この流れ自体を制御することができます。
古いAPIでは、MapRunnerを通じてこの流れを制御できますが、0.20.0からの新しいAPIでは単純にMapperクラスのrun関数をオーバーライドすることで、行えます。
デフォルトのrun関数は以下の通りです。
public void run(Context context) throws IOException, InterruptedException {
setup(context); // 初期化処理
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context); // map関数を繰り返す
}
cleanup(context); // 終了処理
}初期化処理を行い、map関数を繰り返し実行し、終了処理する流れがそのまま書かれています。
例えば、WEBページのクロールなど、一回のmap関数の実行に時間がかかる処理の場合、map関数をさらに複数スレッドで実行した方が効率的です。
そうした場合に、このrun関数を活用できます。
なお、Reducerの流れの制御も同様にrun関数を上書きすることで行えますが、新しいAPIでしか行えず、古いAPIではMapRunnerに相当するものがありません。
Partitioner
Partitionerはmap関数の出力を、Partitionに分割し、それぞれをReduceTaskに割り当てます。
デフォルトのPartitionerはHashPartitionerで、Keyのハッシュ値にもとづいて分割します。
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
public void configure(JobConf job) {}
public int getPartition(K2 key, V2 value,
int numReduceTasks) {
return (key.hashCode() & Integer .MAX_VALUE) % numReduceTasks; // Keyのハッシュ値をReduceTaskの数で割った余り
}
}getPartition関数は、Keyのハッシュ値をReduceTaskの数で割った余りを返し、Partitionを決定します。
つまり、同じKeyは必ず同じReduceTaskで処理されることになります。
Partitionerをカスタマイズする例をあげてみます。
map関数の出力Keyが、ファイル名だったとして、同じ拡張子のファイルは、同じReduceTaskで処理したいとしましょう。
(エラー処理などは省略します)
public int getPartition(Text key, Text value,
int numReduceTasks) {
String extension = key.toString().replaceAll("^.*?\\." ,""); // ファイル名から拡張子を抽出
return ((new Text(extension)).hashCode() & Integer .MAX_VALUE) % numReduceTasks;
}このようにKeyのファイル名から拡張子を抽出し、拡張子のハッシュ値をもとに分割すれば、
同じ拡張子のファイルは必ず同じReduceTaskで処理されるというわけです。
その後のReducerでは、同じ拡張子のファイルの長さの合計を計算する、といった処理が考えられますが、それには、もう一工夫必要です。
reduce関数に渡される、Valueのグルーピングを拡張子ごとに行う必要がありますが、これは後ほど解説します。
Combiner
Combinerは、Mapの出力をさらに集計する処理のことでMapTask内で行われます。Combinerの新たな出力が、Reducerの入力として渡されます。
例えば、 初回のHadoopの記事 でも解説したWordCountの例をあげてみましょう。
Combinerを使わないと以下のようになります。
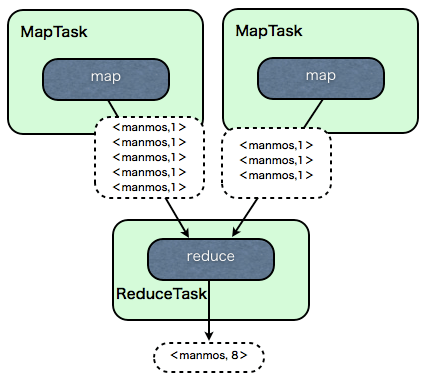
map関数の出力のKeyに単語の名前、Valueには1がセットされ、map関数の出力がそのままreduce関数に渡されます。
reduce関数では単語の数がカウントされて、<manmos,8> と単語の数の合計を出力します。
では、combinerを使うとどうなるでしょうか?
