こんにちは。Yahoo! JAPAN研究所でインターンシップをしている立命館大学大学院修士2年の松根です。普段は、レコメンドシステムや機械学習アルゴリズムに関する研究をしています。
今回は、Yahoo! JAPAN内に多く存在するユーザの興味や属性を予測するモデルを活用することで、より多くの方々に対してレコメンドを行うシステムCERAMとその実証実験の結果について紹介いたします。今回お伝えする内容は、データサイエンスのトップカンファレンスの1つである「KDD2022」の本会議に採択された内容となっています。
予測モデルのリサイクル
突然ですが、皆さんはリサイクルと聞いてどのようなイメージを思い浮かべますか?リサイクルとは、必要なくなったものやゴミなどを捨てるのではなく、回収し、再度利用することです。例として、駅で使用された切符を回収し、それをゴミ箱やトイレットペーパーなどに変換して利用するといったことが挙げられます。
そういったリサイクルの中でも、今回のテーマの中心になっているのは「予測モデルのリサイクル」です。Yahoo! JAPANでは検索、ショッピング、ニュースなど幅広く多くのサービスが展開されています。
そして、サービスごとのデータを分析することで、ユーザがどんな属性を持っているかや、ユーザがどんなことに興味があるのか推定しています。例えば、あるユーザは「カブトムシを飼っていそう」だとか、また別のユーザは「旅行が好きそうな人だ」などです。こういったユーザの興味や属性の推定を行うモデルのことを予測モデルと呼んでおり、ヤフーに蓄積されたユーザの利用ログデータをAIが解析することで作成されます。
(※モデル作成にあたり、ヤフーではお客様のプライバシーの保護に細心の注意を払っています。詳しくはYahoo! JAPAN プライバシーセンターをご覧ください。)
なぜ「予測モデルのリサイクル」?
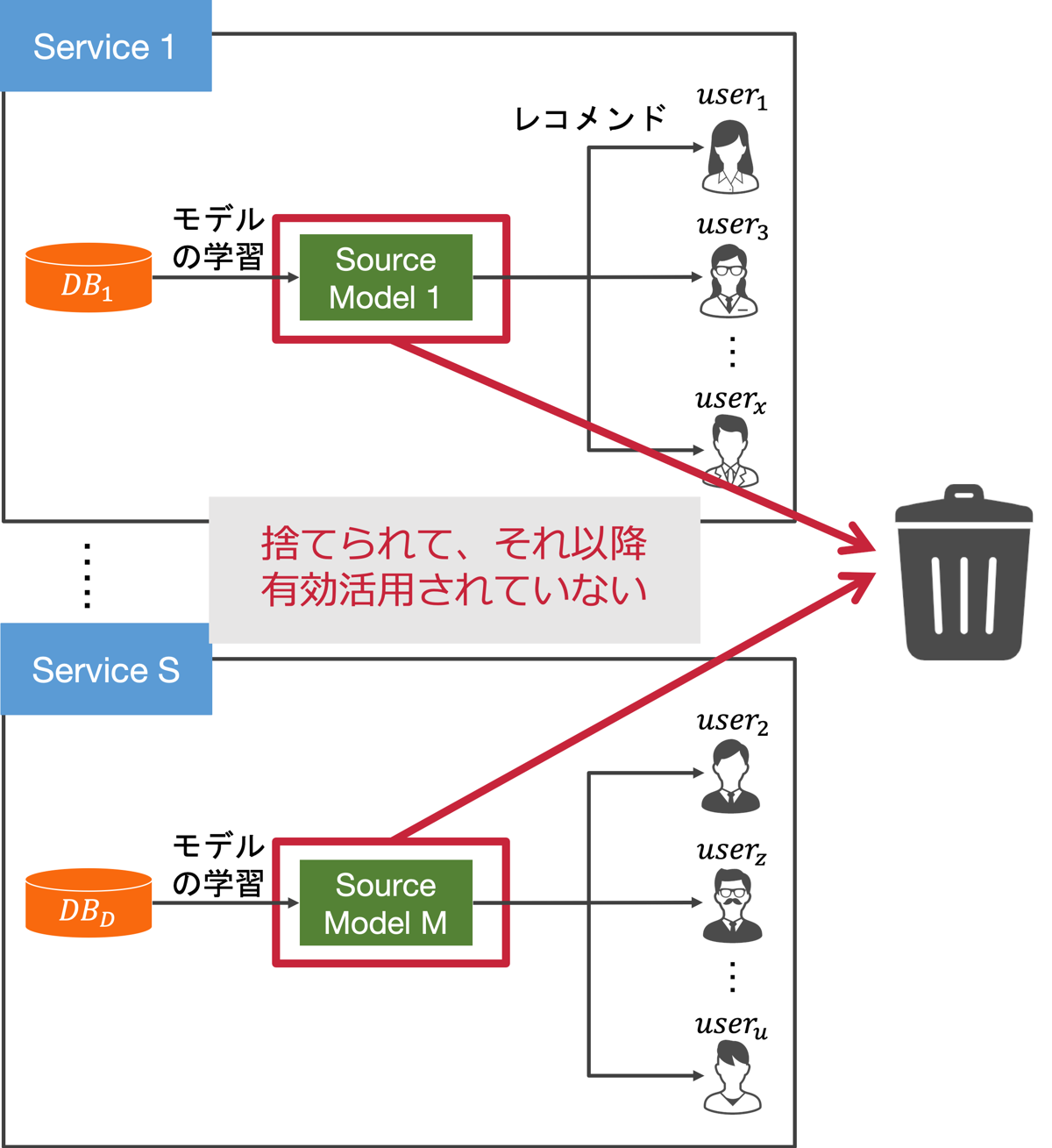
