こんにちは。Yahoo! JAPAN研究所で自然言語処理の研究開発をしている柴田です。
早稲田大学との共同研究で、日本語言語理解ベンチマークJGLUEを、2022年6月に構築・公開しました。自然言語処理モデルの網羅的評価に用いるもので、利用申請など不要でどなたでもお使いいただけます。これまで日本語においてはこういったベンチマークは存在していませんでした。この記事では公開の背景やその中身、日本語基盤モデルの評価などを紹介します。
1. 背景
近年、基盤モデル(Foundation Model)と呼ばれるモデルが注目を浴びています。基盤モデルとは大規模なデータから学習し、さまざまなタスクに適用できるモデルのことを指し、スタンフォードのグループが命名しました[文献1]。基盤モデルには、自然言語処理のモデルであるBERT[文献2]やGPT-3[文献3]、言語と画像のモデルであるCLIP[文献4]などが含まれ、一昔前では不可能だったことがどんどんできるようになってきています。
![基盤モデル ([文献1]より引用)](https://s.yimg.jp/images/tecblog/2022-H2/142/01_foundation_model.png)
(出典:[文献1]より引用)
基盤モデルの性能を向上させるには公開されたベンチマーク、すなわち、いくつかのデータセットを集めた評価セットが不可欠です。基盤モデルは汎用的でさまざまなタスクに適用可能なので、一つのタスクではなくいくつかのタスクでの総合的な評価が必要です。また、ベンチマークは公開され誰でも利用可能なものでないと、同じ土俵で複数の基盤モデルを比較できません。
基盤モデルの性能が向上すると、より難しいベンチマークが提案され、また、難しいベンチマークが解けるように基盤モデルの性能が向上していく、のように、基盤モデルの性能向上と難しいベンチマークの提案のサイクルが生まれ、双方が進歩していっています。

2. 自然言語処理における日本語ベンチマークの必要性
自然言語処理モデルの網羅的評価にはGLUE(General Language Understanding Evaluation)[文献5]や、これをさらに難しくしたSuperGLUE[文献6]のようなベンチマークが広く用いられています。
自然言語処理の場合、ベンチマークは言語ごとに構築する必要があります。必然的に英語を中心にベンチマークの構築が進んでいますが、中国語やフランス語など、英語以外の言語でも構築が進んでいます。しかし、日本語においてはGLUEのようなベンチマークは存在せず、日本語の自然言語処理の進展を阻害しています。
日本語は他の言語と比較して、以下のような特殊性があります。
- 単語が空白で区切られていません。
- ひらがな・カタカナ・漢字・アルファベットなどさまざまな文字種が使用されます。
- 主語や目的語が頻繁に省略されます。(例えば「昨日、サッカーの試合を見た。」という文において主語の「私」が省略されています。)
したがって、英語のベンチマークでの知見がそのまま日本語にあてはまるかは分からず、日本語のベンチマークが必要不可欠です。
そこで、日本語言語理解ベンチマークJGLUE(Japanese General Language Understanding Evaluation)を構築・公開しました。JGLUEの構築はヤフーと早稲田大学河原研究室(以下、早稲田大)との共同研究で行いました。
3. JGLUEの構築方法
日本語のベンチマークを構築する方法として、英語のベンチマークを翻訳することも考えられますが、自動翻訳、人手翻訳いずれにしても、翻訳に起因する不自然さが生じてしまいます。そこで、翻訳の不自然さが生じないように、日本語のテキストで一から構築しました。
最初から多くのデータセットを作ることは難しいことから、英語のベンチマークである上述のGLUEやSuperGLUEで採用されているタスクをなるべくカバーするように、以下のようにタスクとデータセットを設計しました。(この記事では、「タスク」は問題の設定、「データセット」は訓練・検証・テストセットからなる最小の単位を指し、全部まとめたものを「ベンチマーク」と呼んでいます。)
| タスク | データセット |
|---|---|
| 文章分類 | MARC-ja |
| JCoLA(他機関から提供される予定) | |
| 文ペア分類 | JSTS |
| JNLI | |
| 質問応答 | JSQuAD |
| JCommonsenseQA |
大規模なデータセットを短期間で構築するために、データセット構築にはYahoo!クラウドソーシングを用いました。
以下に各データセットの概要を示します。
MARC-ja
MARC-jaは商品レビューを入力として、ポジティブ(positive)かネガティブ(negative)かを推定するタスクです。多言語商品レビューコーパスMARC(Multilingual Amazon Reviews Corpus)[文献7]の日本語部分を用いて構築しています。検証・テストセットについては正解ラベルが妥当であるかをクラウドソーシングで判定し、ラベルをクリーニングしています(訓練セットは数が多いことからクリーニングはしておりません)。

