ベクトル検索技術は、画像や音声などのオブジェクトデータを、機械学習モデルなどを利用してベクトルで表現し、ベクトル間の距離を計算することで、類似するベクトルを検索する手法です。
高次元ベクトルの類似検索では計算量が増加することから、kNN(k-Nearest Neighbor)ではなくANN(Approximately Nearest Neighbor)が広く利用されています。検索で利用できるデータ形式は、ベクトルへの変換が可能であれば、テキスト、画像、音声、動画、バイナリなどさまざまなデータを利用できます。
ベクトル検索は、類似画像検索はもちろんのこと、レコメンデーションやデータ解析にも利用できます。ヤフーでも、後述する「Yahoo!ショッピング」の類似商品画像検索や、「ヤフオク!」の出品商品画像の推定などに利用されています。
ベクトル検索を実施するために必要なコンポーネントは「Embedding」「IndexStore」「Algorithm」の3つです。
Embeddingは、械学習モデルを利用してオブジェクトデータからベクトルに変換する役割があります。IndexStoreは、検索対象のベクトルインデックスを保存しておくレイヤーで、メモリ上やストレージ上など、さまざまなバリエーションがあります。Algorithmはベクトル検索のコアロジックで、例としてNGT、ScaNN、Faissなどが挙げられます。

ベクトル検索の2つのフェーズについて、大まかなデータフローを類似画像検索の例を用いて説明します。
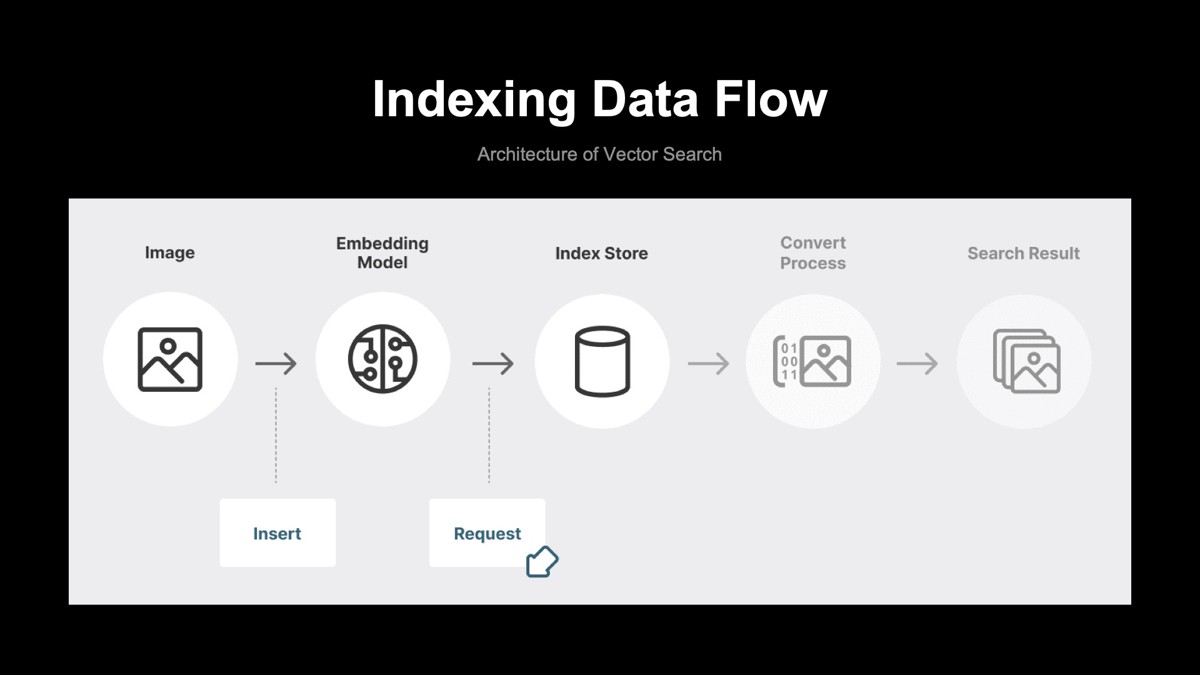
Indexingフェーズ
