Yahoo! JAPAN研究所の鍜治です。本記事では、4月18日に公開されたオープンソースの単語分散表現学習ツールyskipに実装されているアルゴリズムincremental SGNSについて解説したいと思います。
単語分散表現の学習ツールとしてはword2vecなどが有名ですが、incremental SGNSは、そのword2vecに実装されている単語分散表現学習アルゴリズムの1つであるskip-gram model with negative sampling (SGNS)を、逐次学習可能な形に拡張したものになります。
Skip-gram model with negative sampling (SGNS)
まずはincremental SGNSの元となっているSGNSについて簡単におさらいをします。
SGNSによる学習をおおざっぱに説明すると、(1)学習データ中で近傍に出現した2単語の分散表現の内積値は大きく、(2)ランダムに選ばれた2単語の分散表現の内積値は小さくなるように単語分散表現を調整していると言うことができます。
![]() 個の単語からなるテキスト
個の単語からなるテキスト![]() が学習データとして与えられたとき、SGNSの学習は以下の損失関数
が学習データとして与えられたとき、SGNSの学習は以下の損失関数![]() を最小化することによって行われます。
を最小化することによって行われます。
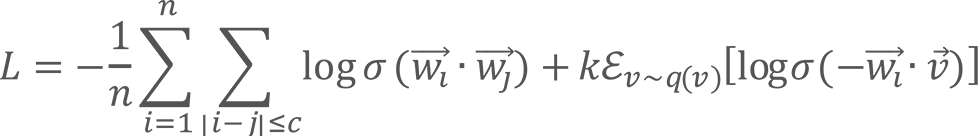
ただし、![]() はシグモイド関数、
はシグモイド関数、![]() は単語
は単語![]() の分散表現、
の分散表現、![]() は期待値を表しています。
は期待値を表しています。![]() と
と![]() は学習データ中で近傍(場所を表す索引
は学習データ中で近傍(場所を表す索引![]() と
と![]() の距離が
の距離が![]() 以下)に出現している単語になります。
以下)に出現している単語になります。![]() は、雑音分布(noise distribution)と呼ばれる確率分布
は、雑音分布(noise distribution)と呼ばれる確率分布![]() からランダムに抽出された単語です。
からランダムに抽出された単語です。
第一項と第二項が、それぞれ前述の(1)と(2)を実現する役割を担っています。上記の数式を見ていただくと、第一項の![]() を大きくする、または第二項の
を大きくする、または第二項の![]() を小さくすれば、損失関数
を小さくすれば、損失関数![]() が小さくなることが確認できるかと思います。
が小さくなることが確認できるかと思います。
逐次学習を解説する上で重要になるのは雑音分布![]() です。雑音分布は、具体的には以下のように定義されます。
です。雑音分布は、具体的には以下のように定義されます。
![]()
ここで![]() は単語
は単語![]() の学習データでの出現頻度で、αは補正を行うパラメータです。この補正に理論的な根拠はありませんが、適切な値のαを乗じることによって(0.75などがよく使われる)、単語分散表現の精度が向上することが経験的に知られています。
の学習データでの出現頻度で、αは補正を行うパラメータです。この補正に理論的な根拠はありませんが、適切な値のαを乗じることによって(0.75などがよく使われる)、単語分散表現の精度が向上することが経験的に知られています。
上記の損失関数は確率的勾配法で最適化することができます(擬似コード1)。
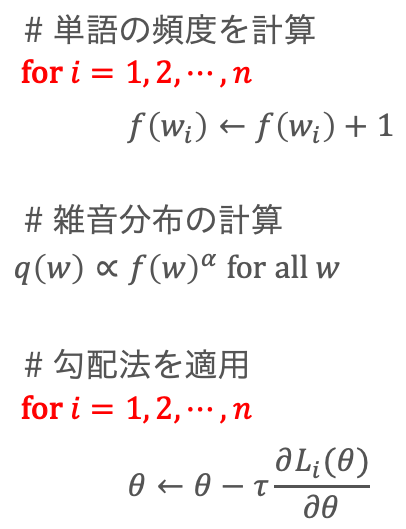
擬似コード1
Incremental SGNS
SGNSの学習に使うことのできるテキストデータは日々増え続けます。そして、その中には商品名などの新語も含まれていると考えられます。そのため、学習データが増えるたびにモデルの再学習を行いたくなります。しかし、モデルをゼロから学習しなおすには、少量の学習データを追加するだけでも時間がかかってしまいます。また、以前学習に使ったデータは捨ててしまった、などということも実際問題としてありえそうです。
そのためSGNSを毎回再学習するのではなく、新規に追加された学習データだけを使って逐次的にモデルの更新を行いたくなります。しかしながらSGNSは逐次的なモデル更新ができません。なぜなら新しいデータが追加されるたびに雑音分布![]() を計算しなおす必要があるためです。