JSTS/JNLI
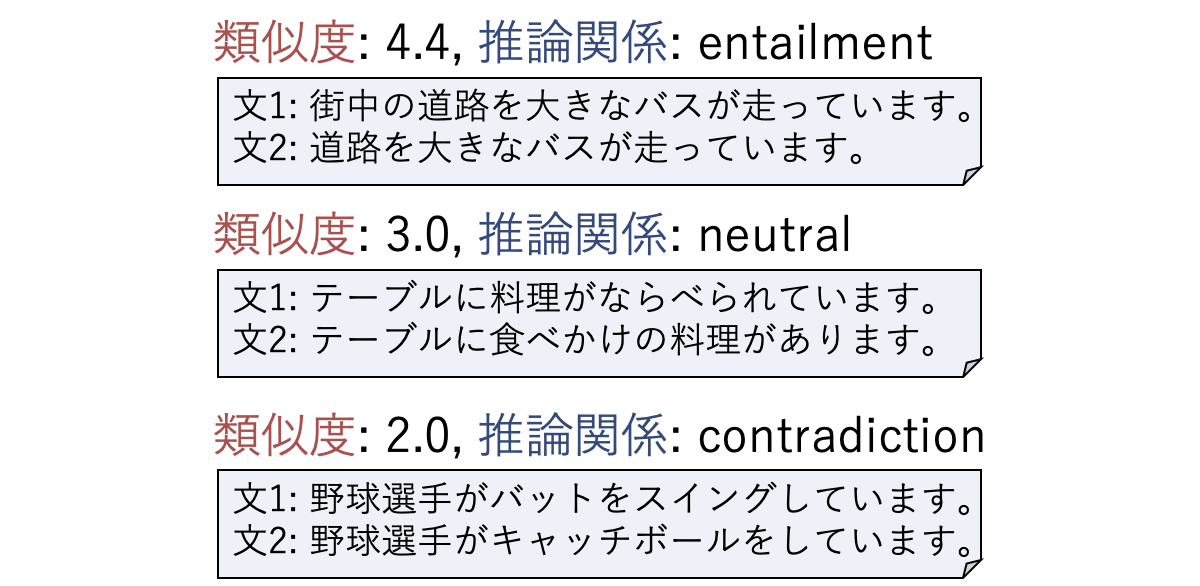
JSTS(Japanese Semantic Textual Similarity)とJNLI(Japanese Natural Language Inference)はともに2つの文が与えられ、JSTSは2文間の類似度(0から5までの値をとり、5が最も類似しています)を、JNLIは含意(entailment)、矛盾 (contradiction)、中立(neutral)のいずれの推論関係かを推定するタスクです。文ペアはヤフーが公開しているYJ Captions Datasetを用い、類似度ならびに推論関係をクラウドソーシングで付与しました。
JSQuAD
質問応答で有名なデータセットにSQuAD(Stanford Question Answering Dataset)[文献8]があります。SQuADは、数文からなる段落とそれに関連する質問が与えられ、段落から抜き出す形で答えるタスクです。JSQuADはSQuADの日本語版で、Wikipediaの日本語記事を用い、段落に対応する質問とその答えをクラウドソーシングで作成しました。

JCommonsenseQA
SQuADとはまた別のタイプの質問応答のデータセットとしてCommonsenseQA[文献9]があります。CommonsenseQAは常識推論能力を評価するための5択の選択式問題です。JCommonsenseQAはCommonsenseQAの日本語版で、コアとなる選択肢を知識ベースであるConceptNetの日本語部分から抽出し、質問と誤り選択肢をクラウドソーシングで作成しました。以下の例において、赤字が正解の選択肢を表しています。

4. 日本語基盤モデルの網羅的評価
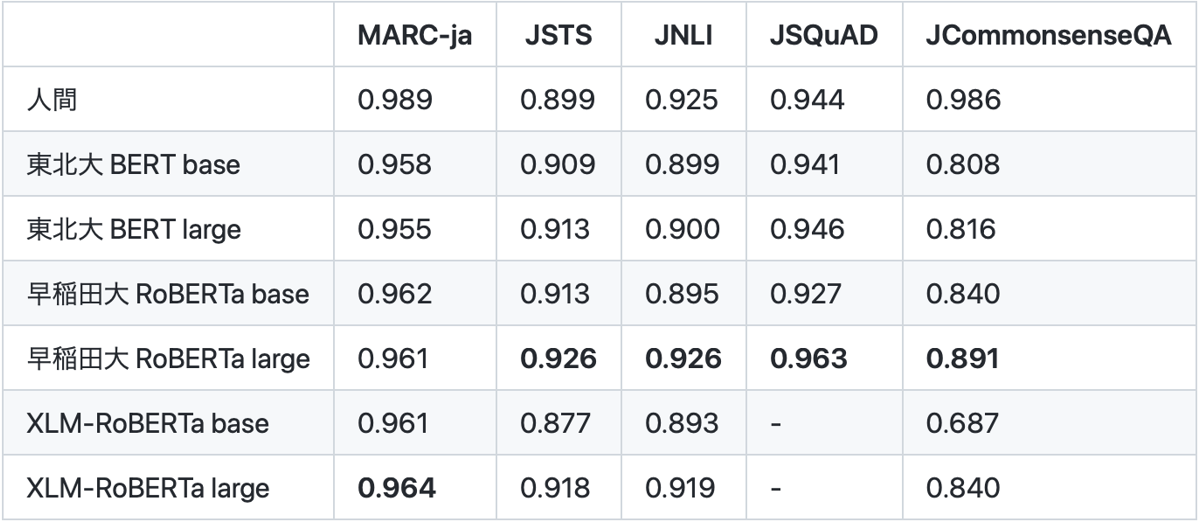
構築したJGLUEを用いて、広く用いられている日本語基盤モデルの網羅的評価を行いました。モデルの精度との比較のために、クラウドソーシングを使って人間のスコアを算出しました。結果を以下に示します。
(XLM-RoBERTaが採用しているトークナイザの結果が単語区切と一致しないことが多く、JSQuADの評価が公平に行えないので除外しています。)
この表からは以下のことが読みとれます。
- 全般的には早稲田大 RoBERTa largeモデルが最も性能がよいです。これはモデルサイズがlargeであることと、事前学習のテキストとしてWikipediaよりも大規模なウェブテキストを使っていることが考えられます。
- 多言語モデルであるXLM-RoBERTaは早稲田大 RoBERTaよりも少し劣っていますが、多言語モデルは日本語に対しても十分性能を出せています。
- JCommonsenseQA 以外についてはベストなモデルは人間のスコアと同等または超えています。
このような網羅的評価が日本語でも行えるようになったのは日本語の自然言語処理における大きな進展であると言えます。
5. おわりに
この記事では構築した日本語言語理解ベンチマークJGLUEの背景や中身、また、JGLUEを用いた日本語基盤モデルの評価について説明しました。より詳細な内容はわれわれの論文[文献10,11]をご参照ください。
JGLUEは以下のアドレスで公開しています。利用申請などは不要で、ライセンスはCC BY-SA 4.0にしています。
お試しいただきフィードバックなどをいただければ幸いです。新たな基盤モデルの開発においてJGLUEが利用されることや、より難しいベンチマークの提案が行われることを期待していますし、われわれも今後より難しいベンチマークを構築していく予定です。
参考文献
- [文献1] Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, Erik Brynjolfsson, Shyamal Buch, Dallas Card, Rodrigo Castellon, Niladri S. Chatterji, Annie S. Chen, Kathleen Creel, Jared Quincy Davis, Dorottya Demszky, Chris Donahue, Moussa Doumbouya, Esin Durmus, Stefano Ermon, John Etchemendy, Kawin Ethayarajh, Li Fei-Fei, Chelsea Finn, Trevor Gale, Lauren Gillespie, Karan Goel, Noah D. Goodman, Shelby Grossman, Neel Guha, Tat- sunori Hashimoto, Peter Henderson, John