Indexingフェーズでは、ベクトルデータをIndexStoreへ保存することを目的としています。IndexStoreに保存したい画像をEmbeddingを通してベクトル化し、ベクトル化されたものをIndexStoreに保存します。
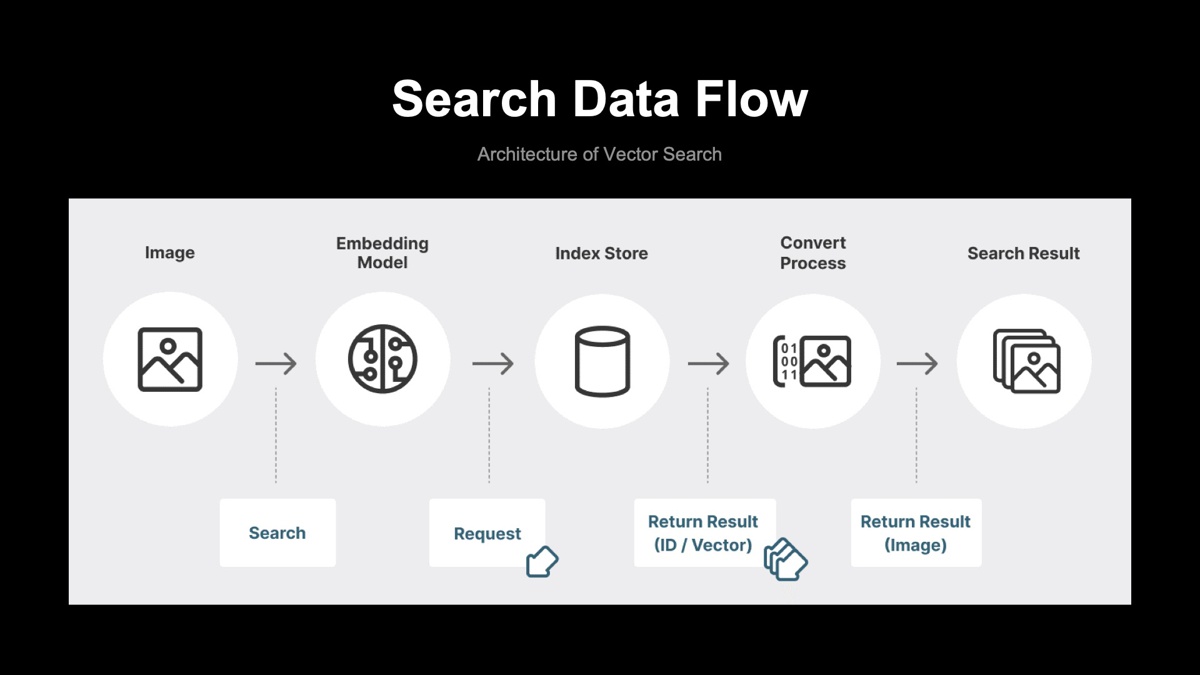
Searchフェーズ
Searchフェーズでは、検索対象画像と類似した画像をIndexingStoreから検索します。検索対象画像をIndexingフェーズと同じEmbeddingモデルを利用してベクトル化し、IndexStoreに対してベクトルを用いて検索リクエストを投げます。ここでANNの検索アルゴリズムを用いて類似のベクトルデータを取得します。最後に、ベクトルデータから画像データに変換し、類似の画像を取得できます。
ベクトル検索の最近の動向
トレンドに関しても少し説明します。
ベクトル検索ライブラリには、GoogleのScaNN、ヤフーのNGT、SpotifyのAnnoy、MetaのFaissなど、さまざまなライブラリが用意されています。本記事で紹介するValdでは、このうちNGTを利用しています(2022年11月時点) 。NGTは、高速高精度のANN検索ライブラリであり、ANN Benchmarksでも非常に高いスコアをつけていることがわかります。NGTに関する解説記事については、こちらを参照ください。
また、ベクトル検索エンジンとしては、本記事で紹介するValdや、Milvus、Qdrant、Weaviateなどがスタンドアローンサービスとして挙げられ、クラウドサービスとしてはVertex AI Matching EngineやPineconeなどがあります。