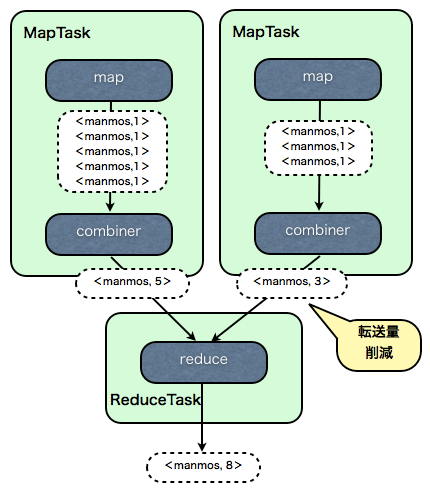
map関数の出力は、MapTask内でCombinerに渡されます。
Combinerでは、そのMapTask内での単語の数の合計を出力し、reduce関数に渡します。
reduce関数では、さらにそれらを足し合わせて、全体の単語の数の合計を出力するというわけです。
Combinerは、ReduceTaskへの転送量を減らし、Reducerの計算量を減らすことで、全体の高速化を図る目的で使われます。
なお、Combinerはオプションであり、必ずしも使うべきではないケースも多いので注意して下さい。
DistributedCache
DistributedCacheは、処理に必要なファイルを各マシンにコピーしてキャッシュする仕組みです。
配布は、Taskが実行される前に、一回だけ行われます。
キャッシュしたファイルは、Mapper、Reducerから自由に利用することができますが、読み込み専用で、変更してはいけません。
単にファイルをキャッシュするだけではなく、zip/tar/tgz/tar.gzなどの圧縮されたファイルは展開してキャッシュされます。
また、jarファイルを配布すると、自動でクラスパスに追加してくれ、MapperやReducerで使うことができます。
.soなどのネイティブライブラリも同様に配布できます。
例えば、jarファイルを配布する例は以下の通りです。
DistributedCache.addFileToClassPath(new Path("test.jar" ), job); // jobはJobConfファイル なお、MapperやReducerで共通で扱いたい文字列などは、JobConfに直接定義してしまうのが便利です。
job.set("my.string.conf" , "test" );MapやReduceの初期化処理などで、以下のようにしてJobConfに定義した文字列を取得できます。
public static class Map extends ... {
private String test;
public void configure(JobConf job) {
// JobConfに設定したデータを読み込む
test = job.get("my.string.conf" ); // "test" が入っている
}
public void map(...) throws IOException {
// 何か処理
}
}Comparator
Comparatorは、Keyのソートや、ReducerでのValueのグルーピングをカスタマイズできます。
Key同士をどう比較するかを定義します。
Keyのソートや、Valueのグルーピングに用いる、RawComparatorのインターフェイスは以下です。
public interface RawComparator<T> extends Comparator<T> {
public int compare(byte [] b1, int s1, int l1, byte [] b2, int s2, int l2);
}Keyのソートや、Valueのグルーピングでは、このcompare関数が呼ばれてバイト単位で比較されることになります。
RawComparatorのデフォルトの実装は、WritableComparatorです。
private final WritableComparable key1;
private final WritableComparable key2;
public int compare(byte [] b1, int s1, int l1, byte [] b2, int s2, int l2) {
try {
buffer.reset(b1, s1, l1); // key1を抽出
key1.readFields(buffer);
buffer.reset(b2, s2, l2); // key2を抽出
key2.readFields(buffer);
} catch (IOException e) {
throw new RuntimeException(e);
}
return compare(key1, key2); // 後のcompare関数を呼び出す
}
public int compare(WritableComparable a, WritableComparable b) {
return a.compareTo(b);
}WritableComparatorでは、バイト列からKeyを抽出し、そのKeyのクラスのcompareTo関数を用いて比較するようになっています。
カスタマイズしたComparatorを、Valueのグルーピングに用いる例をあげてみます。
先ほどのPartitionerのときの例では、同じ拡張子のファイルを同じReduceTaskに割り当てる処理を行いました。
その後のReducerでは拡張子ごとにファイルのバイト数の合計などを求める、などの処理が考えられますが、その場合、拡張子ごとにValueをグルーピングする必要があります。
拡張子ごとにグルーピングするComparatorクラスは以下の通りです。
なおKeyにはファイル名がセットされています。
public static class FileExtensionComparator extends WritableComparator {
protected FileExtensionComparator() {
super (Text.class, true );
}
public int compare(WritableComparable w1, WritableComparable w2) {
Text t1 = (Text) w1;
Text t2 = (Text) w2;
return getExtension(t1).compareTo(getExtension(t2));
}
private Text getExtension(Text t){
return new Text( t.toString().replaceAll("^.*?\\." ,"") ); // ファイル名から拡張子を抽出
}
}まず比較したいKeyのクラス(Text)を指定して、WritableComparatorのコンストラクタを呼び出します。
比較する際にcompare関数が呼び出されるので、ファイル名から拡張子を抽出して、TextのcompareToメソッドを呼び出しています。
このクラスをJobConfのsetOutputValueGroupingComparator関数で指定すれば、拡張子ごとにグルーピングされるというわけです。
なお、実はこの方法だと、一度Keyのバイト列をデシリアイズしてから比較しているので、低速です。
MapReduceでは、この比較のスピードは全体の処理時間に大きく影響します。
例えば、TextのデフォルトのComparatorでは、バイト列をそのまま比較する最適化を行っています。
public static class Comparator extends WritableComparator {
public Comparator() {
super (Text.class);
}
public int compare(byte [] b1, int s1, int l1,
byte [] b2, int s2, int l2) {
int n1 = WritableUtils.decodeVIntSize(b1[s1]); // ヘッダのバイト数を求める
int n2 = WritableUtils.decodeVIntSize(b2[s2]); // ヘッダのバイト数を求める
return compareBytes(b1, s1+n1, l1-n1, b2, s2+n2, l2-n2); // ヘッダのバイト数を除外して、バイト列のまま比較
}