を計算しなおす必要があるためです。
そこでSGNSを逐次学習可能な形に拡張したincremental SGNSを提案しました。アイデアは非常にシンプルで、雑音分布を事前に計算しておくのではなく、確率的勾配法を行いながら雑音分布を逐次的に更新していくというものです(疑似コード2)。

擬似コード2
要するにこれは、少し手抜きをして雑音分布を計算することによって逐次学習を可能にしているわけです。このことが単語分散表現の精度に悪影響を与えないか心配になるかもしれません。しかし、学習が進むにつれて雑音分布はどんどん正確になっていく(擬似コード1で求められる分布に近づく)ので、実際問題として精度はほとんど低下しません。理論的にも、学習データが十分に大きいときには、incremental SGNSはオリジナルのSGNSと同じ損失関数を最適化していると見なすことができます(論文参照)。
実装の工夫
上記のアイデア自体は非常にシンプルなのですが、効率的に実装しようとすると次の2点が問題になります。
- 語彙を事前に決めることが難しくなり、ナイーブに実装すると語彙サイズが際限なく拡大してしまいメモリ効率が悪くなる。
- 雑音分布を事前計算する場合に比べると、雑音分布から単語をランダムに抽出する処理が遅くなり、その結果として学習速度が低下する。
まず問題1については、動的な語彙を採用することによって対応しています。学習中にMisra-Griesアルゴリズムを使用して頻度上位の![]() 単語を近似的に列挙し、それらを語彙集合としています。
単語を近似的に列挙し、それらを語彙集合としています。![]() の値は事前に設定しておく必要がありますが、100万などの十分大きな値にしておけば実用上問題ありません。頻度上位の
の値は事前に設定しておく必要がありますが、100万などの十分大きな値にしておけば実用上問題ありません。頻度上位の![]() 単語はその時々で変化するため、語彙は学習の過程で動的に変化します。
単語はその時々で変化するため、語彙は学習の過程で動的に変化します。
次に問題2については、擬似コード1のように雑音分布を事前計算できれば、配列を使って効率的に抽出を行えることが知られています。具体例として、単語が![]() の3種類だけあり、
の3種類だけあり、![]() 、
、![]() 、
、![]() である場合を考えます。このとき、
である場合を考えます。このとき、![]() という配列を作成しておけば、一様分布にしたがってこの配列の要素をランダムに抽出することによって、雑音分布から定数時間で単語を抽出することが可能です。
という配列を作成しておけば、一様分布にしたがってこの配列の要素をランダムに抽出することによって、雑音分布から定数時間で単語を抽出することが可能です。
しかし、incremental SGNSの学習では![]() が動的に変化するため、学習データから単語を一つ読み込むたびに、この配列を作り直す必要があります。擬似コード2では
が動的に変化するため、学習データから単語を一つ読み込むたびに、この配列を作り直す必要があります。擬似コード2では
![]() と書いているだけなので簡単そうに見えますが、一般的に上記配列の要素数は大きいため(100万など)、この処理を単純に実装してしまうと速度が低下してしまいます。そこで、reservoir based samplingを重み付きに拡張したアルゴリズムを使うことによって、定数時間での配列更新を実現しています。
と書いているだけなので簡単そうに見えますが、一般的に上記配列の要素数は大きいため(100万など)、この処理を単純に実装してしまうと速度が低下してしまいます。そこで、reservoir based samplingを重み付きに拡張したアルゴリズムを使うことによって、定数時間での配列更新を実現しています。
まとめ
全体的に少し駆け足になってしまいましたが、yskipに実装されているアルゴリズムincremental SGNSについて解説をしました。Yahoo! JAPAN研究所では、こうしたオープンソース公開や論文発表にも力を入れて活動しています。今後も積極的に情報発信をしていきたいと思います。