高速分散近似近傍密ベクトル検索エンジン「Vald」とは
Valdの概要
Valdは、Kubernetes上で動作する高速分散近似近傍密ベクトル検索エンジンです。オープンソース上で開発が進められており、ビリオンスケール規模のベクトルデータに対して、実時間でのベクトル検索を可能とする設計をしています。
ValdはGo言語を用いて開発されており、コアロジックに先ほど紹介したNGTが利用されています。Client Libraryは複数のプログラミング言語をサポートしています。gRPCのProtoファイルを公開しているので、どんなプログラミング言語でも利用することが可能です。
主な機能として、「非同期インデクシング」「拡張性」「自動バックアップ」「水平スケール」「ベクトルデータのレプリケーション」などがあります。
Valdのアーキテクチャ
Valdはマイクロサービスアーキテクチャを採用しており、Kubernetesと親和性の高い設計です。
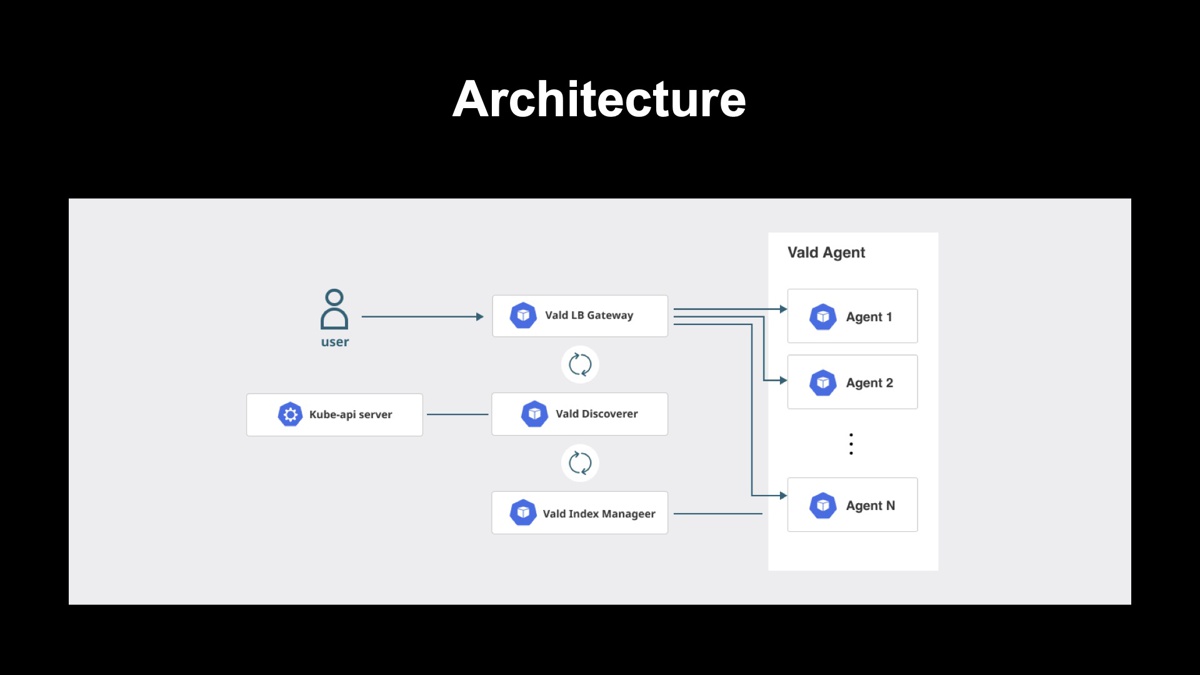
各コンポーネントはユースケースに応じて柔軟にカスタマイズ可能です。以下、各コンポーネントについてを紹介します。
Vald LB Gateway
Valdクラスタのエンドポイントである重要なコンポーネントで、全てのリクエストがここを通ります。リソースベースのロードバランサーを搭載し、メモリ平滑的にデータをインサートすることが可能です。また、検索結果のリランキングもこのコンポーネントで実行されます。Vald Discoverer