「予測モデルのリサイクル」に着目した理由は、Yahoo! JAPAN内にはレコメンド改善に活用できそうな予測モデルがたくさんあるにもかかわらず、それらは一度レコメンドに使用されると捨てられてしまうという状況があったためです。
Yahoo! JAPANでは幅広く多くのサービスが展開されています。そして各サービスでは、ユーザの興味を予測するモデルをサービスから得られたデータを用いて学習し、レコメンドに活用しています。例えば、Yahoo!ショッピングでカブトムシグッズをたくさん購入している人のログデータを用いて「カブトムシを飼っていそうな人」を予測するモデルや、Yahoo!トラベルを通じて、旅行の予約をたくさんしている人のログデータを用いて「旅行が好きそうな人」を予測するモデルを作成しています。
これらの予測モデルをサービスを横断して総合的に活用することができれば、ユーザの興味に関するシグナルをより多く取得することができ、レコメンドの改善に生かすことができます。しかしながら、これらの予測モデルは一度レコメンドに使用されると、それ以降有効活用されていないという状況がありました。そこで「予測モデルのリサイクル」を行うことで、レコメンドを改善しようというのが本件のモチベーションとなっています。
「予測モデルのリサイクル」を実用化する際の問題点
本件は「予測モデルのリサイクル」を通してレコメンドの改善をすることが主な目的となっていますが、それに加えてシステムを実用化することも目的としています。つまり、ただ「予測モデルのリサイクル」を行う手法を考えるだけではなく、それを実際のサービスやアプリケーションで活用できるようにするということです。
今回の「予測モデルのリサイクル」実用化を実現するために、行ったことは以下の2つです。
- 心理的障壁の軽減
- 実際のサービスにおける効果検証
1つめの心理的障壁については、今回のシステムを利用してレコメンドを行うサービス担当者の方が、システムがうまく動作するのか不安に感じる可能性があるという心理的障壁を軽減する必要があるということです。それは今回、各サービスで学習された予測モデルが予測した結果、つまりは、本当に正しいかどうか分からない不確実なものをシステム内で活用していくためです。
