こんにちは。ヤフーの広告部門で機械学習エンジニアをしている加藤です。
ヤフーの広告配信にはさまざまな機械学習モデルが使用されており、私たち機械学習エンジニアは日々それらのモデルの改善を行っています。機械学習モデルを改善する際には必ず一度A/Bテストを行いKPI向上を確認したのちにリリースをするのですが、改善施策が多く動くようになりA/Bテストの数が増えてくると、徐々にそれら全てのA/Bテストを管理すること自体が難しくなってきます。特にそれぞれのA/Bテストのために作成されたコードの管理は煩雑になりがちで、アドホックに作成されたコードがあまり統一されない形で配置されがちです。
この記事ではこの問題をGitHubのPull Request機能(以下PR)をうまく活用することで改善した広告配信コンバージョン率(CVR)予測システムの事例を紹介します。従来は各A/Bテスト用モデル作成コードを別々に少しファイル名等を変えて作成しmainブランチに配置していたところを、本番モデルのみをmainブランチに配置し、テスト用モデルを各featureブランチから作成できるようにすることで、A/Bテスト用モデルの管理を簡単に行うことができるようになりました。
広告配信CVR予測システムの概要
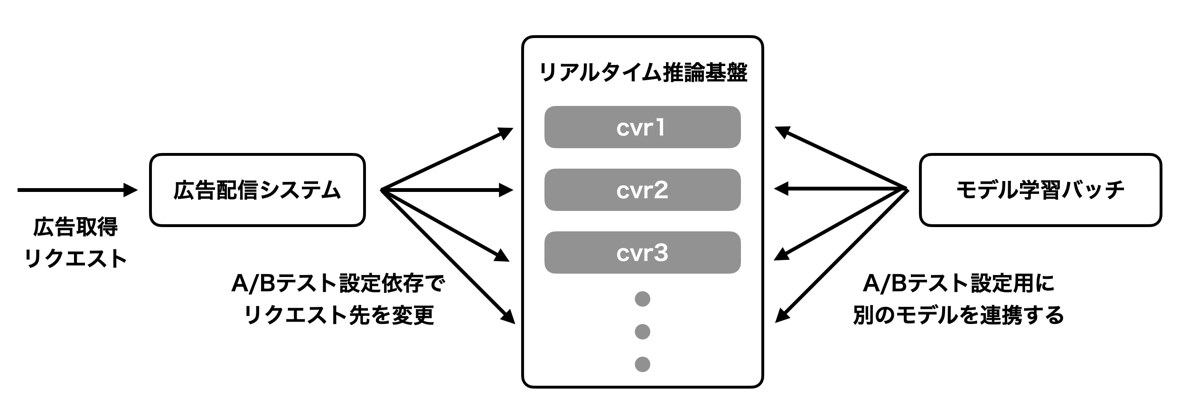
広告主が広告を掲載するのは顧客に商品やサービスを買ってほしいからです。それら購買活動を広告配信の文脈ではコンバージョンと呼び、広告配信システムの最適化にはその確率(CVR)を予測するCVR予測システムがさまざまな場面で活躍しています。CVRの値はサイトを訪れたユーザー、訪問されたサイト、配信された広告、訪問時刻、などさまざまな要素によって変化するため、その値の予測はユーザーがサイトを訪れるたびに行われ、配信する広告の選択に利用されています。
ユーザーがサイト訪問をするたびにCVR予測をするため、CVR予測システムは大きく分けてそのトラフィックを捌くためのリアルタイム推論基盤と、そのリアルタイム推論基盤に学習済みCVR予測モデルを連携するための学習バッチシステムに分割されます。学習バッチは定期的に起動し学習データの集計とモデル学習を行い、学習済みモデルをストレージに配置します。リアルタイム推論基盤は定期的にストレージを確認し、最新のモデルが存在すれば自動で更新を行います。
CVR予測システムは常に改善が行われており、改善の効果を確認するA/Bテストを実施するためにリアルタイム推論基盤には複数種類のモデルを連携できます。リアルタイム推論基盤の制約により連携できるモデルの種類数は固定値となっており、現状では10種類のモデルが連携できる状態になっています。それぞれの連携口を慣用的にcvr0からcvr9と名付けて呼んでおり、その最後の数字(0-9)をモデルsuffixと呼んでいます。
(※予測やモデル作成にあたり、ヤフーではお客様のプライバシーの保護に細心の注意を払っています。詳しくはYahoo! JAPAN プライバシーセンターをご覧ください。)
A/Bテスト実施時に存在した課題
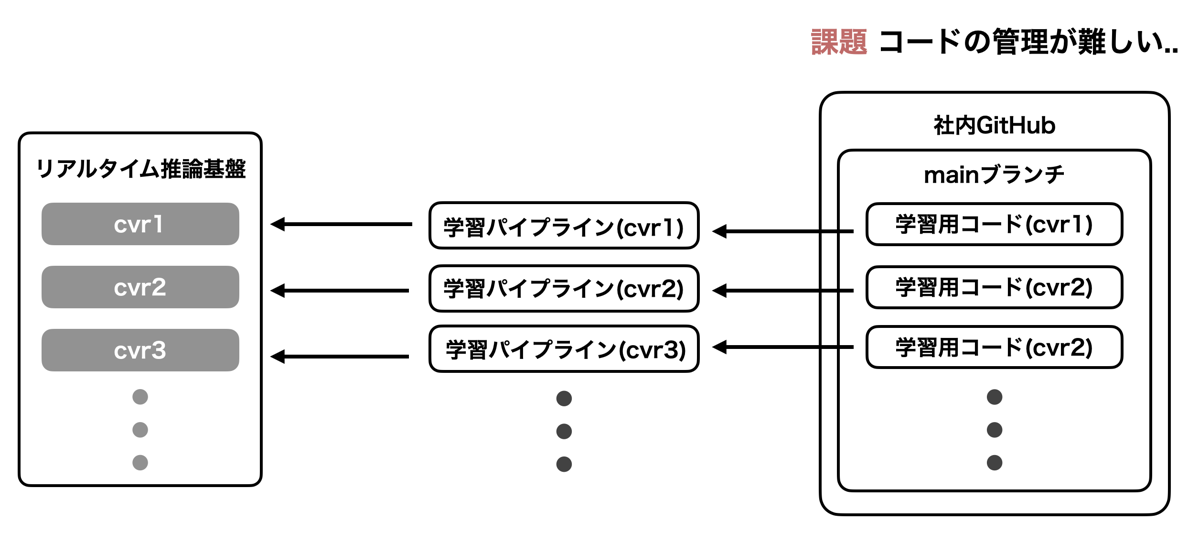