KubernetesのAPIサーバーからノードやポッドリソースの情報を集計し、Vald LB GatewayやVald Index Managerに必要な情報を伝達しています。Vald Index Manager
Vald Agentがストアされているインデックスのコミットタイミングなどをコントロールし、サービス停止なしでのインデックスデータの更新を実現しています。Vald Agent
Valdの心臓部です。Vald Agentでは、ベクトルデータのCRUD処理を担当し、実際のANNアルゴリズム(NGT)もここで利用しています。
ここからは、Valdで実装されている特徴的な機能である「Distributed Index Replication」、「自動バックアップ」、「検索アーキテクチャ」についてそれぞれ解説していきます。
Distributed Index Replication
Distributed Index Replicationの機能の主な目的は、以下3つです。
- 障害時にインデックスの欠損を防ぐ
- 複数のAgentに均等にインデクシングすることで、Agent Podのメモリ使用率を平滑化し、コンピューティングリソースをくまなく使うことができる
- リソースをくまなく使えることで、検索スピードを向上させられる
下図は、Distributed Indexingのデータフローです。この例ではベクトルaからyまでのデータが順次インサートリクエストに乗っていきます。インサートリクエストを受けつけたLB Gatewayは、インデックスレプリカの数(この例ではIndex Replica=2)に応じて、N個のAgentのうち2つのAgentに対して必ずインサートを実施します。