2つめは、実際のサービスやアプリケーションにシステムを導入するにあたって、十分な性能が出せているかを大規模なオンラインテストで検証する必要があるといことです。
どうやって解決したのか
今回は、「予測モデルのリサイクル」を通したレコメンドの改善、特により多くの方々にレコメンドを行うための手法CERAM(Coverage Expansion Recommendation system by Associating discarded Models)を開発しました。
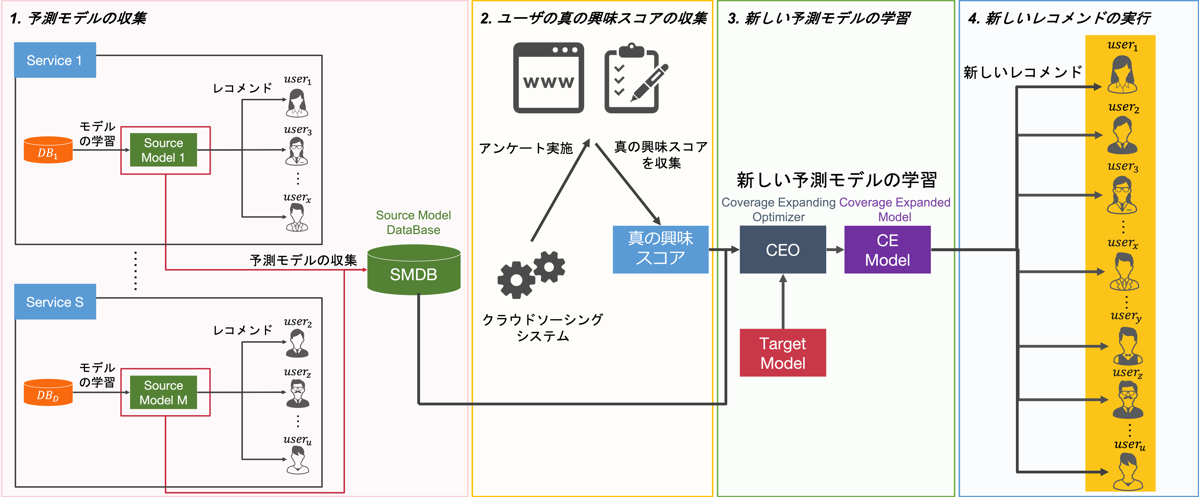
CERAMは大きく分けて、4つのステップで構成されています。
- 予測モデルの収集
- ユーザの真の興味スコアの収集
- 新しい予測モデルの学習
- 新しいレコメンドの実行
1つ目の「予測モデルの収集」というステップでは、今までは捨てられていた各サービスが学習されたユーザの興味や属性を予測するモデルを1つのデータベースに格納します。その結果、下図のように、行にユーザ、列に各サービスの予測モデルを対応づけ、各値はあるユーザの予測モデルの予測スコアを表すようなデータベースを作成できます。このデータベースを活用することで、サービスを横断して今までは捨てられていた予測モデルのさらなる活用やそのリサイクルが可能になります。
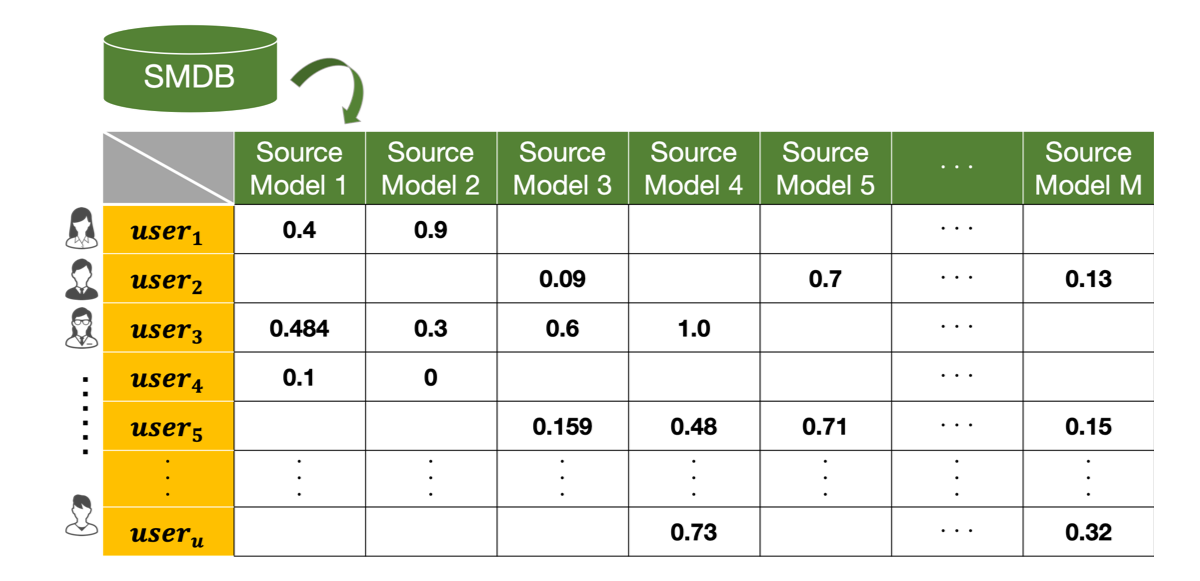
ここでポイントとなるのは、各サービスのユーザ群は異なるため、それに伴い予測モデルが予測を行うことができるユーザも各予測モデルごとに異なるため、空白がたくさんあるようなデータが出来上がることです。そして、この空白を予測するような新しい予測モデルを機械学習を用いて学習することで、より多くの方々に対してレコメンドを行うことが可能になります。