A/Bテストを行う際には学習バッチからリアルタイム推論基盤に複数の種類のモデルを連携する必要があります。学習バッチはもともと一つの種類のモデルを作成するために作られたものだったため、複数のモデルを連携するにあたってはその学習バッチをほぼコピーして作成された複数の学習パイプラインが作成されていました。それらのソースコードはモデルsuffixに応じて少しずつファイル名を変えて( train1.py 、 train2.py のような形)同じレポジトリのmainブランチに配置されていました。結果的に、モデルsuffixそれぞれのために、ほぼ同じだが細かいところが所々異なるデータ集計コードやモデル学習コード等が多数存在する状態になっていました。
このようなシステムになっていたため、CVR予測モデルの改善案を思いつきA/Bテストを実施することになった場合は、まずどのモデルsuffixを使用するかを決定するところから始めることになっていました。その宣言を行ったあと、そのモデルsuffixに紐づくデータ集計スクリプトやモデル学習コードを改修する開発を行い、A/Bテストを実施していました。
長年このような流れでA/Bテストが行われてきていたのですが、いくつか課題が出てきていました。
- 異なるモデルsuffixのコードが同じレポジトリにファイル名を変えて配置されているため、モデル間の差分を把握するのが難しい状態でした。また、そもそもコードの内部にモデルsuffixに依存した関数名などが存在していたため、例え手動で差分を取ったとしてもそれら意味のない差分が多く出てきてしまい、本質的なコードの挙動についての差分を見つけにくくなっていました。
- A/Bテストが終了し本番適用となった場合、その変更を他の開発中のモデルsuffixに取り込む手法が手動で差分を見ながら適用するしか方法がなく、手作業によるミスが発生しうる状態でした。
- 本来であればA/Bテスト期間中のみモデルsuffixを占有すれば十分だが、そのための開発期間中もそのモデルsuffixに紐づくコード等を全て占有してしまい、モデルsuffixの数以上のA/Bテストの開発を並列で行うことが難しくなっていました。
GitHubのPR機能をうまく活用した解決方法
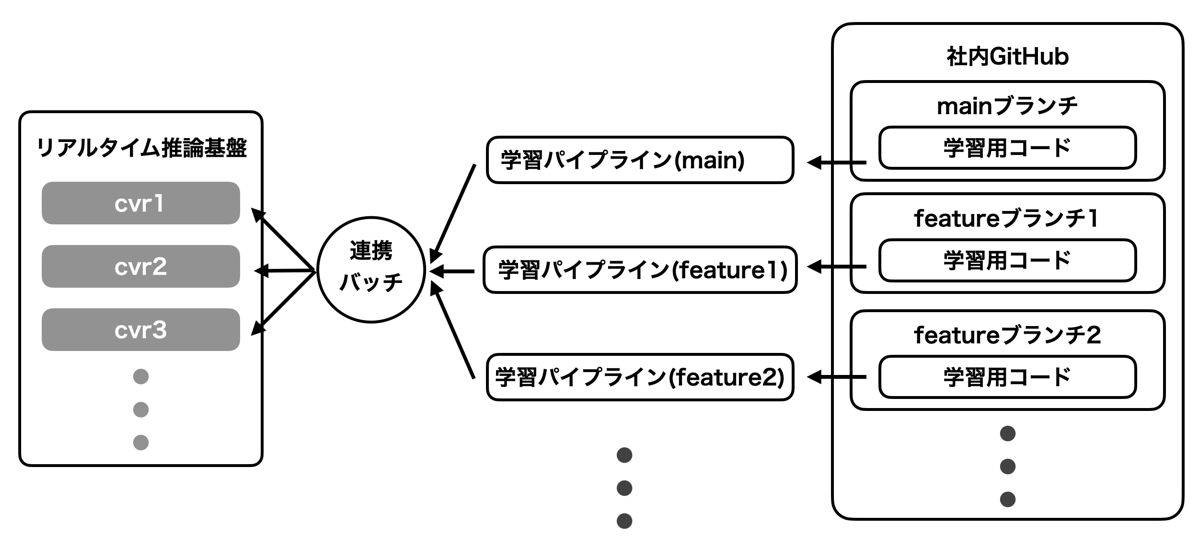
それらの課題を解消するため、上図のように根本的に学習バッチの管理の仕方を見直しました。本番環境で使用されているモデルのデータ集計コードやモデル学習のコードをmainブランチに配置し、A/Bテスト用のモデルは全てそのmainブランチに対するPRとして管理します。本番環境で使用されるモデルを作成する学習パイプラインはmainブランチから生成され、A/Bテストで使用される学習パイプラインはそれぞれのPRに付随するfeatureブランチから生成されます。A/Bテスト中はそのfeatureブランチから生成された学習パイプラインを使用して配信を行い、性能改善が確認されればそのfeatureブランチをmainブランチにマージ、性能が改善しなければマージせずにcloseします。
このようにGitHubのPR機能を応用し、A/Bテスト用モデルをPRとして管理することで、従来存在した複数の課題を解決できました。
- 本番モデルとテストモデルの差分は単にPRの差分画面を見るだけで済み、従来のように手動で差分を取るなどの作業が必要なくなりました。