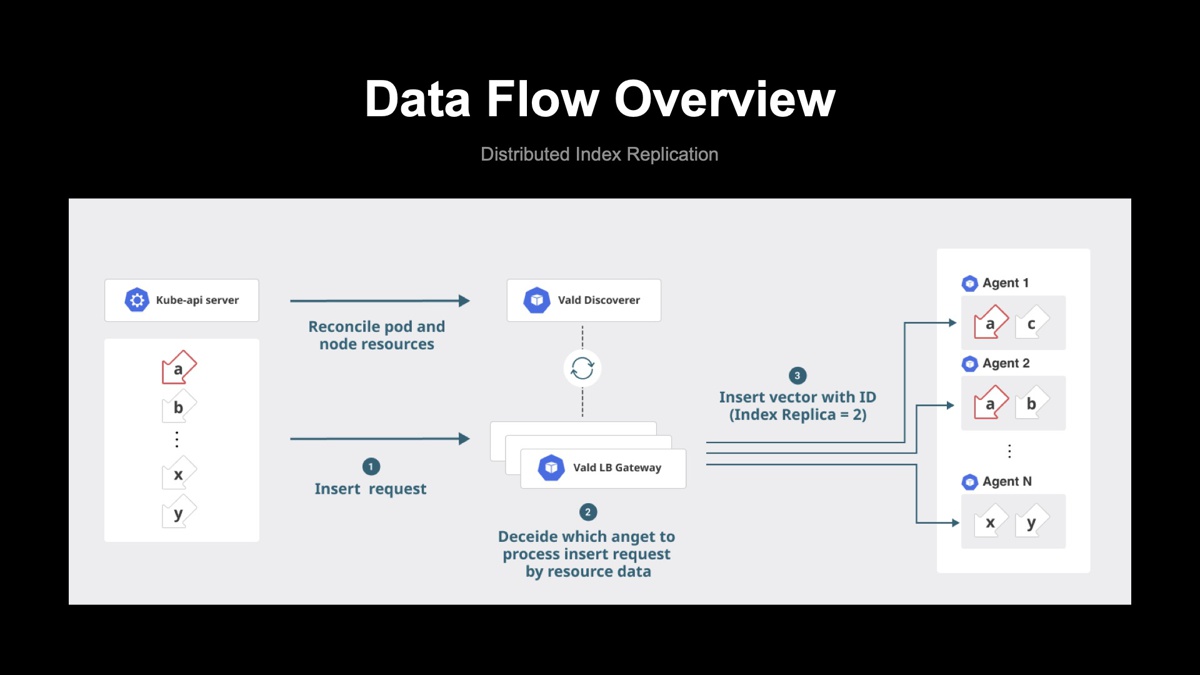
ここからは、インサートリクエストを送るAgentの選択アルゴリズムについて説明します。
下図はValdクラスタのAgent Podが3つのノード上で動作している例を示しています。各ノードのメモリ使用率は70%、50%、40%です。ノードのメモリを超えてプロセスを実行できないため、ノードメモリを重要視してランキングを実施します。

まずノードメモリの使用率から優先順位を決定し、次に各ノードの中でメモリ使用率が一番低い順に優先順位を割り当てます。最終的には、Agent 3、5、1、2、4の順にインサートされる優先順位が決定します。例えば、Index Replica=3の場合であれば、3、5、1にインサートされます。
Distributed Indexingのより詳しい解説については、アーカイブ動画(6:18頃)をご覧ください。
このアルゴリズムが実装される前のValdは、かなり乱れたメモリ使用率をしていましたが、アルゴリズムが搭載されてからは、より平滑的にベクトルデータを処理できることが確認できています。また、AgentのOOM Kill防止にも役に立っています。
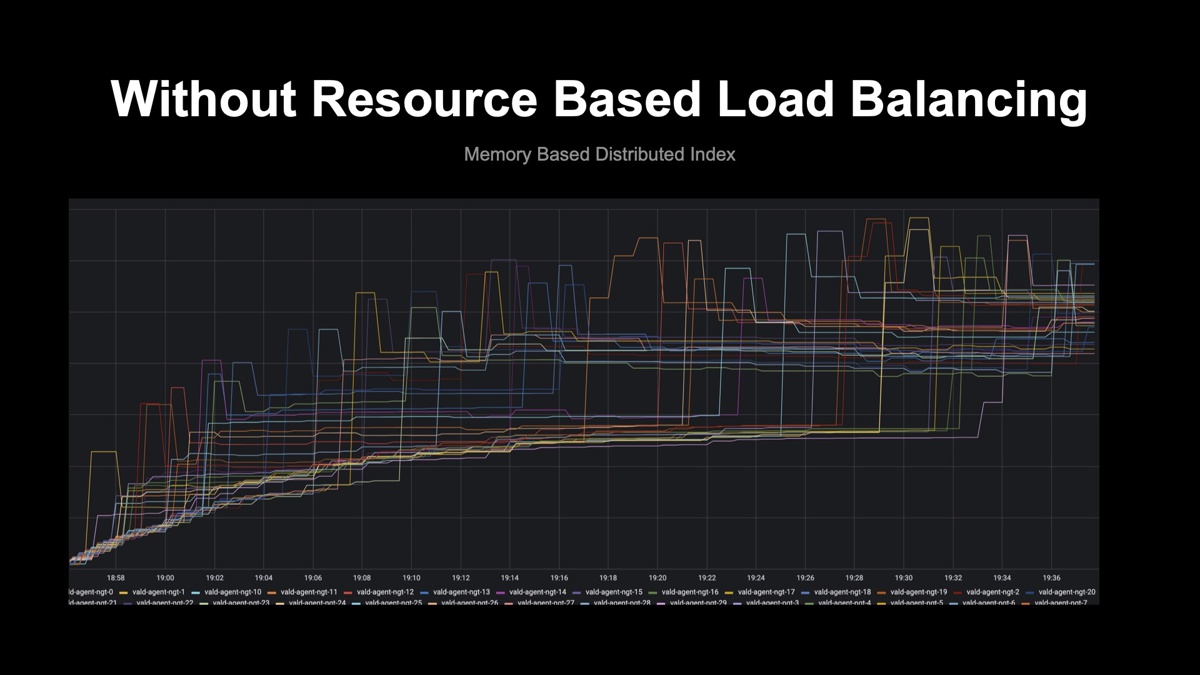
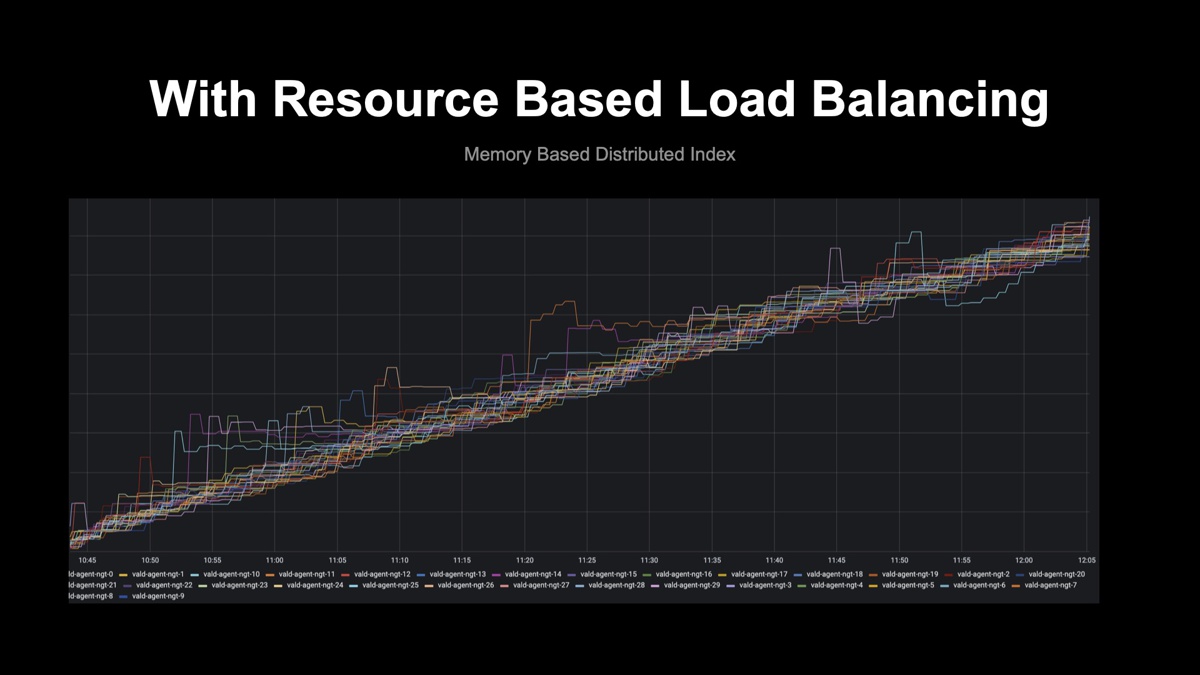
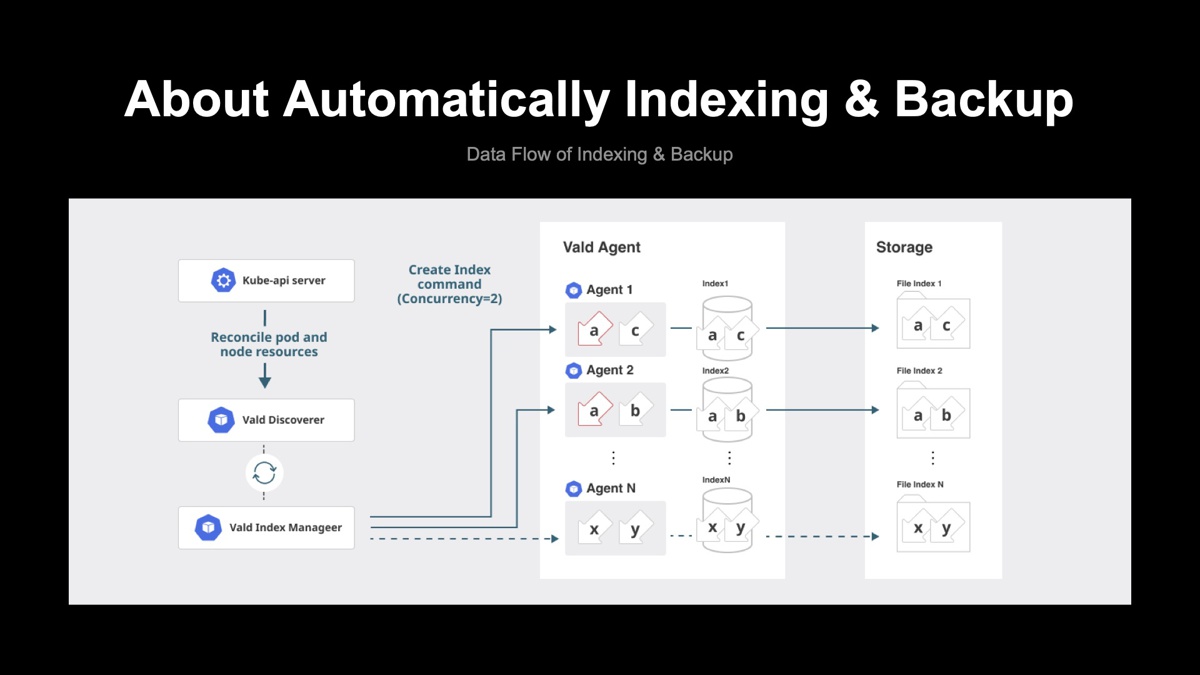
自動インデックスバックアップ