2つ目の「ユーザの真の興味スコアの収集」というステップでは、クラウドソーシングのシステムを用いて、web上でアンケートを行うことで、予測モデルの予測スコアといった本当に正しいかわからないスコアではなく、ユーザの真の興味を収集します。ここで収集されたデータは、次の新しい予測モデルを学習するステップで活用されます。
3つ目の「新しい予測モデルの学習」というステップでは、ステップ1とステップ2で収集したデータを用いて、より多くの方々にレコメンドを行うための新しい予測モデルの学習を行います。具体的には、空白を埋めたい予測モデルをターゲット、その他の予測モデルを説明変数として設定し、機械学習アルゴリズムを適用することで新しい予測モデルの学習を行います。ここで、データベース内のデータを使ってそのまま学習すると、予測スコアという本当に正しいかどうかわからない不確実なものから学習するため、先述した心理的抵抗が強く生じてしまう可能性があります。そこで、ステップ2で収集した真の興味スコアを説明変数として扱う一部のモデル、一部のユーザの対して加えることで、予測スコアの不確実性を軽減し、ある程度の信頼性を保証することで、心理的抵抗を軽減しています。
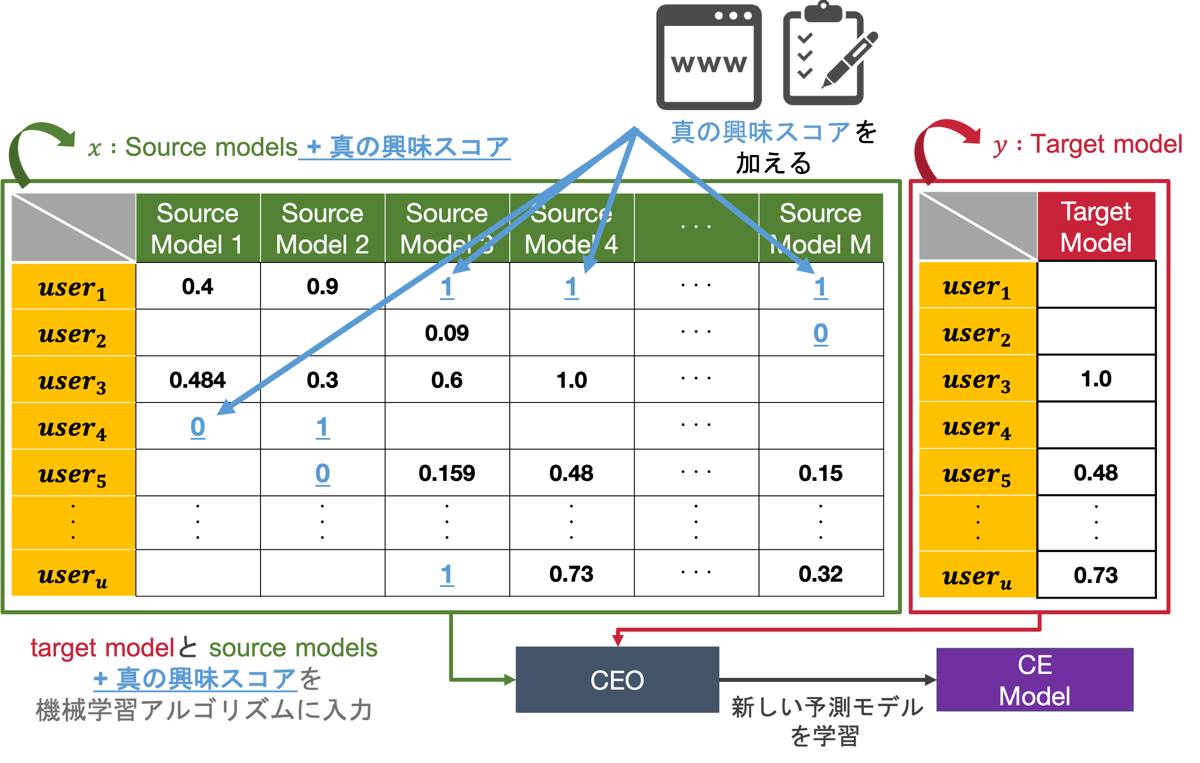
4つ目の「新しいレコメンドの実行」というステップでは、3つ目のステップで学習した新しい予測モデルを用いて、空白の予測を行い、より多くの方々に対するレコメンドを新しく実行していきます。
オンラインテストでの効果検証
今回は、開発したCERAMを実用化するために、実際のサービスにおける大規模なオンラインテストでCERAMの性能を評価しました。
具体的には、そのサービスで普段レコメンドに使われている予測モデルと、CERAMでユーザの興味を予測し、レコメンドのメールを送信します。そして、そのサービスで普段レコメンドに使われている予測モデルと同じCTR(Click Through Rate)でCERAMが新しくどれだけのユーザに対してレコメンドが可能だったかを評価しました。