}WritableComparatorのcompareBytesクラスを呼び出し、バイト列のまま比較を行っています。
なお、Textは、文字列のバイトの長さを、先頭に可変長で格納しています。
そこで、WritableUtilsクラスのdecodeVIntSize関数で、長さの情報を格納しているヘッダ自体のバイト数を求めて、そのヘッダを除外して比較を行っています。
このComparatorをTextのデフォルトのComparatorとして登録するには、
static {
WritableComparator.define(Text.class, new Comparator());
}のようにstaticブロックで、WritableComparatorのdefine関数を呼び出します。
OutputFormat
OutputFormatのインターフェイスは以下のようになっています。
public interface OutputFormat<K, V> {
RecordWriter<K, V> getRecordWriter(FileSystem ignored, JobConf job,
String name, Progressable progress)
throws IOException;
void checkOutputSpecs(FileSystem ignored, JobConf job) throws IOException;
}InputFormatと同様に、getRecordWriter関数で、KeyとValueを受け取って実際にデータを出力するRecordWriterクラスを返します。
RecordWriterのインターフェイスは以下です。
public interface RecordWriter<K, V> {
void write(K key, V value) throws IOException;
void close(Reporter reporter) throws IOException;
}write関数が繰り返し呼ばれて、データが書き込まれます。
例えば、Key/ValueをXMLに変換して書き出したい、HDFSではなくDBに書き込みたい、などの場合にOutputFormatのカスタマイズは有効です。
なお、複数のファイル、場所にMapReduceの出力を書き込める、 MultipleOutputFormat や、 MultipleOutputs という便利な仕組みも用意されています。
Writable
WritableクラスはMapReduceのKeyやValueとして使われるクラスです。
例えば、テキストにはTextクラス、intにはIntWritableといった具合にWritableクラスが用意されています。
Writableクラスは、マシン間で転送可能なバイトストリームへのシリアライズ、デシリアライズを行います。
Javaで用意されているものより、コンパクトで高速に処理できるのが特徴です。
Writableクラスのインターフェイスは以下の通りです。
public interface Writable {
void readFields(DataInput in);
void write(DataOutput out);
}readFields関数はバイトストリームのDataInputを読み取り、デシリアイズを行います。
また、write関数は、シリアイズを行い、バイトストリームのDataOutputに書き出します。
例えば、緯度経度を扱うWritableクラスは以下の通りです。
MapReduceのKeyとして扱うためには、比較も可能であるようにWritableComparableインターフェイスを実装します。
public class LatLon implements WritableComparable {
public double lat;
public double lon;
public LatLonDistance latLonDistance;
public double baseLat=35.681382; // 東京駅の緯度
public double baseLon=139.766084; // 東京駅の経度
public LatLon(double lat, double lon) {
this .lat = lat;
this .lon = lon;
latLonDistance = new LatLonDistance(baseLat,baseLon);
}
public LatLon() {
this (0.0f, 0.0f);
}
// シリアライズして書き出し
public void write(DataOutput out) throws IOException {
out.writeDouble(lat);
out.writeDouble(lon);
}
// デシリアライズして読み込み
public void readFields(DataInput in) throws IOException {
lat = in.readDouble();
lon = in.readDouble();
}
public String toString() {
return Double .toString(lat) + ", " + Double .toString(lon);
}
// 比較
public int compareTo(LatLon other) {
double myDistance = latLonDistance.calc(lat,lon); // 東京駅からの距離
double otherDistance = latLonDistance.calc(other.lat,other.lon); // 東京駅からの距離
return -Double .compare(myDistance, otherDistance); // 距離の逆順で比較(東京駅からの距離が近い方が大きい値)
}
public boolean equals(Object o) {
if (!(o instanceof LatLon)) return false ;
LatLon other = (LatLon) o;
return this .lat == other.lat && this .lon == other.lon;
}
// Partitionerなどに使うHash値を求める
public int hashCode() {
return (int ) (Double .doubleToLongBits(lat) ^ Double .doubleToLongBits(lon));
}
}write関数では、DataOutputのwriteDouble関数を呼び出しで、バイトストリームへの書き出しを行っています。
また、readFields関数では、DataInputのreadDouble関数でバイトストリームから読みだし、緯度経度を設定しています。
比較は、東京駅からの距離の逆順で行うようになっています。(東京駅からの距離が近い方が大きい値)
コンストラクタで、東京駅の緯度経度を指定してLatLonDistanceクラスを初期化し、compareTo関数内で、東京駅からの距離を計算しています。
なお、高速化のためには前述したComparatorを実装する必要があります。
また、Partitionerで呼び出される、hashCode関数なども必要です。
次回は
以上でカスタマイズポイントの解説は終わりです。
次回は、実際のサービスでの活用事例をあげ、今までに解説したカスタマイズポイントがどういじられているかを紹介する予定です。
P.S.
Hadoop Hack Night もよろしくお願いします!
(R&D統括本部 吉田一星)
追記Hadoopを使いこなす(1)
Hadoopを使いこなす(3)
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