インデクシング中のAgentは、検索やインサート処理などすべてのCRUD処理を実施できません。もし、全てのAgentが同時にインデクシングを行うとValdクラスタの動作が停止してしまいます。そこで、Vald Index ManagerがValdクラスタとして動作が停止しない程度に、各Agentがタイミングをずらしてインデクシング行うようにタイミングをコントロールしています。
Valdの検索アーキテクチャ
ベクトルデータの検索は下図のようになっており、今回は「Top-K = 2件のデータが欲しい」というクエリを想定して解説します。
LB Gatewayは、①検索リクエストを受け取り、②全てのAgentに対してトップ2件の検索リクエストをブロードキャストします。AgentがN台ある想定なので、③では2N個のデータが返ってきます。④のプロセスでは、2N個のデータから2個にデータを絞るプロセスが実施されます。
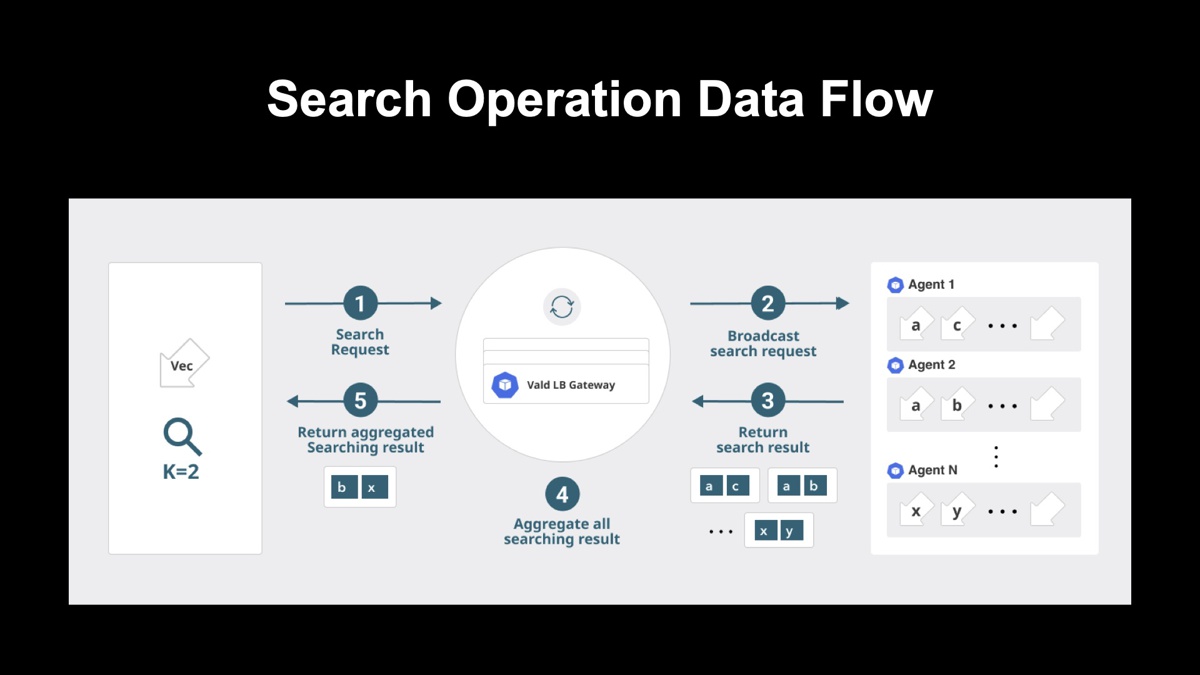
④におけるアグリゲーションプロセスについては、アーカイブ動画(10:10頃)で詳細を解説しているのでぜひそちらもご覧ください。
Valdのユースケースとデモ
Valdの4つの活用例
ベクトル検索の応用範囲は多岐にわたりますが、ここでは、「検索」「分類」「推薦」「分析」の4つの領域でのValdの活用方法について紹介します。
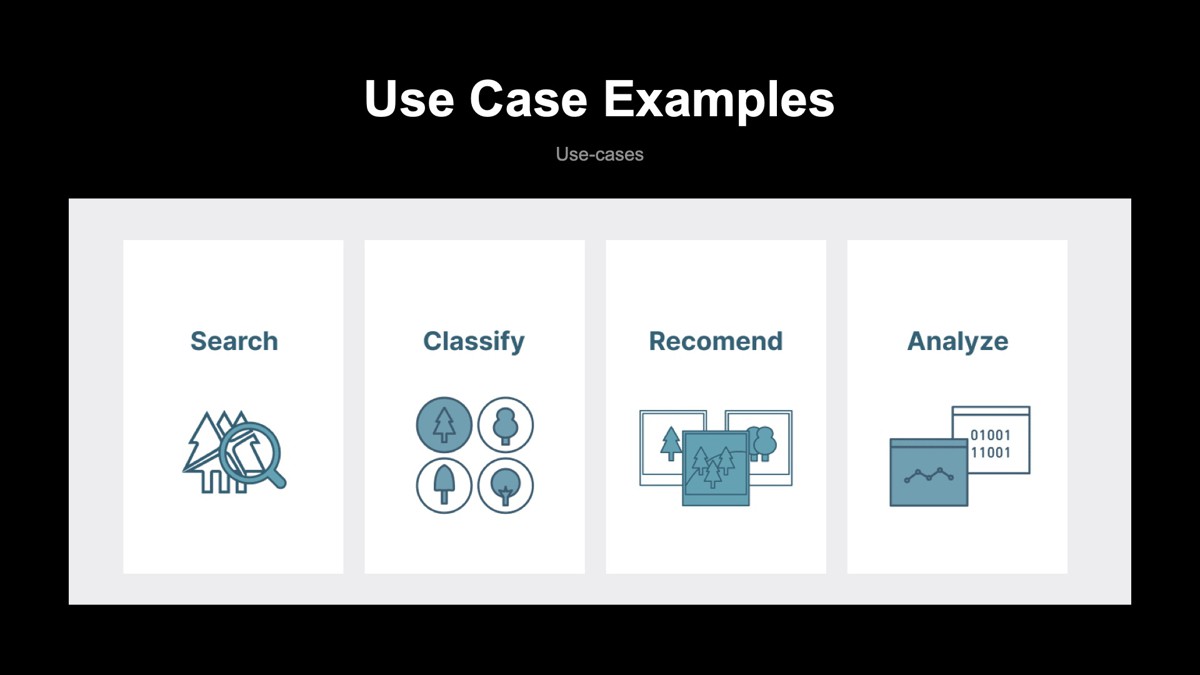
検索
検索したいオブジェクトデータに類似したオブジェクトデータを検索します。類似画像検索が一番想像しやすいと思います。分類
入力したオブジェクトデータがどのグループに属するかを分類します。顔画像認識などが応用事例です。推薦
