こんにちは。Yahoo!広告のデータサイエンティストをしております、田辺 広樹(ざるご)です。
時系列ビッグデータに対しては、オフライン評価の実施にあたって、学習時とは異なる操作を行う必要があります。弊チームでは従来、これらに対して、書き捨ての集計クエリ、Python スクリプトを作成することで対応を行っていました。
本記事では、これらの操作を自動化し、オフライン評価のための工数を削減した取り組みをご紹介します。
前提: Yahoo!広告における機械学習パイプライン
Yahoo!広告では、時系列ビッグデータを用いて、ヤフーの AI プラットフォーム上で広告配信コンバージョン率(CVR)予測モデルを学習し、広告配信に活用しています。
CVR 予測の機械学習パイプラインは、継続的なモデルの学習とサービングを行えるよう、ヤフーの AI プラットフォーム内で提供されている OSS のワークフローツールである Apache Airflow や Argo Workflows を用いて自動化されています。
具体的には、以下の機械学習パイプラインの各ステップを Argo Workflows で、パイプライン全体を Airflow で定義することにより、データ集計から学習・サービングまでを定期的に実行できるようなシステムが整えられています。
- 訓練データを作成するために必要なデータがデータベースに蓄積されるのを待つ
- データを集計・前処理し、訓練データを作成する
- 訓練データを用いて学習を行い、予測モデルを作成し、推論サーバーに連携する
ヤフーの AI プラットフォームに関しては、以下の記事で詳しく説明されておりますので、興味のある方はご一読ください。
オフライン評価の課題
Yahoo!広告に限らず、多くの Web サービスで使われる機械学習モデルの改善プロセスは、例えば以下のようなフローチャートに当てはめることができます。
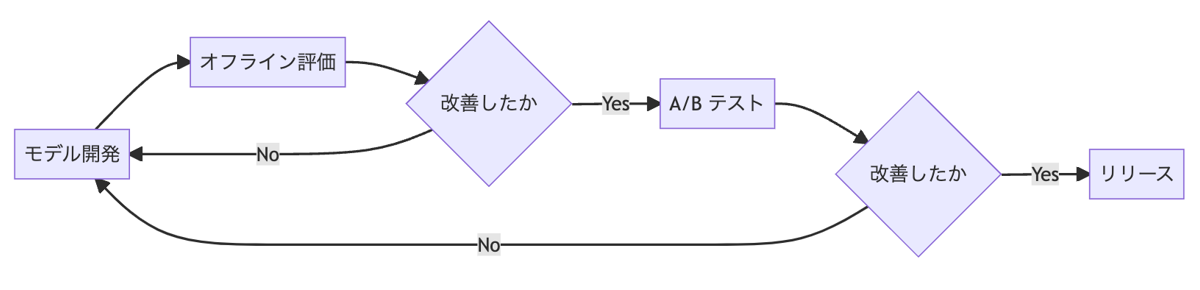
上記のフローチャートでは、開発したモデルが実際にリリースされるまでに、オフライン評価・A/B テストの 2 段のハードルを乗り越える必要があります。各ハードルを乗り越えられなかったモデルは、都度開発からやり直しになることから、前半にあるハードル(オフライン評価)ほど、使われる頻度が高いということになります。
一方、とくに時系列ビッグデータに対しては、以下のような理由から、オフライン評価の実施には、学習時とは異なる操作を行う必要があります。
- leakage を防ぐため、学習時とは異なる方法でのデータ集計・前処理が必要
- 学習済みモデルを使って、評価用データに対して、推論、評価を行うことが必要
そこで、以下の 2 ステップに分けて改善を行いました。
- オフライン評価のパイプライン化
- 評価パイプラインの定期実行への組み込み
1. オフライン評価のパイプライン化
機械学習モデルを生成するにあたって、データ集計 → 前処理 → 学習の流れをパイプライン化することは一般的です。
弊チームでは、Argo Workflows がこのパイプライン化を実現しています。Yaml で記述された設定ファイルを submit するだけでこれらの流れを実行することができ、非常に便利です。
前節にも述べたように、オフライン評価にあたっては、学習時と同じパイプラインを用いることはできませんが、評価は学習と常にセットで行われるべきことを考えると、評価時専用のパイプラインを用意することにも、十分なメリットが見込まれます。
そこで、データ集計 → 前処理 → 推論・評価という流れのパイプライン(Argo Workflows)を、学習時とは別に用意することとしました。(もちろん、学習時と共通化できる処理についてはなるべく共通化を行います。)
一度パイプラインを用意してしまえば、次回以降はそれを実行するだけで良く、モデル開発時の実験を楽に行えるようになりました。
2. 評価パイプラインの定期実行への組み込み
使われないプログラムは加速度的に壊れていきます。
実は、以前にも、オフライン評価用のパイプライン(Argo Workflows)が作られたことはありました。しかし、そのパイプラインは、使いたい人がたまに adhoc に使っていただけのものであったため、十分なメンテナンスが行われておらず、次に使おうと思った時には仕様変更などによってまともに動かなくなっているようなことが頻発していました。