Hewitt, Daniel E. Ho, Jenny Hong, Kyle Hsu, Jing Huang, Thomas Icard, Saahil Jain, Dan Juraf- sky, Pratyusha Kalluri, Siddharth Karamcheti, Geoff Keeling, Fereshte Khani, Omar Khattab, Pang Wei Koh, Mark S. Krass, Ranjay Krishna, Rohith Kuditipudi, and et al. On the opportunities and risks of foundation models. CoRR, Vol. abs/2108.07258, 2021.
- [文献2] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In NAACL2019, pp. 4171– 4186, Minneapolis, Minnesota, June 2019.
- [文献3] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. In NeurIPS2020, Vol. 33, pp. 1877–1901. Curran Associates, Inc., 2020.
- [文献4] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, Vol. 139 of Proceedings of Machine Learning Research, pp. 8748–8763. PMLR, 18–24 Jul 2021.
- [文献5] Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. GLUE: A multi-task benchmark and analysis platform for natural language understanding.In EMNLP2018 Workshop, pp. 353–355, Brussels, Belgium, November 2018.
- [文献6] Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. SuperGLUE: A stickier benchmark for general-purpose language understanding systems. In NeurIPS2019, Vol. 32. Curran Associates, Inc., 2019.
- [文献7] Phillip Keung, Yichao Lu, Gy ̈orgy Szarvas, and Noah A. Smith. The multilingual Amazon reviews corpus. In EMNLP2020, pp. 4563–4568, Online, November 2020.
- [文献8] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ questions for machine comprehension of text. In EMNLP2016, pp. 2383–2392, Austin, Texas, November 2016.
- [文献9] Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering challenge targeting commonsense knowledge. In NAACL2019, pp. 4149–4158, Minneapolis, Minnesota, June 2019.
- [文献10] 栗原健太郎, 河原大輔, 柴田知秀. JGLUE: 日本語言語理解ベンチマーク. 言語処理学会第28回年次大会, 2022. https://www.anlp.jp/proceedings/annual_meeting/2022/pdf_dir/E8-4.pdf
- [文献11] Kentaro Kurihara, Daisuke Kawahara, and Tomohide Shibata. JGLUE: Japanese general language understanding evaluation. In LREC2022, pp. 2957–2966, Marseille, France, June 2022. https://aclanthology.org/2022.lrec-1.317
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 柴田 知秀
- Yahoo! JAPAN研究所 上席研究員
- 自然言語処理に関する研究開発をしています。
-