検索対象のオブジェクトデータに対して、推薦したいアイテムを推薦結果として返却します。ECのおすすめ商品やパーソナライズされたインターネット広告などが活用事例です。分析
異常検知やマルウェア検出などへ活用できます。時系列データやバイナリデータなど、さまざまなオブジェクトデータに対して事前に知り得ている異常状態やマルウェアに対応するベクトルを検索することで、入力データの分析ができます。
導入事例
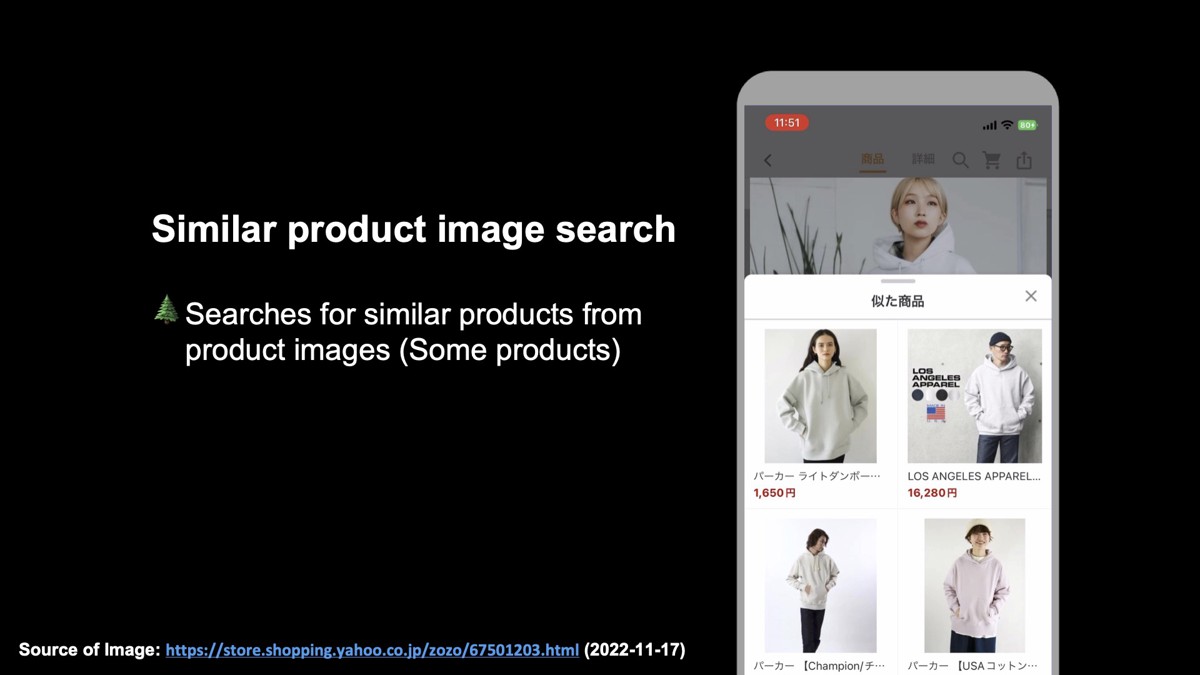
「Yahoo!ショッピング」では、スマートフォンアプリ上で特定のカテゴリーの商品画像から類似商品の検索を行えます。例えば、検索可能な商品には虫眼鏡マークのアイコンが出て、アイコンをタップすると類似商品を検索できます。
「ヤフオク!」では出品時に、出品商品画像から商品情報の推定にValdを利用しています。例えば、撮影した写真を実際に利用することで、商品名の推定を行えます。商品を撮影するだけで商品タイトルやブランド名などを推定して表示できるため、ユーザーによる入力の煩わしさがなくなります。

他にもさまざまなサービスでValdが活用されています。
Valdの導入方法
ここからはValdの導入方法について紹介します。Valdは、「Helmコマンドを利用した方法」、「vald-helm-operatorを利用した方法」という二つの方法でデプロイすることが可能です。
Helmを利用した方法は、数ステップでデプロイすることが可能です。クラスタの操作は全てHelmコマンドで行います。