このような現象を防ぐためには、開発したパイプラインが、強制的に使われ続けるような状態を保つ必要があります。そこで今回は、学習パイプラインの後段に、評価用パイプラインをつなげ、定常的に評価結果が生成されるような枠組みを作成しました。具体的には、定期実行されている学習パイプライン(Airflow)へ以下のように処理を付け加えました。
- 訓練データを作成するために必要なデータがデータベースに蓄積されるのを待つ
- データを集計・前処理し、訓練データを作成する
- 訓練データを用いて学習を行い、予測モデルを作成し、推論サーバーに連携する
- (New!) 評価用データを作成するために必要なデータがデータベースに蓄積されるのを待つ
- (New!) データを集計し、評価用データを作成する
- (New!) 評価用データに対して 3. で作成した予測モデルを用いて推論・評価を行い、評価結果を出力する
実装上の工夫: Airflow の Sensors について
上記のうち、「4. (New!) 評価用データを作成するために必要なデータがデータベースに蓄積されるのを待つ」のステップは不可欠です。なぜなら、評価用データは学習時から見ると未来のデータであり、学習終了時点では存在しない可能性があるためです。
便利なことに、Airflow には、何かが起こるのを待つことに特化した、Sensors という機能があります。今回は、評価用データの生成を待つ目的で、この Sensors を利用しました。ただし、今回のケースでは、Sensors をデフォルト設定のまま利用すると、2 つの問題点がありました。
Sensors の長期化
1 つ目は、Sensors の長期化です。
CVR 予測の評価には、ある程度長期間のデータが必要になります。すると、学習終了時から評価用データの生成を待ち続けた場合、1 つの Sensors が worker を占有し続けるという問題が発生します。
この点に関しては、Sensors のオプションにmode=rescheduleを指定し、poke_interval(Sensors による監視の間隔)を長めに指定することで対応しました。Sensors には、poke(既定)と、reschedule という 2 つのモードがあります。poke の場合は、Sensors は監視先のイベントが発生するまで worker を占有し続けますが、reschedule の場合は、一度チェックが失敗した後、poke_interval に指定した時間が経過するまで、worker を解放してくれます。
今回のように、Sensor が長期になることが予定されているケースでは、reschedule を用いるのが適切と言えるでしょう。
Sensors の大量発生
問題点の 2 つ目は、Sensors の大量発生です。
モデルの学習は定期的に行われる関係上、学習が終わるたびに次々と新しい Sensors がタスクとして追加されてしまい、クラスタに負荷をかけてしまう恐れがあります。これに関しては、Sensors タスクのオプションに、max_active_tis_per_dag=1というオプションを指定し、同名タスクの同時実行数を最大 1 つまでに制限することで対処しました。
おわりに
これにより、特定の日時に学習された特定のバージョンのモデルに紐づいて、評価用データ・評価結果がそれぞれ自動的に生成されるようになりました。評価パイプラインを定期実行に組み込むことは、本文で述べたように、評価用パイプラインのデグレを防ぐメリットのほか、常にオフライン KPI が可視化されることから、本番利用が始まった後も予測モデルの精度を監視し続けられるというメリットも得られます。
オフライン評価は、機械学習モデルを開発するには避けては通れない道だと思います。少しでも役に立つ部分がありましたら幸いです。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 田辺 広樹(ざるご)
- Yahoo!広告 データサイエンティスト
- Yahoo!広告の機械学習モデルの開発を担当しています。
-