今回の実験では、「串カツ」、「スキー」、「焼肉」に対する興味を予測するモデルの3つを対象にし、Yahoo!ロコの訴求メールで串カツ、焼肉ジャンルの予約のレコメンド、Yahoo!チケットでスキー場特集の訴求メールでレコメンドを行いました。結果は下の表のようになっています。

結果として、今回のCERAMはCTRを維持したままより多くのユーザに対して新しくレコメンドすることが可能となり、サービスに対しても大きな影響を与えられることが確認できました。
具体的には、串カツに対するレコメンドの結果が最も顕著で、そのサービスで普段レコメンドに使われている予測モデルと同じCTRでCERAMが約76.9倍(人数にして約52万人)もの新しいユーザに対してレコメンドできるという結果が得られました。また、焼肉に対するレコメンドにおいては、1.7%と小さな効果に見えるかもしれませんが、1%レベルの効果でもレコメンドの規模が大きくなっていけば、CERAMがサービスに与える効果は大きくなっていくため、サービスに対してとても有益な結果といえます。
メンターからの一言
本インターンにて松根さんのメンターをさせていただいている坪内と申します。Yahoo! JAPANでの予測モデルのリサイクルによるレコメンド改善手法CERAMについて紹介してもらいました。
この研究は、ヤフーの膨大なデータを解析するものです。データ解析の高度なスキルはもちろん、データに対して真摯に向き合う姿勢も問われる研究テーマとなっています。2年間の成果が見事、データ解析のトップカンファレンスであるKDD22に採択されました。まだ詳細を発表できませんが、次の論文、さらに次の論文の執筆も見えてきました。
さらなる素晴らしい成果を生み出していただきたいです!松根さんを応援ください!
紹介論文
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 松根 喜生
- Yahoo! JAPAN研究所(インターンシップ)
- Yahoo! JAPAN研究所のインターンシップとして、レコメンドシステムや機械学習アルゴリズムに関する研究をしています。