一方、vald-helm-operatorでは、Kubernetes のCustom Resource Definition機能(CRD)を利用します。あらかじめ定義されたCRDに基づき、vald-helm-operatorが理想の状態となるようにValdクラスタの管理を行います。クラスタの設定の変更などは全てkubectlコマンドで行うことができます。プロダクション環境でのValdクラスタの利用では、こちらの方法を推奨しています。
以下では、Helmを利用したデプロイの手順について説明します。手順は大きく4つのステップがあります。
- デプロイするKubernetesクラスタを準備
- Helm RepoにValdのチャートを追加
- ユーザーごとにデプロイしたい内容のパラメータを記載するvalues.yamlを作成
- Helmインストールコマンドを用いて、Valdクラスタをデプロイ
デモ
Helmコマンドを利用したValdクラスタのデプロイのデモと、chiVeを利用した類似テキスト検索のデモをアーカイブ動画(18:50頃)で実演しているので、ぜひそちらもご覧ください。
さいごに
ValdはOSSとして開発しているプロダクトです。ぜひお気軽にお試しください。フィードバックやご要望も受け付けているので、いつでもご連絡ください。
アーカイブ動画
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 加藤 優介
- CTOテックラボ ソフトウェアエンジニア
- テックラボで主管する4つのプロダクトのプロダクトオーナーを担う。
-

- 湯川 輝一朗
- CTOテックラボ ソフトウェアエンジニア
- Vald内のプロジェクトマネジメントとCRE領域に従事。
-