- 本番適用となったモデルの変更を取り込むのは単にブランチ間のマージを行うだけですみ、従来のように人手でマージを行う必要がなく、人的ミスが減りました。
また、各ブランチに紐づく学習パイプラインが生成したモデルをリアルタイム推論基盤の各連携口に紐づけるバッチ処理も用意しました(上図の連携バッチ)。このバッチ処理は定期的に全ての学習パイプラインを確認し、モデルの生成が終了しているパイプラインが存在すれば保持している対応関係をもとにそのモデルを適切な連携口に自動でコピーします。その対応関係はバッチ処理内部の一つの設定ファイルで管理されており、例えばmainブランチのモデルは現在本番環境で主に使用している連携口cvr0に連携し、今度A/Bテストを行う予定の変更を入れたfeatureブランチのモデルは別の連携口cvr7に連携しておく、というような設定を簡単に行うことができます。
このようなバッチ処理を学習パイプラインとリアルタイム推論基盤への連携口の間に導入することで、学習パイプラインの開発や動作検証などとリアルタイム推論基盤へのモデル連携を完全に分離することができました。従来はそれらの依存が大きかったため連携口の種類数以上の開発を並列に行うことができませんでしたが、この導入後それ以上の並列数で開発を行うことが可能になりました。
検討したが採用しなかった案
今回採用した、A/Bテスト用のモデルをGitHubのPR機能を用いて管理する方法は、調べれば行っている例は出てくるものの、業界標準になっている手法であるとは言えないと思います。そのため今回の方法を採用する前には複数の方法を検討し、社内の機械学習基盤などの特性も考慮しながら採用を決めました。
例えば、ヤフーの広告配信システムでは一般的な Feature Flag の採用も考えましたが、CVR予測システムの性質と合わないため見送りました。 Feature Flag 方式を採用すれば1種類のコードで設定によって複数の挙動をさせることができるため、似たようなコードを複数管理する必要がなく、コード管理が簡単になると考えられます。ただし一般的なシステム開発と異なり機械学習システムは次のような特徴があるため、 Feature Flag 方式には向いていないと判断し採用しませんでした。
- モデルアーキテクチャの根本的な変更など Feature Flag とするには大きすぎる変更を入れる機会が比較的多い
- SQL等による集計が学習パイプラインに含まれていることが多く、SQLスクリプトに対して Feature Flag を実装するのが難しい
おわりに
機械学習システムのA/Bテスト用コードの管理をGitHubのPR機能をうまく活用して簡単にできるようにしました。これにより複数のA/Bテストを実施する際の管理コストを低下させた上、従来存在した人手での作業によるミスが入り込む余地を減らすことができました。今後もA/Bテスト等の高速化を図るための改善を行うと同時に、改善されたシステムを用いて広告配信をさらに改善していきます。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 加藤 卓也
- 広告配信 機械学習エンジニア
- Yahoo!広告の配信システムと機械学習モデルの開発を担当しています。



